一种基于Intral-Class Gap GAN的面部表情识别方法
文献发布时间:2023-06-19 09:26:02
技术领域
本发明涉及图像处理及深度学习的面部表情识别领域,总的来说,是关于一种基于生成对抗的面部表情识别方法。
背景技术
我国庞大的流动人口对城市基础设施和公共服务构成巨大的压力,近年来恶性伤人事件频发,安防形势备受关注,城市管理与服务体系严重滞后,亟待完善,加强城市监控和对不法分子的面部表情识别变得尤为重要。表情是通过脸部肌肉变化表现出的情绪状态,通过对人的面部情感表达的识别,可以判断出异常心理状态、推测极端情绪,观测复杂环境出现的行人的面部表情,为进一步判断人的心理提供技术支撑,大致判断出哪些人比较可疑,及时阻止某些犯罪活动。传统的面部表情识别主要是基于模板匹配和神经网络的面部表情识别方法。而且传统的面部表情在特征选择过程需要人为干预,依靠人工对特征提取算法进行精细设计,缺乏足够的计算能力,训练难度大、准确率低且及易丢失原有的表情信息。
发明内容
发明目的:
根据上述提出的真实情况下的面部表情识别存在的类内差距,针对复杂环境安检中难度大,由类内差距引起的不能满足面部表情识别识别率的需求的技术问题,提供一种基于生成对抗的面部表情识别方法。
技术方案:
一种基于Intral-Class Gap GAN的面部表情识别方法,
所述的识别模型构建,包括以下几个步骤:
(1)、采集人脸不同来源及不同表情的实时图像;
(2)、将该图像输入至Intral-Class Gap GAN神经网络模型进行识别;
(3)、输出识别结果;
所述(2)步骤中的Intral-Class Gap GAN神经网络模型构建方法如下:
(2.1)、采集人脸不同来源及不同表情的历史图像;
(2.2)、对采集的人脸图像进行预处理,构建人脸表情数据集;
(2.3)、针对(2.2)步骤中的数据集中存在类内差距的面部表情识别问题,构建Intral-Class Gap GAN神经网络模型;
(2.4)、结合输入图像与重构图像之间的像素差异和潜在向量的差异对网络的生成器和鉴别器进行同时训练,确保重构图像与输入图像的差异最小。
(2.2)步骤中人脸表情数据集构建方法如下:
S11:以Multi-PIE和JAFFE表情数据集做基础,通过(2.1)步骤在网络上下载面部表情图片,进行自制所需的面部表情数据集,选择不同国家、不同年龄段、不同职业等人群的abomination、happy,neutral、anxious、surprise and fear 5种面部表情进行实验,增加了大量具有类内差距的面部表情特征的复杂度该数据集作为网络训练的输入图像x
S12:几何归一化处理所述输入图像,并对归一化处理后的图像进行人脸检测;
S13:尺度归一化所述步骤S12中的处理之后的图像,统一图像的尺寸。
步骤(2.4)中具体如下:
S14:基于步骤S13中处理的图像对基于生成对抗的IC-GAN(Intral-Class GapGAN)神经网络的面部表情识别网络模型进行训练;
S15:对图像进行数据增强以及数据扩充处理;
S16:对所述网络模型进行训练并保存训练后的网络模型。
所述步骤S12中包括以下几个步骤:
S121:针对采集的图像定特征点[x,y],对两只眼睛和鼻子的特征点进行标定,得到特征点的坐标值;
S122:根据人脸上的眼睛的坐标将图像进行旋转,以保证人脸方向的一致性,其中人的眼睛的距离为d,两只眼睛的中点为O;
S123:据标定的特征点和几何模型确定包含人脸的方框,从O开始,向左和向右分别裁剪d的距离,上下方向分别取0.5d和1.5d的进行裁切。
所述步骤S13中包括以下步骤:
S131:对步骤S123中裁切出来的图片进行尺度归一化,将图像统一resize为256*256像素的图像,完成对图像的几何归一化。
所述步骤S14中包括以下步骤:
S141:利用pytorch深度学习框架构建所提出的IC-GAN(Intral-Class Gap GAN)神经网络,首先将S13步骤处理之后的图片输入到第一层卷积层进行卷积操作,通过4*4的卷积核对输入图像进行卷积,输出为128*128*64;再采用LeakyReLu激活函数对卷积进行非线性操作,输出为128*128*64;所述LeakyReLu激活函数为:
S142:对上一层的输出继续使用4*4的卷积核进行卷积操作,输出为64*64*128,继而采用batchnorm层对上一层的输出进行归一化操作,再采用LeakyReLu激活函数对卷积进行非线性操作,输出为64*64*128
S143:对上一层的输出继续使用步骤S142的方法进行卷积、batchnorm和LeakyReLu操作,输出为4*4*100;
S144:对S143的输出进行卷积核4*4的反转置卷积操作,输出为29*29*1,然后使用batchnorm进行批量归一化操作,再采用ReLu激活函数对输出进行非线性操作,输出为32*32*128;所述ReLu激活函数为:
S145:对上一层的输出再次进行步骤S144所述的卷积、bathnorm和ReLu操作,输出为64*64*64;
S146:对上一层的输出使用ReLu激活函数进行非线性操作,再使用卷积核为4*4的反转置卷积对上一层进行卷积操作,然后使用Tanh激活函数进行非线性操作,输出为128*128*128;所述的Tanh激活函数为:
S147:对上一层的输出再次进行S141-S143过程中的操作,输出为1*1*5;
S148:将步骤S13中尺度归一化后的图像和S147的输出一起输入到一个4*4的卷积层,进行卷积操作,然后使用非线性激活函数LeakyReLu进行非线性激活,输出为128*128*64;
S149:对上一层的输出使用4*4的卷积核对上一层的输出进行卷积操作,然后使用batchnorm进行批量归一化操作,再采用LeakyReLu非线性激活;
S1491:继续对上一层的输出采用S142的过程进行卷积、batchnorm以及非线性操作输出为4*4*1;
S1492:最后对上一层的输出采用Softmax,输出判别为真的概率;
S1493:将S147过程的的输出进行全连接操作,通过Softmax分类器最终实现训练出5种表情,所述5种表情为1=happy,2=abomination,3=neutral,4=anxious,5=surprise and fear,实现对面部表情的识别。
步骤S15包含
S151:将网络损失loss函数也分为四部分,对于第一部分的生成网络,在像素层面上减小原始图像和重构图像的差距,重构误差损失为:
L
pX表示数据分配;X是输入图像G(x)是网络中生成器生成的图像;
使用Salimans等提出的特征匹配方法,以减少训练的不稳定性,图像特征层面进行优化,第二部分网络的鉴别器的一个特征匹配误差为:
L
式中f(·)代表鉴别器模型变换;
第三部分为潜在向量z与重构潜在向量
式中h(■)代表编码变换;
第四部分的网络损失为Softmax层的交叉熵损失:
式中k(■)代表Softmax的交叉熵损失过程,k(y)代表真实结果,
整体网络损失函数如下:
L=ω
其中ω
S152:优化器选择Adam Optimizer,学习率设置为0.0002,训练样本分批次进行训练,每个批次选择16张图片进行训练,epoch分别设为100,200,300,400;
S153:在每次的训练中首先获得1个epoch的图片,接下来计算loss损失值,然后使用Adam优化器不断更新网络的参数,使网络的损失值最小。
步骤(3)中,将图片输入到已经训练好的IC-GAN网络模型中进行识别,最终输出每类面部表情的概率,输出概率最大的表情类别即为我们分类的结果;概率计算公式如下:
其中z
优点效果:
本发明设计一种基于生成对抗的面部表情识别方法,包含了具有类内差距的面部表情识别的网络训练过程和离线识别过程;所述的离线识别过程,应该包含以下步骤:
S11:通过网络下载、跳帧解析视频、采集输入图像x;
S12:几何归一化处理所述输入图像x,并检测归一化处理后的图像x’;
S13:处理所述检测裁剪后的图像x’到统一的尺寸;
S14:构建基于生成对抗的面部表情识别的网络模型;
S15:对图像x’进行数据增强和数据扩充处理,以及统一图像尺寸;
S16:对所述网络模型进行训练并对训练后的网络模型进行存储;
对所述的识别过程,应该包含以下几个步骤:
S21:通过网络下载、跳帧解析视频、采集输入图像I;
S22:然后所述的输入图像I输入所述训练后的网络模型;
S23:得到识别结果。
对所述步骤S12还应该包含以下步骤:
S121:对所述输入图像进行几何归一化处理;所述的几何归一化方法包括尺度归一化、外头校正、扭脸校正;
S122:通过OpenCV开源库中的人脸检测方法,对几何归一化后的图像进行人脸检测,然后对检测后的图像进行降噪处理;
S23:得到几何归一化后的图像x’。
对所述的步骤S13还应该包含:
S131:根据所述的人脸的坐标确定图像的位置;
S132:使用OpenCV检测得到人脸图像;
S133:使用裁剪后的人脸图像调整为统一尺寸,将剪切后的人脸图像变为256*256大小。
更进一步,步骤S14还应该包含:S141:利用pytorch深度学习框架构建我们的IC-GAN神经网络,首先将图片输入到con_1层进行卷积操作,通过4*4的卷积核对输入图像进行卷积,输出为128*128*64;再采用LeakyReLu激活函数对卷积进行非线性操作,输出为128*128*64;所述LeakyReLu激活函数为:
S142:对上一层的输出继续使用4*4的卷积核进行卷积操作,输出为64*64*128,继而采用batchnorm层上对上一层的输出进行归一化操作,再采用LeakyReLu激活函数对卷积进行非线性操作,输出为64*64*128;
S143:对上一层的输出继续使用S142的方法进行卷积、batchnorm和LeakyReLu操作,输出为4*4*100;
S144:对S143的输出进行卷积核4*4的反转置卷积操作,输出为29*29*1,然后使用batchnorm进行批量归一化操作,再采用ReLu激活函数对输出进行非线性操作,输出为32*32*128;
S145:对上一层的输出再次进行S144所述的卷积、bathnorm和ReLu操作,输出为64*64*64;
S146:对上一层的输出使用ReLu激活函数进行非线性操作,再使用卷积核为4*4的反转置卷积对上一层进行卷积操作,然后使用Tanh激活函数进行非线性操作,输出为128*128*128;
S147:对上一层的输出再次进行S141-S143过程中的操作,输出为1*1*5;
S148:将原始图像和S147的输出一起输入到一个4*4的卷积层,进行卷积操作,然后使用非线性激活函数LeakyReLu进行非线性激活,输出为128*128*64;
S149:对上一层的输出使用4*4的卷积核对上一层的输出进行卷积操作,然后使用batchnorm进行批量归一化操作,再采用LeakyReLu非线性激活;
S1491:继续对上一层的输出采用S150的过程进行卷积、batchnorm以及非线性操作输出为4*4*1;
S1492:最后对上一层的输出采用Softmax,输出判别为真的概率。
S1493:将S147过程的的输出进行全连接操作,通过Softmax分类器最终实现训练出5种表情,所述5种表情为1=happy,2=abomination,3=neutral,4=anxious,5=surprise and fear,实现对面部表情的识别;
步骤S15还应该包含:S151:根据网络结构以及实验特点,将网络损失loss也分为四部分,对于第一部分的生成网络,在像素层面上减小原始图像和重构图像的差距,重构误差损失为:
L
本文使用Salimans等提出的特征匹配方法,以减少训练的不稳定性,图像特征层面进行优化,第二部分网络的鉴别器的一个特征匹配误差为:
L
式中f(·)代表鉴别器模型变换。
第三部分为潜在向量z与重构潜在向量
式中h(·)代表编码变换。
第四部分的网络损失为Softmax层的交叉熵损失:
式中k(·)代表Softmax的交叉熵损失过程,k(y)代表真实结果,
整体网络损失函数如下:
L=ω
其中ω
S152:优化器选择Adam Optimizer,学习率设置为0.0002,训练样本分批次进行训练,每个批次选择16张图片进行训练,epoch分别设为100,200,300,400。
S153:在每次的训练中首先获得1个epoch的图片,接下来计算loss损失值,然后使用Adam优化器不断更新网络的参数,使网络的损失值最小。
更进一步,所述的S16还应该包含:S161:通过网络下载、跳帧解析视频、采集输入图像;
S162:对所述输入图像进行几何归一化处理、人脸检测、opencv处理和统一尺寸;
S163:将处理后的图像输入到训练好的IC-GAN网络模型中进行识别,最终输出每种表情的概率,概率最大的表情作为我们的网络想要识别的表情。
与现有技术相比,本发明的优点在于:
本发明提供的基于生成对抗的面部表情识别方法,通过与传统人工提取表情特征的方法相比,实现了自动对人脸表情特征的提取,相比于稍微早期的神经网络面部表情识别,本发明实现了识别率的提高,从而精确的进行表情识别。
附图说明
为了更加清晰的说明本发明实施例或现有的技术方案,以下将会对实施例或现有技术描述中锁足要的全部附图作简要的介绍,所以,下列附图是本发明的一些实施例,对于这个领域的其他研究者,能够根据这些图获得其他的附图。
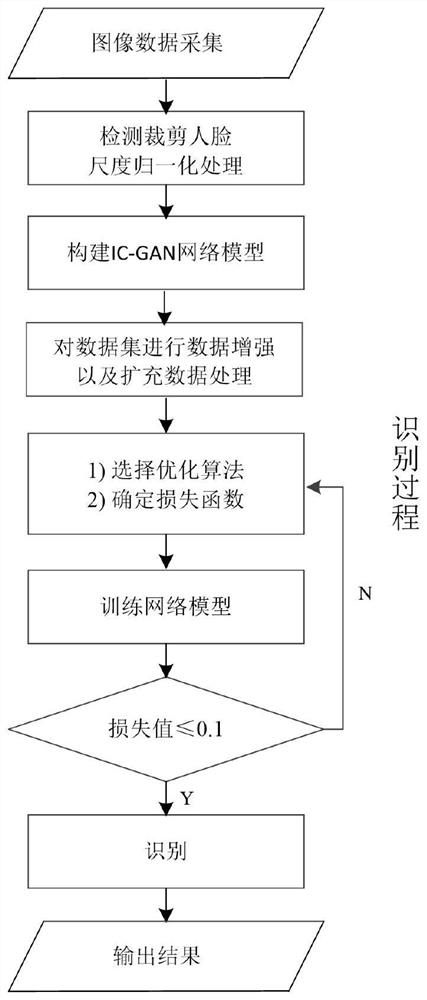
图1为本发明整体流程图。
图2为本发明IC-GAN网络模型示意图
具体实施方式
一种基于Intral-Class Gap GAN的面部表情识别方法,
所述的识别模型构建,包括以下几个步骤:
(1)、采集人脸不同来源及不同表情的实时图像;
(2)、将该图像输入至Intral-Class Gap GAN神经网络模型进行识别;
(3)、输出识别结果;
所述(2)步骤中的Intral-Class Gap GAN神经网络模型构建方法如下:
(2.1)、采集人脸不同来源及不同表情的历史图像;
(2.2)、对采集的人脸图像进行预处理,构建人脸表情数据集;
(2.3)、针对(2.2)步骤中的数据集中存在类内差距(同一种表情的差距叫类内差距,或者说同类表情有不同的表达形式,此类为类内差距,有可以叫类内差距较大,采集到的图像可能受外界环境遮挡物拍摄角度等影响同样是笑的表情可能由于上述原因造成误识成其他类型的表情,同类表情,但是由于周围环境复杂等原因造成特征区别特别大最终影响识别精度,同类表情就是例如:都是微笑,都是大笑等,受外界环境遮挡物拍摄角度等影响都会造成误识成其他类型的表情的情况)的面部表情识别问题,构建Intral-ClassGap GAN神经网络模型;
(2.4)、结合输入图像(网络训练时输入的训练样本)与重构图像(是训练过程中产生的图像用来与原图像进行匹配当生成也就是重构的图像与输入图像无差异时认为网络已经训练好了可以正确提取图像特征了)之间的像素差异和潜在向量的差异对网络的生成器和鉴别器进行同时训练,确保重构图像与输入图像的差异最小。(我们所构建的网络在训练的时候通过将原始输入的图片与网络生成的图片进行对比什么时候网络生成的图片跟输入图片一致了网络就训练好了这个时候网络识别的能力最强)
(2.2)步骤中人脸表情数据集构建方法如下:
S11:以Multi-PIE和JAFFE表情数据集做基础,通过(2.1)步骤在网络上下载面部表情图片,进行自制本文所需的面部表情数据集(样本扩充),选择不同国家、不同年龄段、不同职业等人群的abomination、happy,neutral、anxious、surprise and fear 5种面部表情进行实验,增加了大量具有类内差距(也可以叫类内差距较大,一般只要有类内差距,基本识别出来差距都比较大,一种表情的相同的表达的形式,包括同一表情(例如同样是微笑、同样是大笑等),在相同的背景环境下所呈现的形式,就叫做类内,例如同一人的同一个微笑表情在同一个背景环境下的呈现,不满足这样的情况就属于存在类内差距,或者叫类内差距较大,例如:背景不同、表情不同或者不是同一个人,只要满足其一的都属于存在类内差距或者类内差距较大。)的面部表情特征的复杂度该数据集作为网络训练的输入图像x
S12:几何归一化处理所述输入图像,并对归一化处理后的图像进行人脸检测(获取合适的人脸图像如权利项3中所说要通过处理获得适合于网络训练的样本数据,例如可能需要旋转保证人脸方向的一致性等);
S13:尺度归一化所述步骤S12中的处理之后的图像,统一图像的尺寸(S12和S13为预处理过程)。
步骤(2.4)中具体如下:
S14:基于步骤S13中处理的图像对基于生成对抗的IC-GAN(Intral-Class GapGAN)神经网络的面部表情识别网络模型进行训练;
S15:对图像进行数据增强以及数据扩充处理;
S16:对所述网络模型进行训练并保存训练后的网络模型。
所述步骤S12中包括以下几个步骤:
S121:针对采集的图像定特征点[x,y],对两只眼睛和鼻子的特征点进行标定,得到特征点的坐标值;
S122:根据人脸上的眼睛的坐标将图像进行旋转,以保证人脸方向的一致性(人脸图像预处理的过程,体现了人脸在图像平面内的旋转不变性),其中人的眼睛的距离为d,两只眼睛的中点为O;
S123:据标定的特征点和几何模型确定包含人脸的方框,从O开始,向左和向右分别裁剪d的距离,上下方向分别取0.5d和1.5d的进行裁切。
所述步骤S13中包括以下步骤:
S131:对步骤S123中裁切出来的图片进行尺度归一化,将图像统一resize为256*256像素的图像,完成对图像的几何归一化。
所述步骤S14中包括以下步骤:
S141:利用pytorch深度学习框架构建所提出的IC-GAN(Intral-Class Gap GAN)神经网络,首先将S13步骤处理之后的图片输入到第一层卷积层进行卷积操作,通过4*4的卷积核对输入图像进行卷积,输出为128*128*64;再采用LeakyReLu激活函数对卷积进行非线性操作,输出为128*128*64;所述LeakyReLu激活函数为:
S142:对上一层(第一层卷积层)的输出继续使用4*4的卷积核进行卷积操作,输出为64*64*128,继而采用batchnorm层对上一层的输出进行归一化操作,再采用LeakyReLu激活函数对卷积进行非线性操作,输出为64*64*128
S143:对上一层的输出继续使用步骤S142的方法进行卷积、batchnorm和LeakyReLu操作,输出为4*4*100;
S144:对S143的输出进行卷积核4*4的反转置卷积操作,输出为29*29*1,然后使用batchnorm进行批量归一化操作,再采用ReLu激活函数对输出进行非线性操作,输出为32*32*128;所述ReLu激活函数为:
S145:对上一层的输出再次进行步骤S144所述的卷积、bathnorm和ReLu操作,输出为64*64*64;
S146:对上一层的输出使用ReLu激活函数进行非线性操作,再使用卷积核为4*4的反转置卷积对上一层进行卷积操作,然后使用Tanh激活函数进行非线性操作,输出为128*128*128;所述的Tanh激活函数为:
S147:对上一层的输出再次进行S141-S143过程中的操作,输出为1*1*5;
S148:将步骤S13中尺度归一化后的图像和S147的输出一起输入到一个4*4的卷积层,进行卷积操作,然后使用非线性激活函数LeakyReLu进行非线性激活,输出为128*128*64;
S149:对上一层的输出使用4*4的卷积核对上一层的输出进行卷积操作,然后使用batchnorm进行批量归一化操作,再采用LeakyReLu非线性激活;
S1491:继续对上一层的输出采用S142的过程进行卷积、batchnorm以及非线性操作输出为4*4*1;
S1492:最后对上一层的输出采用Softmax,输出判别为真的概率。
S1493:将S147过程的的输出进行全连接操作,通过Softmax分类器最终实现训练出5种表情,所述5种表情为1=happy,2=abomination,3=neutral,4=anxious,5=surprise and fear,实现对面部表情的识别。
步骤S15包含
S151:根据所构建的IC-GAN网络结构,将网络损失loss函数也分为四部分,对于第一部分的生成网络,在像素层面上减小原始图像和重构图像的差距,重构误差损失为:
L
pX表示数据分配;X是输入图像G(x)是网络中生成器生成的图像;
本文使用Salimans等提出的特征匹配方法,以减少训练的不稳定性,图像特征层面进行优化,第二部分网络的鉴别器的一个特征匹配误差为:
L
式中f(·)代表鉴别器模型变换。
第三部分为潜在向量z与重构潜在向量
式中h(·)代表编码变换。
第四部分的网络损失为Softmax层的交叉熵损失:
式中k(·)代表Softmax的交叉熵损失过程,k(y)代表真实结果,
整体网络损失函数如下:
L=ω
其中ω
S152:优化器选择Adam Optimizer,学习率设置为0.0002,训练样本分批次进行训练,每个批次选择16张图片进行训练,epoch分别设为100,200,300,400。
S153:在每次的训练中首先获得1个epoch的图片,接下来计算loss损失值,然后使用Adam优化器不断更新网络的参数,使网络的损失值最小。
步骤(3)中,将图片输入到已经训练好的IC-GAN网络模型中进行识别,最终输出每类面部表情的概率,输出概率最大的表情类别作为我们分类的结果
为使得本技术领域的研究者能够更加清楚的理解本发明的方案,以下将结合本发明实施例中的附图,对本发明的技术方案进行详细、完整的描述,本文给出的只是本发明的一部分实施例。基于本发明中的实施例,如果研究者在没有获得创新性成果的情况下,得到的所有的其他实施例,全部都应该属于本发明的保护范围。
需要说明的是,本发明的说明书和权利要求书以及上述说明书中的术语“第一”、“第二”等是为了不用描述相似对象的先后顺序或者是先后次序,以及用来区别说明书中的相似对象。在这样使用的情况下,部分数据是可以相互互换的,便于描述或者图示意外的顺序的实施。除此之外,说明书中术语“包括”和“具有”以及他们的相似术语,清楚地说明了说明书中所列出的对这些过程、方法、产品以及设备固有属性的其他步骤。
如图1,2所示,本发明提供了一种基于生成对抗的面部表情识别方法,包含存在类内差距的面部表情识别的网络训练过程和离线识别过程。
作为实施方案,所述的离线识别过程,应该包含以下步骤:
步骤S11:通过网络下载、跳帧解析视频、采集输入图像x;
步骤S12:几何归一化处理所述输入图像x,并检测归一化处理后的图像x’;
步骤S13:处理所述检测裁剪后的图像x’到统一的尺寸;
步骤S14:构建基于生成对抗的面部表情识别的网络模型;
步骤S15:对图像x’进行数据增强和数据扩充处理,以及统一图像尺寸;
步骤S16:对所述网络模型进行训练并对训练后的网络模型进行存储;
在具体的实施方案中,步骤S12还应该包含以下步骤:
步骤S121:对所述输入图像进行几何归一化处理;所述的几何归一化方法包括尺度归一化、外头校正、扭脸校正;
步骤S122:通过OpenCV开源库中的人脸检测方法,对几何归一化后的图像进行人脸检测,然后对检测后的图像进行降噪处理;
S23:得到几何归一化后的图像x’。
作为一种优选的实施方式,步骤S23还要包含:
S131:根据所述的人脸的坐标确定图像的位置;
S132:使用OpenCV检测得到人脸图像;
S133:使用裁剪后的人脸图像调整为统一尺寸,将剪切后的人脸图像变为256*256大小。
更进一步,步骤S14还应该包含:S141:利用pytorch深度学习框架构建我们的IC-GAN神经网络,首先将图片输入到con_1层进行卷积操作,通过4*4的卷积核对输入图像进行卷积,输出为128*128*64;再采用LeakyReLu激活函数对卷积进行非线性操作,输出为128*128*64;所述LeakyReLu激活函数为:
S142:对上一层的输出继续使用4*4的卷积核进行卷积操作,输出为64*64*128,继而采用batchnorm层上对上一层的输出进行归一化操作,再采用LeakyReLu激活函数对卷积进行非线性操作,输出为64*64*128;
S143:对上一层的输出继续使用S142的方法进行卷积、batchnorm和LeakyReLu操作,输出为4*4*100;
S144:对S143的输出进行卷积核4*4的反转置卷积操作,输出为29*29*1,然后使用batchnorm进行批量归一化操作,再采用ReLu激活函数对输出进行非线性操作,输出为32*32*128;
S145:对上一层的输出再次进行S144所述的卷积、bathnorm和ReLu操作,输出为64*64*64;
S146:对上一层的输出使用ReLu激活函数进行非线性操作,再使用卷积核为4*4的反转置卷积对上一层进行卷积操作,然后使用Tanh激活函数进行非线性操作,输出为128*128*128;
S147:对上一层的输出再次进行S141-S143过程中的操作,输出为1*1*5;
S148:将原始图像和S147的输出一起输入到一个4*4的卷积层,进行卷积操作,然后使用非线性激活函数LeakyReLu进行非线性激活,输出为128*128*64;
S149:对上一层的输出使用4*4的卷积核对上一层的输出进行卷积操作,然后使用batchnorm进行批量归一化操作,再采用LeakyReLu非线性激活;
S1491:继续对上一层的输出采用S150的过程进行卷积、batchnorm以及非线性操作输出为4*4*1;
S1492:最后对上一层的输出采用Softmax,输出判别为真的概率。
S1493:将S147过程的的输出进行全连接操作,通过Softmax分类器最终实现训练出5种表情,所述5种表情为1=happy,2=abomination,3=neutral,4=anxious,5=surprise and fear,实现对面部表情的识别;
作为优选的实施方案,所述的IC-GAN网络,使用使用pytorch搭建网络,其中包括输入层、卷积层、激活函数、池化层、全连接层、BN层和输出层。
]作为优选的实施方案,卷积层前后的大小可以描述为如下公式:
卷积层的输入大小为:W
卷积层的输出大小为:
D
上述公式中,K为卷积核的个数,F为卷积核的大小,S为步长,P为边界填充。
作为优选的实施方式,作为本申请的一种混合表情数据集共有4455张图像共5种表情标签,1=happy,2=abomination,3=neutral,4=anxious,5=surprise and fear,本发明存在数据集赝本分布不均衡的问题,因此采用图像仿射变换、图像镜像变换、调整对比度和亮度等方式对数据集进行扩充,扩充之后的混合表情数据集数量如表1:
表1扩充后混合数据集各表情的数量
作为本申请的一种最优选的方法,步骤S15还应该包含:S151:根据网络结构以及实验特点,将网络损失loss定义为4部分;
S152:优化器选择Adam Optimizer,学习率设置为0.0002,训练样本分批次进行训练,每个批次选择16张图片进行训练,epoch分别设为100,200,300,400;
S153:在每次的训练中首先获得1个epoch的图片,接下来计算loss损失值,然后使用Adam优化器不断更新网络的参数,使网络的损失值最小。
更进一步,所述的S16还应该包含:S161:通过网络下载、跳帧解析视频、采集输入图像;
S162:对所述输入图像进行几何归一化处理、人脸检测、opencv处理和统一尺寸;
S163:将处理后的图像输入到训练好的IC-GAN网络模型中进行识别,最终输出每种表情的概率,概率最大的表情即为我们的网络想要识别的表情。
与现有技术相比,本发明的优点在于:
本发明提供的基于生成对抗的面部表情识别方法,通过与传统人工提取表情特征的方法相比,实现了自动对人脸表情特征的提取,相比于稍微早期的神经网络面部表情识别,本发明实现了识别率的提高,从而精确的进行表情识别。
作为本申请的一种实施例,讲过数据增强后的样本数共有4455张训练样本,411张测试样本,模型训练的想法是在将图片输入到网络进行训练之前,首先通过OpenCV开源代码将图像进行裁剪,其次将图像统一为256*256大小,然后将经过预处理后的图片作为网络的输入,训练IC-GAN网络模型。Softmax损失函数采用交叉熵损失函数,优化器采用AdamOptimizer,将学习率设为0.0002,将训练样本分批次进行训练,每个批次选择16张图片进行训练,epoch分别设为100,200,300,400。
作为本申请的一种优选的实施方式,识别过程应该包含以下步骤:
S21:通过网络下载、跳帧解析视频、采集输入图像I;
S22:然后所述的输入图像I输入所述训练后的网络模型;
S23:得到识别结果。
上述本发明实施例序号只是为了描述本发明,不表示任何实施例的好坏。
在本发明的实施例中,对各个实施例的叙述各有侧重点,如果某个实施例中的部分没有描述清晰,可以参考其他实施例中对应的描述;
在本申请所提供的几个实施例中,所描述的技术内容,可以通过其他的方式实现。以上所有的描述都仅仅是示意性的。
- 一种基于Intral-Class Gap GAN的面部表情识别方法
- 一种基于面部表情识别的自闭症儿童交流障碍辅助方法