一种基于SqueezeNet的农作物叶片病害识别方法
文献发布时间:2023-06-19 09:46:20
技术领域
本发明涉及农业植保领域,尤其涉及一种基于SqueezeNet的农作物叶片病害识别方法。
背景技术
准确识别农作物病害类别是农作物病害防治的前提,而农作物叶片病斑及其相关特征是判断农作物病害种类及其病害程度的重要依据。传统的农作物病害检测主要依靠人工现场观察判断,存在主观性强、工作强度大等不足。
利用现代信息技术对农作物病害种类进行诊断和识别是一种先进有效的手段。传统机器学习病害识别方法一般包含图像分割,特征提取和模式识别三个环节,如果不能准确的提取病斑底层特征并选择对分类贡献率较高的特征来进行分类,则分类性能会明显下降。与传统机器学习方法相比,深度学习是一种端到端的方法,它以原始数据为输入,以最终的任务为输出,经过层层抽取将原始数据逐层抽象为任务自身所需要的特征,避免了人为特征选取对分类性能的影响,也同时明显增强系统的识别性能。
目前卷积神经网络在农业工程相关领域已获得广泛应用。为了获得更好的性能,近年来网络层数不断增加,从7层的AlexNet到16层的VGGNet,再到22层的GoogleNet、152层的ResNet,更有上千层的ResNet和DenseNet等。但这些传统卷积神经网络识别系统存在模型参数大、模型运算量要求高的不足,简言之就是效率问题。
效率问题主要是模型的存储问题和模型计算量问题。首先,深层次网络需要保存大量权值参数,这对设备内存的要求较高;其次,在实际应用中往往是快速响应需求,为达到实用标准,要么提高处理器性能,要么减少计算量。只有解决CNN效率问题,才能让CNN走出实验室,更广泛的应用于日常生活当中。对此,通常的方法是进行模型压缩,即在已经训练好的模型上进行压缩,使得网络携带更少的网络参数,从而解决内存问题,同时可以解决计算速度问题。
相比于在已经训练好的模型上进行处理,轻量化模型设计则是另辟蹊径。轻量化模型设计的主要思想在于设计更高效的“网络计算方式”从而使网络参数及计算量减少的同时不过多损失网络的识别性能。
发明内容
发明的目的:本发明克服了传统卷积神经网络识别系统存在的模型参数量大、模型运算量要求高的不足,在经典SqueezeNet模型的基础上进行改进,提出一种基于SqueezeNet的农作物叶片病害识别方法。
技术方案:
本发明公开了一种基于SqueezeNet的农作物叶片病害识别方法,包括如下连续步骤:
1)收集各类不同农作物的不同种类叶片病害图像,对原始数据集进行增强和扩充,划分训练集和测试集;
2)从网络规模小型化和计算过程轻量化的角度出发,对经典SqueezeNet结构进行精简与参数修改,获取4种改进SqueezeNet模型;
3)训练参数设置,多次迭代后得到训练后的模型;
4)将测试图像输入训练后的模型中进行测试。
2、根据权利要求1所述的一种基于SqueezeNet的农作物叶片病害识别方法,其特征在于,所述1)中的4种改进SqueezeNet模型的获取包括如下步骤:
1)将经典SqueezeNet模型的卷积层10输出通道数从1000修改为需要进行分类识别的种类数量,获取改进后的基础模型;
2)获取第一种改进模型:删除1)中SqueezeNet模型8个fire模块中的最后面3个fire模块,修改此后最后一个fire模块的参数,即把该fire模块中squeeze层的输出通道数量作相应减少,同时把expand层的输出通道数量作相应增加,获取第一种改进后的模型;
3)在第一种改进模型的基础上,获取第二种改进模型:因为1×1的卷积运算量和参数量都是3×3卷积时的1/9,因此2)的基础上,将此时模型中所有fire模块的expand层中1×1和3×3的卷积核数目按3:1的比例重新分配,既减少参数数量,又同时大幅减少计算量,获取第二种改进后的模型;
4)在第二种改进模型的基础上,获取第三种改进模型:由于特征图的大小与深度学习架构的运算量有紧密关系,把fire模块2从最大池化层A、B之间移动到最大池化层B、C之间,相应计算量会显著减少,获取第三种改进后的模型;
5)在第三种改进模型的基础上,获取第四种改进模型:由于特征图的大小与深度学习架构的运算量有紧密关系,把fire模块3、4从最大池化层B、C之间移动到最大池化层C后面,相应计算量又会显著减少,获取第四种改进后的模型。
本发明设计的一种基于SqueezeNet的农作物叶片病害识别方法与现有技术相比,其优点在于:
1)针对传统卷积神经网络识别系统存在模型参数大、模型运算量要求高的不足,本发明提出以经典轻量级卷积神经网络SqueezeNet作为模型的基础架构进行作物病害识别,其本身已经是一种轻量且高效的卷积神经网络模型;
2)从进一步实现网络规模小型化和计算过程轻量化的角度出发,本发明对经典SqueezeNet结构进行精简与参数修改,获取4种改进后的SqueezeNet模型;
3)本发明所提出的4种改进模型在显著减少模型参数内存需求和模型计算量的同时使模型性能保持在一个较高的水平,较好地平衡了这三项指标,更加有利于将改进后的模型部署在移动终端等嵌入式资源受限设备上,有助于实现对农作物病害的实时准确识别。
附图说明
图1是经典SqueezeNet结构图;
图2是经典SqueezeNet中fire模块内部结构图;
图3是本发明的改进后的基础模型结构图;
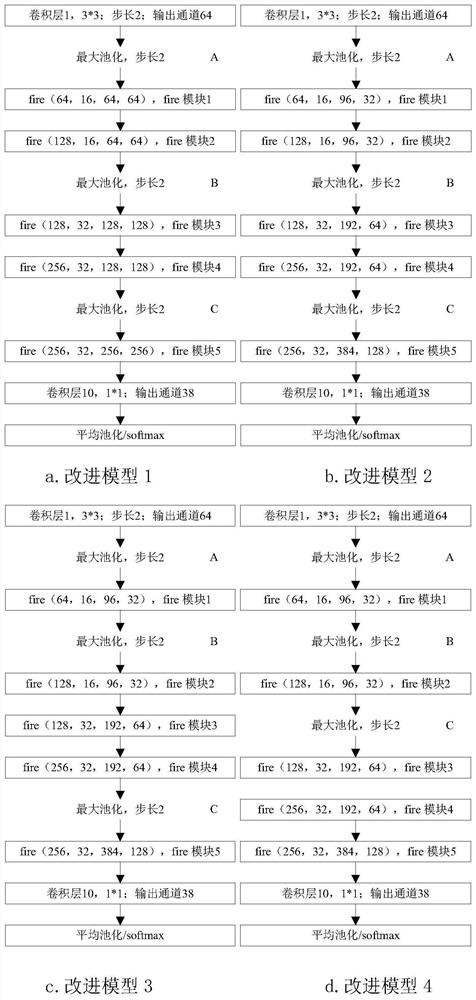
图4是本发明的改进的SqueezeNet模型1、2、3、4结构图;
具体实施方式
下面结合附图并以PlantVillage工程提供的叶片图像数据为例,对本发明的技术内容进行详细阐述。
以PlantVillage工程开源数据库(www.plantvillage.org)所收集的26类病害叶片及12类健康叶片共38类叶片合计54306张叶片图像作为实验数据,考虑到各类样本数量不均衡问题,在经过欠采样和数据增强(水平镜像翻转、改变亮度、加噪声等)后,使得各类叶片的样本数量大致均衡,总数增加到73327张,随机选取其中的80%作为训练集,20%作为测试集。
如图1所示,经典SqueezeNet结构包含两个普通的卷积层和8个fire模块。
输入图片大小为224×224像素,第一个卷积层使用3×3的卷积核,步长为2,输出通道为64。通过第一个卷积层后,特征图大小为112×112像素。经典SqueezeNet结构中共有三个最大池化层分别表标识为池化层A、B和C,每通过一个池化层,图像的大小就变为原来的一半以减少计算量。最大池化层A、B之间及B、C之间各有2个fire模块。最大池化层C后连接4个fire模块。卷积层10采用1×1的卷积核,输入通道为512,输出通道为1000,输出特征图大小为14×14像素。卷积层10的输出采用全局平均池化,并通过softmax分类器计算得到1000种分类的概率。其中全局平均池化是指将每个输出通道特征图的所有值融合为一个平均值,使得该层输出特征维数等于该层的输出通道数。
如图2所示,SqueezeNet的核心在于fire模块,它由两部分构成,分别是squeeze层和expand层。通常定义一个fire模块为fire(M,N,E1,E2),其中M代表fire模块的输入通道数,N代表squeeze层的输出通道数,E1和E2分别代表expand层中1×1卷积核和3×3卷积核的输出通道数目。squeeze层是一个卷积核为1×1的卷积层,它把输入通道从M变到N,通常N小于M,squeeze层主要用来对输入通道进行压缩,以减少网络的计算量;expand层是包含1×1和3×3两种卷积核的卷积层,1×1卷积核、3×3卷积核分别将输入通道从N扩张成E1与E2,最后把1×1和3×3得到的特征图进行拼接,得到输出通道为(E1+E2)的特征图。
如图3所示,PlantVillage工程需要识别26类病害及12类健康叶片,两者合计38类,因此将图1中卷积层10的输出通道数从1000修改为38,将此仅修改了卷积层10参数的模型标识为改进后的基础模型。
如图4所示,注意到经典SqueezeNet模型是为对ImageNet数据库进行分类的,该数据库包含了1000类物体,而PlantVillage工程提供的叶片图像只有38类,对于这样相对简单些的任务并不需要很深的网络结构,因此,本发明对基础改进模型做如下修改:移除fire模块6、7和8,并把fire模块5的参数修改为fire(256,32,256,256),即把该模块中squeeze层的输出通道由48减少为32,同时把expand层的输出通道由192增加为256,修改后的网络结构如图4a所示,并将其标识为改进模型1。
如图4所示,注意到3×3的卷积核共有9个参数,进行一次卷积需要进行9次浮点乘法和1次浮点加法运算。而1×1的卷积核只有1个参数,进行一次卷积运算只需要进行1次浮点乘法运算,所以1×1的卷积运算量和参数量比3×3卷积时大幅度减少。改进模型1中所有fire模块的expand层中1×1和3×3的卷积核数目比例是1:1,改进模型2就是把所有fire模块的expand层中1×1和3×3的卷积核数目按3:1的比例重新分配,图4b显示了改进模型2的架构。
如图4所示,注意到改进模型2中共有5个fire模块。其中最大池化层A、B中间有2个fire模块,最大池化层B、C中间有2个fire模块,最后一个fire模块位于最大池化层C和卷积层10之间。原始图片大小为224×224像素,通过第一个卷积层后,特征图大小为112×112像素;通过最大池化层A后,特征图大小变为56×56像素;通过最大池化层B后,特征图大小变为28×28像素;通过最大池化层C后,特征图大小变为14×14像素。
如图4所示,很显然,特征图的大小与深度学习架构的运算量有着紧密的关系。对fire模块2即fire(128,16,96,32),如果把它从最大池化层A、B之间移动到最大池化层B、C之间,相应计算量会显著减少。基于此思想,在改进模型2的基础上,把fire模块2从最大池化层A、B之间移动到最大池化层B、C之间,提出改进模型3;在改进模型3的基础上,把把fire模块3、4从最大池化层B、C之间移动到最大池化层C之后,提出改进模型4。其结构如图4c、4d所示。
实验软件环境为Ubuntu 16.04LTS 64位系统,采用目前流行的PyTorch(https://pytorch.org/)深度学习开源框架。PyTorch是一个基于Torch的Python开源机器学习库,它主要由Facebook的人工智能小组开发,不仅能够实现强大的GPU加速,同时还支持动态神经网络。计算机内存为16GB,搭载Intel Core i5-8300 CPU,GPU采用英伟达的GTX1050Ti对深度学习模型进行加速。
采用批处理方法将训练数据与测试数据分为多个批次,训练数据和测试数据的批次大小都设置为32,即每个批次训练32张图片,遍历一次训练集中的所有图片称作一次迭代。训练时采用了迁移学习的技术,模型收敛速度很快,因而每个模型都只迭代了30次,训练模型时采用了随机梯度下降优化算法。为了防止过拟合采用了随机失活技术,其参数p设置为0.5;初始学习率设置为0.01,学习率更新策略为每7次迭代学习率减小为原来的0.1倍。训练具体采用anaconda环境,框架是pytorch10,训练30个epoch,每个epoch有3666次迭代。
最终测试集上的测试结果如表1所示:
表1改进模型的参数及性能
由表1可以看出,本发明提出的改进模型1~4均表现较为优异,在显著减少模型参数内存需求和模型计算量的同时使模型性能保持在一个较高的水平,较好地平衡了这三项指标,适合未来将模型部署在移动终端等嵌入式资源受限设备上,有助于实现对农作物病害的实时准确识别。
表1中后三项技术指标解释如下:
常用混淆矩阵定义的中变量定义:
TP(true positive):真实值为正且预测也为正的数量;
TN(true negative):真实值为负且预测也为负的数量;
FP(false positive):真实值为负但预测为正的数量;
FN(false negative):真实值为正但预测为负的数量。
查准率(Precision)定义如下:
查准率是分类器预测的正样本中预测正确的比例,取值范围为[0,1],取值越大表示模型预测能力越好。
查全率(recall)定义如下;
查全率是分类器预测正确的正样本占所有正样本的比例,取值范围为[0,1],取值越大模型预测能力越好。
准确率(accuracy)定义如下:
准确率是最常见的评价指标,是分类正确样本除以所有样本的总数。在正、负样本不平衡的情况下,准确率这个评价指标有很大的缺陷,因此需要综合的运用查准率、查全率和准确率这三个指标对算法模型进行科学和全面的评价。
本发明的技术内容及技术特征已揭示如上,然而熟悉本领域的技术人员仍可能基于本发明的教示及揭示而作种种不背离本发明精神的替换及修饰,因此,本发明保护范围应不限于实施例所揭示的内容,而应包括各种不背离本发明的替换及修饰,并为本专利申请权利要求所涵盖。
- 一种基于SqueezeNet的农作物叶片病害识别方法
- 一种基于多阶段训练的农作物病害长尾图像识别方法