一种基于跨域深度卷积神经网络的视觉目标跟踪方法
文献发布时间:2023-06-19 10:08:35
技术领域
本发明属于计算机视觉技术领域,具体涉及一种视觉目标跟踪方法。
背景技术
视觉目标跟踪是计算机视觉中最关键的组成部分之一,已广泛应用于智能交通监控、行为分析、视觉引导等众多领域。近年来,受图像分类和物体检测的启发,深度卷积神经网络(CNN)已被广泛用于视觉目标跟踪任务。深度卷积神经网络具有的深度、多隐藏层结构以及权值共享网络,能够减少权值数量,并极大提高网络的学习能力。
杨大伟,巩欣飞,毛琳,张汝波(《重构特征联合的多域卷积神经网络跟踪算法》,激光与光电子学进展,2019,56(19):165-173)针对已有的基于卷积神经网络的目标跟踪网络模型中存在的特征稳健性差以及目标背景信息丢失导致跟踪失败的问题,提出一种基于重构特征联合的多域卷积神经网络视觉跟踪算法。将网络末端卷积层提取的深层目标特征,通过反卷积操作上采样,获得了包含目标背景信息的重构特征,再通过联合目标高级特征和背景信息的重构特征的方式增强特征的稳健性,达到了有效区分目标和背景的目的。但该网络模型在训练阶段针对每个网络分支,仅利用单个域的正负样本进行训练,导致模型泛化性有限。此外,在在线跟踪阶段,该算法使用在线训练的回归器进行目标边界框回归,使得训练样本不足,回归精度较低。
发明内容
为了克服现有技术的不足,本发明提供了一种基于跨域深度卷积神经网络的视觉目标跟踪方法,首先在VGG网络架构基础上构建深度卷积神经网络模型,只保留VGG网络架构前三个卷积层Conv1-Conv3和两个全连接层FC4-FC5,在第二个全连接层FC5之后连接多域全连接层;然后随机取出1个训练集序列,构建正样本、负样本和难例负样本对网络模型进行训练,当达到预先设定的训练次数时结束训练,即得到最终用于目标跟踪的深度卷积神经网络模型。本方法充分利用跨域的信息进行离线训练,提高了模型对于目标和背景的分辨力,并通过多任务学习显著提高视觉目标跟踪的精度。
本发明解决其技术问题所采用的技术方案包括以下步骤:
步骤1:构建深度卷积神经网络模型;
采用VGG网络架构,只保留VGG网络架构的前三个卷积层Conv1-Conv3和两个全连接层FC4-FC5,在第二个全连接层FC5之后连接多域全连接层;
多域全连接层的每个域对应于一个训练序列中的单个目标,并由一个用于区分目标和背景的二值分类层和一个用于定位的边界框回归层组成;多域全连接层的层数N
步骤2:在N
步骤3:将N
其中,P
步骤4:在每个mini-batch结束后重复步骤2到步骤3,直到达到预先设定的训练次数N
步骤5:利用步骤1到步骤4训练的深度卷积神经网络模型进行在线目标跟踪;
步骤5-1给定序列图像I
步骤5-2:确定检测精度P,P的取值范围为(b
步骤5-3:第二帧及后续的每一帧中,以上一帧目标的位置为中心,选取N
优选地,所述a
优选地,所述b
本发明的有益效果是:本发明的一种基于跨域深度卷积神经网络的视觉目标跟踪方法充分利用跨域的信息进行离线训练,提高了模型对于目标和背景的分辨力,并通过多任务学习显著提高视觉目标跟踪的精度。
附图说明
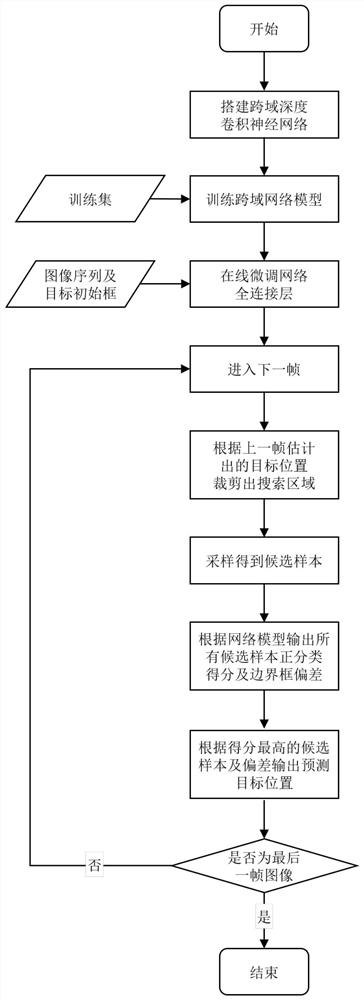
图1是本发明方法流程图。
图2是本发明方法网络结构图。
图3是本发明实施例测试结果图。
具体实施方式
下面结合附图和实施例对本发明进一步说明。
已有的基于卷积神经网络的视觉目标跟踪算法在离线训练时大多只试图区分单个域中的目标和背景,对不同域中,特别是当前景对象属于同一语义类或具有相似外观时的前景对象的区分并不强大。本发明针对这一问题,设计了基于卷积神经网络的新型视觉目标跟踪模型,不仅利用单个域中的目标和背景信息,而且充分利用跨域的信息进行离线训练,提高模型对于目标和背景的分辨力,并通过多任务学习同时训练分类和回归模型,从而提高跟踪精度。
如图1所示,一种基于跨域深度卷积神经网络的视觉目标跟踪方法,包括以下步骤:
步骤1:构建深度卷积神经网络模型;
采用VGG网络架构,只保留前三个卷积层Conv1-Conv3和两个全连接层FC4-FC5,在第二个全连接层FC5之后连接多域全连接层;
多域全连接层的每个域对应于一个训练序列中的单个目标,并由一个用于区分目标和背景的二值分类层和一个用于定位的边界框回归层组成;多域全连接层的层数N
步骤2:在N
步骤3:将N
其中,P
步骤4:在每个mini-batch结束后重复步骤2到步骤3,直到达到预先设定的训练次数N
步骤5:利用步骤1到步骤4训练的深度卷积神经网络模型进行在线目标跟踪;
步骤5-1给定序列图像I
步骤5-2:确定检测精度P,P的取值范围为(0,1);对序列图像I
步骤5-3:第二帧及后续的每一帧中,以上一帧目标的位置为中心,选取N
具体实施例:
1、搭建深度跨域卷积神经网络模型,具体过程如下:
加载VGG网络,输入为107×107×3的图像,通过96个7×7的卷积核(Conv1)提取较大尺度的特征信息,经过最大池化层后,再分别通过256个3×3卷积核(Conv2)以及512个3×3卷积核(Conv3)构成的卷积层经过进一步特征提取后由两层512个神经元组成的全连接层(FC4-FC5)将特征进行加权求和,最后输入多域全连接层,每个域对应于一个训练序列中的单个目标,并由一个用于区分目标和背景的二值分类层(FC6-cls)和一个用于定位的边界框回归层组成(FC6-reg)。多域全连接层的层数N
2、搭建深度卷积神经网络模型对单个域以及跨域信息进行训练,具体过程如下:
(1)依照图2构建深度神经网络模型,用随机数初始化所有的滤波器、参数及权重。
(2)在N
t
其中,(x,y,w,h)和(x
(3)将步骤(2)中N
其中,P
其中,y
回归损失L
其中,t和b分别表示网络输出和真实的边界框偏移量。
(4)在每个mini-batch结束后重复步骤(2)~(3),直到达到预先设定的训练次数N
3、利用步骤2训练得到的网络模型进行在线目标跟踪,具体过程如下:
(1)给定序列图像I
(2)确定检测精度P,P的取值范围为(0,1)。对[I
(3)在第二帧及后续的每一帧中,以上一帧目标的位置为中心,选取N
如图3所示,是采用本发明模型进行测试的结果,能够看到,本发明对目标取得了很好的跟踪结果。
- 一种基于跨域深度卷积神经网络的视觉目标跟踪方法
- 一种基于深度特征融合卷积神经网络的综合式目标跟踪方法