一种基于对偶生成对抗网络的模仿化妆图像虚拟卸妆方法
文献发布时间:2023-06-19 10:29:05
技术领域
本发明涉及图像处理技术领域,特别是指一种基于对偶生成对抗网络的模仿化妆图像虚拟卸妆方法。
背景技术
爱美之心,人皆有心。随着人们生活质量的提升,越来越多的人注重自己的外在,希望通过化妆带来形象上的提升。但化妆给人自信的同时,也给人们的生活带来一些不便,其中包括人脸认证系统的识别性能下降。
近年来,深度学习技术的发展使得人脸认证系统的识别率有了突飞猛进的提高,因此在人机交互、信用卡验证、门禁系统等实际场景,人脸识别技术得到了越来越多的应用,例如,2015年3月举办的德国CeBIT大会开幕式上,马云演示了刷脸支付技术,并成功刷脸购物;从2017年开始国内各火车站已陆续实现刷脸身份识别,另一方面目前大多数手机都已支持人脸解锁,提高了用户体验。目前,人脸识别产品已广泛应用于金融、安检、工厂及网络应用等领域。随着技术的进一步成熟和社会认同度的提高,人脸识别技术将应用在更多的领域。
然而越来越普遍的化妆行为对人们的面部特征影响较大,妆后人脸在很大程度上不同于本来面部信息,如图1所示,给基于人脸的身份认证系统带来了较大的挑战,造成识别错误或者拒识。此种情况下让用户当场卸妆会造成用户体验度的急剧下降,在操作和效率上也极不现实。
因此考虑采用对带妆人脸图像进行处理得到用户素颜照从而进行人脸识别方式,来完成此情况下的用户身份信息核对。目前对人脸图像进行处理的技术在人们日常生活中发挥着较大的作用,近年来,研究者们开始探索人脸图像的数字化妆技术,出现一些专业软件可以对人脸进行虚拟化妆或试妆,在电子商务、社交网络等领域应用较为广泛。
而针对化妆的逆过程——卸妆,最近也受到越来越多的关注。2016年,Wang S等人提出探索化妆背后的人脸信息,首先检测有可能化妆的部位,然后对局部区域进行卸妆处理。该方法取得一定效果的同时,具有一些局限性,它将化妆和卸妆看作两个独立的过程。实际上,理想的化妆和卸妆算法应该具有可逆性,该性能可有效地被利用于算法的设计和训练上。2017年,Chen Y C等人提出元素回归网络,在不知道美颜具体操作的情况下将美颜后的照片进行还原。遗憾的是,该方法在化妆风格改变或者过度化妆时不能有效工作。2018年,Chang H.等人提出非对称风格转换的思想,将素颜照人脸迁移到指定化妆风格的美妆照,同时也能将美妆人脸进行卸妆。该方法取得了较好的化妆效果,且能进行不同化妆风格的迁移,但卸妆算法需要有化妆风格图做输入,限制了应用场景。
目前已有的人脸图像虚拟卸妆工作主要集中在美颜化妆上,对模仿化妆的卸妆方法研究较少。模仿化妆是指化妆者选定另一个人作为模仿对象,通过化妆使自己看起来和被模仿者相似,如图2所示。可以看出,模仿化妆和美颜化妆在成像特性上有较大的区别,因此在虚拟卸妆方法上应该被区别对待。因此,设计合理的方法对模仿化妆的人脸图像进行虚拟卸妆,得到用户的本来面部信息从而顺利进行身份认证,具有重大的研究意义和社会价值。
发明内容
针对上述背景技术中存在的不足,本发明提出了一种基于对偶生成对抗网络的模仿化妆图像虚拟卸妆方法,解决了现有模拟化妆受模仿者和被模仿者的面部信息的影响,造成卸妆效果差的技术问题。
本发明的技术方案是这样实现的:
一种基于对偶生成对抗网络的模仿化妆图像虚拟卸妆方法,其步骤如下:
步骤一:采集M组数据作为数据集,并对数据集中的每组数据进行预处理,其中,每组数据包括模仿者的化妆人脸图像、模仿对象的人脸图像和模仿者的素颜图像;
步骤二:将模仿者的化妆人脸图像和模仿对象的人脸图像合并为n×n×6的第一输入矩阵,并将第一输入矩阵输入卸妆生成器网络,生成素颜图像,其中n表示输入图像的宽度或高度;
步骤三:将模仿者的素颜图像和模仿对象的人脸图像合并为n×n×6的第二输入矩阵,并将第二输入矩阵输入化妆生成器网络,生成化妆图像;
步骤四:将步骤二的素颜图像和步骤三的化妆图像分别输入判别器网络,并计算判别器网络的损失函数,根据损失函数调整卸妆生成器网络和化妆生成器网络的网络参数;
步骤五:循环执行步骤二至步骤四,直至损失函数的值不变,得到卸妆生成器和化妆生成器;
步骤六:采集用户的化妆人脸图像和被模仿者的人脸图像作为测试集,并对测试集进行预处理后输入步骤五中的卸妆生成器,得到用户的素颜图像。
对数据集或测试集进行预处理的方法为:将人脸图像的两眼之间的距离作为半径d,以人脸图像的两眼中间点为中心,分别向左、右、上、下截取1.5d、1.5d、d、2d的区域对应的人脸图像,完成人脸图像的预处理。
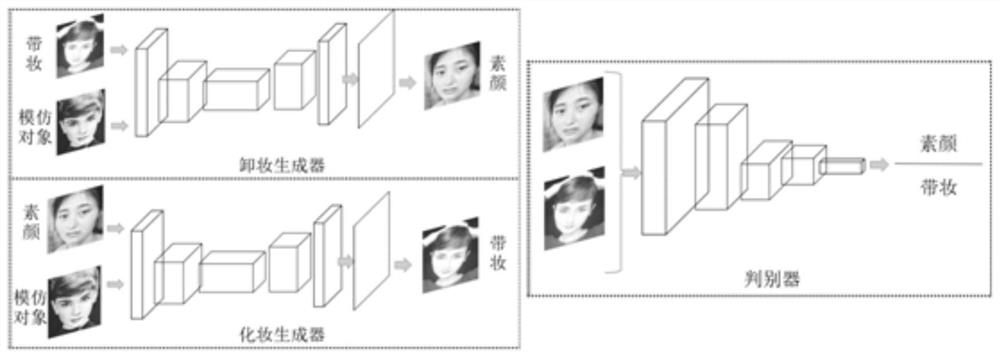
所述卸妆生成器网络和化妆生成器网络的网络结构相同,均包括输入层、第一卷积层、第二卷积层、第一反卷积层、第二反卷积层和输出层,输入层与第一卷积层相连接,第一卷积层与第二卷积层相连接,第二卷积层与第一反卷积层相连接,第一反卷积层与第二反卷积层相连接,第二反卷积层与输出层相连接。
所述判别器网络为CNN网络。
所述判别器的损失函数为:
l
其中,x为判别器的输入图像,D(x)为判别器判断为素颜的概率,p
当输入图像x为化妆图像时,p
与现有技术相比,本发明具有以下有益效果:
1)准确模拟模仿化妆的成像原理:在模仿化妆中,以模仿者的素颜照为出发点、被模仿者的面部特点为化妆行为的目的点,具有明确的引导性。
2)具有较好的卸妆效果:本发明将模仿图像和被模仿者人脸图像同时作为卸妆器的输入,因此具有较好的卸妆效果。
3)作为训练卸妆生成器的副产品,可得到相对应的化妆生成器:本发明采用对偶生成对抗网络,同时设计卸妆生成器、化妆生成器、判别器三个子网络,将卸妆生成器的输出素颜照片输入化妆生成器生成化妆效果图,和原始化妆图像比较。通过训练,不仅得到卸妆生成器,还可获得相应的化妆生成器,根据不同的被模仿者照片得出不同的化妆效果,可用于多人脸融合或人脸化妆风格的试妆。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为化妆对面部信息的改变的示意图。
图2为模仿化妆的示例图。
图3为本发明的模仿化妆的成像原理图。
图4为本发明的流程图。
图5为本发明的卸妆/化妆生成器的网络结构图。
图6为本发明的判别器网络结构图。
图7为本发明的图像预处理的对齐方式示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有付出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
模仿化妆有其独特的特性,比如具有明确的目的性,如图3所示,其中模仿者素颜照为成像的起点,被模仿者面部特征为化妆的目的点,模仿化妆的过程为成像从模仿者素颜照逐渐靠近被模仿者的过程,因此最后化妆效果同时受模仿者和被模仿者面部特征的影响。作为化妆的逆过程,本发明采用的卸妆方法同时考虑了模仿者和被模仿者的人脸信息,将其同时输入卸妆器进行虚拟卸妆。
因此,本发明实施例提供了一种基于对偶生成对抗网络的模仿化妆图像虚拟卸妆方法,采用如图4所示的基于对偶生成对抗网络(Generative Adversarial Networks,GAN)的虚拟卸妆方法,本发明中对偶生成对抗网络包含三个主要部分,分别是:a)卸妆生成器,b)化妆生成器,c)判别器。其中卸妆生成器用来完成人脸图像的卸妆功能,化妆生成器和判别器用于辅助卸妆生成器的训练。对模仿化妆的人脸图像进行卸妆时,由系统摄像头获取包含待认证人脸的图像,并从系统数据库中调取或由用户提供相应模仿对象的人脸图像,将带妆人脸图像和模仿对象图像成对输入卸妆生成器,得到用户的卸妆后照片。具体步骤如下:
步骤一:采集M组数据作为数据集,并对数据集中的每组数据进行预处理,其中,每组数据包括模仿者的化妆人脸图像、模仿对象的人脸图像和模仿者的素颜图像;
为了得到更好的图像比对和卸妆效果,在进入网络之前需要对图像进行预处理,包括人脸检测、人脸对齐等。如图7所示,对图像进行预处理的方法为:将人脸图像的两眼之间的距离作为半径d,以人脸图像的两眼中间点为中心,分别向左、右、上、下截取1.5d、1.5d、d、2d的区域对应的人脸图像,作为卸妆生成器的输入,完成人脸图像的预处理。
步骤二:将模仿者的化妆人脸图像和模仿对象的人脸图像合并为n×n×6的第一输入矩阵,并将第一输入矩阵输入卸妆生成器网络,生成素颜图像;
步骤三:将模仿者的素颜图像和模仿对象的人脸图像合并为n×n×6的第二输入矩阵,并将第二输入矩阵输入化妆生成器网络,生成化妆图像;
本发明采用生成对抗网络完成模仿化妆人脸图像的卸妆。所述卸妆生成器网络和化妆生成器网络的网络结构相同,网络结构如图5所示,包括输入层、第一卷积层、第二卷积层、第一反卷积层、第二反卷积层和输出层,输入层与第一卷积层相连接,第一卷积层与第二卷积层相连接,第二卷积层与第一反卷积层相连接,第一反卷积层与第二反卷积层相连接,第二反卷积层与输出层相连接。
首先将化妆人脸图像和被模仿者的人脸图像合并为n×n×6的输入矩阵,其中n表示输入图像的宽和高,即每行包含n个像素,每列包含n个像素。因为每个彩色图像包含RGB三个分量,因此两个图像合并为6个分量,即n×n×6的矩阵。然后经过两次卷积之后得到特征图,然后再经过两次反卷积处理得到生成的模仿者的素颜图像。其中神经元的激活函数使用ReLU函数。输入设置为128×128的RGB彩色图像,网络输出128×128的RGB彩色图像。
首先将素颜图像和被模仿者的人脸图像合并为n×n×6的输入矩阵,其中n表示输入图像的宽和高,即每行包含n个像素,每列包含n个像素。因为每个彩色图像包含RGB三个分量,因此两个图像合并为6个分量,即n×n×6的矩阵。然后经过两次卷积之后得到特征图,然后再经过两次反卷积处理得到化妆图像。
步骤四:将步骤二的素颜图像和步骤三的化妆图像分别输入判别器网络,并计算判别器网络的损失函数,根据损失函数调整卸妆生成器网络和化妆生成器网络的网络参数;本发明采用的判别器为CNN结构,如图6所示。判别器网络由4个卷积层、1个全连接层和一个softmax层组成,其中前三层卷积层后加pooling层,图中矩形的边长表示feature map及滤波器的大小,矩形的个数表示feature map的个数。输入为128×128的RGB彩色图像,输出为两类分类结果,分别是素颜或化妆。
GAN在训练的过程中需要设置合理的损失函数,本发明中生成器采用的损失函数如下式所示:
l
其中,
此外基于两个生成器的对偶性设计对偶损失l
所述判别器的损失函数为:
l
其中,x为判别器的输入图像,D(x)为判别器判断为素颜的概率,p
当输入图像x为化妆图像时,p
步骤五:循环执行步骤二至步骤四,直至损失函数的值不变,得到卸妆生成器和化妆生成器;
步骤六:采集用户的化妆人脸图像和被模仿者的人脸图像作为测试集,并对测试集进行预处理后输入步骤五中的卸妆生成器,得到用户的素颜图像。
通过第一阶段的训练,网络模型已经学习到对模仿化妆图像进行卸妆的能力,可以作为卸妆器实现卸妆功能,具体为:系统采集用户的带妆图像,并从数据库中调取或者由用户提供被模仿者的人脸图像,对两张图像进行人脸检测和对齐(操作方法与步骤一相同),并将尺寸调整为128×128×3大小。然后将两张图像合并为128×128×6的矩阵,输入图4中的卸妆生成器,得到用户的素颜图像,完成卸妆功能。
本发明达到的效果为:1)本发明能够准确模拟模仿化妆的成像原理:以往对化妆图像进行虚拟卸妆的方法没能单独考虑模仿化妆的行为类型,因此对模仿化妆的卸妆效果欠佳。在模仿化妆中,以模仿者的素颜照为出发点、被模仿者的面部特点为化妆行为的目的点,具有明确的引导性。2)具有较好的卸妆效果:模仿化妆的效果受模仿者和被模仿者的面部信息的影响,因此良好的针对模仿化妆的卸妆算法应同时考虑模仿者和被模仿者的面部信息,本发明将模仿图像和被模仿者人脸图像同时作为卸妆器的输入,因此具有较好的卸妆效果。3)作为训练卸妆生成器的副产品,可得到相对应的化妆生成器:本发明采用对偶生成对抗网络,同时设计卸妆生成器、化妆生成器、判别器三个子网络,将卸妆生成器的输出素颜照片输入化妆生成器生成化妆效果图,和原始化妆图像比较。因此通过训练,不仅得到卸妆器,还可获得相应的化妆生成器,根据不同的被模仿者照片得出不同的化妆效果,可用于多人脸融合或人脸化妆风格的试妆。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种基于对偶生成对抗网络的模仿化妆图像虚拟卸妆方法
- 一种基于对偶距离损失的生成对抗网络训练方法