用于传感器数据中改善的对象标记的方法和系统
文献发布时间:2023-06-19 10:32:14
技术领域
本发明涉及用于传感器数据中的对象标记的一种方法以及一种系统。
背景技术
在机器学习领域中,通常使用可能包含例如图像数据和/或视频数据的训练数据集,以便例如在这样的或类似的数据中学习自动对象识别。这种自动对象识别的一个示范性的使用可以是例如自主驾驶运行或飞行运行,以便识别车辆周围环境的对象。为了在此保证可靠的对象识别,可能需要大量的训练数据集。
通常,在(训练)数据集中,将辨识出的对象分类、标记或标明,并形成可以进行机器处理以用于机器学习的对象-标签对。例如,在检测到交通情况的场景的数据集中,道路走向可以作为对象设有标记,该标记将该道路走向标明或分类为道路走向。尤其是这类图像注释和视频注释的产生(即图像数据集和视频数据集中的对象标记)可能是成本密集的,因为这完全不能自动化或仅能非常有限地自动化。因此,这种图像注释和视频注释主要由人工处理者执行,由此,例如对所记录的图像进行注释以用于语义分割可能平均持续一个多小时。
发明内容
因此,本发明的任务是提供一种用于以简化的或更加成本有利的方式提供包含对象标记或注释的数据的可能性。
该任务通过根据独立权利要求的用于传感器数据中的对象标记的一种方法和一种系统来解决。本发明的有利扩展方案由从属权利要求、说明书以及附图得出。
用于传感器数据中的对象标记的这类方法尤其可以用于产生用于机器学习的一个或多个训练数据集。该方法具有以下步骤:
-首先,通过至少一个传感器检测第一状态中的场景。场景可以是例如车辆周围环境、道路图像、道路走向、交通情况等,并且可以包括静态的和/或动态的对象,例如交通区域、建筑物、交通参与者等。传感器可以是诸如摄像机、激光雷达传感器之类的单个的光学传感器,或者可以包括这类或类似传感器的融合。
-在包含第一状态中的场景的第一数据集中,将第一对象标记(例如第一注释)分配给包含在场景中的至少一个对象。第一数据集可以包含呈现处于其第一状态中的场景的图像或图像序列,即例如包含道路走向的图像。第一对象标记可以例如围绕、填充、标注或以其他方式、但优选以光学的方式标识对象。因此,仅示范性地,可以以机器可读的方式追踪道路走向。换句话说,对象和对象标记可以形成例如在机器学习中可处理的对象-标签对。可以将对象标记分配给确定的对象类别,例如道路、树木、建筑物、交通标志、行人等。
-此外,通过至少一个传感器检测不同于第一状态的第二状态中的类似的或至少基本一致的场景。在最简单的情况下,这可能意味着,例如,至少两次驶过道路并且在此通过传感器检测所述道路,其中,在这种情况下,例如,不同的时间将第一状态和第二状态区分开。如上所述,第一状态中的场景的一个或多个对象已经标记,即例如道路走向。
-然后,针对在场景的第二状态中(再)识别出的对象,至少部分地采纳包含在第一数据集中的第一对象标记作为第二数据集中的第二对象标记。直观地考虑,在上面所提及的道路走向的示例中,该道路走向可能已经被追踪到。显然,原则上,可以以任意多的数据集和/或状态重复该方法。
借助该方法,能够降低包含对象标记或注释的数据的提供成本。因此,对于第二(第三、第四等)数据集,至少不必再次完全重新创建所有的对象标记。相反,该开销仅须进行一次,其中,然后,能够由此推导出第二数据集。直观地考虑,可以在一个或多个其他状态中重新检测待检测的地点(对于该地点的图像内容,已经存在注释),其中,注释的开销仅在最初时进行。如果为了通过机器学习训练一个功能而应在日间和在夜间检测地点,则在这种情况下,例如仅在日间场景中放置对象标记并采纳该对象标记用于夜间场景将是足够的。因此,可以基于现有的对象-标签对产生大量训练数据,而不分别产生用于注释的成本。
一种扩展方案设置,为了识别第二数据集中的场景,将场景的地点信息分配给第一数据集。地点信息例如可以通过合适的传感器(例如通过GPS等)提供。由此能够更容易地再识别场景或者说更容易地将数据集分配给确定的场景。
根据另一扩展方案,也可以融合传感器数据,以便提供地点信息。例如,这可以基于GPS和(例如呈摄像机等的校准数据形式的)摄像机本征(Kamera-Intrinsik)的组合。还能够考虑车辆的自身运动数据。由此更进一步改善再识别。
另一扩展方案设置,为了识别第二数据集中的场景,将场景的视角信息和/或位姿信息分配给第一数据集。除了地点信息的分配之外,这也可以进行,并且可以例如基于车辆的自身运动数据、通过GPS数据、摄像机本征等进行。由此更进一步改善再识别。
根据一种扩展方案,例如可以单目地、通过立体深度估计、光流估计和/或基于激光雷达数据对已经具有第一对象标记的图像执行深度预测,即基于第一数据集执行深度预测。还可以对未知图像(即第二数据集)中的语义分割执行预测。
一种扩展方案设置,变换对象标记或者说标签,以便对象标记更精确地匹配于第二数据集的新图像。该变换也称为扭曲(warping)。
根据另一扩展方案,可以使用SLAM(Simultaneous Localization And Mapping,同步定位和制图)方法,以便获得更好的地点和位姿确定。
如果第一对象标记的采纳至少部分自动化地通过人工智能模块(简称KI模块)进行,则可以特别显著地降低用于对象标记或注释的开销。人工智能模块可以具有至少一个处理器,并且例如通过程序指令而设置为用于模拟类人的决策结构,以便独立地解决问题,在此例如自动的对象标记或注释。
对于该方法的特别高的性能,已经证实为有利的是,KI模块的至少一个人工神经网络确定第一和第二数据集中的场景的一致的图像区域,该至少一个人工神经网络可以多层地和/或卷积地构型。
一种扩展方案设置,人工神经网络可以提供逐像素的一致性掩膜
为了节省更多成本,可以通过第一和/或第二数据集来训练KI模块,为此,可以将第一和/或第二数据集作为训练数据集提供给KI模块。
根据另一扩展方案,可以优选地通过SLAM方法确定在第一状态与第二状态之间场景的至少一个区分特征,并且将第二对象标记分配给该区分特征。这至少在以下情况下是可能的:区分特征(例如差异等级(Differenzklasse))已经具有足够良好的质量(例如具有高置信度的统计测试),并且对于场景的其余图像内容而言比较网络显示出一致性。然后,例如可以提供自动采纳对象标记(即注释)的选项。换句话说,例如基于上面所提及的或另一人工神经网络,可以借助现有的训练数据执行预测,以便探测场景中的可能的变化。由于对于该场景在训练数据中已经存在图像-标签对,因此能够实现高的预测质量。注释与预测之间的差异给出关于必须重新注释(nachannotieren)哪些对象的指示。
一种扩展方案设置,通过图像序列可以检测第二状态中的场景,并且基于在待标记的单个图像之前和/或之后的至少一个单个图像可以补偿以下不利位置:由该不利位置检测到第二状态中的场景。
例如,场景的第一状态和第二状态可以通过天气条件、照明条件等来区分。例如,在由于雾而相对于晴朗的天气变差的可见度的情况下、在夜间或在类似情况下可以再次检测场景。
根据另一扩展方案,例如当第二状态包括黑暗、差的可见度等时,第二状态可能导致以下结果:在第二数据集中,场景的一个或多个对象不(再)可见。在这种情况下,可以相应地标记或注释这种不可见区域,或基于例如信噪比自动地排除该不可见区域。
本发明还涉及一种用于传感器数据中的对象标记的系统。该系统尤其可以根据上述方法运行,并且因此可以根据上述实施变型方案中的一个或多个来进行扩展。该系统具有至少一个用于检测场景的、优选为光学的传感器,并且具有数据处理装置,例如具有处理器、存储器和/或类似物的计算机。数据处理装置设置用于,在包含第一状态中的场景的第一数据集中,将第一对象标记分配给包含在场景中的至少一个对象,并且对于在场景的第二状态中所识别出的对象,至少部分地采纳包含在第一数据集中的第一对象标记来作为第二数据集中的第二对象标记。
根据一种扩展方案,该系统可以具有第二传感器,该第二传感器用于在检测场景期间进行地点确定和/或位姿确定,其中,地点确定和/或位姿确定能够分配给所检测的场景,即尤其是能够分配给第一数据集。第二传感器例如可以包括一个或多个传感器,例如以用于GPS定位、以用于自身运动确定等。
下面基于附图结合对本发明的优选实施例的描述,进一步示出改善本发明的其他措施。
附图说明
以下参照附图详细地描述本发明的有利实施例。附图示出:
图1示出可以借助本发明所基于的方法来运行的系统的示意图;
图2以道路走向为示例示出本发明的实际应用。
附图仅是示意性的,而不是按比例的。在附图中,相同的、相同作用的或类似的元素总是设有相同的附图标记。
具体实施方式
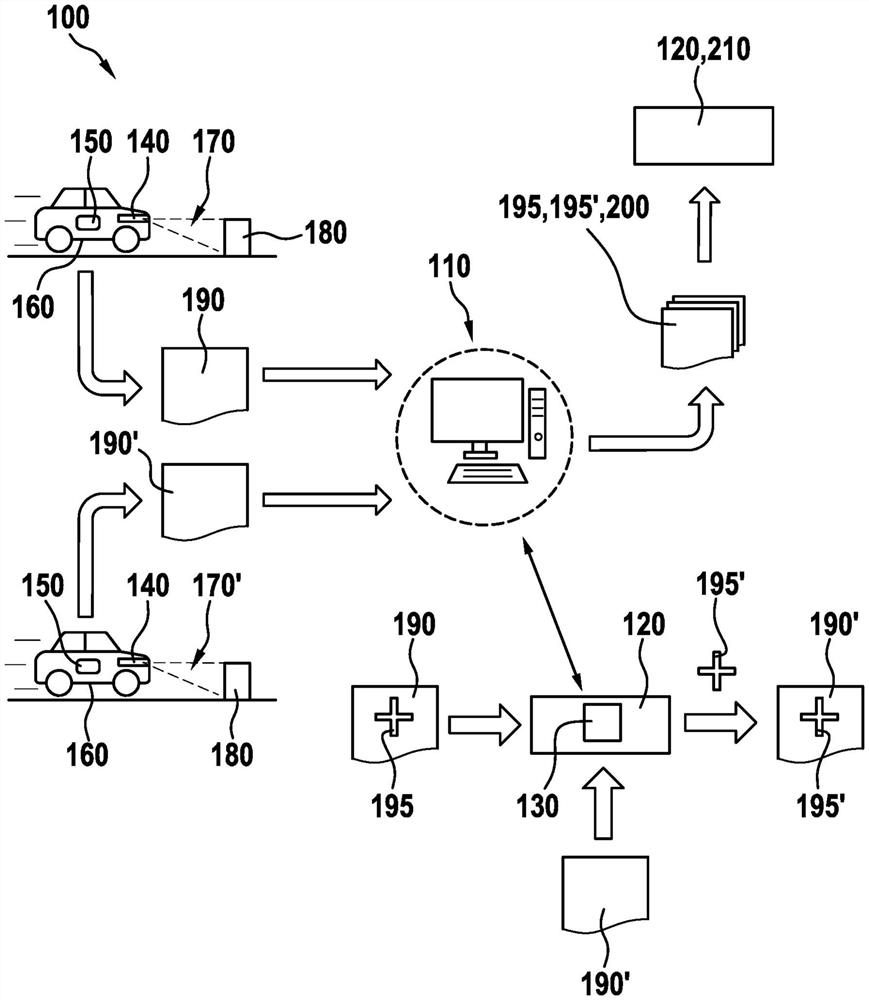
图1示出系统100的示意图,该系统适用于在图像中或在图像序列中所识别出的对象或对象类别的部分自动化的和/或全自动化的标记或注释。
系统100包括数据处理装置110,该数据处理装置可以具有处理器、存储装置(尤其是用于程序代码等的存储装置)。在本实施例中,数据处理装置110具有至少一个人工智能模块120(简称KI模块),该至少一个人工智能模块示范性地通过多层人工神经网络130设置用于图像中或图像序列中的模式识别。此外,该系统具有实施为光学传感器(例如实施为摄像机)的至少一个第一传感器140,以及用于地点确定和/或位姿确定的至少一个第二传感器150。在此,传感器140、150示范性地布置在机动车160处或该机动车中,并且也可以从另一车辆系统中借用。如此,第一传感器140可以是驾驶辅助系统的一部分,该驾驶辅助系统也可以设置用于机动车160的自主行驶运行。第二传感器150可以是导航系统、里程计系统等的一部分。
系统100可以借助以下描述的方法运行。
首先,机动车160运动通过场景170,在此,该场景示范性地涉及具有对象180的交通情况,该对象例如可以是呈道路走向、交通标志等形式的静态对象。在第一状态中,借助第一传感器140将场景170记录为图像或图像序列并存储在第一数据集190中。场景170的第一状态例如对应于机动车160的通过场景的日间行驶,其中,在此假设场景的相应地日间明亮的照明。基于通过第二传感器150进行的地点确定和/或位姿确定,还将地点信息(即地点,在该地点处已经记录该场景)和视角信息和/或位姿信息保留在第一数据集190中。
在不同于第一状态的第二状态中重新记录相同或相似的场景,因此在图1中以170‘标记在第二状态中重新记录的场景。在此,示例性地,这对应于机动车160通过场景170‘的夜间行驶,其中,在此假设相应地夜间黑暗的周围环境。此外,假设对象180仍然是场景170‘的一部分。将第二状态中的场景170‘存储在第二数据集190‘中。
此外,将第一数据集180提供给数据处理装置110,并且借助该数据处理装置例如手动地或通过KI模块120部分自动化地、也可能全自动化地以第一对象标记195(即注释)标记对象190。第一对象标记195例如可以是道路走向的突出部(Hervorhebung)。
也将第二数据集190‘提供给数据处理装置110并在其中进行处理。KI模块120还设置用于,识别第二数据集190‘中的对象180,并将第二对象标记195‘分配给该对象,在对象180不变的情况下,该第二对象标记与第一数据集190中的第一对象标记195相同。对于场景170‘和/或对象180的(再)识别,KI模块120追溯存储在第一数据集190中的、关于场景170的记录的地点和位姿的信息。作为通过KI模块120进行的处理的结果,现在,第二数据集190‘也包含类似的或相同的场景170‘和第二对象标记195‘。
如在图1中所表明的那样,第一和第二数据集190、190‘用作用于KI模块120自身或用于其他KI模块210的训练数据集200,该其他KI模块例如也可以是自主驾驶车辆的一部分。
图2在左侧示出示范性的场景170,在该场景中,对象180是道路走向,在此,该道路走向已经设有第一对象标记195。假设在场景170的记录期间,存在相对较差的天气,并且因此略微限制视野。在图2的右侧,再次在较清晰的天气中记录场景170‘。KI模块120已经(再)识别出场景170‘,并且已经自动地将第二对象标记195‘分配给对象180(即道路走向)。
从所示出的实施例出发,能够在许多方面改动系统100和上述方法。如此,例如能够基于第一数据集190,例如单目地、通过立体深度估计、光流估计和/或基于激光雷达数据对已经具有第一对象标记的图像执行深度预测。还可以在未知图像中(即在第二数据集中)执行语义分割的预测。此外,可以想到,变换第一对象标记195,以便该对象标记更精确地匹配于第二数据集190‘的新图像。该变换也称为扭曲。此外,能够使用SLAM(同步定位和制图)方法,以便获得更好的地点确定和位姿确定。还可以想到,人工神经网络130可以提供逐像素的一致性掩膜作为输出。这可以为手动、部分自动或全自动的进一步处理形成良好的基础。此外,可能的是,尤其是通过SLAM方法确定在第一状态与第二状态之间场景170、170‘的至少一个区分特征,并且将第二对象标记195‘分配给该区分特征,至少在以下情况下:区分特征(例如差异等级)已经具有足够良好的质量(例如具有高置信度的统计测试),并且对于场景170、170‘的其余图像内容而言人工神经网络130显示出一致性时,例如提供自动地采纳对象标记195的选项。
- 用于传感器数据中改善的对象标记的方法和系统
- 用于标记对象的二维标记、用于生成标记的方法和系统、用于生成标记码的方法和系统以及用于认证对象的方法和系统