基于大数据体系的综采工作面数据融合方法
文献发布时间:2023-06-19 10:58:46
技术领域
本发明属于数据融合技术领域,具体属于一种基于大数据体系的综采工作面数据融合方法。
背景技术
数据统一采集需要协调各设备之间关系,保证数据的关联性和完整性,现有技术可以实现数据统一采集,但是在矿井方面的应用处于空白领域。市面上现有技术可以实现大数据的采集和处理,但是针对煤矿井下恶劣环境无法实现,一是煤矿井下环境复杂,需要采集数据量大且杂;二是综采工作面各设备之间通信协议各不相同,导致数据无法统一;三是技术实现。
现有煤矿井下设备数据获取主要是通过监控系统直接在设备上采集,由于各设备厂家不同,导致采集数据格式不一,形成数据的多源异构性。现有技术无法实现矿井综采工作面的实时数据采集和融合。
发明内容
为了解决现有技术中存在的问题,本发明提供一种基于大数据体系的综采工作面数据融合方法,实现数据的统一采集和处理,保证系统的稳定、可靠运行。
为实现上述目的,本发明提供如下技术方案:基于大数据体系的综采工作面数据融合方法,其特征在于,具体包括以下步骤:
S1平台搭建:采用多台服务节点搭建大数据平台,多服务节点包括数据采集系统、云数据中心、数据处理平台和数据区;
S2数据采集:数据采集系统采集设备数据,并对采集的数据进行分类,利用数据格式转换模型对分类后的数据进行格式转换,得到数据格式统一的数据集;
S3数据传输及处理:数据采集系统通过TCP/IP和MQTT协议将步骤S2中数据集中的数据以json字符串的形式传输至云数据中心,云数据中心进行身份鉴权和数据处理,得到完整的数据集;
S4数据存储:将步骤S3得到的完整的数据集传输至数据处理平台,数据处理平台根据数据集标识将数据分类存储于HDFS中,HDFS根据数据分类模型对分类存储的数据进行整合,并存储至数据区中。
进一步的,步骤S1中,采用大数据处理框架和企业大数据管控平台中多台服务节点搭建大数据平台,大数据平台具备双节点热备份,大数据平台7×24小时不间断业务流转。
进一步的,步骤S2中,数据采集平台采用EMQTT数据采集平台系统,以各矿务局-工作面为基准,对不同工作面进行编码,通过编码主题区分数据源,采用采集多线程方式采集数据。
进一步的,步骤S2中,数据采集平台通过自动订阅主题的方式获取设备运行姿态、工况和环境监测数据。
进一步的,步骤S3中,在数据采集系统和云数据中心建立独立点对点的数据通道,通过EMQ加密技术,对数据通道进行加密,EMQ加密技术采用双向ACL数据访问控制校验,EMQ平台采用emqx_auth_mysql基于MySQL的认证/访问控制插件。
进一步的,步骤S3中,设备与EMQ平台服务器建立单向传输数据通道,确保设备与EMQ平台服务器的订阅关系相互独立;云数据中心接收EMQ平台服务器反馈工况数据,并将反馈的数据与数据采集平台的ACL数据服务中所接收到的工况数据进行关联实现数据融合。
进一步的,步骤S3中,云数据中心对接入消息服务器的发布者和订阅者进行身份鉴权,当发布者通过身份校验后,订阅者通过身份校验接入EMQX平台后,发布者与订阅者建立订阅关系时,云数据中心将主动对建立的数据通道内部的数据进行拦截,抓取数据并对发布者身份确认,
1)云数据中心确认身份鉴权无误后,将恢复通道连接状态;
2)云数据中心确认身份鉴权出现问题时,云数据中心将主动断开连接。
进一步的,步骤S3中,所述数据处理包括前处理和失真处理,其中,前处理采用ETL处理流程对工况数据进行处理,ETL处理流程包括抽取、转换、加载;失真处理采用多重插补法对数据变量之间的关系进行预测,利用蒙特卡洛方法生成多个完整的数据集,并对这些数据集进行分析,最后对分析结果进行汇总处理。
进一步的,步骤S4中,所述整合包括数据转换和数据清洗,所述数据转换采用结构化数据处理模块将HDFS中存储的数据进行格式转换;所述数据清洗采用分箱方法。
进一步的,步骤S4中,所述数据集标识依据时间节点、数据类型建立。
与现有技术相比,本发明至少具有以下有益效果:
本发明提供一种基于大数据体系的综采工作面数据融合方法,针对工作面设备的传输协议各异问题,定制研发相关驱动和交互方法,通过多台服务节点搭建大数据平台,最大降低集群单点故障率,并通过数据采集系统实现多源数据的采集获取,通过Mqtt(数据发布/订阅传输协议)以及TCP/IP(传输控制协议/因特网互联协议)将数据流以json字符串的形式发送至云数据中心,云数据中心对采集的数据进行鉴权和处理并传输至数据处理平台,数据处理平台根据数据流标识将数据分类存储于HDFS(分布式文件系统)内,并在HDFS中使用数据分类模块进行数据的过滤、清洗、数据格式转换,最终得到融合的数据并将数据存储至数据区,以便后续支持分析类应用。
本发明中数据采集系统由服务节点提供自适应的数据传输服务,降低大数据平台数据处理负荷;同时数据采集系统采取EMQTT平台,EMQTT平台符合大数据平台中工况数据发布订阅功能需求,并满足其它扩展和升级中所需要的功能性技术。
进一步的,由于工况数据日数据量约在500M~2048M之间,传统关系型数据库如MYSQL不能够长期有效的存储,对数据积累时间过长单表数据量过大,维护繁琐、影响线上业务等多种因素存在,故建立分布式且高可用的文件数据系统即HDFS作为底层数据持久话的支撑。
HDFS对于数据的安全性、容错性、容灾机制都有非常完善的体系机制,达到毫秒级实时数据的接入以及防止数据失帧,避免由于数据量大在传输中出现的数据失帧、脏数据无法处理的现象,本发明采用HDFS对数据集进行存储,减缓了数据集中数据的负载、优化了底层数据的存储、提高大数据平台的运转效率,同时可以有效的对数据集中的数据进行归纳、分离、聚合等操作,可永久留存高价值高密度数据。此外,HDFS分布式文件系统支持热扩容机制,当集群环境下存储空间有限时,可动态添加节点,进行存储容量的扩容。
附图说明
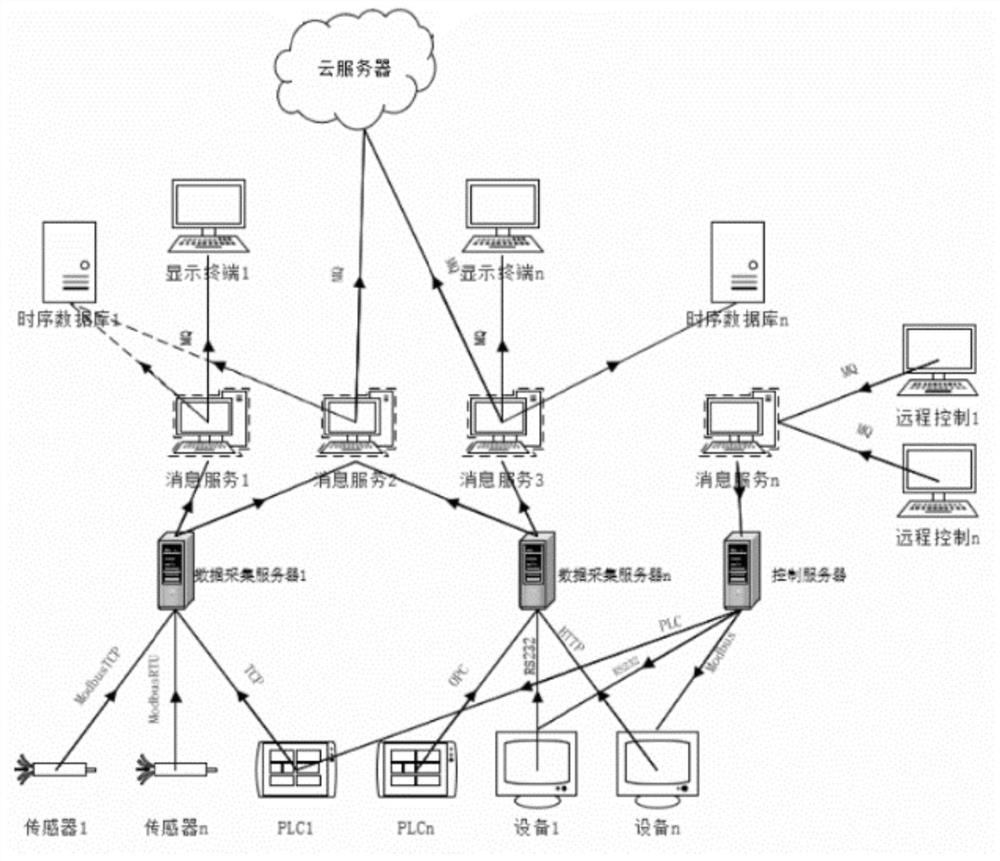
图1本发明数据采集及传输示意图。
具体实施方式
下面结合附图和具体实施方式对本发明作进一步的说明。
本发明针对工作面设备的传输协议各异问题,定制研发相关驱动和交互方法,实现多源数据的采集获取,通过Mqtt(数据发布/订阅传输协议)以及TCP/IP(传输控制协议/因特网互联协议)将数据流以json字符串的形式发送至云数据中心,云数据中心对采集的数据进行鉴权和处理并传输至数据处理平台,数据处理平台根据数据流标识将数据分类存储于HDFS(分布式文件系统)内,并在HDFS中使用数据分类模块进行数据的过滤、清洗、数据格式转换,最终得到融合的数据并将数据存储至数据区,以便后续支持分析类应用。
本发明提供一种基于大数据体系的综采工作面数据融合方法,具体包括以下步骤:
1)平台搭建:采用多台服务节点搭建大数据平台,多服务节点包括数据采集系统、数据模型,集控中心、云数据中心、数据处理平台和存储器;
采用Hadoop(大数据处理框架)和CDH(企业大数据管控平台)中多台服务节点搭建大数据平台,搭建好的大数据平台具备双节点热备份,且确保实现7×24小时不间断业务流转。
优选的,Hadoop是一个分布式系统集群,对于计算节点的服务器来说,要求服务器的硬件配置是稍低的,同时避免了大量的服务器集群之间的数据传输问题。
2)数据采集:数据采集系统使用传感器、摄像头等探测装置,采集设备运行姿态、工况、环境监测数据,通过CAN、RS485和MODBUS RTU接口等将采集的数据传输至工作面主机;数据采集系统对采集的数据进行分类,利用数据格式转换模型对分类后的数据进行格式转换,得到数据格式统一的数据集;
为了更好的实现大数据平台的数据融合,需要采集综采工作面相关设备的详细数据量,采集的主要工况数据包括采煤机数据、支架数据、破碎机、转载机、刮板运输机和泵站数据,具体数据如下:
(1)采煤机数据
各工作电机运行电流、温度、摇臂轴温、滚筒高度及卧底量;采煤机的行走速度和定位采煤机位置,采煤机的俯、仰采角度及采煤机行走方向的工作面倾角;液压系统备压压力及泵箱内液压油的高度,冷却水流量、压力,油箱温度,左右滚筒高度。
(2)支架数据
所有支架立柱压力,推移行程,控制模式,所有支架控制器的急停状态、通信状态、驱动器与支架控制器通信状态,工作面的推进度,包括当班和累计进度。单架单动作、成组推溜,成组伸收护帮、成组伸收伸缩梁等动作的动作编码数据。
(3)三机数据
破碎机、转载机及刮板运输机,各设备减速器及电动机温度、压力、流量、位移、转速、开关状态显示、回路运行状态、电流值、电压值以及漏电、断相、过载数据。
(4)泵站数据
泵站出口压力、泵站油温、泵站油位状态、泵站电磁阀动作情况、液箱液位、乳化液油箱油位数据。
如图1所示为数据采集和传输的示意图,由于采煤机数据、支架数据、三机数据、泵站数据没有统一结构,上述数据采集系统采集的数据存在多源异构的问题,因此采集到的数据并不能被云数据中心所识别,故需要对其云数据中心内配置的对应数据模型进行数据统一格式转换,转换流程如下:
a.采集数据并对数据进行简单分类;
b.根据数据格式转换模型对分类后的数据进行模型匹配;
c.利用数据格式转换模型对分类后的数据进行格式转换,得到数据格式统一的数据集;
优选的,步骤2)中的数据采集系统采用Flume框架能对采集到的工况数据进行简单处理,并写入各种数接受方。其设计的原理也是基于将可以对多数据流、多数据环境下采集到的工况数据汇集起来,并存储到HDFS即分布式文件系统或HBase即分布式列族非关系数据库等集中存储器中。
优选的,步骤2)中数据采集平台采用EMQTT开源消息队列遥测传输协议服务器简称消息服务器《Erlang MQTT Broker开源MQTT消息服务器》,数据采集系统以各矿务局-工作面为基准,对不同工作面进行编码,通过编码主题区分数据源,采用采集多线程方式,进行采集工况数据。
优选的,步骤2)中数据采集系统通过自动订阅主题的方式获取数据,井下设备与EMQ平台服务器建立单向传输数据通道,确保每次井下设备与EMQ平台服务器之间的订阅关系相互独立。
3)数据传输及处理:数据采集系统通过TCP/IP和MQTT协议将将步骤S2中得到数据集中的数据以json字符串的形式传输至云数据中心,云数据中心进行身份鉴权和数据处理,得到完整的数据集;
步骤3)中在数据采集系统和云数据中心之间建立独立点对点的数据通道,通过EMQ加密技术,对数据通道进行加密,EMQ加密技术采用双向ACL数据访问控制校验,EMQ平台采用emqx_auth_mysql基于MySQL的认证/访问控制插件。
步骤3)中,云数据中心对接入EMQX消息服务器的发布者和订阅者进行身份鉴权,当发布者通过身份校验后,订阅者通过身份校验接入EMQX消息服务器后,发布者与订阅者建立订阅关系时,云数据中心将主动对建立的数据通道内部的数据进行拦截,抓取数据并对发布者身份确认:
1)云数据中心确认身份鉴权无误后,将恢复通道连接状态;
2)云数据中心确认身份鉴权出现问题时,云数据中心将主动断开连接。
云数据中心收到由EMQ平台服务器反馈的地质数据后,将反馈的数据与数据采集系统的ACL数据服务中所接收到的工况数据进行关联,实现数据更好的融合。
步骤3)中的数据处理包括前处理和失真处理,其中,前处理:采用ETL处理流程对工况数据进行处理,ETL处理流程包括抽取、转换、加载;
失真处理采用多重热插补法,对于丢失的数据但属性级别较高的,云数据中心采用多重热插补法对数据集中数据变量之间的关系进行预测,即在算法内建立(M)插补值的向量来替代所检测到的每一个缺失值或失帧值的过程;通过插补值的向量的第一个元素对象建立完整的第一数据集,插补值的向量的第二个元素依据第一个数据集建立第二数据集,算法运行时间的复杂度为O(n^
基于实际需求考虑,大数据平台内部整体采用SHIRO安全校验框架、JWT安全认证框架、REDIS(SESSION)缓存校验框架等多种手段实现大数据平台内部数据交互流转过程,最大限度降低内部敏感数据暴露、明文传输、传输断层后数据丢失外漏等问题。
4)数据存储:将步骤3)得到的完整的数据集传输至数据处理平台,数据处理平台根据数据集标识将数据分类存储于HDFS中,根据数据分类模型对分类存储数据进行融合,并定期将融合的数据存储至数据区中。
数据处理平台采用数据分类模型对完整数据集中的数据进行标准化、数据更新/追加的整合,并定期将采煤机、运输三机、支架、泵站的历史数据保存在物理磁盘中,利用Sqoop(数据迁移工具)提取数据库、文件系统、列族数据库、内存数据库中的数据集并存入HDFS(分布式文件管理系统)。
数据处理平台采用HIVE数据仓库对HDFS内的数据进行建表,提高数据SQL脚本化查询语言)查询能力,对数据仓库进行动态在线扩容,并对关键数据进行二次备份。
优选的,数据分类模型采用Spark SQL(结构化数据处理模块),Spark SQL将HDFS(分布式文件系统)中的数据进行计算处理,对HDFS中的地质切片数据、工况原始数据,进行分解、清洗、过滤、数据格式转换后,写入到MySQL数据库。
优选的,写入到MySQL数据库中的数据还需进行数据清洗,数据处理平台采用分箱方法考察数据的“近邻”来光滑有序的数据值。
优选的,整合后的数据要存入不同的数据区中,当数据分类模型转换后的数据集,在平台内根据自动识别分类算法,对数据进行分类存储,需存入临时数据区。
经过Sqoop(数据迁移工具)的数据集按照以设备、数据类型、时间节点进行分类存储,优化数据存储机制,对非结构化数据进行结构化处理,需存入主题或集市数据区。
步骤4)中,HDFS分布式文件系统存储底层离线数据、历史数据、日志等数据包。
步骤4)中,数据集标识依据时间节点、数据类型建立,以采煤机为例:
采煤机:
{"obj":"采煤机","Name":"左滚筒.高度
","Value":"-0.8","Time":"123","Qos":"0","Note":"null"}
{"obj":"采煤机","Name":"右滚筒.电流
","Value":"108.13","Time":"123","Qos":"0","Note":"null"}
{"obj":"采煤机","Name":"右滚筒.高度
","Value":"2.88","Time":"123","Qos":"0","Note":"null"}
{"obj":"采煤机","Name":"左牵引.电流
","Value":"122.5","Time":"123","Qos":"0","Note":"null"};
依据数据集标识建立二级索引,将二级索引目录信息存入元数据服务器中,数据经加工计算后的结果交付到数据集市,支持分析类应用。
- 基于大数据体系的综采工作面数据融合方法
- 基于大数据体系的北斗交通运输数据融合系统