一种抗终末糖基化蛋白受体的抗体及其应用
文献发布时间:2023-06-19 11:09:54
技术领域
本发明涉及生物医药技术领域,具体涉及一种抗终末糖基化蛋白受体的抗体及其应用。
背景技术
糖基化终产物受体(receptor for advanced glycation endproducts,RAGE)是一种膜蛋白,属于免疫球蛋白超家族。人RAGE由404个氨基酸组成,分别由较大的细胞外段(321个氨基酸残基)、跨膜段(19个氨基酸残基)及短的细胞内段(41个氨基酸残基)3个部分构成。氨基酸序列分析表明,RAGE为免疫球蛋白超家族的新成员,它与免疫球蛋白超家族中的MUC18糖蛋白、神经细胞粘附分子(nerve cell adhesion molecule,NCAM)及CD20胞内部分的氨基酸序列高度同源。可溶性RAGE(soluble RAGE,sRAGE)即RAGE胞外段,为配体结合部位,具有V型片段紧接两个C型片段的免疫球蛋白样结构,每个都含有一对保守的半胱氨酸残基,V型片段还含有两个与N偶联的糖基化位点,这些对于RAGE分子结构的稳定性和特异识别配体的功能具有重要意义。在胞外段之后是一个跨膜区和一条带有高度负电荷的胞质尾巴。胞内段RAGE与B细胞激活标记CD20具有高度同源性,该段很可能在配体占领受体后结合胞浆内信号转导分子,产生细胞效应。
专利文献US10550184B2、CN102089430A、CN102686611A、US20100143349A1、WO2008137552A2等均记载了抗RAGE抗体,采用了不同的抗体可变区CDR序列以及不同的抗体结合抗原的表位。
文章(Tekabe Y,Anthony T,Li Q,et al.Treatment effect with anti-RAGE F(ab′)2antibody improves hind limb angiogenesis and blood flow in Type 1diabetic mice with left femoral artery ligation.Vascular Medicine.2015;20(3):212-218.doi:10.1177/1358863X14568337)中报道了一种抗RAGE F(ab’)2抗体的治疗改善了左股动脉结扎的1型糖尿病小鼠后肢血管生成和血流量,其中抗RAGE F(ab’)2抗体为鼠源抗体而非人源化抗体。文章(Yared Tekabe,Joane Luma,Qing Li,Ann Marie Schmidt,Ravichandran Ramasamy,Lynne L.Johnson,Imaging of Receptors for AdvancedGlycation End Products in Experimental Myocardial Ischemia and ReperfusionInjury,JACC:Cardiovascular Imaging,Volume 5,Issue 1,2012,Pages 59-67,ISSN1936-878X)报道了动物模型中实验性心肌缺血再灌注损伤中晚期糖基化终产物受体的显像,其中抗RAGE F(ab’)2抗体为未进行人源化的鼠源抗体片段。文章(Demling,N.,Ehrhardt,C.,Kasper,M.et al.Promotion of cell adherence and spreading:a novelfunction of RAGE,the highly selective differentiation marker of humanalveolar epithelial type I cells.Cell Tissue Res 323,475–488(2006))报道的抗RAGE抗体也为未进行人源化的鼠源抗体。然而,上述由动物血清生成的现有抗体不适合于人的长期治疗。
发明内容
针对现有技术的不足,本发明提供了一种抗终末糖基化蛋白受体的抗体及其应用。本发明筛选和克隆出可以特异性结合终末糖基化蛋白受体(Receptor for Advancedglycation end product,RAGE)的新抗体。该新抗体的轻链和重链的抗原结合互补结合决定区(complementarity-determining regions,CDR)序列独特,其CDR区和已发现的抗体CDR区不同。本发明获得的抗体可以和细胞表面的人RAGE蛋白特异性的结合,并具有抑制和阻断细胞上RAGE将胞外信号传递到细胞内的功能。
本发明制备的与人RAGE结合的新单克隆抗体,其与现有公开的抗人RAGE抗体的与人RAGE结合的结构域不同,及其抑制人RAGE与Aβ、S100-A4、S100-A6的特定相互作用。
本发明的目的是通过以下技术方案实现的:
第一方面,本发明提供了一种抗终末糖基化蛋白受体的抗体,
包括轻链可变区、重链可变区;所述轻链可变区的CRD区序列包括轻链CDR1、轻链CDR2、轻链CDR3;所述轻链CDR1的氨基酸序列为SEQ ID NO.11所示,轻链CDR2的氨基酸序列为SEQ ID NO.12所示,轻链CDR3的氨基酸序列为SEQ ID NO.13所示;
所述重链可变区的CRD区序列包括重链CDR1、重链CDR2、重链CDR3;所述重链CDR1的氨基酸序列为SEQ ID NO.5所示,重链CDR2的氨基酸序列为SEQ ID NO.6所示,重链CDR3的氨基酸序列为SEQ ID NO.7所示。
优选地,所述抗体的重链可变区的氨基酸序列如SEQ ID NO.1所示,轻链可变区的氨基酸序列如SEQ ID NO.2所示;
或所述抗体为包括以前述轻链可变区和重链可变区为基础的突变体或人源化抗体,所述突变体包括与前述轻链可变区和重链可变区序列具有50%以上同源性的氨基酸序列;所述人源化抗体包括对前述轻链可变区和重链可变区中的非CDR区序列进行突变后得到。
优选地,所述抗体的重链可变区的碱基序列如SEQ ID NO.3所示,轻链可变区的碱基序列如SEQ ID NO.4所示。
优选地,所述抗体还包括轻链恒定区、重链恒定区;
所述重链恒定区的氨基酸序列如SEQ ID NO.30所示,轻链恒定区的氨基酸序列如SEQ ID NO.29所示。
所述重链恒定区的碱基序列如SEQ ID NO.32所示,轻链恒定区的碱基序列如SEQID NO.31所示。
优选地,所述人源化抗体的重链可变区氨基酸序列如SEQ ID NO.41所示,轻链可变区氨基酸序列如SEQ ID NO.42所示。
第二方面,本发明提供了一种包含前述的抗终末糖基化蛋白受体的抗体的重组质粒。
第三方面,本发明提供了一种抗终末糖基化蛋白受体的抗体的制备方法,其特征在于,包括以下步骤:
A、筛选获得分泌抗RAGE抗体的单克隆杂交瘤细胞,并获得编码抗人RAGE抗体重链可变区和轻链可变区DNA片段;
B、将克隆出的抗人RAGE抗体的轻链可变区和重链可变区分别与人IgG1抗体的轻链恒定区和重链恒定区进行重组,即得。
第四方面,本发明提供了一种抗终末糖基化蛋白受体的抗体在制备抑制星状细胞活化和肝纤维化的组合物中的应用。
第五方面,本发明提供了一种抗终末糖基化蛋白受体的抗体在制备治疗老年痴呆的组合物中的应用。
第六方面,本发明提供了一种抗终末糖基化蛋白受体的抗体在制备S100A4、S100A6蛋白拮抗剂中的应用。
第七方面,本发明提供了一种抗终末糖基化蛋白受体的抗体在制备Aβ蛋白拮抗剂中的应用。
与现有技术相比,本发明具有如下的有益效果:
1、本发明通过重组sRAGE蛋白免疫小鼠,并用杂交瘤细胞技术筛选得到一种全新的抗人RAGE蛋白的抗体A5;通过逆转录PCR技术获得编码A5的轻链和重链可变区的DNA序列;ELISA、流式细胞术、生物膜层干涉三种方法表明A5嵌合抗体对人源RAGE(sRAGE)具有良好的亲和力(KD=2.15×10
2、本发明获得的抗RAGE抗体具有治疗RAGE相关疾病及病症,优选选自脓毒症、败血症性休克、李斯特菌病、炎性疾病包括类风湿性关节炎和银屑病性关节炎和肠病、癌症、关节炎、克罗恩病、慢性急性炎性疾病、心血管疾病、勃起机能障碍、糖尿病、糖尿病并发症、血管炎、肾病、视网膜病、神经病、淀粉样变性、动脉粥样硬化、外周血管病、心肌梗死、充血性心力衰竭、糖尿病性视网膜病、糖尿病性神经病、糖尿病性肾病和阿尔茨海默病,尤其是糖尿病和/或炎性病症。
3、由于RAGE蛋白及其配体与肝纤维化有着密切的联系,当抑制RAGE受体表达、抑制RAGE活性或者加入RAGE受体拮抗剂时,机体的肝纤维化进程被抑制,本发明提供的抗体还具有治疗肝纤维化的潜力。
附图说明
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
图1为小鼠免疫效价测定结果;
图2为抗RAGE抗体基因克隆结果;
图3为A5L1、A5H1、Y9L1和Y9H1的PCR产物电泳结果图;
图4为A5嵌合抗体纯化SDS-PAGE胶图;
图5为A5嵌合抗体HPLC结果;
图6为A5嵌合抗体ELISA结果;
图7为A5嵌合抗体与重组人sRAGE结合的表面等离子体共振传感器反应信号;
图8为CCK8测定A5嵌合抗体对SH-SY5Y细胞增殖影响(**:P<0.01,***:P<0.001);
图9为不同组别磷酸化ERK1/2蛋白表达水平的变化;
图10为CCK8测定A5嵌合抗体和S100A4/S100A6之间的相互作用(*:P<0.05);
图11为CCK8测定A5嵌合抗体和Aβ之间的相互作用(*:P<0.05,**:P<0.01);
图12为人源化A5单链抗体纯化SDS-PAGE胶图;
图13为人源化A5单链抗体ELISA结果。
具体实施方式
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进。这些都属于本发明的保护范围。
以下实施例制备人鼠嵌合抗体的方法主要步骤如下:
1.小鼠免疫
6周龄的雄性BALB/c小鼠作为免疫对象,重组人可溶性RAGE蛋白作为抗原,第一次免疫与弗氏完全佐剂乳化后进行免疫,10天之后,采用弗氏不完全佐剂和抗原乳化后分别进行第2、3、4次免疫,每次免疫间隔9天。第4次免疫后3天,采血验证免疫效果。血清中抗人RAGE抗体的滴度大于8000-10000倍稀释后即可进行下一步实验。
2.杂交瘤融合
选择免疫效果最好的小鼠,麻醉后,进行颈椎脱臼处死和酒精消毒。取出脾脏,分离脾脏细胞,并用灭菌的聚乙二醇4000(PEG-4000)介导脾脏细胞和小鼠腹水瘤细胞(SP2/0)进行融合。对于融合的杂交瘤细胞用含HAT培养基(次黄嘌呤(H)、氨基喋呤(A)和胸腺嘧啶核苷(T)])进行选择性培养,未成功融合的脾脏细胞和SP2/0细胞无法继续存活。
3.单克隆细胞筛选
对融合的杂交瘤细胞采用有限稀释法进行单克隆化,待到单克隆细胞长到7天后,采用酶联免疫吸附分析(ELISA)技术筛选分泌抗RAGE抗体的单克隆杂交瘤细胞,对阳性细胞株进行2轮筛选后,抗体基因克隆,获得分泌抗体的单克隆细胞。
4.抗体基因克隆
对筛选出分泌抗体的单克隆细胞进行培养,用TRIzol试剂抽提细胞总RNA,采用逆转录聚合酶链式反应(Reverse transcription polymerase chain reaction,RT-PCR)技术分别扩增出每个单克隆抗体细胞株中编码抗人RAGE抗体重链可变区和轻链可变区DNA片段,将产物送到上海生物工程有限公司进行测序分析,获得基因序列后,根据氨基酸密码子翻译出氨基酸序列。5.重组抗RAGE抗体的获得和验证
将克隆出的抗人RAGE抗体的轻链可变区和重链可变区分别与人IgG1相应的轻链恒定区和重链恒定区进行重组,并构建到pcDNA3.1/Myc-His(-)A载体上,获得表达出鼠-人嵌合抗体的质粒。将构建好的质粒导入到人胚肾细胞株(HEK293T)细胞中表达,并用ELISA技术验证重组抗RAGE抗体和重组人RAGE蛋白的结合能力。
实施例1小鼠单克隆抗体的筛选
1、小鼠免疫
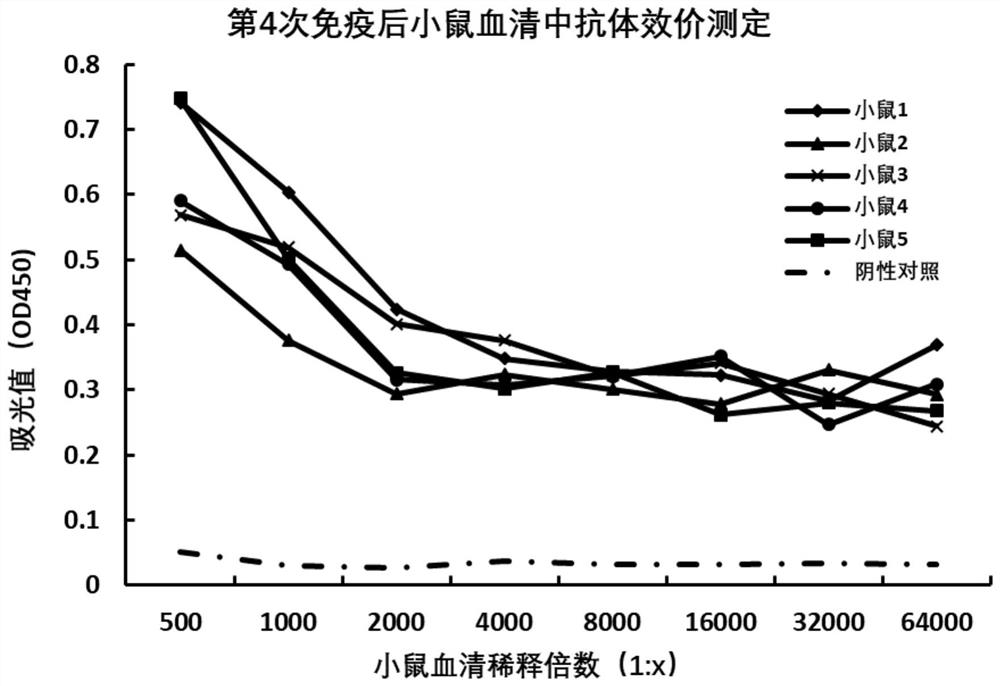
以人的sRAGE蛋白作为抗原,按照常规免疫程序,第一次采用等体积的弗氏完全佐剂与蛋白充分乳化后,在6周龄的雄性BALB/c小鼠皮下接种免疫,每只小鼠免疫100μg蛋白,共计免疫5只。10天以后每次采用弗氏不完全佐剂和抗原乳化后进行免疫,每隔9天免疫一次,连续免疫3次,第4次免疫后3-4天尾静脉采血验证免疫效果,用ELISA的方法测定小鼠中抗体的滴度。采用美国Jackson immunoresearch公司HRP偶联抗小鼠IgG(H+L)二抗和北京索莱宝公司的单组分TMB检测与sRAGE结合的小鼠抗体。分别对5只免疫的小鼠血清分析发现,血清被稀释64000倍后测得的吸光值依然高于阴性对照血清2倍以上,表明小鼠免疫成功,产生了特异性结合RAGE细胞外结构的抗体,符合开展细胞融合实验的要求。分析结果参见图1。
2、小鼠杂交瘤融合过程
为了获得可以体外培养并持续分泌抗体的细胞株,采用常规的小鼠骨髓瘤细胞与免疫小鼠脾脏内分化的B淋巴细胞进行融合,产生杂交瘤细胞株。实验材料包含免疫后的Bab/c小鼠(小鼠来源于中国科学院实验动物中心,在上海交通大学完成免疫,具体免疫方法与步骤1相同)、未免疫的Bab/c小鼠(中国科学院实验动物中心)、骨髓瘤细胞株Sp 2/0(中国科学院细胞库)、50%的PEG4000(美国西格玛试剂公司,现为美国Merck公司品牌),1640无血清培养基(美国GE公司)、PBS、FBS(美国赛默飞世尔公司,GIBCO)、HAT(美国西格玛试剂公司,现为美国Merch公司品牌)。其他耗材全部购买自美国康宁公司。
操作过程在无菌操作台中完成。具体步骤如下:
2.1首先分离饲养细胞,具体步骤为:脱颈处死未免疫Bab/c小鼠,浸入70%酒精中消毒,剪开小鼠腹部的皮肤(勿剪破肌肉层)。用5ml注射器吸取5ml 1640无血清培养基,注入小鼠腹部,摇动小鼠身体,使巨噬细胞充分溶于培养基。用注射器小心吸回培养基,放入15ml离心管,1000rpm,5分钟,弃上清。用PBS清洗一遍,离心弃上清。加入40ml含HAT的1640+20%FBS充分混匀后,以100ul/孔加入96孔板,37℃、CO
2.2然后准备小鼠骨髓瘤细胞株Sp 2/0,在融合前用8-N-鸟嘌呤进行一次筛选,以确保所有参加融合的Sp 2/0细胞对HAT培养基敏感。用1640+10%FBS培养基(即在1640无血清培养基中加入10%FBS后制得)培养筛选后的SP2/0细胞,每隔2到3天以1:3的比例进行传代,观察培养瓶的底部细胞覆盖率情况。在准备融合前48小时做最后一次传代,待传代后细胞密度长到覆盖瓶底80%左右用于细胞融合实验。
2.3按照每只小鼠脾脏淋巴细胞使用8瓶(规格75cm)SP2/0细胞进行准备。融合前免疫小鼠淋巴细胞准备,将已经完成sRAGE免疫的小鼠(即前述的免疫后的Bab/c小鼠,称为1号小鼠)进行颈椎脱臼处死,浸入70%酒精中消毒。剪开上腹部直至小鼠左背部,分离出脾脏,除去脾脏上的结缔组织,放入无菌平皿中,加少量PBS,用两只一端磨砂的无菌载玻片磨碎脾脏,边磨边加入少量PBS,将磨出的脾脏细胞冲入平皿。随后将平皿中的脾脏细胞全部移入15ml离心管,加入适量的PBS,混匀,离心后,用PBS洗涤一遍待用。收集步骤2.2制备的所有的Sp 2/0细胞,并用PBS洗涤一遍待用。
2.4将步骤2.3处理后的脾脏细胞和Sp 2/0细胞混合在50ml离心管中,加入30-40ml含1640+20%FBS培养基(即在1640无血清培养基中加入20%FBS后制得),1000rpm离心3分钟,去上清。轻敲离心管的底部,使细胞悬在管底培液中。
2.5将分装并高压灭菌的PEG4000在水浴中溶化,加入等体积的1640无血清培养基,充分溶解,制成50%PEG4000的溶液。
2.6将步骤2.4的装有细胞的离心管放入40℃水浴,缓慢分步滴入50%PEG4000的溶液。具体的分步滴入步骤为:1)用玻璃滴管沿管壁缓慢滴入1ml 50%PEG4000的溶液,持续时间2分钟,停顿30秒;2)用与步骤1)同样的方法滴入1ml的1640完全培养基,持续时间1分钟,并重复1次;3)用步骤1)同样的方法滴入1ml的1640完全培养基,持续时间0.5分钟,并重复1次;4)加入完全培养基15ml,离心1分钟,去上清,轻敲底部。
2.7最后将步骤2.6处理后的离心管中加入25ml含HAT的完全培养基,然后将离心管中的溶液以50μl/孔种入含有步骤1.1的饲养细胞的96孔板。将96孔板放在CO
3、杂交瘤细胞筛选和克隆化
选择融合后分泌抗体最高的3个孔的细胞进行第二轮筛选,按照0.8个细胞/孔的细胞密度用含有HT的1640+10%FBS培养基将细胞稀释后种入含有饲养细胞的96孔板中,在5%CO
表1
对于优选的抗体阳性孔细胞,移到有饲养层(即步骤2.1中分离的用于共培养的饲养细胞)的组织培养瓶中继续培养,并传代2次之后保存,并进行再一次的有限稀释和建立稳定单克隆株,获得单克隆细胞质A5和Y9。
4、抗人RAGE抗体的基因克隆
对表达抗RAGE抗体的单克隆细胞株A5和Y9进行扩增后,收集1╳10E6细胞,用1ml的TRIzol试剂(美国Thermofisher公司)裂解细胞和抽提细胞总RNA。以杂交瘤细胞(Y5、Y9)的总RNA作为逆转录模版,采用逆转录试剂盒(大连宝生物工程有限公司)和参考文献的技术路线合成抗体克隆引物和进行逆转录合成cDNA和对编码抗体轻链和重链可变区的DNA序列进行PCR扩增(Andrew Bradbury,《Antibody Engineering》,Springlinker出版社,2010年,15-20页)。获得了如图2所示的DNA产物,经过通过DNA测序后属于编码小鼠抗体可变区的完整序列,其中A5的重链可变区氨基酸序列如SEQ ID NO.1所示,轻链可变区氨基酸序列SEQ ID NO.2所示。对抗体A5、Y9的重链可变区氨基酸序列和轻链可变区氨基酸序列进行分析,获得了A5抗体重链的CDR1、CDR2和CDR3的氨基酸序列分别为SEQ ID NO.5、SEQ IDNO.6、SEQ ID NO.7,重链的FR1、FR2、FR3氨基酸序列分别为SEQ ID NO.8、SEQ ID NO.9、SEQID NO.10,A5抗体轻链的CDR1、CDR2、CDR3的氨基酸序列分别为SEQ ID NO.11、SEQ IDNO.12、SEQ ID NO.13,A5抗体轻链的FR1、FR2、FR3氨基酸序列分别为SEQ ID NO.14、SEQ IDNO.15、SEQ ID NO.16;Y9抗体重链的CDR1、CDR2、CDR3的氨基酸序列分别为SEQ ID NO.17、SEQ ID NO.18、SEQ ID NO.19,Y9抗体重链的FR1、FR2、FR3氨基酸序列分别为SEQ IDNO.20、SEQ ID NO.21、SEQ ID NO.22,Y9抗体轻链的CDR1、CDR2、CDR3的氨基酸序列分别为SEQ ID NO.23、SEQ ID NO.24、SEQ ID NO.25,Y9抗体轻链的FR1、FR2、FR3氨基酸序列分别为SEQ ID NO.26、SEQ ID NO.27、SEQ ID NO.28,详见表2,3。
表2
表3
实施例2抗人RAGE嵌合抗体表达质粒的构建
在本例示性方案中,我们将鼠源抗体A5的可变区和人IgG1型抗体的恒定区(SEQID NO.29、SEQ ID NO.30)组装合成嵌合抗体进行抗体的人源化改造。具体步骤如下:
以上述实施例1中克隆得到的编码鼠源抗人RAGE抗体A5的重链可变区DNA作为模板,以引物A5H1-V-F(5’-3’:CTAGTCTAGAATGGACTCCAGGCTCAAT,SEQ ID NO.33)和引物A5H1-V-R(5’-3’:CGCGCTGCTCACGGTTGAGGAGACGGTGACCGTGGTCCCTGC,SEQ ID NO.34)克隆编码鼠源抗RAGE抗体A5的重链可变区片段(氨基酸序列SEQ ID NO.1、碱基序列SEQ ID NO.3);以编码人IgG1型抗体重链的核酸为模板,以引物A5H1-C-F(5’-3’:GTCACCGTCTCCTCAACCGTGAGCAGCGCG,SEQ ID NO.35)和引物A5H1-C-R(5’-3’:CCGGAATTCTCACTTCCCGGGGCTCAG,SEQ ID NO.36)扩增人源IgG1型抗体重链恒定区的核酸片段(氨基酸序列SEQ ID NO.30、碱基序列SEQ ID NO.32),PCR程序为94℃10s,55℃10s,72℃10s,30个循环,将得到的PCR产物经琼脂糖凝胶电泳回收后备用;
overlapping PCR将扩增所得鼠源抗RAGE抗体A5的重链可变区核酸序列(SEQ IDNO.3)与人源Ig G1型重链恒定区核酸序列(SEQ ID NO.31)进行连接,具体方法为:将上述得到的编码A5重链可变区的DNA片段与编码人IgG1型抗体重链恒定区的DNA片段混合,以该混合DNA为模板,以引物A5H1-V-F和引物A5H1-C-R为上下游引物进行扩增,PCR条件为94℃10s,55℃10s,72℃10s,30个循环,PCR检测结果如图3所示,目的片段条带大小与预期相符,表明目的基因扩增成功。
将得到的产物片段经琼脂糖凝胶电泳回收后用XbaI和EcoRⅠ处理,并与同样经过XbaI和EcoRⅠ处理的pcDNA3.1(-)连接。连接产物转化大肠杆菌DH5α感受态细胞,将转化细胞涂布于含50μg/mL氨苄西林的琼脂平板在37℃过夜培养。挑取平板上长出的单克隆,于5mL含50μg/mL氨苄西林的LB培养基中震荡培养过夜,并提取质粒,对其进行测序,将测序结果正确的质粒命名为A5H1并保存备用。
以上述克隆得到的编码鼠源抗人RAGE抗体的轻链可变区DNA作为模板,以引物A5L1-V-F(5’-3’:CTAGTCTAGAATGAGGGTCCTTGCTGAG,SEQ ID NO.37)和引物A5L1-V-R(5’-3’:CCGGAATTCGGTCCGCTTGATCTCCAGCTTGGTCCCCCC,SEQ ID NO.38)克隆编码鼠源抗RAGE抗体A5的轻链可变区片段(氨基酸序列SEQ ID NO.2、碱基序列SEQ ID NO.4);以引物A5L1-C-F(5’-3’:CTAGTCTAGAGGGGGGACCAAGCTGGAGATCAAGCGGACC,SEQ ID NO.39)和引物A5L1-C-R(5’-3’:CCGGAATTCTCAGCACTCGCCCCGGTT,SEQ ID NO.40)编码人IgG1型抗体轻链的核酸为模板,以扩增人源IgG1型抗体轻链恒定区的核酸片段(氨基酸序列SEQ ID NO.29、碱基序列SEQ ID NO.31),PCR程序为94℃10s,55℃10s,72℃10s,30个循环,将得到的PCR产物经琼脂糖凝胶电泳回收后备用;
overlapping PCR将扩增所得鼠源抗RAGE抗体A5的轻链可变区核酸序列(SEQ IDNO.4)与人源Ig G1型轻链恒定区核酸序列(SEQ ID NO.31)进行连接,具体连接方法为:将上述得到的编码A5轻链可变区的DNA片段与编码人IgG1型抗体轻链恒定区的DNA混合,以该混合DNA为模板,以引物A5L1-V-F和引物A5L1-V-R为上下游引物进行扩增,PCR条件为94℃10s,55℃10s,72℃10s,30个循环,PCR检测结果如图3所示,目的片段条带大小与预期相符,表明目的基因扩增成功。
将得到的产物片段经琼脂糖凝胶电泳回收后用XbaI和EcoRⅠ处理,并与同样经过XbaI和EcoRⅠ处理的pcDNA3.1(-)连接。连接产物转化大肠杆菌DH5α感受态细胞,将转化细胞涂布于含50μg/mL氨苄西林的琼脂平板在37℃过夜培养。挑取平板上长出的单克隆,于5mL含50μg/mL氨苄西林的LB培养基中震荡培养过夜,并提取质粒,对其进行测序,将测序结果正确的质粒命名为A5L1并保存备用。
实施例3.抗人RAGE嵌合抗体的表达
在本例示性实施方案中,我们采用HEK293E细胞瞬时表达方式进行抗人RAGE的人鼠嵌合抗体的表达。将上述步骤1构建得到的抗人RAGE的人鼠嵌合抗体A5’的轻链表达质粒A5L1及重链表达质粒A5H1按照轻重链质粒质量比为3:1进行HEK293E的瞬时表达。具体步骤如下:
3.1转染前一天用新鲜Gibco Freestyle 293培养基将HEK293E细胞稀释至1.5-2.5×10
3.2转染当日,按照每10
3.3 1000rpm 5min离心收集步骤2.1获得的HEK293E细胞,经Gibco Freestyle293培养基洗涤细胞1次,1000rpm 5min离心收集细胞,用200ml Gibco Freestyle 293培养基重悬细胞至细胞密度为4×10
3.4将孵育的DNA-PEI复合物加入步骤2.3的细胞中,37℃,110rpm,5%CO
实施例4.抗人RAGE的人鼠嵌合抗体A5’的纯化
将步骤2获得的HEK293E瞬时表达A5’所收集的上清用等体积PBS(20mM PBS,150mMNaCl,pH 6.8-7.4)稀释,上到预先用PBS平衡的Protein A(蛋白A)亲和层析柱,上样完毕后用5倍柱体积的PBS洗涤,用pH5.0的100mM柠檬酸缓冲液洗除去杂组份,用pH3.0的100mM柠檬酸缓冲液洗脱抗体,洗脱时用1.5mL EP管收集洗脱液,800μl/管,用pH9.0的1M Tris-Hcl缓冲液立即中和收集到的洗脱样品。利用还原型SDS-PAGE胶查看收集蛋白纯化情况(图4),合并含有目的蛋白的收集管。将Protein A纯化所得A5’抗体用MILLIPORE Amicon Ultra(30MWCO)超滤离心管浓缩并将溶解蛋白的溶液置换为PBS。
利用BCA试剂盒测定抗体浓度:A5’:3.51mg/ml(3ml),即400ml转染体系可得到A5’抗体9.53mg(A5’抗体产量为23.83mg/L)。将蛋白用0.22μm灭菌滤头过滤除菌后,分装在无菌EP管中,100μl/管进行后续试验或保存于-80℃冰箱中。利用TSK G2000SWxl柱对纯化的人鼠嵌合抗体A5’进行HPLC验证纯度,HPLC结果如图5显示人鼠嵌合抗体A5’只有一个峰,峰型较为尖锐。
实施例5.抗人RAGE的人鼠嵌合抗体A5’的抗原结合能力分析
5.1酶联免疫法(ELISA)测定抗原抗体亲和力
利用ELISA实验检测纯化后的抗人RAGE的嵌合抗体A5’与抗原之间的特异性结合能力。具体方法为:用10ml抗原包被液溶解20μg sRAGE重组蛋白(人源),加入到聚苯乙烯96孔酶标板中,每孔100μl,置于4℃冰箱过夜;次日,倒去96孔板里的液体,用洗涤缓冲液洗涤3次;封闭液加入96孔板,每孔100μl,置于37℃封闭0.5小时,倒去封闭液,置于4℃冰箱保存;将纯化好的A5’抗体和非特异性人源IgG用PBS分别稀释成5μg/ml,倍比稀释13次,加入包被好sRAGE重组蛋白的96孔板中,每孔加入100μl,PBS作为阴性对照,置于37℃培养箱中1-2h;倒去96孔板里的液体,用洗涤缓冲液洗涤3次后加入辣根过氧化物酶(HRP)标记抗体:封闭液稀释辣根过氧化物酶(HRP)标记驴抗人抗体(1:10000,该抗体为商业化检测抗体,AffiniPure Donkey Anti-Human IgG(H+L),Jackson ImmunoResearch,709-005-149),每孔加入100μl,37℃培养箱中1h;倒去96孔板里的液体,用洗涤缓冲液洗涤3次;每孔加入100ul TMB底物溶液,室温暗处放置5-30min;每孔加入50μl终止液终止反应;用酶标仪测定450nm波长下吸光值。ELISA结果如图6所示,表明人鼠嵌合抗体A5’对重组人sRAGE重组蛋白具有高亲和力。
5.2生物膜层干涉技术测定A5’嵌合抗体与重组人sRAGE亲和力
测定仪器为fortebio Octet RED 96。利用生物素标记试剂盒对重组人sRAGE抗原进行生物素标记。将标记好的重组人sRAGE抗原稀释成100nm,将A5’抗体稀释成300nM,再用PBS将300nM溶液稀释成200,100,50nM。将传感器置于PBS溶液中30min,预湿备用。将PBS,重组人sRAGE抗原,平衡洗脱液,A5’抗体(50,100,200,300nm),再生缓冲液和中和缓冲液依次加入对应的96孔板中,阴性对照除将抗体的四个孔换成PBS外,其他所有孔相同;运行程序如下:
1)Baseline1:120s
2)Loading:300s
3)Baseline2:120s
4)Association:300s
5)Dissociation:300s
6)Regeneration:15s
7)Neutralization:5s
8)Regeneration和Neutralization循环3次
9)Association:300s
10)Dissociation:300s
11)Regeneration和Neutralization循环3次
12)Association:300s
13)Dissociation:300s
14)Regeneration和Neutralization循环3次
15)Association:300s
16)Dissociation:300s
采集数据后,用仪器的数据分析软件对数据进行分析,以Baseline2采集所得信号为基线并扣减参比信号(进行样品空白和传感器空白双扣除),对所得数据进行群组分析并进行拟合,结果如图7,得到A5’嵌合抗体与重组人sRAGE结合的KD值为2.15×10
5.3流式细胞术测定A5’嵌合抗体与人RAGE亲和力
建立RAGE高表达细胞株,用于测定A5’嵌合抗体与细胞表面RAGE受体的亲和力。用慢病毒转染方法构建的稳定表达RAGE蛋白的RAGE-NIH 3T3细胞。将A5’嵌合抗体与RAGE-NIH3T3细胞、NIH3T3细胞进行流式细胞实验,A5’嵌合抗体用量为1μg、2μg、5μg。流式细胞结果显示,对于NIH3T3细胞,阴性对照组和A5’抗体组吸收峰重合,抗体量达到5μg时,吸收峰也未发生偏移,说明NIH3T3细胞上没有和A5’抗体结合的靶点蛋白。对于RAGE-NIH3T3细胞,A5’抗体引起吸收峰偏移,并且1μg、2μg、5μg剂量的吸收峰重合,说明1μg剂量时,RAGE-NIH3T3细胞上的RAGE蛋白和A5’抗体的结合已经达到饱和。流式细胞术测定结果表明抗原抗体具有良好的亲和力。
实施例6.抗人RAGE的人鼠嵌合抗体A5’对细胞增殖的抑制
6.1考察人鼠嵌合抗体A5’对表达RAGE的人神经母细胞瘤细胞SH-SY5Y细胞增殖的影响。
首先将SH-SY5Y细胞培养在含有10%FBS的DMEM培养基中,培养条件为37℃,5%CO
将SH-SY5Y细胞均匀接种于96孔板中(3000个/孔),培养基为10%FBS+DMEM;培养24小时后,将细胞培养基更换为1%FBS+DMEM培养基;继续培养24小时后,吸去细胞培养基,加入含不同浓度抗体A5’的无FBS培养基,A5’抗体浓度为0、6.25、12.5、25、50μg/ml;加抗体A5’作用48h后,用CCK8试剂盒测定细胞增殖情况。CCK8结果显示,A5嵌合抗体抑制SH-SY5Y细胞增殖,并且随着抗体剂量的升高,抑制作用逐渐增强。在25μg/ml和50μg/ml剂量下,A5’抗体对SH-SY5Y细胞增殖的抑制效果有显著性差异(图8)。(0vs 25μg/ml:100±6.73%vs85.01±5.35%,P<0.01,0vs 50μg/ml:100±6.73%vs 79.64±7.94%,P<0.001)表明人鼠嵌合抗体A5’能够抑制表达RAGE的人神经母细胞瘤细胞SH-SY5Y细胞的增殖。
6.2A5’对SH-SY5Y细胞的增殖的机制
将SH-SY5Y细胞均匀接种于6孔板中(200000个/孔)。培养基为:10%FBS+DMEM;培养24小时后,将细胞培养基更换为1%FBS+DMEM培养基;饥饿培养细胞24小时后,吸去细胞培养基,加入无FBS的DMEM培养基和溶解了A5’抗体(浓度为50μg/ml)的无FBS的DMEM培养基;2小时后,用细胞刮和PBS收集6孔板中细胞,将细胞1000rpm,3min离心后,弃去上清。每孔加入100μl的1%TritonX100 PBS细胞裂解液(含1mM PMSF、1mM Na3VO4、5mM NaF),置于冰上15min,而后离心:14000rpm,4℃,10min。收集上清,用BCA试剂盒测定各组蛋白浓度,定量蛋白上样,Western Blotting分析ERK1/2和p(phosphorylation,磷酸化)-ERK1/2蛋白水平变化。
Western Blotting结果显示(图9),加入A5’抗体的SH-SY5Y细胞p-ERK/ERK比值升高(IMAGEJ软件扫描灰度),表明A5’抗体通过提高ERK1/2蛋白磷酸化水平来抑制SH-SY5Y细胞增殖,也说明A5’抗体与RAGE受体的结合可以影响ERK1/2磷酸化水平。
实施例7.人鼠嵌合抗体A5’和S100A4重组蛋白、S100A6重组蛋白之间的相互作用
S100A4、S100A6蛋白为RAGE的配体。S100A4和S100A6蛋白均可通过激活RAGE信号通路,从而激活肝星状细胞,加剧肝纤维化进程。
本例示性方案中通过考察神经母细胞瘤细胞SH-SY5Y细胞的增殖情况来考察人鼠嵌合抗体和S100A4重组蛋白、S100A6重组蛋白之间的相互作用。
首先将SH-SY5Y细胞培养在含有10%FBS的DMEM培养基中,培养条件为37℃,5%CO2饱和湿度。当细胞密度达到80-90%时,弃去细胞原有培养基,用3~5ml PBS洗去培养皿内残余的FBS,用1ml 0.25%的胰酶室温下消化3min后,加入双倍量的完全培养基终止消化。轻轻吹打成单细胞悬液,以1:3或者1:4比例传代培养或者接种到不同大小的细胞培养板中用于后续实验。
将SH-SY5Y细胞均匀接种于96孔板中(3000个/孔),培养基为10%FBS+DMEM;培养24小时后,将细胞培养更换为1%FBS+DMEM培养基;继续培养24小时后,吸去细胞培养基,用10%FBS的培养基溶解不同蛋白,加药进行试验:a)阴性:PBS+DMEM;b)A5’:20μg/ml;c)S100A4:终浓度25μM/ml;d)S100 A6:终浓度25μM/ml;e)
A5’+S100A4:终浓度A5’20μg/ml,S100A4 25μM/ml;f)A5’+S100A6:终浓度A5’20μg/ml,S100A6 25μM/ml;加抗体作用48h后,用CCK8试剂盒测定细胞增殖情况。CCK8结果显示,S100A4、S100A6蛋白均抑制SH-SY5Y细胞增殖,加入A5’抗体(20μg/ml)后,SH-SY5Y细胞活率显著提升(图10,S100 A4 vs S100A4+A5:69.07±6.34%vs 82.95±4.31%,P<0.05,S100 A6 vs S100A6+A5:37.17±6.71%vs 51.12±14.77%,P<0.05)),表明A5抗体是S100A4、S100A6的拮抗剂,一定程度上阻止了S100A4、S100A6与RAGE受体之间的相互作用。
实施例8.人鼠嵌合抗体A5’和Aβ重组蛋白之间的相互作用
Aβ诱导组织纤维化,与阿尔兹海默症的发生紧密相连,且Aβ可以诱导SH-SY5Y细胞发生自噬,诱导细胞凋亡,RAGE受体则是介导Aβ进入细胞的主要方式之一。本例示性方案中通过考察神经母细胞瘤细胞SH-SY5Y细胞的增殖情况来考察人鼠嵌合抗体A5’和Aβ重组蛋白之间的相互作用。实验方案如上所述步骤6的方法相同,CCK8结果显示,Aβ抑制了细胞活性。而加入A5’抗体后,细胞活力逐渐上升,在A5’抗体25μg/ml和50μg/ml水平上和仅加入Aβ组有显著性差异(图11,Aβvs Aβ+25μg/ml A5:61.96±4.74%vs 72.95±4.33%,P<0.05,Aβvs Aβ+50μg/ml A5:61.96±4.74%vs 76.30±4.98%,P<0.01)。结果显示,A5’抗体是Aβ的拮抗剂,可以通过与RAGE受体相结合的方式,阻止Aβ进入细胞。
实施例9.抗人RAGE人源化单链抗体(hscFV)的表达与纯化
通过分别将A5抗体的重链和轻链与人IgG序列数据库进行对比,选择氨基酸序列相似性最高的人IgG序列作为模版,对A5轻重链可变区中非CDR区序列按照人IgG序列进行突变,提高A5抗体可变区序列与人IgG对应序列的相似性。突变后的重链可变区氨基酸序列见SEQ ID No.41,轻链可变区氨基酸序列见SEQ ID No.42。通过基因合成,利用突变后的序列构建人源化抗RAGE单链抗体(hscFV),VL和VH之间用3个重复的GGGGS肽链连接,合成基因序列见SEQ ID NO.43。将合成的hscFV表达序列用通用的方法构建到商业化表达载体pET28a(+)中。采用大肠杆菌BL21(DE3)作为宿主菌,参考文献诱导条件和表达方法(Journal of Biotechnology,2000,77:169–178),利用包涵体表达的方法表达hscFV抗体,采用镍亲和层析进行分离,获得纯化后hscFV抗体的SDS-PAGE电泳结果见图12。其中泳道1:流穿,2:20mM咪唑洗脱组分,3-4:50mM咪唑洗脱组分,5-6:100mM咪唑洗脱组分,7-8:200mM咪唑洗脱组分,9-10:500mM咪唑洗脱组分。
实施例10.抗RAGE的hscFV与抗原的亲和力
针对抗人RAGE抗体A5进行人源化后是否改变其与人RAGE的亲和力的问题,我们测定人源化后A5的单链抗体hscFV与RAGE的结合能力。将RAGE蛋白用包被缓冲液稀释为2μg/mL,4℃包被过夜。倒去包被液,加入PBS,300μL/孔,静置5分钟后倒出,重复三次。每孔加入封闭液(1%BSA)100μl,4℃封闭过夜后弃封闭液,再用PBST洗涤3次并拍干。对hscFV的样品进行倍比稀释,取每个样品100μl加入包被了RAGE的孔内,每个样品设3个重复孔。37℃孵育2个小时后弃去酶标板中的样品,重复洗涤4次,每次5分钟。每孔加入1:20000新鲜稀释的HRP-小鼠抗His抗体(美国Protech生物技术公司)100μL,37℃孵育60分钟,重复洗涤4次,每次5分钟。每孔加入100μL单组份TMB显色液(北京索莱宝生物技术公司),室温避光放置5分钟。每孔加50ul的2M硫酸终止反应,酶标仪读取450nm处吸光值。结果如图13所示,表明A5抗体的人源化改造依然保持识别和结合RAGE的特性。
本发明具体应用途径很多,以上所述仅是本发明的优选实施方式。应当指出,以上实施例仅用于说明本发明,而并不用于限制本发明的保护范围。对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进,这些改进也应视为本发明的保护范围。
序列表
<110> 上海交通大学
<120> 一种抗终末糖基化蛋白受体的抗体及其应用
<130> KAG45787
<160> 43
<170> SIPOSequenceListing 1.0
<210> 1
<211> 125
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 1
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Arg Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Asp Lys Gly Leu Glu Trp Val
35 40 45
Ala Tyr Ile Ser Gly Gly Ser Asn Val Ile Tyr Tyr Ala Asp Thr Val
50 55 60
Glu Gly Arg Phe Thr Ile Ser Arg Asp Asn Pro Lys Asn Thr Leu Phe
65 70 75 80
Leu Gln Met Thr Ser Leu Arg Ser Glu Asp Ala Ala Met Tyr Tyr Cys
85 90 95
Val Arg Asn Phe Arg Tyr Asn Gly Ser Ser Leu His Tyr Trp Tyr Phe
100 105 110
Asp Val Trp Gly Ala Gly Thr Thr Val Thr Val Ser Ser
115 120 125
<210> 2
<211> 104
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 2
Asp Ile Gln Met Asn Gln Ser Pro Ser Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Asp Thr Ile Thr Ile Thr Cys His Ala Ser His His Ile Asn Val Trp
20 25 30
Val Thr Trp Tyr Gln Gln Lys Pro Gly Asn Ile Pro Lys Leu Leu Ile
35 40 45
Tyr Lys Ala Ser Lys Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Phe Gly Thr Gly Phe Ser Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Gln Gln Gly Gln Ser Tyr Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu
100
<210> 3
<211> 376
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 3
gatgtgcagc tggtggagtc tgggggaggc ttagtgcagc ctggagggtc ccggaaactc 60
tcctgtgcag cctctggatt cactttcagt agctttggaa tgcactgggt tcgtcaggct 120
ccagacaagg ggctggagtg ggtcgcatac attagtggtg gcagtaatgt catctactat 180
gcagacacag tggagggccg attcaccatc tccagagaca atcccaagaa caccctgttc 240
ctgcaaatga ccagtctaag gtctgaggac gcggccatgt actattgtgt aagaaacttc 300
cgttacaacg gtagtagcct tcactactgg tacttcgatg tctggggcgc agggaccacg 360
gtcaccgtct cctcag 376
<210> 4
<211> 314
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 4
gacatccaga tgaatcagtc tccatccagt ctgtctgcat cccttggaga cacaattacc 60
atcacttgcc atgccagtca tcacattaat gtttgggtaa cctggtacca gcagaaacca 120
ggaaatattc ctaaactttt gatctataag gcttccaagt tgcactcagg cgtcccatca 180
aggtttagtg gcagtggatt tggaacaggt ttctcattaa ccatcagcag cctgcagcct 240
gaagacattg ccacttacta ctgtcaacag ggtcaaagtt atccgtacac gttcggaggg 300
gggaccaagc tgga 314
<210> 5
<211> 8
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 5
Gly Phe Thr Phe Ser Ser Phe Gly
1 5
<210> 6
<211> 8
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 6
Ile Ser Gly Gly Ser Asn Val Ile
1 5
<210> 7
<211> 18
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 7
Val Arg Asn Phe Arg Tyr Asn Gly Ser Ser Leu His Tyr Trp Tyr Phe
1 5 10 15
Asp Val
<210> 8
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 8
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Arg Lys Leu Ser Cys Ala Ala Ser
20 25
<210> 9
<211> 17
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 9
Met His Trp Val Arg Gln Ala Pro Asp Lys Gly Leu Glu Trp Val Ala
1 5 10 15
Tyr
<210> 10
<211> 38
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 10
Tyr Tyr Ala Asp Thr Val Glu Gly Arg Phe Thr Ile Ser Arg Asp Asn
1 5 10 15
Pro Lys Asn Thr Leu Phe Leu Gln Met Thr Ser Leu Arg Ser Glu Asp
20 25 30
Ala Ala Met Tyr Tyr Cys
35
<210> 11
<211> 6
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 11
Arg His Ile Asn Val Trp
1 5
<210> 12
<211> 3
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 12
Asn Ala Ser
1
<210> 13
<211> 9
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 13
Leu Leu Gly Gln Ser Tyr Pro Tyr Ser
1 5
<210> 14
<211> 26
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 14
Asp Ile Arg Met Asn His Ala Pro Ser Ser Leu Ser Ala Ser Leu Val
1 5 10 15
Asp Thr Ile Thr Ile Ser Cys His Ala Ser
20 25
<210> 15
<211> 17
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 15
Gly Thr Trp Tyr Gln Gln Lys Pro Glu Asn Ile Pro Lys Leu Leu Ile
1 5 10 15
Tyr
<210> 16
<211> 36
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 16
Arg Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly Asn Gly Phe Gly
1 5 10 15
Thr Gly Phe Ser Leu Thr Ile Asn Asn Leu Gln Pro Glu Asp Ile Ala
20 25 30
Thr Tyr Tyr Cys
35
<210> 17
<211> 8
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 17
Gly Phe Thr Phe Ser Asp Phe Tyr
1 5
<210> 18
<211> 10
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 18
Ser Arg Asp Lys Ala Asn Asp Tyr Thr Thr
1 5 10
<210> 19
<211> 14
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 19
Ala Arg Asp Ala Tyr Tyr Gly Asn Tyr Val Lys Phe Ala Tyr
1 5 10
<210> 20
<211> 25
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 20
Glu Val Lys Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Thr Ser
20 25
<210> 21
<211> 17
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 21
Met Glu Trp Val Arg Gln Pro Pro Gly Lys Arg Leu Glu Trp Ile Ala
1 5 10 15
Ala
<210> 22
<211> 38
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 22
Glu Tyr Ser Ala Ser Val Lys Gly Arg Phe Ile Val Ser Arg Asp Thr
1 5 10 15
Ser Gln Ser Ile Leu Tyr Leu Gln Met Asn Ala Leu Arg Ala Glu Asp
20 25 30
Thr Ala Ile Tyr Tyr Cys
35
<210> 23
<211> 6
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 23
Gln Asp Ile Asn Lys Phe
1 5
<210> 24
<211> 3
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 24
Tyr Thr Ser
1
<210> 25
<211> 8
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 25
Leu Gln Tyr Asp Asn Leu Arg Thr
1 5
<210> 26
<211> 26
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 26
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Gly Asn Val Thr Ile Thr Cys Lys Ala Ser
20 25
<210> 27
<211> 17
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 27
Ile Ala Trp His Gln Tyr Lys Pro Gly Lys Gly Pro Arg Leu Leu Ile
1 5 10 15
His
<210> 28
<211> 36
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 28
Thr Leu Gln Pro Gly Ile Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly
1 5 10 15
Arg Asp Tyr Ser Phe Ser Ile Ser Asn Leu Glu Pro Glu Asp Ile Ala
20 25 30
Thr Tyr Tyr Cys
35
<210> 29
<211> 106
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 29
Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln
1 5 10 15
Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr
20 25 30
Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser
35 40 45
Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr
50 55 60
Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys
65 70 75 80
His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro
85 90 95
Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
100 105
<210> 30
<211> 330
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 30
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
1 5 10 15
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
65 70 75 80
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
100 105 110
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
115 120 125
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
130 135 140
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
145 150 155 160
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
165 170 175
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
180 185 190
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
195 200 205
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
210 215 220
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu
225 230 235 240
Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
245 250 255
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
260 265 270
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
275 280 285
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
290 295 300
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
305 310 315 320
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
325 330
<210> 31
<211> 318
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 31
actgttgctg ctccatctgt ttttattttt ccaccatctg atgaacaact taaatctgga 60
actgcttctg ttgtttgtct tcttaataat ttttatccaa gagaagctaa agttcaatgg 120
aaagttgata atgctcttca atctggaaat tctcaagaat ctgttactga acaagattct 180
aaagattcta cttattctct ttcttctact cttactcttt ctaaagctga ttatgaaaaa 240
cataaagttt atgcttgtga agttactcat caaggacttt cttctccagt tactaaatct 300
tttaatagag gagaatgt 318
<210> 32
<211> 993
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 32
gcctccacca agggcccatc ggtcttcccc ctggcaccct cctccaagag cacctctggg 60
ggcacagcgg ccctgggctg cctggtcaag gactacttcc ccgaaccggt gacggtgtcg 120
tggaactcag gcgccctgac cagcggcgtg cacaccttcc cggctgtcct acagtcctca 180
ggactctact ccctcagcag cgtggtgacc gtgccctcca gcagcttggg cacccagacc 240
tacatctgca acgtgaatca caagcccagc aacaccaagg tggacaagaa agttgagccc 300
aaatcttgtg acaaaactca cacatgccca ccgtgcccag cacctgaact cctgggggga 360
ccgtcagtct tcctcttccc cccaaaaccc aaggacaccc tcatgatctc ccggacccct 420
gaggtcacat gcgtggtggt ggacgtgagc cacgaagacc ctgaggtcaa gttcaactgg 480
tacgtggacg gcgtggaggt gcataatgcc aagacaaagc cgcgggagga gcagtacaac 540
agcacgtacc gggtggtcag cgtcctcacc gtcctgcacc aggactggct gaatggcaag 600
gagtacaagt gcaaggtctc caacaaagcc ctcccagccc ccatcgagaa aaccatctcc 660
aaagccaaag ggcagccccg agaaccacag gtgtacaccc tgcccccatc ccgggatgag 720
ctgaccaaga accaggtcag cctgacctgc ctggtcaaag gcttctatcc cagcgacatc 780
gccgtggagt gggagagcaa tgggcagccg gagaacaact acaagaccac gcctcccgtg 840
ctggactccg acggctcctt cttcctctac agcaagctca ccgtggacaa gagcaggtgg 900
cagcagggga acgtcttctc atgctccgtg atgcatgagg ctctgcacaa ccactacacg 960
cagaagagcc tctccctgtc tccgggtaaa tga 993
<210> 33
<211> 28
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 33
ctagtctaga atggactcca ggctcaat 28
<210> 34
<211> 42
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 34
cgcgctgctc acggttgagg agacggtgac cgtggtccct gc 42
<210> 35
<211> 30
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 35
gtcaccgtct cctcaaccgt gagcagcgcg 30
<210> 36
<211> 27
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 36
ccggaattct cacttcccgg ggctcag 27
<210> 37
<211> 28
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 37
ctagtctaga atgagggtcc ttgctgag 28
<210> 38
<211> 39
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 38
ccggaattcg gtccgcttga tctccagctt ggtcccccc 39
<210> 39
<211> 40
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 39
ctagtctaga ggggggacca agctggagat caagcggacc 40
<210> 40
<211> 27
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 40
ccggaattct cagcactcgc cccggtt 27
<210> 41
<211> 127
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 41
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Asp Lys Gly Leu Glu Trp Val
35 40 45
Ala Tyr Ile Ser Gly Gly Ser Asn Val Ile Tyr Tyr Ala Asp Ser Val
50 55 60
Glu Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Val Arg Asn Phe Arg Tyr Asn Gly Ser Ser Leu His Tyr Trp Tyr Phe
100 105 110
Asp Val Trp Gly Ala Gly Thr Thr Val Thr Val Ser Ser Leu Glu
115 120 125
<210> 42
<211> 104
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 42
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys His Ala Ser His His Ile Asn Val Trp
20 25 30
Val Thr Trp Tyr Gln Gln Lys Pro Gly Lys Val Pro Lys Leu Leu Ile
35 40 45
Tyr Lys Ala Ser Lys Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Val Ala Thr Tyr Tyr Cys Gln Gln Gly Gln Ser Tyr Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu
100
<210> 43
<211> 732
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 43
gacatccaga tgacccagtc tccgtcttct ctgtctgctt ctgttggtga ccgtgttacc 60
atcacctgcc acgcttctca ccacatcaac gtttgggtta cctggtacca gcagaaaccg 120
ggtaaagttc cgaaactgct gatctacaaa gcttctaaac tgcactctgg tgttccgtct 180
cgtttctctg gttctggttc tggtaccgac ttcaccctga ccatctcttc tctgcagccg 240
gaagacgttg ctacctacta ctgccagcag ggtcagtctt acccgtacac cttcggtggt 300
ggtaccaaac tgggtggtgg tggttctggt ggtggtggtt ctggtggtgg tggttctgaa 360
gttcagctgg ttgaatctgg tggtggtctg gttcagccgg gtggttctct gcgtctgtct 420
tgcgctgctt ctggtttcac cttctcttct ttcggtatgc actgggttcg tcaggctccg 480
gacaaaggtc tggaatgggt tgcttacatc tctggtggtt ctaacgttat ctactacgct 540
gactctgttg aaggtcgttt caccatctct cgtgacaacg ctaaaaactc tctgtacctg 600
cagatgaact ctctgcgtgc tgaagacacc gctgtttact actgcgttcg taacttccgt 660
tacaacggtt cttctctgca ctactggtac ttcgacgttt ggggtgctgg taccaccgtt 720
accgtttctt ct 732
- 一种抗终末糖基化蛋白受体的抗体及其应用
- 一种抗人白介素-1受体辅助蛋白的单链抗体及其应用