一种基于激活函数SGRLU的深度神经网络计算系统
文献发布时间:2023-06-19 11:14:36
技术领域
本发明涉及深度学习技术领域,尤其是一种基于激活函数SGRLU的深度神经网络计算系统。
背景技术
现如今,大数据技术的快速发展极大地推动了深度学习技术的发展进程。深度学习技术以神经网络为出发点,为了让神经网络能够模拟出神经元对通过信号的选择性,人们提出了激活函数,它能够让前层网络传递来的特征信息经过非线性的变换再传递给后层网络。
激活函数的数学定义是映射h:R→R,且几乎处处可导。从定义上来看,几乎所有的连续可导函数都可以作为激活函数,但目前常见的是分段线性函数和具有指数形状的非线性函数。随着研究的不断深入,现有激活函数存在的问题不断暴露,例如神经元死亡、锯齿现象、对噪声不具有鲁棒性、深度加深精度下降、不同网络稳定性不一致等。下面对目前较为常见的几种激活函数进行介绍。
Sigmoid函数
整流线性单元ReLU函数f(x)=max(0,x)是最早提出的非饱和激活函数,如图3所示,其收敛速度比饱和激活函数快8倍,因其计算简单有效,一直应用于深度神经网络。当x≥0时,梯度恒等于1,具有梯度保持特性,能够有效地避免梯度消失和梯度爆炸的问题;然而,当x<0时,函数具有硬饱和特性,当输入落入硬饱和区,激活函数响应为0,导致梯度恒等于0,可能导致神经元不再被任何数据激活,造成大量神经元死亡的现象。PReLU为ReLU函数的衍生版,称之为带参数整流线性单元,如图4所示,该激活函数可自适应地学习整流器的参数,也可忽略额外计算成本以提高精度。
Swish函数f(x)=x·Sigmoid(β·x)是结合基本的一元函数和二元函数,建立一个简单的约束搜索空间,使用自动搜索方法实现的激活函数,如图5所示,Swish 函数具有非单调、平滑、无上界有下界的特性,并保留少量的负权重。在-5≤x≤0 时,函数有凸形区域,β参数可调节凸形形状;在x>0时,函数为介于线性函数与ReLU函数之间的平滑函数,没有引用ReLU梯度保持特性。Mish函数 f(x)=x·tanh(softplus(x))=x·tanh(ln(1+e
SELU函数和SERLU激活函数,函数形式分别如下:
SELU函数和SERLU函数为了使输入和输出满足自归一化特性,通过假设神经网络输入和输出都是独立随机变量并服从均值为0、方差为1的高斯分布,推导出激活函数的固定参数λ
基于梯度优化学习的前馈神经网络FNN、卷积神经网络,随着训练层数加深,会出现梯度消失和梯度爆炸问题,该问题受网络结构设计、权重初始化、梯度优化算法、激活函数性质等因素的影响。近几年,为了不断加深可训练的神经网络层数,深度学习技术在以下几个方面取得进步:1、训练深度神经网络时,神经网络隐层参数更新会导致网络输出层的输出数据分布发生变化,并且随着层数的增加,根据链式规则,这种偏移现象会逐渐被放大,故引入批归一化Batch Normali zation、层归一化Layer Normalization、权重归一化Weight Normalization、批归一与权重混合等方法,解决变量偏移问题,以加速训练的收敛速度,减少模型对初始化权重的依赖,有效训练大规模深度神经网络;2、网络结构方面,ResNet和 UNet残差模块的神经网络结构设计,大大缓解了在训练深层神经网络时发生梯度消失和梯度爆炸问题;3、在SGD梯度优化算法基础上提出了Adam、AdaGrad、 RMSProp等改进方法,以提高网络训练速度和学习率参数的自适应调整;4、激活函数在神经网络中引入非线性表达,强化网络学习能力,从Sigmoid、Tanh等饱和性函数发展到Softplus、Maxout、ReLU等不饱和性函数,解决深度神经网络的梯度消失问题。
虽然现有的Sigmoid、ReLU、Mish、SERLU等激活函数在神经网络中引入非线性表达,强化网络学习能力。然而,在前馈神经网络FNN使用训练参数在螺旋分类数据集SpiralData的实验中,现有激活函数存在收敛速度较慢、测试精确度较低的问题;在加深前馈神经网络FNN的深度实验中,Mish激活函数的训练速度也明显下降。在使用VGG16、Resnet50、SqueezeNet三种不同堆叠结构的 CNN深度神经网络对CIFAR-10和CIFAR-100两种数据集的实验中,现有激活函数的图像分类Top-1和Top-5精度表现不稳定。
发明内容
针对上述技术问题,本发明提出一种全新的激活函数SGRLU以及基于SGRL U的深度神经网络计算系统。
本发明保护一种深度神经网络计算系统,包括至少一个处理器、至少一个非暂时性计算机可读介质,所述非暂时性计算机可读介质存储描述神经网络的数据,所述神经网络包括实现激活函数SGRLU的至少一个激活单元;所述激活函数SGRLU由高斯函数和恒等函数复合而成,SGRLU函数在正区间与ReLU函数具有相同特性,梯度恒等于1,在负区间受可训练参数影响,呈单调性或非单调性;在负区间呈单调性时,与PReLU函数具有相同特性,在负区间呈非单调性时,与Swish函数具有类似特性。
进一步的,SGRLU函数数学表达式为
更进一步的,α=0、β=0,
本发明还保护一种存储在非暂时性计算机可读介质中的神经网络,所述神经网络包括实现激活函数的至少一个激活单元,所述激活函数采用SGRLU函数。
本发明的有益效果:
1、SGRLU函数上方无界,下方有界,上方为非饱和区,避免了Sigmoid、ta nh激活函数对于较大输入出现梯度度弥散问题而导致的训练速度过慢的问题,有界的下方有助于实现强正则化的效果;
2、SGRLU函数图像在x∈[≈-2,0]区间内呈凸形区域,且对于大的负输入具有近似零的可忽略响应,能够保证其输出服从零均值分布,又不会出现锯齿现象,加快收敛速度。对大的负输入具有可忽略的响应,一定程度上增加了激活稀疏性,能够实现对输入变化或噪声更具鲁棒性;但又不像ReLU函数完全截断,由于存在少量的负数部分,允许比较小的梯度流入,避免了ReLU函数中存在的神经元死亡问题。
3、SGRLU作为神经网络的激活函数,具有较好的训练速度,并且对于深度神经网络具有较好的训练效果,并且在精确度和一致性上也表现较好。
附图说明
图1为Sigmoid函数的曲线图;
图2为Tanh函数的曲线图;
图3为ReLU函数的曲线图;
图4为PReLU函数的曲线图;
图5为Swish函数的曲线图;
图6为Mish函数的曲线图;
图7为激活函数SGRLU(α=0,β>0)的曲线图;
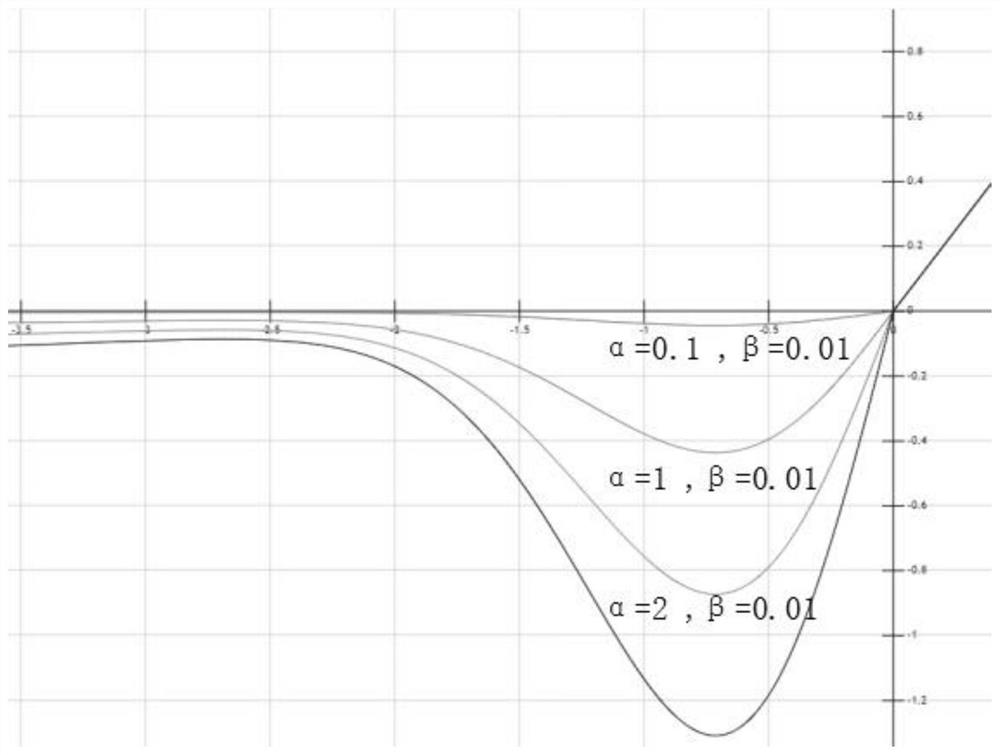
图8为激活函数SGRLU(β=0.01)不同α的曲线图;
图9为激活函数SGRLU(β=0.01)不同α的一阶导数曲线图;
图10为7种多分类数据集的可视化图,其中a为簇状数据集可视化图、b为条状数据集可视化图、c为方形数据集可视化图、d圆形数据集为可视化图、e为螺旋数据集可视化图、f为类Sigmoid数据集、g为类正态分布数据集;
图11为实验一中验证得到的α训练参数值分布直方图;
图12为实验一中α自学习训练与α固定参数两种情况的损失曲线对比图;
图13为CIFAR-10数据集中的10个类别以及每个类别中的10个随机图像;
图14为VGG16不同激活函数对CIFAR-10数据集图像分类的损失曲线;
图15为VGG16不同激活函数对CIFAR-100数据集图像分类的损失曲线;
图16为Resnet50不同激活函数对CIFAR-10数据集图像分类的损失曲线;
图17为Resnet50不同激活函数对CIFAR-100数据集图像分类的损失曲线;
图18为SqueezeNet不同激活函数对CIFAR-10数据集图像分类的损失曲线;
图19为SqueezeNet不同激活函数对CIFAR-100数据集图像分类的损失曲线。
具体实施方式
下面结合附图和具体实施方式对本发明作进一步详细的说明。本发明的实施例是为了示例和描述起见而给出的,而并不是无遗漏的或者将本发明限于所公开的形式。很多修改和变化对于本领域的普通技术人员而言是显而易见的。选择和描述实施例是为了更好说明本发明的原理和实际应用,并且使本领域的普通技术人员能够理解本发明从而设计适于特定用途的带有各种修改的各种实施例。
实施例1
一种深度神经网络计算系统,包括至少一个处理器、至少一个非暂时性计算机可读介质,所述非暂时性计算机可读介质存储描述神经网络的数据,所述神经网络包括实现激活函数SGRLU的至少一个激活单元;所述激活函数SGRLU由高斯函数和恒等函数复合而成,SGRLU函数在正区间与ReLU函数具有相同特性,梯度恒等于1,在负区间受可训练参数影响,呈单调性或非单调性;在负区间呈单调性时,与PReLU函数具有相同特性,在负区间呈非单调性时,与Swish函数具有类似特性。
SGRLU函数的数学表达式为
下面结合SGRLU函数在α、β的不同取值时的函数图像,对其进行特性分析。
一、若α=0、β=0,
因此,SGRLU函数对于正区间的激活继承了ReLU函数的梯度保持特性,梯度恒等于1,避免出现梯度消失和梯度爆炸的问题。
二、若α=0、β>0,
三、若α>0、0<β≤0.44,SGRLU函数的负区间具有与Swish函数或SERLU 函数类似形状的凸形区域,在x∈[≈-2,0]区间内,α值越大,凸形面积越大,极小值越小,如图8所示。
此时,SGRLU函数上方无界,下方有界。上方为非饱和区,避免了Sigmoid、 tanh激活函数对于较大输入出现梯度度弥散问题而导致的训练速度过慢的问题;有界的下方有助于实现强正则化的效果。
SGRLU函数图像在x∈[≈-2,0]区间内呈凸形区域,且对于大的负输入具有近似零的可忽略响应,能够保证其输出服从零均值分布,又不会出现锯齿现象,加快收敛速度。对大的负输入具有可忽略的响应,一定程度上增加了激活稀疏性,能够实现对输入变化或噪声更具鲁棒性;但又不像ReLU函数完全截断,由于存在少量的负数部分,允许比较小的梯度流入,避免了ReLU函数中存在的神经元死亡问题。
Swish函数和SERLU函数使用Sigmoid、tanh、softplus复合的指数函数对原始输入正则化而成凸形区域,而SGRLU函数使用简单的高斯函数对原始输入正则化而成凸形区域,计算更加简单。
基于上述分析,SGRLU函数可以松散地看作是一个平滑函数,它在分段线性函数和非线性函数之间进行非线性插值。α、β为可训练参数,则模型插值程度可控。
SGRLU函数与ReLU函数相同的是,上方无界和下方有界,具有分段线性、单调性;不同的是,SGRLU函数还可以是非单调可伸缩的凸形函数,具有非线性特性,这一点又类似于Swish函数或SERLU函数。SGRLU函数可训练的单调性与非单调性是区别于大多数常见激活函数的差异性。
下面再结合SGRLU函数的一阶导数在α、β的不同取值时的函数图像,对其进行特性分析。
SGRLU函数的一阶导数
一、若α=0,
二、若α>0、0<β≤0.44,SGRLU'(x)函数图像如图9所示。当-3<x<0时,α越大,一阶导数越偏离x轴,α越小,一阶导数越靠近x轴;当x<-3时,一阶导数趋于0。
下面本发明通过三个实验来验证SGRLU函数作为激活函数的有效性及其性能。
1、实验一,验证SGRLU函数训练参数α、β有效性
在前馈神经网络FNN的隐藏层后接SGRLU激活函数,将不同隐藏层的 SGRLU激活函数的参数α和β均设置为可训练参数。构建7种多分类数据集训练该前馈神经网络FNN,观察不同隐藏层参数β的训练值分布情况,选择其中一种螺旋分类SpiralData(可视化图见10.e)数据集将β固定为0.01,观察参数α的训练值分布情况。
本实验采用的7种数据集的数据可视化如图10所示,依次为簇状数据集(ClusterData)、条状数据集(StripData)、方形数据集(SquareData)、圆形数据集(CircleData)、螺旋数据集(SpiralData)、类Sigmoid数据集(SimilarSigmoidData)、类正态分布数据集(SimilarNormalData),每种数据集均有4个类别和2000个样本。为便于可视化,上述数据集图例中通过颜色区分类别,一个类别对应一种颜色,每个类别的数据具有2维特征,分别对应坐标轴的x值与y值,特征值范围均为 [-1,1],其中ClusterData、StripData、SquareData数据具有良好的可分性,对神经网络模型的特征学习要求比较低,CircleData、SpiralData、SimilarSigmoidData、 SimilarNormalData数据对神经网络模型的特征学习要求比较高,需要神经网络模型学习到较为复杂的特征。
⑴参数β的有效性验证
SGRLU激活函数在β=0.01时是凸形函数,训练β可以进一步提高收敛速度。采用7层的FNN网络结构(输入层+5个隐藏层+输出层),使用构造的7种多分类数据集对其进行训练,记录误差率降为0.01时,各个隐藏层β的训练参数值。
7种数据集在该FNN网络5个隐藏层的β值次数统计如表1所示。从表1可以看出,靠近输入层的β≤0.44居多,靠近输出层的β>1居多。统计结果表明,单调性可训练是SGRLU激活函数的一个重要特性。β≤0.44时,SGRLU激活函数为凸形非单调函数;β>1时,SGRLU激活函数为线性单调函数;0.44<β≤1 时,SGRLU激活函数介于凸形和线性函数之间。因此,单调性可训练是SGRLU 函数的一个重要特性。
表1
⑵参数α的有效性验证
当β固定不变(设置为0.01),可以通过改变α参数来控制凸形的程度。采用 22层FNN网络结构(输入层+20个隐藏层+输出层),使用4个类别共1000个样本的螺旋分类数据集SpiralData(数据可视化见图10.e)对其进行训练,记录误差率降为0.01时,各个隐藏层α的训练参数值。
验证得到的α训练参数值分布直方图如图11所示。统计结果表明,α分布在0-2之间,在a≈0.9处有一个峰值,即当β固定为0.01,α初始值为0.9。
图12为α自学习训练与α固定参数两种情况的损失曲线对比图。由图12可知,α自学习训练损失下降到0.1所需的迭代次数少,即收敛速度更快。
2、实验二,验证SGRLU函数的神经网络训练效果
本实验选用前馈神经网络FNN,权重参数更新使用反向传播算法,训练最大次数为10万次,使用4个类别共2000个样本的螺旋分类数据集SpiralData(数据可视化见图10.e)对其进行训练,通过调节学习率、加深神经网络层数,分别观察Sigmoid、ReLU、Mish、SERLU、SGRLU激活函数的训练效果。
选取螺旋分类数据集SpiralData中90%的样本作为训练集,10%的样本作为测试集。为了提高网络训练速度并减小训练过程中的震荡现象,采用批量梯度下降法(BatchGradient Descent)进行模型训练,BatchSize大小设置为90,即每次迭代以90个样本为一组数据。螺旋分类数据集SpiralData的数据分类实验解决的是多分类问题,输入数据为样本的横坐标和纵坐标,输出数据为样本的类别,因此,神经网络的输入节点数为2,输出节点数为4。由于每次训练的网络初始权值是满足正态分布的随机数据,训练结果存在偶然性,因此,针对每一种给定的深度神经网络模型进行10次训练,分别取训练速度及精度的平均值进行对比。
⑴调整学习率
学习率是神经网络学习过程中影响权重值调整幅度的重要参数。学习率过大容易造成网络学习不充分,而学习率过小则会导致训练速度缓慢。本实验分别取学习率为0.01、0.03和0.1,采用4层FNN网络结构(输入层+2个隐藏层+输出层),每个隐藏层20个神经元,观察五种不同激活函数下网络的训练情况。表 2统计了五种不同激活函数在不同学习率下训练误差率降为0.01时的迭代次数,表3统计了训练次数达到最大迭代次数时的测试误差率,其中“-”均表示不能训练。
表2
表3
实验结果表明,该FNN网络中使用SERLU、SGRLU的训练速度要明显优于Sigmoid、Mish、ReLU,并且在学习率增长到0.1时,仍然保持较低的测试误差率。在该FNN网络结构下,ReLU与SGRLU的训练精度差异不大,Mish 和SERLU的训练精度则要略差于前两者。Sigmoid在小学习率时,收敛速度过慢,本实验训练超过10万次,损失值无法下降,无法训练。
⑵加深网络深度
通过改变网络的隐层数量加深网络深度,目的是观察深度神经网络中不同激活函数的表现,以寻找适应性更强的激活函数。在4层FNN网络(输入层+2个隐藏层+输出层)的基础上,分别将隐藏层加至4层、6,即分别形成6层FNN 网络、8层FNN网络,每个隐藏层20个神经元。本实验固定学习率为0.03,表4 统计了五种不同激活函数在不同数量隐藏层结构下训练误差率降至0.01时的迭代次数,表5统计了训练结束时的测试误差率,其中“-”均表示不能训练。
表4
表5
实验结果表明,随着网络深度的增加,采用五种不同激活函数的神经网络在训练精度上均有不同幅度的提升,说明网络层次的加深有助于数据特征的提取。然而,当隐层数量增加至4个时,使用Mish激活函数的训练速度明显下降,且在10次训练中超过一半出现了梯度消失现象,说明Mish函数很难适应于深度神经网络的训练;当隐层数目增加至6个时,ReLu与SGRLU的训练精度差异不大,Mish和SERLU的精度则要略差于前两者。
3、实验三,通过不同堆叠结构的卷积神经网络,不同数据集进行图像分类任务训练,验证SGRLU激活函数的性能
图像分类任务是计算机视觉中非常重要的一个分支,卷积神经网络在图像分类中的特征提取主干网络结构也非常多。本实验使用具有代表性的VGG16、 Resnet50、SqueezeNet三种不同堆叠结构的卷积神经网络CNN,在其他训练参数保持一致的情况下,分别使用ReLU、Mish、SERLU、SGRLU四种激活函数,对CIFAR-10和CIFAR-100两种数据集图像分类任务的训练结果进行对比。实验的操作系统为Ubuntu 18.04,GPU显卡型号为NvidiaGeForce GTX 2080Ti (12GB),使用PyTorch 1.4.0深度学习框架,Python版本为3.6。
⑴本实验采用的三种卷积神经网络的简单介绍
①VGG是2014年Simonyan等提出的用于图像分类任务的深度神经网络模型,根据卷积核大小和卷积层数量不同,共有VGG11、VGG13、VGG16、VGG19 等6种网络结构配置。本实验选择由13个卷积层、3个全连接层和5个池化层堆叠的VGG16网络结构,默认在卷积层和全连接层后使用ReLU激活函数。
②2015年He-Kaiming等对传统深度神经网络的堆叠网络结构进行改进,在两个或多个网络层之间加入短路机制的残差学习模块。深度残差网络(Deep residual network,ResNet)就是通过将多个残差学习模块堆积在一起而形成的深度神经网络,是当前应用最为广泛的特征提取网络。ResNet的典型网络结构有 ResNet18、ResNet34、ResNet50。本实验选用Resnet50网络结构,先对输入做卷积操作,之后包含4个残差学习单元,最后全连接操作进行分类任务,总共使用 50次卷积,默认激活函数使用ReLU。
③SqueezeNet是2017年Han等提出的一种压缩的、轻量的、高效的CNN 模型,SqueezeNet网络基本单元采用Fire module模块化的卷积(包括1x1卷积核的squeeze层、混合1x1和3x3卷积核的expand层),降低了CNN模型的参数数量和网络复杂度。整个SqueezeNet使用8个Fire module堆积而成,默认激活函数使用ReLU。
⑵本实验采用的CIFAR-10和CIFAR-100图像数据集是8000万微小图像数据集的标注子集,由AlexKrizhevsky,VinodNair和Geoffrey Hinton收集。
①CIFAR-10数据集包含60000张32x32颜色图像,分为10个类,每个类 6000张图像,有50000张训练图像和10000张测试图像,图13所示是CIFAR-10 数据集中的10个类别以及每个类别中的10个随机图像。
②CIFAR-100有100个类,每个类包含600个图像,每个类有500个训练图像和100个测试图像。CIFAR-100中的100个类被分为20个超类。每个图像都有一个“fine”标签(所属类)和一个“coarse”标签(所属超类)。
⑶将Mish、SERLU、SGRLU激活函数在VGG16、Resnet50、SqueezeNet 三种不同堆叠结构的卷积神经网络上替换所有默认激活函数ReLU,分别使用 CIFAR-10数据集和CIFAR-100数据集进行图像分类任务训练。所有网络初始权重参数都用He-初始化,BatchSize大小设置为256,即每次迭代以256张图像为一组数据,共训练200个epoch,使用Adam(AdaptiveMoment Estimation)优化器,同时保持其他网络参数不变,仅改变激活函数,记录训练结果的精确度和损失曲线。
表6
表7
ReLU、Mish、SERLU、SGRLU四种激活函数在VGG16、Resnet50和 SqueezeNet三种卷积神经网络的图像分类TOP-1和TOP-5精确度统计,CIFAR-10 数据集图像分类的精确度统计见表6,CIFAR-100数据集图像分类的精确度统计见表7。
从表6可以看出,在上述三种网络架构下和两种数据集上,使用SGRLU的 TOP-1和TOP-5精确度均优于默认的ReLU激活函数。
在CIFAR-10实验中,VGG16架构下,SGRLU的Top-1精度比ReLU提高了 0.92%。虽然Mish在VGG16架构下,比SGRLU有略高的Top-5精确度,但同时发现Mish在网络较深的Resnet50模型中的性能不一致性。在Resnet50模型中,Mish 的Top-1精确度表现最差,SGRLU的Top-1精度相对Mish提高了2.62%,相对ReLU 提高了0.85%、相对SERLU提高了1.59%。在CIFAR-100实验中,SGRLU的Top-1 和Top-5精度表现稳定。由此表明,SGRLU在三种不同堆叠结构和深度的卷积神经网络结构中网络训练的精确度保持稳定。
比较三种不同堆叠结构对CIFAR-10和CIFAR-100数据集图像分类的损失曲线(参照图14-19)可知,SGRLU的损失下降到0.1、0.05所需的迭代次数均要快于ReLU、Mish、SERLU。
综上,三种不同堆叠结构的卷积神经网络,使用两种数据集进行图像分类任务训练的结果表明,选择使用SGRLU激活函数的性能和一致性表现较好。
显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域及相关领域的普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都应属于本发明保护的范围。显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域及相关领域的普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都应属于本发明保护的范围。
- 一种基于激活函数SGRLU的深度神经网络计算系统
- 一种面向深度神经网络的自适应激活函数参数调节方法