边缘计算环境中基于深度Q神经网络的工作流调度方法
文献发布时间:2023-06-19 11:16:08
技术领域
本发明主要涉及深度强化学习和边缘计算领域,特别是涉及到一种边缘计算环境中基于深度Q神经网络的工作流调度方法。
背景技术
基于移动边缘计算(MEC)的移动边缘网络可以为流行的移动应用程序(如虚拟/增强现实,移动游戏,车载网络应用程序等)提供低延迟和高计算量。在移动边缘网络中,带有计算和存储功能的边缘云服务器部署在移动用户附近,对于移动设备而言,将服务卸载到边缘服务器上可以为移动用户提供最佳的服务质量,即最小的响应延迟。
对于移动应用可以定义为一系列任务的执行,而这些任务的执行顺序由任务之间对结果数据的依赖性得到。通常可由有向无环图(DAG)表示移动设备生成的工作流,工作流中的任务节点集合对应图中的节点集合,而任务节点间存在数据依赖的关系则被表示为图中的有向边。除了调度工作流任务带来的难点外,还存在两个难点:(1)移动边缘计算场景的动态未知性。(2)用户与边缘服务器之间的信息交互存在着数据泄露和数据被篡改的可能性,给用户造成损失。
因此,如何在移动边缘计算环境中保证移动用户工作流调度的服务质量和信息安全是移动边缘计算研究中的一个重要问题。
发明内容
为了解决上述问题,本发明提供一种边缘计算环境中基于深度Q神经网络的工作流调度方法。
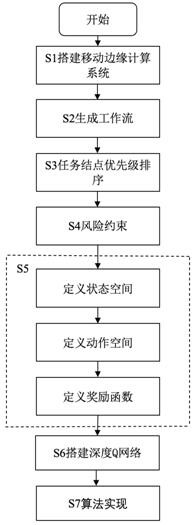
本发明包含以下步骤:
S1.构建边缘计算环境模型:
由U来表示移动设备,由集合eNB={eNB
移动用户的计算能力由C
移动设备U与n个边缘服务器之间的传输速率为
S2.生成工作流:
将移动设备生成的工作流中所包含的任务节点个数设为K,对1-K进行随机排列,并以此排列顺序作为有向无环图的拓扑排序结果来生成对应的有向无环图G=
有向边e
S3.任务结点优先级排序:
为每个任务节点v
其中
通过从结束节点向其前驱节点一步步计算得到所有工作流中任务节点的权重后,按照权重大小进行降序排序作为工作流中任务节点的执行顺序。
S4.风险约束:
在移动设备将任务节点v
任务数据被攻击的风险概率为
S5.构建移动边缘环境中的马尔可夫决策过程模型,具体如下:
S51.定义系统的状态
S52.定义系统的动作
S53.定义系统的奖励(τ)=-T
S6.搭建深度Q网络:
所述深度Q神经网络包括估计Q神经网络、target神经网络和经验池;
Q神经网络与目标Q神经网络具有一样的网络结构,而且Q神经网络会定期的将网络参数传递给target神经网络;
经验池用于存放每个时间片中与环境交互得到的状态转移样本,每次学习需要从经验池中随机抽取固定批量的四元组对估计Q神经网络进行训练。
S7.算法实现:
给定一个常量episode作为学习时间,学习并调度完工作流中所有任务节点视为一次学习完成;在工作流调度过程中,先设置当前时间片为0;在第τ个时间片的开始,通过观察移动边缘环境的当前状态s(τ)选择并执行动作a(τ),计算执行完动作后的奖励R(s(τ),a(τ))和观测执行完动作后系统的状态s(τ′+1),并将其存储到经验池中;当经验池中存放了足够的数据之后,开始进行抽样学习。
本发明通过Q神经网络的学习和决策在大大提升在移动边缘网络环境中工作流的执行效率的同时还保证了用户的信息安全。
附图说明
图1为本发明基于深度强化学习的工作流任务调度方法的流程图;
图2为移动边缘计算环境下工作流调度的架构图;
图3为基于深度强化学习的安全感知的工作流调度策略图;
图4为任务节点数为100的工作流收敛图;
图5为本发明算法和AWM算法在风险概率变化下的对比图;
图6为本发明算法和AWM算法在服务器计算能力变化下的对比图;
图7为本发明算法和AWM算法在服务器个数变化下的对比图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图对本发明进行进一步详细说明。
相反,本发明涵盖任何由权利要求定义的在本发明的精髓和范围上做的替代、修改、等效方法以及方案。进一步,为了使公众对本发明有更好的了解,在下文对本发明的细节描述中,详尽描述了一些特定的细节部分。对本领域技术人员来说没有这些细节部分的描述也可以完全理解本发明。
如图1所示,本发明的一种边缘计算环境中基于深度Q神经网络的工作流调度方法,包括以下步骤:
S1.构建边缘计算环境模型:在实际场景中,一个移动设备周围有多个边缘服务器为其提供服务。在本发明的场景中由U来表示移动设备,由集合eNB={eNB
S2.生成工作流:将移动设备生成的工作流中所包含的任务节点个数设为K,对1-K进行随机排列,并以此排列顺序作为有向无环图的拓扑排序结果来生成对应的有向无环图G=
S3.任务结点优先级排序:本发明中通过为每个任务节点v
S4.风险约束:在移动设备将任务节点v
S5.构建移动边缘环境中的马尔可夫决策过程模型,具体包含以下步骤:
S51.定义系统的状态
S52.定义系统的动作
S53.定义系统的奖励(τ)=-T
S6.搭建深度Q网络:深度Q神经网络的搭建主要由三个功能组件组成。分别是:估计Q神经网络、target神经网络和经验池。Q神经网络与目标Q神经网络具有一样的网络结构,而且Q神经网络会定期的将网络参数传递给target神经网络。经验池用于存放每个时间片中与环境交互得到的状态转移样本,每次学习需要从经验池中随机抽取固定批量的四元组对估计Q神经网络进行训练。
S7.算法实现:给定一个常量episode作为学习时间,学习并调度完工作流中所有任务节点视为一次学习完成。在工作流调度过程中,先设置当前时间片为0。在第τ个时间片的开始,通过观察移动边缘环境的当前状态s(τ)选择并执行动作a(τ),计算执行完动作后的奖励R(s(τ),a(τ))和观测执行完动作后系统的状态s(τ′+1),并将其存储到经验池中。当经验池中存放了足够的数据之后,开始进行抽样学习。
本发明还实现了AWM基线算法,将工作流中的任务节点调度到负载最小的边缘服务器来执行,与本发明的SAWS策略进行对比。并且分别就风险概率变化、服务器计算能力变化、服务器数量变化对工作流执行时间的影响进行评估。而且从以上场景的对比中可以观察到SAWS策略是优于AWM策略的。
以任务节点数为100的工作流为例,从图4中显示了SAWS策略的学习情况,可以观察到学习的次数越多,工作流的执行时间越短并且在学习后期逐渐趋于平稳,这说明本发明可以有效的降低移动边缘环境中的工作流的执行时延。
风险概率:依次将工作流中任务执行的风险概率P
边缘服务器计算能力:分别将所有边缘服务器的计算能力设置为15GHz/s、17.5GHz/s、20GHz/s、22.5GHz/s、25GHz/s进行实验。图6中显示了两种策略在边缘服务器计算能力不同时的工作流执行情况。由图中可以观察到在边缘服务器计算能力越强,执行完工作流的时间就越短。主要是因为边缘服务器计算能力越强,对任务进行解密的时间和执行任务的时间就越短,而且当其他任务被卸载到边缘服务器上时,任务的等待时间也会变短。
边缘服务器数量:依次改变环境中边缘服务器的数量为2、4、6、8、10进行实验。图7显示了两种策略在边缘服务器个数不同时的工作流执行情况。可以观察得到,随着边缘服务器个数的增加,执行完工作流的时间就越短。主要是因为环境中的边缘服务器数量增多,卸载到每个边缘服务器上任务节点数量相应减少,任务执行的等待时间下降。
- 边缘计算环境中基于深度Q神经网络的工作流调度方法
- 分层边缘计算环境中基于深度强化学习的任务调度方法