诱导具有突变基因的细胞的死亡的组合物以及通过使用所述组合物诱导具有突变基因的细胞的死亡的方法
文献发布时间:2023-06-19 11:21:00
【技术领域】
本发明涉及一种用于诱导具有基因组序列变异的细胞的死亡的组合物,其包含核酸酶和切割剂;以及一种诱导具有基因组序列变异的细胞的死亡的方法。
【背景技术】
具有受损基因或基因组的细胞导致与生物体或其器官的存活或功能相关的问题。可能存在选择性地诱导这些细胞死亡的多种方法。然而,这些方法中的大多数也会对正常细胞造成损害,因此不适用于临床使用。
癌细胞是具有受损基因或基因组的最具代表性的细胞,这些受损基因或基因组导致生物体或其器官的存活或功能出现问题。尽管与人基因组相比,DNA损害只占很小的一部分,但对原癌基因或抑制基因的DNA损害最终增加癌症发作的可能性(Molecular CellBiology.第4版.Lodish H.,Berk A.,Zipursky S.L.等人纽约:W.H.Freeman;2000,“Section 12.4DNA Damage and Repair and Their Role in Carcinogenesis”)。
对癌症特有的突变的研究和分析被认为是开发癌症治疗剂的主要基础。例如,可以开发针对特定基因突变的治疗剂,并通过对癌症突变的研究来验证突变特征与药物反应性之间的相关性。
癌症是由基因突变的积累引起的,所述基因突变是通过生殖细胞遗传的,或者是在细胞周期中在体细胞中获得的。这些癌基因、肿瘤抑制基因和DNA修复基因的变化导致细胞丧失生长和调节机制,从而发展为癌症。
在由该过程引起的癌症中,已经观察到许多现象,其中插入了在正常细胞中未发现的新DNA序列(插入:IN)或者其中正常细胞的部分DNA缺失(缺失:Del)。在癌细胞的这种DNA中出现的特定插入或缺失DNA(IN/DEL)属于正常细胞中不存在的DNA序列,因此可用作正常细胞与癌细胞之间的分化攻击靶标。
同时,DNA双链断裂(DSB)是细胞水平上最严重的损害形式之一。受损的DNA通过非同源末端接合和同源重组来修复,而无法修复的DNA可能导致遗传信息的损害或重排,从而引起细胞死亡。
CRISPR/Cas是一种使用RNA指导的基因编辑工具,并且能够通过使用细菌诱导的核酸内切酶Cas9(或突变体切口酶)和指导RNA将指导RNA序列与基因组DNA序列匹配,从而将双链(或单链)断裂引入基因组的特定位置中。CRISPR/Cas介导的基因敲除预期比RNA干扰介导的基因敲除更有效,并为基因功能研究提供了有用的实验工具。
在研究中,已经报道CRISPR-Cas系统可以在哺乳动物细胞中起作用,并且源自微生物的适应性免疫的基因编辑技术包括Cas9(CRISPR相关蛋白9:RNA指导的DNA核酸内切酶)和指导RNA(gRNA)。指导RNA包括crRNA(CRISPR RNA)和tracrRNA(反式激活crRNA),并与Cas9结合,并通过与靶序列的碱基配对将Cas9导向至靶基因组序列以形成双链断裂(DSB)。定义靶序列的唯一标准为是否存在前间区序列邻近基序(PAM),并且前间区序列邻近基序(PAM)的序列根据识别其的Cas蛋白而不同。例如,已知源自化脓性链球菌(S.pyogenes)的Cas9是5'-NGG-3'(其中N是A、T、G或C);源自嗜热链球菌(S.thermophilus)的Cas9是5'-NNAGAAW-3';并且源自空肠弯曲杆菌(C.jejuni)的Cas9是5'-NNNNRYAC-3'。所述PAM可以用于基因编辑,因为所述序列在人基因组上以规律的间隔排列。
同时,已经报道,所述CRISPR/Cas系统可以应用于人癌症疗法(Oncotarget.2016年3月15日;7(11):12305-17)。然而,这表明,基于与癌症发作相关的多个基因突变,基因组的一个或多个部分的修饰或缺失可能增加提供有效的癌症治疗剂的可能性。
在该技术背景下,本发明人发现具有基因组序列变异的细胞(如癌细胞)具有其固有的In/Del序列,还发现能够由细胞的特定DNA位点中的多个DNA DSB(双链断裂)诱导具有基因组序列变异的细胞的死亡,所述多个DNA DSB源自基于In/Del序列产生的一种或多种切割剂和核酸酶,从而基于该发现完成了本发明。
【发明内容】
【技术问题】
因此,已鉴于上述问题而产生本发明,并且本发明的一个目的是提供一种包含核酸酶和切割剂的组合物,其用于诱导具有基因组序列变异的细胞的死亡。
本发明的另一个目的是提供一种包含核酸酶和切割剂的用于治疗癌症的组合物。
本发明的另一个目的是提供一种包括核酸酶和切割剂的方法,其用于诱导具有基因组序列变异的细胞的死亡。
本发明的另一个目的是提供一种使用核酸酶和切割剂治疗癌症的方法。
【技术解决方案】
根据本发明的一个方面,上述和其他目的可以通过提供一种包含核酸酶和切割剂的组合物来实现,所述组合物用于诱导具有基因组序列变异的细胞的死亡,所述切割剂特异性识别包含具有基因组序列变异的细胞所特有的突变体序列的核酸序列。
根据另一个方面,提供了一种包含核酸酶和切割剂的用于治疗癌症的组合物,所述切割剂特异性识别包含所述癌症所特有的插入和/或缺失的核酸序列。
根据另一个方面,提供了一种用于诱导具有基因组序列变异的细胞的死亡的方法,其包括用核酸酶和切割剂处理具有基因组序列变异的细胞,所述切割剂特异性识别包含具有基因组序列变异的细胞所特有的突变体序列的核酸序列。
根据另一个方面,提供了一种用于诱导具有基因组序列变异的细胞的死亡的方法,其包括:对具有基因组序列变异的细胞和正常细胞进行全基因组测序(WGS);
比较具有基因组序列变异的细胞与所述正常细胞之间的所得的WGS数据,以选择具有基因组序列变异的细胞所特有的突变体序列;
产生识别所选择的突变体序列的切割剂;
制备包含切割剂和核酸酶的组合物;以及
将所述组合物施加至具有基因组序列变异的细胞。
根据另一个方面,提供了一种用于诱导具有基因组序列变异的细胞的死亡的方法,其包括:
对具有基因组序列变异的细胞和正常细胞进行全基因组测序(WGS);
比较具有基因组序列变异的细胞与所述正常细胞之间的所得的WGS数据,以选择具有基因组序列变异的细胞所特有的一个或多个In/Del;
产生识别所选择的In/Del的切割剂;
制备包含切割剂和核酸酶的组合物;以及
将包含所述核酸酶和所述切割剂的组合物施加至具有基因组序列变异的细胞。
根据另一个方面,提供了一种治疗癌症的方法,其包括向受试者施用核酸酶和切割剂和核酸酶,所述切割剂特异性识别包含具有基因组序列变异的细胞所特有的突变体序列的核酸序列。
根据另一方面,提供了一种治疗癌症的方法,其包括用包含切割剂和核酸酶的表达盒的载体处理具有基因组序列变异的细胞,所述切割剂特异性识别包含具有基因组序列变异的细胞所特有的插入和/或缺失的核酸序列。
根据另一个方面,提供了一种包含核酸酶和切割剂的用于患者特定的癌症疗法的组合物,所述切割剂特异性识别包含所述患者的癌细胞所特有的插入和/或缺失的核酸序列。
根据另一个方面,提供了一种患者特定的癌症疗法,其包括:从患者的癌细胞选择所述癌细胞所特有的一个或多个In/Del;产生识别一个或多个In/Del的切割剂;以及向所述患者递送包含核酸酶和所述切割剂的组合物。
【附图说明】
图1显示了当DNA的多个DSB(双链断裂)同时发生时关于细胞是否被诱导死亡的检测结果;
图2显示了关于DNA是否被使用指导RNA的CRIPSR系统切割的检测结果;
图3显示了在将30个特异性RNP(核糖核苷酸蛋白)复合物转染到结直肠癌细胞和骨肉瘤细胞中以诱导DNA DSB后通过集落形成测定检测的细胞生长;
图4显示了使用免疫荧光和流式细胞术测量的AAV的细胞感染;
图5显示了通过免疫荧光检测AAV颗粒转染的结果;
图6显示了使用30个U2OS细胞系特异性crRNA检测的U2OS特异性crRNA依赖性细胞死亡;
图7显示了关于U2OS细胞特异性saCAS9 AAV系统是否运行以及U2OS细胞是否发生细胞死亡的检测结果;
图8显示了基于通过癌症特有的In/Del所致的细胞死亡测量的细胞活力(%);
图9显示了关于是否仅在crRNA特异性细胞系中诱导AAV依赖性细胞死亡的检测结果;
图10显示了关于胶质母细胞瘤是否发生选择性癌细胞死亡的检测结果;
图11显示了在使用包含ATM激酶抑制剂的AAV颗粒与使用不包含ATM激酶抑制剂的AAV颗粒之间的细胞死亡差异的检测结果;以及
图12显示了肺癌特有的In/Del诱导的细胞死亡(CINDELA)的作用的检测结果。
【具体实施方式】
除非另外定义,否则本文所用的所有技术和科学术语的含义与由本发明所属领域中的技术人员所理解的含义相同。通常,本文所用的命名法是本领域中熟知的,并且是通常使用的。
在一个方面,本发明涉及一种包含核酸酶和切割剂的组合物,其用于诱导具有基因组序列变异的细胞的死亡,所述切割剂特异性识别包含具有基因组序列变异的细胞所特有的突变体序列的核酸序列。
在另一个方面,本发明涉及一种包含核酸酶和切割剂的用于治疗癌症的组合物,所述切割剂特异性识别包含所述癌症所特有的插入和/或缺失的核酸序列。
在另一个方面,本发明涉及一种用于诱导具有基因组序列变异的细胞的死亡的方法,其包括用核酸酶和切割剂处理具有基因组序列变异的细胞,所述切割剂特异性识别包含具有基因组序列变异的细胞所特有的突变体序列的核酸序列。
如本文所用,术语“具有基因组序列变异的细胞”(也称为“突变细胞”或“具有基因突变的细胞”)是指通过基因突变赋予了与正常细胞的活性不同的活性的细胞,并且可以例如指处于由基因突变所致的疾病的发作状态的细胞,特别是癌细胞。
所述癌症是例如黑色素瘤、小细胞肺癌、非小细胞肺癌、神经胶质瘤、肝癌、甲状腺肿瘤、胃癌、卵巢癌、膀胱癌、肺癌、结直肠癌、乳腺癌、前列腺癌、胶质母细胞瘤、子宫内膜癌、肾癌、结肠癌、胰腺癌、食管癌、头颈癌、间皮瘤、肉瘤、骨肉瘤、胆管癌或表皮癌,但不限于此。
在癌细胞中观察到一种现象,其中插入了在正常细胞中未发现的新DNA序列,称为“插入”(IN);或者其中正常细胞的一部分DNA缺失,称为“缺失(Del)”,并且其中在相应癌细胞中可能存在特定插入或缺失的DNA序列。
当细胞中发生DNA的DSB(双链断裂)时,细胞具有DNA损害修复机制以修复对DNA的损害。然而,所述DNA损害修复机制在双链断裂数量少时有效地修复对DNA的损害,但在双链断裂数量巨大时导致死亡。细菌可以通过单个双链断裂而被杀死,但是需要更多的多个DSB来诱导动物细胞的死亡。
根据本发明,基于上述事实,本发明人发现了具有基因组序列变异的细胞(例如,癌细胞)的多个In/Del,并且产生了能够识别多个In/Del的多种切割剂,并最终使用核酸酶和多种切割剂诱导具有基因组序列变异的细胞(例如,癌细胞)的特异性死亡。
作为实现DNA双链断裂的手段的核酸酶可以是限制酶、锌指核酸酶(ZNFN)、转录激活因子样效应物核酸酶(TALEN)或Cas蛋白或编码其的核酸,但不限于此。所述Cas蛋白可以是Cas3、Cas9、Cpf1(来自普雷沃菌属(Prevotella)和弗朗西斯氏菌属(Francisella)的CRISPR 1)、Cas6、C2c12或C2c2,但不限于此。
所述Cas蛋白可以源自包含Cas蛋白的直系同源物的微生物属,其选自棒杆菌属(Corynebacter)、萨特氏菌属(Sutterella)、军团菌属(Legionella)、密螺旋体属(Treponema)、产线菌属(Filifactor)、真杆菌属(Eubacterium)、链球菌属(Streptococcus)(化脓性链球菌)、乳杆菌属(Lactobacillus)、支原体属(Mycoplasma)、拟杆菌属(Bacteroides)、黄沃拉菌属(Flaviivola)、黄杆菌属(Flavobacterium)、固氮螺菌属(Azospirillum)、葡糖醋杆菌属(Gluconacetobacter)、奈瑟氏菌属(Neisseria)、罗斯氏菌属(Roseburia)、细小棒菌属(Parvibaculum)、葡萄球菌属(Staphylococcus)(金黄色葡萄球菌(Staphylococcus aureus))、硝酸盐裂解菌属(Nitratifractor)、棒状杆菌属(Corynebacterium)和弯曲杆菌属(Campylobacter),并且所述Cas蛋白是从中分离的或重组的。
在另一个方面,本发明涉及用于诱导具有基因组序列变异的细胞的死亡的方法,其包括:对具有基因组序列变异的细胞和正常细胞进行全基因组测序(WGS);比较具有基因组序列变异的细胞与所述正常细胞之间的所得的WGS数据,以选择具有基因组序列变异的细胞所特有的突变体序列;产生识别所选择的突变体序列的切割剂;制备包含切割剂和核酸酶的组合物;以及将所述组合物施加至具有基因组序列变异的细胞。
在另一个方面,本发明涉及用于诱导具有基因组序列变异的细胞的死亡的方法,其包括:对具有基因组序列变异的细胞(例如,癌细胞)和正常细胞进行全基因组测序(WGS);比较具有基因组序列变异的细胞与正常细胞之间的所得的WGS数据,以选择具有基因组序列变异的细胞所特有的多个In/Del;产生识别所选择的In/Del的切割剂;制备包含切割剂和核酸酶的组合物;以及将包含所述核酸酶和所述切割剂的组合物施加至具有基因组序列变异的细胞。
作为切割剂靶标的In/Del的定位可以通过WGS(全基因组测序)或消减杂交和测序进行。在得到的In/Del是在癌症中发现的插入的情况下,立即制备指导RNA,并且在得到的In/Del是在癌症中发现的缺失的情况下,定位断裂点,然后产生包括所述断裂点的指导RNA。
如本文所用,术语“WGS(全基因组测序)”是指通过下一代测序使用全长基因组序列以10x、20x和40x的不同深度读取基因组的方法。如本文所用,术语“下一代测序”是指如下技术,其包括将全长基因组以基于芯片和基于PCR的配对末端形式片段化和基于化学杂交以非常高的速度对所述片段进行测序。
消减杂交是一种用于克隆在若干组织或细胞之间具有表达差异的基因的方法。可以检测到待测细胞的DNA样品所特有的基因。将待测细胞的DNA修饰为单链DNA,然后退火。通过调整退火条件,可以将待测细胞所特有的DNA序列分离成双链DNA。
例如,包含癌细胞(其是具有基因突变的细胞类型)所特有的In/Del的核酸序列例如可以包含如下基因位点,在所述基因位点处通过靶向In/Del的核酸酶在核酸序列中诱导DNA的DSB;以及核酸序列(例如,当所述核酸酶是Cas9时,具有与由Cas9蛋白识别的PAM序列的5'端和/或3'端相邻的长度为约17bp至23bp的核酸序列)中由核酸酶特异性识别的序列。
包含癌细胞(其是具有基因组序列变异的细胞)所特有的In/Del的核酸序列表示为相应序列位点的两条DNA链中PAM序列所在的链的核酸序列。在这种情况下,由于指导RNA实际所结合的DNA链是与PAM序列所在的链互补的链,因此包含在指导RNA中的靶向序列与包含In/Del的核酸序列具有相同的核酸序列,不同的是由于RNA的特征而将T改为U。
当所述Cas9蛋白源自化脓性链球菌时,所述PAM序列可以是5'-NGG-3'(其中N是A、T、G或C),并且包含具有基因组序列变异的细胞所特有的In/Del的核酸序列可以是如下基因位点,其位于所述序列中与5'-NGG-3'序列的5'端和/或3'端相邻的位置,例如最大长度为约50bp或约40bp的基因位点。
当所述Cas9蛋白源自嗜热链球菌时,所述PAM序列可以是5'-NNAGAAW-3'(其中N是A、T、G或C),并且包含具有基因组序列变异的细胞所特有的In/Del的核酸序列可以是如下基因位点,其位于所述序列中与5'-NNAGAAW-3'序列的5'端和/或3'端相邻的位置,例如最大长度为约50bp或约40bp的基因位点。
当所述Cas9蛋白源自金黄色葡萄球菌时,所述PAM序列可以是5'-NNGRRT-3'(其中N是A、T、G或C,并且R是A或G),并且包含具有基因组序列变异的细胞所特有的In/Del的核酸序列可以是如下基因位点,其位于所述序列中与5'-NNAGAAW-3'序列的5'端和/或3'端相邻的位置,例如最大长度为约50bp或约40bp的基因位点。
当所述Cas9蛋白源自空肠弯曲杆菌时,所述PAM序列可以是5'-NNNNRYAC-3'(其中N是A、T、G或C,R是A或G,并且Y是C或T),并且包含具有基因组序列变异的细胞所特有的In/Del的核酸序列可以是如下基因位点,其位于所述序列中与5'-NNNNRYAC-3'序列的5'端和/或3'端相邻的位置,例如最大长度为约50bp或约40bp的基因位点。
如本文所用,术语“切割剂”是指如下核苷酸序列,其能够识别并切割与正常细胞相比具有基因组序列变异的细胞的核酸序列中经修饰和改变的部分。
与正常细胞的核苷酸序列相比,本文使用的切割剂应以不同的序列存在多个从而足以诱导细胞死亡,优选为1至30个、更优选为10至30个以及还更优选16至30个,但是其数量可能根据细胞或切割剂的类型而变化。
特异性识别包含具有基因组序列变异的细胞(例如,癌细胞)所特有的In/Del的核酸序列的切割剂可以是例如指导RNA。所述指导RNA可以例如包括选自以下的至少一种:由CRISPR RNA(crRNA)、反式激活crRNA(tracrRNA)和单指导RNA(sgRNA),特别是包含彼此键合的crRNA和tracrRNA的双链crRNA:tracrRNA复合物、或具有通过寡核苷酸接头彼此连接的crRNA或其一部分和tracrRNA或其一部分的单链指导RNA(sgRNA)。
特异性识别包含具有基因组序列变异的细胞所特有的In/Del的核酸序列的指导RNA意指与所述PAM序列所在的DNA链的互补链的核苷酸序列具有至少90%、至少95%、至少96%、至少97%、至少98%、至少99%或100%序列互补性的核苷酸序列,并且可以与所述互补链的核苷酸序列连接。
所述指导RNA可以通过以下步骤来产生:比较癌细胞与正常细胞之间的所得的WGS数据以选择所述癌细胞所特有的In/Del;设计满足基于所述In/Del产生指导RNA的条件的一种或多种癌细胞特异性指导RNA;然后根据所述In/Del位点的长度设置任意顺序,并对所有染色体均匀地设计所述指导RNA,从而完成最终的指导RNA组合。
产生指导RNA的条件如下:(a)除所述PAM位点外的指导RNA的核苷酸序列的长度为20个碱基对;(b)存在于所述指导RNA中的鸟嘌呤和胞嘧啶的总比例在40%与60%之间;(c)In/Del存在于所述PAM位点附近的紧邻前部区域中;(d)最大均聚物长度为4个碱基对或更少;以及(e)进行定位,其允许正常细胞所得的WGS数据的一个错配,不应有定位结果。
在此基础上产生的指导RNA可以例如包含选自SEQ ID NO:1至163的至少一个序列。能够诱导癌细胞死亡的指导RNA的数量可以是具有不同序列的多个,特别是约1至约40个、约15至约25个或约10至约20个。所述指导RNA可以例如包含选自SEQ ID NO:1至30的至少一个序列、选自SEQ ID NO:31至60的至少一个序列、选自SEQ ID NO:61至90的至少一个序列、选自SEQ ID NO:91至120的至少一个序列,选自SEQ ID NO:121至136的至少一个序列以及选自SEQ ID NO:137至163的至少一个序列。
在一个实施方案中,所述癌症可以是结直肠癌,并且特异性识别包含所述结直肠癌所特有的插入和/或缺失的核酸序列的切割剂可以是包含选自SEQ ID NO:1至30所示序列的至少一个序列的指导RNA。
在一个实施方案中,所述癌症可以是骨肉瘤,并且特异性识别包含所述骨肉瘤所特有的插入和/或缺失的核酸序列的切割剂可以是包含选自SEQ ID NO:31至60所示序列的至少一个序列的指导RNA或者包含选自SEQ ID NO:91至120所示序列的至少一个序列的指导RNA。
在一个实施方案中,特异性识别包含正常细胞所特有的插入和/或缺失的核酸序列的切割剂可以是包含选自SEQ ID NO:61至90所示序列的至少一个序列的指导RNA。
在一个实施方案中,所述癌症可以是胶质母细胞瘤,并且特异性识别包含所述胶质母细胞瘤所特有的插入和/或缺失的核酸序列的切割剂可以是例如包含选自SEQ ID NO:121至136所示序列的至少一个序列的指导RNA。
在一个实施方案中,所述癌症可以是肺癌,并且特异性识别包含所述肺癌所特有的插入和/或缺失的核酸序列的切割剂可以是包含选自SEQ ID NO:137至163所示序列的至少一个序列的指导RNA。
根据本发明的实施方案,在结直肠癌细胞系HCT116、骨肉瘤细胞系U2OS、胶质母细胞瘤细胞系GBL-67、肺癌组织和通过将正常细胞永生化而获得的细胞系REP1中每一种的细胞中鉴定出癌症特有的In/Del,产生特异性识别癌症特有的In/Del的指导RNA以诱导DNADSB,然后观察细胞生长。特别地,特异性识别结直肠癌细胞系HCT116的In/Del的指导RNA包含选自SEQ ID NO:1至30的至少一个序列,并且特异性识别骨肉瘤细胞系U2OS的In/Del的指导RNA包含选自SEQ ID NO:31至60或SEQ ID NO:91至120的至少一个序列,特异性识别所述胶质母细胞瘤细胞系的In/Del的指导RNA包含选自SEQ ID NO:121至136的至少一个序列,特异性识别所述肺癌细胞系的In/Del的指导RNA包含选自SEQ ID NO:137至163的至少一个序列,并且特异性识别正常细胞系REP1的In/Del的指导RNA包含选自SEQ ID NO:61至90的至少一个序列。
通过全基因组翻译(WGS)检测细胞系特有的In/Del,然后将指导RNA设计为包含在所述PAM位点的区域中,所述区域与相应区域强烈结合。应该确认的是,所设计的指导RNA被发现不会引起对正常的人标准基因组的非特异性反应。然后,根据所述In/Del位点的长度确定任意顺序,并基于所述顺序将指导RNA设计为均匀地分布在所有染色体上,从而完成最终的多个指导RNA组合。尽管在该实施方案中使用了30个指导RNA,但是可以根据癌细胞的类型和引起DSB的实验方法来调整指导RNA的数量。
可以将根据本发明的核酸酶和切割剂(例如,指导RNA)以如下形式递送至细胞:(a)具有不同序列的多个指导RNA和包含编码核酸酶(例如,Cas蛋白)的核酸序列的载体;(b)核糖核蛋白(RNP)或RNA指导的工程化核酸酶(RGEN),其包含具有不同序列的多个指导RNA和核酸酶(例如,Cas蛋白);或(c)至少一个指导RNA和由核酸酶(例如,Cas蛋白)编码的mRNA,但不限于此。
在一个实施方案中,所述载体可以是病毒载体。所述病毒载体可以选自负链RNA病毒,如逆转录病毒、腺病毒-细小病毒(例如,腺相关病毒(AAV))、冠状病毒和正粘病毒(例如流感病毒);正链RNA病毒,如棒状病毒(例如,狂犬病和水疱性口炎病毒)、副粘病毒(例如,麻疹和仙台病毒)、甲病毒属和小核糖核酸病毒;双链DNA病毒,包括疱疹病毒(例如,单纯疱疹病毒1型和2型、EB病毒、巨细胞病毒)和腺病毒、痘病毒(例如,牛痘、鸡痘或金丝雀痘)等。
可以将所述载体通过电穿孔、脂质转染、病毒载体或纳米颗粒以及PTD(蛋白质易位结构域)融合蛋白方法在体内递送或递送至细胞中。
在一些情况下,可以进一步包括例如选自咖啡因、渥漫青霉素、CP-466722、KU-55933、KU-60019和KU-559403的至少一种ATM(共济失调毛细血管扩张症突变基因)抑制剂,选自五味子乙素、NU6027、NVP-BEZ235、VE-821、VE-822(VX-970)、AZ20和AZD6738的至少一种ATR(共济失调毛细血管扩张症和Rad-3突变基因)抑制剂或者DNA-PKcs(DNA依赖性蛋白激酶催化亚基)的DNA双链修复抑制剂来抑制DNA双链修复,以通过DNA双链断裂增加细胞死亡效率。
在另一个方面,本发明涉及一种包含核酸酶和切割剂的用于治疗癌症的组合物,所述切割剂特异性识别包含所述癌症所特有的插入和/或缺失的核酸序列。在另一个方面,本发明涉及一种治疗癌症的方法,其包括向受试者施用核酸酶和切割剂,所述切割剂特异性识别包含所述癌症所特有的插入和/或缺失的核酸序列。
在另一个方面,本发明涉及一种包含核酸酶和切割剂的用于患者特定的癌症疗法的组合物,所述切割剂特异性识别包含所述患者的癌细胞所特有的插入和/或缺失的核酸序列。
如本文所用,术语“患者特定的癌症”意指充分考虑患者的固有性质或患者的疾病特性,以便有效地治疗癌症。用于患者特定的癌症疗法的组合物可有效地用于选择治疗剂和方法。
如本文所用,术语“具有基因组序列变异的细胞”是指通过基因修饰赋予了与正常细胞的活性不同的活性的细胞,并且可以例如指处于由基因突变所致的疾病的发作状态的细胞,特别是癌细胞。
所述癌症是例如黑色素瘤、小细胞肺癌、非小细胞肺癌、神经胶质瘤、肝癌、甲状腺肿瘤、胃癌、卵巢癌、膀胱癌、肺癌、结直肠癌、乳腺癌、前列腺癌、胶质母细胞瘤、子宫内膜癌、肾癌、结肠癌、胰腺癌、食管癌、头颈癌、间皮瘤、肉瘤、骨肉瘤、胆管癌或表皮癌,但不限于此。
在癌细胞中观察到一种现象,其中插入了在正常细胞中未发现的新DNA序列,称为“插入”(IN);或者其中正常细胞的一部分DNA缺失,称为“缺失(Del)”,并且其中在相应癌细胞中可能存在特定插入或缺失的DNA序列。
当细胞中发生DNA的DSB(双链断裂)时,细胞具有DNA损害修复机制以修复对DNA的损害。然而,所述DNA损害修复机制在双链断裂数量少时有效地修复对DNA的损害,但在双链断裂数量巨大时导致死亡。细菌可以通过单个双链断裂而被杀死,但是需要更多的多个DSB来诱导动物细胞的死亡。
根据本发明,基于上述事实,本发明人发现了具有基因组序列变异的细胞(例如,癌细胞)的多个In/Del,并且产生了能够识别多个In/Del的多种切割剂,并最终使用核酸酶和多种切割剂诱导具有基因组序列变异的细胞(例如,癌细胞)的特异性死亡。
作为实现DNA双链断裂的手段的核酸酶可以是限制酶、锌指核酸酶(ZNFN)、转录激活因子样效应物核酸酶(TALEN)或Cas蛋白或编码其的核酸,但不限于此。所述Cas蛋白可以是Cas3、Cas9、Cpf1(来自普雷沃菌属和弗朗西斯氏菌属的CRISPR 1)、Cas6、C2c12或C2c2,但不限于此。
所述Cas蛋白可以源自包含Cas蛋白的直系同源物的微生物属,其选自棒杆菌属、萨特氏菌属、军团菌属、密螺旋体属、产线菌属、真杆菌属、链球菌属(化脓性链球菌)、乳杆菌属、支原体属、拟杆菌属、黄沃拉菌属、黄杆菌属、固氮螺菌属、葡糖醋杆菌属、奈瑟氏菌属、罗斯氏菌属、细小棒菌属、葡萄球菌属(金黄色葡萄球菌)、硝酸盐裂解菌属、棒状杆菌属和弯曲杆菌属,并且所述Cas蛋白是从中分离的或重组的。
例如,包含癌细胞(其是具有基因突变的细胞类型)所特有的In/Del的核酸序列例如可以包含如下基因位点,在所述基因位点处通过靶向In/Del的核酸酶在核酸序列中诱导DNA的DSB;以及核酸序列(例如,当所述核酸酶是Cas9时,具有与由Cas9蛋白识别的PAM序列的5'端和/或3'端相邻的长度为约17bp至23bp的核酸序列)中由核酸酶特异性识别的序列。
包含癌细胞(其是具有基因组序列变异的细胞)所特有的In/Del的核酸序列表示为相应序列位点的两条DNA链中PAM序列所在的链的核酸序列。在这种情况下,由于指导RNA实际所结合的DNA链是与PAM序列所在的链互补的链,因此包含在指导RNA中的靶向序列与包含In/Del的核酸序列具有相同的核酸序列,不同的是由于RNA的特征而将T改为U。
当所述Cas9蛋白源自化脓性链球菌时,所述PAM序列可以是5'-NGG-3'(其中N是A、T、G或C),并且包含具有基因组序列变异的细胞所特有的In/Del的核酸序列可以是如下基因位点,其位于所述序列中与5'-NGG-3'序列的5'端和/或3'端相邻的位置,例如最大长度为约50bp或约40bp的基因位点。
当所述Cas9蛋白源自嗜热链球菌时,所述PAM序列可以是5'-NNAGAAW-3'(其中N是A、T、G或C),并且包含具有基因组序列变异的细胞所特有的In/Del的核酸序列可以是如下基因位点,其位于所述序列中与5'-NNAGAAW-3'序列的5'端和/或3'端相邻的位置,例如最大长度为约50bp或约40bp的基因位点。
当所述Cas9蛋白源自金黄色葡萄球菌时,所述PAM序列可以是5'-NNGRRT-3'(其中N是A、T、G或C,并且R是A或G),并且包含具有基因组序列变异的细胞所特有的In/Del的核酸序列可以是如下基因位点,其位于所述序列中与5'-NNAGAAW-3'序列的5'端和/或3'端相邻的位置,例如最大长度为约50bp或约40bp的基因位点。
当所述Cas9蛋白源自空肠弯曲杆菌时,所述PAM序列可以是5'-NNNNRYAC-3'(其中N是A、T、G或C,R是A或G,并且Y是C或T),并且包含具有基因组序列变异的细胞所特有的In/Del的核酸序列可以是如下基因位点,其位于所述序列中与5'-NNNNRYAC-3'序列的5'端和/或3'端相邻的位置,例如最大长度为约50bp或约40bp的基因位点。
如本文所用,术语“切割剂”是指如下核苷酸序列,其能够识别并切割与正常细胞相比具有基因组序列变异的细胞的核酸序列中经修饰和改变的部分。
与正常细胞的核苷酸序列相比,本文使用的切割剂应以不同的序列存在多个从而足以诱导细胞死亡,优选为1至30个、更优选为10至30个以及还更优选16至30个,但是其数量可能根据细胞或切割剂的类型而变化。
特异性识别包含具有基因组序列变异的细胞(例如,癌细胞)所特有的In/Del的核酸序列的切割剂可以是例如指导RNA。所述指导RNA可以例如包括选自以下的至少一种:由CRISPR RNA(crRNA)、反式激活crRNA(tracrRNA)和单指导RNA(sgRNA),特别是包含彼此键合的crRNA和tracrRNA的双链crRNA:tracrRNA复合物、或具有通过寡核苷酸接头彼此连接的crRNA或其一部分和tracrRNA或其一部分的单链指导RNA(sgRNA)。
特异性识别包含具有基因组序列变异的细胞所特有的In/Del的核酸序列的指导RNA意指与所述PAM序列所在的DNA链的互补链的核苷酸序列具有至少90%、至少95%、至少96%、至少97%、至少98%、至少99%或100%序列互补性的核苷酸序列,并且可以与所述互补链的核苷酸序列连接。
所述指导RNA可以通过以下步骤来产生:比较癌细胞与正常细胞之间的所得的WGS数据以选择所述癌细胞所特有的In/Del;设计满足基于所述In/Del产生指导RNA的条件的癌细胞特异性指导RNA;然后根据所述In/Del位点的长度设置任意顺序,并对所有染色体均匀地设计所述指导RNA,从而完成最终的指导RNA组合。
产生指导RNA的条件如下:(a)除所述PAM位点外的指导RNA的核苷酸序列的长度为20个碱基对;(b)存在于所述指导RNA中的鸟嘌呤和胞嘧啶的总比例在40%与60%之间;(c)In/Del存在于所述PAM位点附近的紧邻前部区域中;(d)最大均聚物长度为4个碱基对或更少;以及(e)进行定位,其允许正常细胞所得的WGS数据的一个错配,不应有定位结果。
在此基础上产生的指导RNA可以例如包含选自SEQ ID NO:1至163的至少一个序列。能够诱导癌细胞死亡的指导RNA的数量可以是具有不同序列的多个,特别是约1至约40个、约15至约25个或约10至约20个。所述指导RNA可以例如包含选自SEQ ID NO:1至30的至少一个序列、选自SEQ ID NO:31至60的至少一个序列、选自SEQ ID NO:61至90的至少一个序列、选自SEQ ID NO:91至120的至少一个序列,选自SEQ ID NO:121至136的至少一个序列以及选自SEQ ID NO:137至163的至少一个序列。
在一个实施方案中,所述癌症可以是结直肠癌,并且特异性识别包含所述结直肠癌所特有的插入和/或缺失的核酸序列的切割剂可以是包含选自SEQ ID NO:1至30所示序列的至少一个序列的指导RNA。
在一个实施方案中,所述癌症可以是骨肉瘤,并且特异性识别包含所述骨肉瘤所特有的插入和/或缺失的核酸序列的切割剂可以是包含选自SEQ ID NO:31至60所示序列的至少一个序列的指导RNA或者包含选自SEQ ID NO:91至120所示序列的至少一个序列的指导RNA。
在一个实施方案中,特异性识别包含正常细胞所特有的插入和/或缺失的核酸序列的切割剂可以是包含选自SEQ ID NO:61至90所示序列的至少一个序列的指导RNA。
在一个实施方案中,所述癌症可以是胶质母细胞瘤,并且特异性识别包含所述胶质母细胞瘤所特有的插入和/或缺失的核酸序列的切割剂可以是例如包含选自SEQ ID NO:121至136所示序列的至少一个序列的指导RNA。
在一个实施方案中,所述癌症可以是肺癌,并且特异性识别包含所述肺癌所特有的插入和/或缺失的核酸序列的切割剂可以是包含选自SEQ ID NO:137至163所示序列的至少一个序列的指导RNA。
可以将根据本发明的核酸酶和切割剂(例如,指导RNA)以如下形式递送至细胞:(a)具有不同序列的多个指导RNA和包含编码核酸酶(例如,Cas蛋白)的核酸序列的载体;(b)核糖核蛋白(RNP)或RNA指导的工程化核酸酶(RGEN),其包含具有不同序列的多个指导RNA和核酸酶(例如,Cas蛋白);或(c)至少一个指导RNA和由核酸酶(例如,Cas蛋白)编码的mRNA,但不限于此。
在一个实施方案中,所述载体可以是病毒载体。所述病毒载体可以选自负链RNA病毒,如逆转录病毒、腺病毒-细小病毒(例如,腺相关病毒(AAV))、冠状病毒和正粘病毒(例如流感病毒);正链RNA病毒,如棒状病毒(例如,狂犬病和水疱性口炎病毒)、副粘病毒(例如,麻疹和仙台病毒)、甲病毒属和小核糖核酸病毒;双链DNA病毒,包括疱疹病毒(例如,单纯疱疹病毒1型和2型、EB病毒、巨细胞病毒)和腺病毒、痘病毒(例如,牛痘、鸡痘或金丝雀痘)等。
可以将所述载体通过电穿孔、脂质转染、病毒载体或纳米颗粒以及PTD(蛋白质易位结构域)融合蛋白方法在体内递送或递送至细胞中。
在一些情况下,可以进一步包括DNA双链修复抑制剂,例如选自咖啡因、渥漫青霉素、CP-466722、KU-55933、KU-60019和KU-559403的至少一种ATM(共济失调毛细血管扩张症突变基因)抑制剂,选自五味子乙素、NU6027、NVP-BEZ235、VE-821、VE-822(VX-970)、AZ20和AZD6738的至少一种ATR(共济失调毛细血管扩张症和Rad-3突变基因)抑制剂或者DNA-PKcs(DNA依赖性蛋白激酶催化亚基)来抑制DNA双链修复,以通过DNA双链断裂增加细胞死亡效率。
此外,在另一个方面,本发明涉及一种患者特定的癌症疗法,其包括:从患者的癌细胞选择所述癌细胞所特有的一个或多个In/Del;产生识别一个或多个In/Del的切割剂;以及向所述患者递送包含核酸酶和所述切割剂的组合物。
本发明的组合物、方法和用途可以在有需要的受试者中以足量或以有效量使用。术语“有效量”或“足量”是以一个或多个剂量单独地或与至少一种其他治疗性组合物、方案或治疗方案组合地给予的量,所述量在任何时间段内有益于受试者或为受试者提供预期或所需的结果。规定的量可以根据多种因素(如配制方法、施用方式、患者的年龄、体重、性别和病理状况、施用时间、施用途径、排泄率和反应敏感性)而变化。
可以使用载体(如病毒载体、质粒载体或土壤杆菌属载体)进行递送,所述载体包含特异性识别核酸序列的切割剂和核酸酶的表达盒或者编码其的核酸,所述核酸序列包含具有基因组序列变异的细胞(例如,癌细胞)所特有的插入和/或缺失。特别地,可以使用作为病毒载体的AAV(腺相关病毒)载体进行递送。
适合于实现治疗效果的AAV载体的剂量可以以载体基因组剂量/体重(vg/kg)的形式来提供,并且可以根据以下因素而变化,例如(a)施用途径、(b)实现治疗效果所需的治疗性基因的表达水平、(c)对所述AAV载体的任何宿主免疫应答以及(d)所表达的蛋白质的稳定性。
实施例
在下文中,将参考实施例更加详细地描述本发明。然而,对本领域技术人员明显的是,提供这些实施例仅用于举例说明本发明,而不应解释为限制本发明的范围。
实施例1:检测通过DSB获得的细胞死亡作用
考虑到多个若干DSB可以诱导细胞死亡并且所有癌细胞都有它们自己的In/Del序列,通过WGS(全基因组测序)鉴定了HCT116、U2OS和REP1细胞的独特In/Del序列。然后,如下表1至表3所示,在癌细胞的独特的DNA插入序列中,选择在染色体上均匀分布的具有6至8bp插入大小的30个区域序列来产生对于每个细胞系的crRNA,用CRISPR RNP复合物转染细胞,然后观察crRNA特异性和细胞活力。
[表1]
[表2]
[表3]
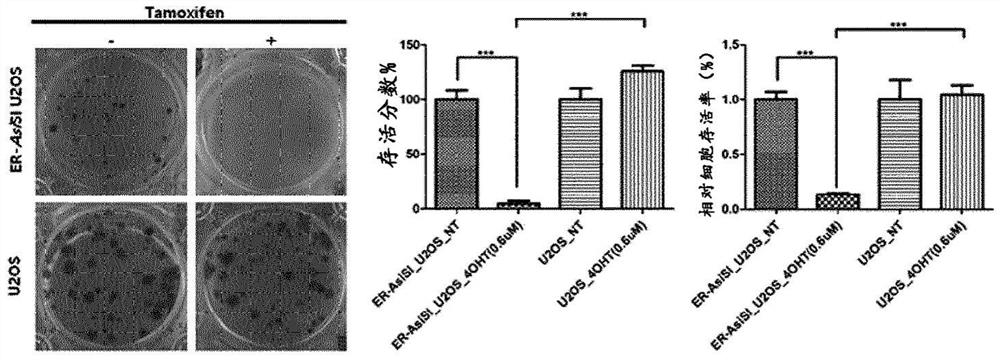
首先,进行实验以确定当同时发生多个DNA DSB时是否诱导了细胞死亡。在用4-OHT(他莫昔芬)处理通过将雌激素受体的结构域插入AsiSI限制酶中而获得的细胞后,检测到细胞死亡,并且结果如图1所示。
当用4-OHT处理AsiSI限制酶时,其进入细胞核并识别特定序列以产生约100个DNADSB(双链断裂)。通过集落形成测定来检测产生DSB后的细胞活力。从接种200个细胞后2天开始,定期用4-OHT处理细胞(每2-3天用其处理一次培养基)以产生DSB。2周后,通过亚甲蓝染色确定是否形成集落。此外,由于各个细胞具有不同的集落大小,因此发现脱色样品展现出与染色样品的那些相似的相对细胞存活。
实施例2.检测CRISPR系统的体外运行
进行体外切割测定以确定CRISPR系统使用实施例1中制备的crRNA是否运行。首先,通过PCR将插入序列的前部和后部的DNA扩增到500bp的大小,随后纯化,然后确定通过使用所制备的crRNA的CRIPSR系统是否切割了DNA。
使用Qiamp DNA迷你试剂盒从RPE1、U2OS和HCT116细胞提取基因组DNA,并基于所述指导RNA特异性产生约500bp长的双向引物。使用iProof高保真DNA聚合酶在设定的退火温度下扩增基因组DNA,在1%琼脂糖凝胶中切割所扩增的DNA,并使用Qiagen QiAquick凝胶提取试剂盒进行提取。
将原料在95℃下储存5分钟,并使其冷却至室温以产生10μM crRNA:tracerRNA复合物。然后,使用PBS将crRNA:tracerRNA复合物和Cas9核酸酶各自调节至1μM的浓度,并在室温下孵育10分钟以产生RNP复合物。
将10X Cas9核酸酶反应缓冲液(200mM HEPES、1M NaCl、50mM MgCl(2)、1mM EDTA(pH 6.5))、1μM Cas9 RNP、100nM DNA底物和无核酸酶水混合,并在37℃下进行消化反应3小时。3小时后,为了从Cas9核酸内切酶释放DNA底物,添加1μl的20mg/ml蛋白酶K并将其在56℃下孵育10分钟。在1%琼脂糖凝胶中检测切割的基因组DNA。
[表4]
[表5]
[表6]
结果示于图2中,并且在琼脂糖凝胶中检测到两个大小为500bp和大小为300bp的原始DNA片段。这证明使用所产生的crRNA的CRISPR系统起到理想的作用。
实施例3.检测DNA DSB诱导后的细胞生长速率
用具有30个特定序列的核糖核苷酸蛋白(RNP)复合物转染结直肠癌HCT116细胞和骨肉瘤U2OS细胞以诱导DNA DSB,然后通过集落形成测定检测细胞生长速率。
单独接种500和1000个细胞并将其用细胞系特异性RNP复合物转染。将1000个U2OS细胞接种在60mm培养皿上,并将500个HCT116细胞接种在60mm培养皿上,接着稳定两天以准备指导RNA的转化。将原料在95℃下储存5分钟,并使其冷却至室温以产生1μM crRNA和1μMtracerRNA的复合物。然后,将1.5μl的1μM crRNA:tracerRNA复合物与1.5μl的1μM Cas9核酸酶和22μl的Opti-MEM培养基在96孔培养皿上于室温下反应5分钟,以产生RNP复合物。将30个RNP复合物(25μl)、30x1.2μl的RNAiMAX转染试剂和30x23.8μl的Opti-MEM培养基调节至1.5ml的总体积,并使其在室温下静置20分钟以产生转化体复合物。此外,为了确定对一种细胞系具有特异性的crRNA是否在其他细胞系中诱导DSB,用对骨肉瘤细胞具有特异性的RNP复合物转染结直肠癌细胞,并且还用对结直肠癌细胞具有特异性的RNP复合物转染骨肉瘤细胞。此时,使用作为ATM抑制剂的2μM KU 55933一起进行处理以抑制细胞内DSB修复系统。然后,在监测细胞生长的同时,每3天更换一次培养基,并另外用ATM抑制剂进行处理。2周后,通过亚甲蓝染色检测细胞的生长。使用ImageJ程序观察并比较染色的集落的数量和面积,并显示了结果。
结果示于图3中。发现在用对各细胞系具有特异性的RNP复合物转染的实验组中,几乎所有细胞通过DSB诱导了死亡,并且所述特异性RNP复合物在其他细胞系中未诱导DSB,因此细胞继续生长。
然而,在用对结直肠癌具有特异性的RNP复合物转染的骨肉瘤中,细胞生长受到一定程度的抑制。其原因被认为是通过用大量RNP复合物(30个RNP复合物)转染抑制了细胞的生长。为了弥补这一缺陷并确定细胞死亡的最少RNP复合物,用HCT116和U2OS gRNA转染RPE1细胞以检测crRNA特异性,并将最少的gRNA数量调整为每个癌细胞20个。
实施例4.检测CINDELA(癌症特有的插入缺失诱导的细胞死亡)的作用
通过WGS(全基因组测序)设计针对saCas9的新型U2OS细胞系特异性crRNA,并将其包装在AAV中。U2OS细胞特异性crRNA的特定序列如下。
[表7]
使用免疫荧光和流式细胞术测量AAV的细胞感染率。通过如下方法进行HA细胞内染色:向60mm培养皿中添加0.1M细胞(第0天),不添加HA或向其中添加0.25ml、0.5ml、1ml的HA以用AAV转染细胞(第2天),并收获,然后将细胞染色(第3天)。使HA(1:300)在室温下静置2小时,使小鼠488(1:500)在室温下静置1小时,使核糖核酸酶A在37℃下静置30分钟,并且使PI在室温下静置10分钟。结果示于图4中。细胞核HA标签阳性细胞的百分比在第1天为约80%,并且所述百分比在第2天和第3天降低。
将8*10
去除固定剂并向其中添加1ml的100%甲醇,然后将细胞在-20℃下孵育10分钟。用1ml的PBS洗涤细胞两次。
用500μl的在PBS中的10%FBS将细胞封闭30分钟,移取封闭溶液,然后向封闭溶液中添加适当的一抗,持续1小时。用在PBS中的0.05%Triton X-100洗涤细胞3次,每次5分钟。在室温下在黑暗中向细胞中添加二抗,持续30分钟,并且用在PBS中的0.05%Triton X-100洗涤细胞三次,每次5分钟,并用PBS和DW进一步洗涤。从载玻片移取周围的腔室。
将封固试剂逐滴施加到每个样品上,并用盖玻片覆盖样品。在这种状态下干燥样品,并完全密封载玻片。使用LSM 880(ZEISS)和ZEN软件(ZEISS)进行焦点检测和可视化。
结果示于图5中。通过免疫荧光发现AAV颗粒被充分转染,并且表7中的crRNA能够产生对应于DNA DSB的rH2AX焦点。
使用30个U2OS细胞系特异性crRNA开发了saCAS9 AAV系统,并将AAV颗粒转导至U2OS细胞中。将8x10
检测正常细胞(特别是RPE1细胞系)中是否发生细胞系特异性选择性细胞死亡。从图7可以看出,如在实施例2中,U2OS细胞系特异性saCAS9 AAV系统运行并且可以在U2OS细胞中诱导细胞死亡,而U2OS细胞系特异性AAV系统在RPE1细胞中未诱导细胞死亡。
测量由于癌症特有的插入缺失诱导的细胞死亡(CINDELA)所致的细胞活力。72小时后,将用AAV颗粒转导的细胞在室温下用1%亚甲蓝染色10分钟。将细胞用PBS洗涤3次,每次10分钟,并在室温下干燥。用500μl的10%乙酸溶液漂白细胞并测量OD值。图8显示了所得的癌细胞活力。
通过流式细胞术以时间依赖性方式测量细胞活力。用U2OS细胞系特异性crRNAAAV颗粒转导U2OS和RPE1细胞二者。使用不含叠氮化物的abd血清/不含蛋白质的PBS将细胞以1*10
实施例5.检测胶质母细胞瘤特有的INDEL诱导的细胞死亡的作用
在患者来源的胶质母细胞瘤中检测由于IN/DEL所致的细胞死亡作用。以与实施例4中相同的方式进行实验,不同之处在于将细胞在低氧腔室中孵育。对于胶质母细胞瘤仅可用16个序列。通过16个胶质母细胞瘤特异性序列检测选择性细胞死亡意指仅产生16个DNADSB。
[表8]
对于16个胶质母细胞瘤特异性序列进行系列转导。NSC-10细胞用作正常对照。从图10可以看出,在胶质母细胞瘤中发生了选择性癌细胞死亡。
实施例6.取决于ATM激酶的存在的细胞死亡作用
将含有或不含ATM激酶抑制剂的AAV颗粒转导至实施例5的胶质母细胞瘤细胞中,并以与实施例4和5中相同的方式进行实验。转导24小时后,将细胞在室温下用1%亚甲蓝染色10分钟。将细胞用PBS洗涤3次,每次10分钟,并在室温下干燥。用500ul的10%乙酸溶液漂白细胞并测量OD。结果示于图11中。
实施例7.检测肺癌特有的IN/DEL诱导的细胞死亡的作用
为了检测癌症特有的IN/DEL诱导的细胞死亡(CINDELA)的作用,将源自患者的肺癌组织用于小鼠异种移植。将患者来源的肺癌组织插入小鼠中,并将含有28个肺癌组织特异性crRNA的AAV颗粒连续注射至小鼠中。
[表9]
每2天注射一次AAV颗粒,并测量肿瘤大小。结果示于图12中。从图12可以看出,正常细胞随着时间的推移而生长,而癌细胞在第二次AAV注射期间没有生长。
尽管已经详细描述了本发明的具体配置,但本领域技术人员应理解,本说明书是为了阐述用于说明性目的的优选实施方案而提供,并且不应理解为限制本发明的范围。因此,本发明的实质范围由所附权利要求及其等同物限定。
【序列自由文本】
附有电子文件。
序列表
<110> 基础科学研究院
蔚山科学技术院
<120> 诱导具有突变基因的细胞的死亡的组合物以及通过使用所述组合物诱导具有突变基因的细胞的死亡的方法
<130> PP-B2259
<150> KR 18/109,214
<151> 2018-09-12
<160> 163
<170> PatentIn版本3.5
<210> 1
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 1
agccctagaa ttcccttcac 20
<210> 2
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 2
cttctccacc aattggtgtt 20
<210> 3
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 3
gttttgtctc attatcacgc 20
<210> 4
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 4
ctgtgtttat ggtgctttgt 20
<210> 5
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 5
tgtaagaagg ccgaatcacg 20
<210> 6
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 6
tcctatacgg ctctaccagt 20
<210> 7
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 7
gtctaaaggt tagaattccg 20
<210> 8
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 8
gagactgcta tcagtcatgt 20
<210> 9
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 9
ttttggtcaa gagcagagga 20
<210> 10
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 10
tgtgtgccgt aatatgggaa 20
<210> 11
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 11
tgaccttctg agttccttat 20
<210> 12
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 12
gtttgtcata ccagtcaaag 20
<210> 13
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 13
acacaggacc agaaaccctg 20
<210> 14
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 14
actcttccag ttgttcactg 20
<210> 15
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 15
gtgcatttct ctgctgagtc 20
<210> 16
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 16
tatatatctg caggatctgc 20
<210> 17
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 17
tctcttgctg tagagtgcgt 20
<210> 18
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 18
acacctgctt caggtgtgtg 20
<210> 19
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 19
catttaaaag gatgccagca 20
<210> 20
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 20
ctgatacttc tgataccaga 20
<210> 21
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 21
gttcagcctg agtttggagt 20
<210> 22
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 22
agagatacag aagtccctgt 20
<210> 23
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 23
agatgtgtaa ggttgcaaca 20
<210> 24
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 24
gaaccacaga acctggcata 20
<210> 25
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 25
tgacctttca caaaggccca 20
<210> 26
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 26
gcctcagggg aatggagata 20
<210> 27
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 27
tttgctactt tgctaggttt 20
<210> 28
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 28
agggagctca gagtcttgtg 20
<210> 29
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 29
ctccttccct tcctgagttt 20
<210> 30
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 30
gtgtgagtga gagagaaaga 20
<210> 31
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 31
ttatccaatc agctatggcc 20
<210> 32
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 32
gcttcactgg cttcactgga 20
<210> 33
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 33
atttgtacag tctgcttact 20
<210> 34
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 34
gcatcttcaa caggtgattc 20
<210> 35
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 35
tttcaagcat ttcaatgcag 20
<210> 36
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 36
ttctctctgt gcttctttga 20
<210> 37
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 37
tggcccttgt ggcagtttag 20
<210> 38
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 38
atgggattaa tgggattgct 20
<210> 39
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 39
tcatacagag aaagcagggc 20
<210> 40
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 40
tcatctcatg tcttctcatg 20
<210> 41
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 41
gacagaaccc aagtaatttc 20
<210> 42
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 42
ttatgccatc tggtccaggc 20
<210> 43
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 43
ccagacatac actaggcatc 20
<210> 44
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 44
tcccgtgagg cattctgtac 20
<210> 45
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 45
attcttcgtg ctgatgtacc 20
<210> 46
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 46
acaatctgtc cagaggccaa 20
<210> 47
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 47
gtgaagggca agcaaggaca 20
<210> 48
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 48
tgatatggca tagcgatcat 20
<210> 49
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 49
taacagccat gtggtgttac 20
<210> 50
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 50
ggaaacagca gcagtgcaca 20
<210> 51
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 51
cagggctaga ccttcgttat 20
<210> 52
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 52
atgcagtgta gcatggggag 20
<210> 53
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 53
agtctttgga caagatgccc 20
<210> 54
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 54
gaagaaagag aagagggctt 20
<210> 55
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 55
agcactttta tctcacccta 20
<210> 56
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 56
actgcctggg gttttccctt 20
<210> 57
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 57
gtgtcaacag ggtcactctg 20
<210> 58
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 58
aatttgcttt ggaaggacct 20
<210> 59
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 59
agattccaga gtgatggaat 20
<210> 60
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 60
agagatacag gagtccctgt 20
<210> 61
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 61
gagtaataag tctgctcttt 20
<210> 62
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 62
actttgagga ccttgaggaa 20
<210> 63
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 63
actgtgggaa ctgtgggaga 20
<210> 64
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 64
caggcatatt ttcccatgta 20
<210> 65
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 65
atgtgatgct ggagagaaat 20
<210> 66
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 66
ggggttagtt tgtgttaact 20
<210> 67
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 67
acttacatca caggcatcac 20
<210> 68
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 68
atgccagatt cttcccagtg 20
<210> 69
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 69
acgaactgtt gggtggtgct 20
<210> 70
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 70
tttaatcgag cacatgcagg 20
<210> 71
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 71
tgatggatct gatggatact 20
<210> 72
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 72
aagaagggct ggtttgttct 20
<210> 73
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 73
acctgcagga actgaaacaa 20
<210> 74
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 74
ttgactccca tggtaacctg 20
<210> 75
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 75
atgaggttac tcagagccag 20
<210> 76
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 76
cacttgagtt caggagagct 20
<210> 77
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 77
cttcacttcc ctcctttcca 20
<210> 78
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 78
cactgccctc aagtccttac 20
<210> 79
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 79
caaactcacc aaatgtccac 20
<210> 80
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 80
ttctttggtt gtggtggttg 20
<210> 81
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 81
tagtgttggg gcataacacc 20
<210> 82
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 82
gtggcatttg gagtccatga 20
<210> 83
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 83
ctcagtactt ggtctcctgt 20
<210> 84
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 84
acctcttgag gggtaacaaa 20
<210> 85
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 85
ccctgaatac tgagcaaagc 20
<210> 86
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 86
gggcaagtgt gtgaagtgtg 20
<210> 87
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 87
acacagtaaa gacccaagta 20
<210> 88
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 88
tgtacatttc caggttcttc 20
<210> 89
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 89
ttggccagct tgtcctgagt 20
<210> 90
<211> 20
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 90
ggccaagatt gcatccagtc 20
<210> 91
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 91
tacctatgcc tcatgtagaa a 21
<210> 92
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 92
atcgtcaggt tctgggaccg t 21
<210> 93
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 93
cagaagagag agagtagtag a 21
<210> 94
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 94
gaatgtttaa ggtatagttt a 21
<210> 95
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 95
tgtttcagca ggggttgaag c 21
<210> 96
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 96
ctatacccta gacttattcc t 21
<210> 97
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 97
gtttctttct acagaataga g 21
<210> 98
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 98
ataggttaac aaagatattc a 21
<210> 99
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 99
ctacaaaata ggtgacataa c 21
<210> 100
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 100
ttaaaatggc gcaaataaat t 21
<210> 101
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 101
ttttatgagt ctgccaggaa t 21
<210> 102
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 102
gaagaaacaa ttttcactgg g 21
<210> 103
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 103
caggaaggga gctagtgagc t 21
<210> 104
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 104
cctctcctgc tgatgatccc c 21
<210> 105
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 105
tgggccgcac gtgtgagtgc c 21
<210> 106
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 106
aggaaacaag cccatgttcc c 21
<210> 107
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 107
catggcagaa aacagaagac a 21
<210> 108
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 108
aacagtctct gtgatagggc a 21
<210> 109
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 109
gggaaaatca gacggatatt c 21
<210> 110
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 110
atttctgttc ttccctcact t 21
<210> 111
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 111
taataactgt gtagttataa c 21
<210> 112
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 112
gttcagatta gctcttaact a 21
<210> 113
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 113
taaacttcct atttattgtc t 21
<210> 114
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 114
ataactaatg ccagggtgag t 21
<210> 115
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 115
ctccacgccg gtagggttag a 21
<210> 116
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 116
agtttgtagt gtctttccag a 21
<210> 117
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 117
tattttccag atgttccaat a 21
<210> 118
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 118
gactatgaga ctactactgc a 21
<210> 119
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 119
ccttagcctc cttttcacac a 21
<210> 120
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 120
agagaagaga aaatagggga a 21
<210> 121
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 121
acacggacaa gttctccgtg a 21
<210> 122
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 122
aacagtgggg cagttaggat t 21
<210> 123
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 123
cacaagatag atagataaga t 21
<210> 124
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 124
tttccaggtt ttgattgagg t 21
<210> 125
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 125
cagatgccag aaaggagact g 21
<210> 126
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 126
gaggagaagc ggcgataatc t 21
<210> 127
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 127
gtagaaggct aaatagttac c 21
<210> 128
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 128
ttataactaa gattctggcc c 21
<210> 129
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 129
tctctttgca ccccaggcat g 21
<210> 130
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 130
agataacaat aattattact t 21
<210> 131
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 131
ccccctggcc aggcagggcc g 21
<210> 132
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 132
agtagcacga acaaaacaag t 21
<210> 133
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 133
gagaaaaatc aggatagagg t 21
<210> 134
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 134
ctccacaagc agatgatcaa g 21
<210> 135
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 135
aagttttgta gaaaactaaa t 21
<210> 136
<211> 21
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 136
tactgtggga taactgacgg c 21
<210> 137
<211> 27
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 137
gaggctattg gatttcattt ctagagt 27
<210> 138
<211> 27
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 138
gcactcacga ggtcacgagg tgtgggt 27
<210> 139
<211> 27
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 139
ctttcttaaa catagaatct ataggat 27
<210> 140
<211> 27
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 140
gaacagtgca aggataggtg tgggggt 27
<210> 141
<211> 27
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 141
tggtgccccg ggtttacact taagaat 27
<210> 142
<211> 27
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 142
cttcatctat aggagcctcc agtgagt 27
<210> 143
<211> 27
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 143
ggccttgagt gaggagaagg caggagt 27
<210> 144
<211> 27
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 144
ggtgaagtac atattctcat atggagt 27
<210> 145
<211> 27
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 145
gggctcagtt ttcccaccag tgggggt 27
<210> 146
<211> 27
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 146
atacgttttg acggccaata gttgaat 27
<210> 147
<211> 27
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 147
acctatgatg tgatagtttg tttgggt 27
<210> 148
<211> 27
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 148
taagacctct taggaagtag aatgaat 27
<210> 149
<211> 27
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 149
tttgagaggc aggggcacca gctgggt 27
<210> 150
<211> 27
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 150
tggaagagtg gaaaaaggtg gaagagt 27
<210> 151
<211> 27
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 151
tctgcagaac aggcgcccag tcagagt 27
<210> 152
<211> 27
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 152
tgtagaattt ttaactgtta acaggat 27
<210> 153
<211> 27
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 153
cagccaatgg tgtaataagc tgtgggt 27
<210> 154
<211> 27
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 154
taaagagact caggagagaa gaagaat 27
<210> 155
<211> 27
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 155
caagggaggt gcctggttgc ccagagt 27
<210> 156
<211> 27
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 156
agtctatttt gattgttttt agggagt 27
<210> 157
<211> 27
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 157
gcatcactga agaatcagcc taagagt 27
<210> 158
<211> 27
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 158
gattttaatc ataactgcat gaagggt 27
<210> 159
<211> 27
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 159
gtcacaagtt tctgtttctt ggtggat 27
<210> 160
<211> 27
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 160
tccatctctg aaatgtggat ggagaat 27
<210> 161
<211> 27
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 161
taaagggtgc ttttcttatt atagaat 27
<210> 162
<211> 27
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 162
tttgggagtg gagagatttg ggggagt 27
<210> 163
<211> 27
<212> DNA
<213> 人工序列(Artificial Sequence)
<220>
<223> 合成序列(Synthetic Sequence)
<400> 163
aggctctcag ggaatgagag gagggat 27
- 诱导具有突变基因的细胞的死亡的组合物以及通过使用所述组合物诱导具有突变基因的细胞的死亡的方法
- 针对具有BRAF基因突变的细胞的细胞死亡诱导试剂、该细胞的增殖抑制试剂及用于治疗由该细胞的增殖异常导致的疾病的医药组合物