训练神经网络以用于车辆重新识别
文献发布时间:2023-06-19 11:39:06
背景技术
跨多个相机或来自单个相机的多个帧匹配车辆或其他对象的外观是车辆或对象跟踪应用的完整任务。车辆重新识别的目标是跨相机网络识别同一车辆,这是城市和其他高度拥挤的交通区域中相机的激增所带来的日益复杂的问题。例如,除了潜在地阻碍特定车辆的相机视线的任何数量的永久或瞬态对象之外,由于环境中车辆的数量增加,从跨由任何数量的相机捕获的多个帧的各种不同方向重新识别同一车辆变得越来越具有挑战性。
已经开发了常规方法来对人执行重新识别任务,诸如通过使用各种损失函数来训练深度神经网络(DNN)以用于人分类任务。根据一个方法,DNN可使用交叉熵损失来训练,但因为每个身份被视为单独的类别并且类别的数目等于训练集中的身份数目,所以学习变得在计算上禁止。其他常规方法已经使用DNN,该DNN使用对比损失或三元组损失来训练以学习用于嵌入空间的嵌入——例如,用于面部验证的面部嵌入。然而,这些常规方法不能为诸如车辆重新识别之类的任务提供足够准确的结果。
其他常规方法包括车辆分类,其是与车辆重新识别密切相关的问题。例如,车辆分类可识别车辆的品牌、型号和/或年份。然而,车辆重新识别是比车辆分类更细粒度的问题,因为重新识别应当能够提取属于同一型号类别的两个车辆之间的视觉差异,例如细微的装饰或颜色差异。此外,与车辆分类不同,预期车辆重新识别在某个地理区域中没有可能的车辆型号类别的任何先验知识的情况下工作。这样,车辆分类方法无法为车辆重新识别任务提供准确和可用的结果。
发明内容
本公开的实施例涉及训练深度神经网络(DNN)以用于车辆重新识别。公开了用于训练DNN以重新识别在任何数量的不同方向和位置处并且由任何数量的不同相机捕获的车辆或其他对象的系统和方法。
与诸如上述那些的常规系统相比,本公开的一个或更多个DNN可被训练以预测对应于在由任何数量的相机捕获的多个图像中表示的车辆的嵌入。一个或更多个DNN可以将与具有相同身份的车辆相对应的多个嵌入计算为在嵌入空间中彼此非常接近,并且可以将与具有不同身份的车辆相对应的多个嵌入计算为进一步分开——所有都仅需要用于训练的身份级注释,同时维持用于有效推理的小嵌入维度。除了对比损失或三元组损失(例如,在实施例中,用SoftPlus函数替换裕度α)之外,一个或更多个DNN还可以使用多个批次用于训练,其中仅与来自批次的一个或更多个更有意义的样本相对应的一个或更多个嵌入可以用于计算损失。为了确定有意义的样本,批采样变体(在此被称为“批样本”)可以使用多项式分布来识别与有意义的样本相对应的嵌入。此外,一些实施例可以使用预训练的网络,而其他实施例可以端到端地(例如,从头开始)训练,并且可以调整学习速率,例如使得预训练的模型具有小于端到端模型的学习速率,这取决于实施例。因此,本公开的一个或更多个DNN可被更有效且高效地训练,与常规解决方案相比减少了计算资源,同时在车辆重新识别任务的部署中维持针对实时或近实时预测的高效推理。
附图说明
下面参考所附附图详细描述用于训练神经网络以用于车辆重新识别的系统和方法,其中:
图1是根据本公开的一些实施例的训练深度神经网络(DNN)以预测用于对象重新识别的嵌入的过程的数据流程图;
图2A是根据本公开的一些实施例的包括用于计算各个采样变体的权重的方程的表;
图2B是根据本公开的一些实施例的包括嵌入距锚嵌入的距离的图表;
图2C包括示出了根据本公开的一些实施例的各个采样变体的权重的图表;
图3是根据本公开的一些实施例的使用三元组损失来训练DNN以预测嵌入的图示;
图4A是根据本公开的一些实施例的包括使用对比损失或三元组损失以及归一化或无归一化层对数据集的测试结果的表;
图4B是根据本公开的一些实施例的包括使用各个采样变体对数据集的测试结果的表;
图4C是根据本公开的一些实施例的包括使用各个采样变体对数据集的测试结果的表;
图4D是根据本公开的一些实施例的包括使用各个采样变体对数据集的测试结果的表;
图5是示出根据本公开的一些实施例的用于训练深度神经网络以预测用于对象重新识别的嵌入的方法的流程图;以及
图6是适合用于实现本公开的一些实施例的示例计算设备的框图。
具体实施方式
公开了涉及训练神经网络以用于车辆重新识别的系统和方法。尽管主要关于车辆重新识别来描述本公开,但这并不旨在是限制性的,并且在不脱离本公开的范围的情况下,本文中所描述的系统和方法可以用于识别其他对象类型,诸如人、动物、无人机、水运船、飞机、建筑车辆、军用车辆等。
车辆重新识别涉及跨不同相机和/或跨如由一个或更多个相机捕获的多个帧匹配对象(并且具体地车辆)的外观。这种挑战在车辆重新识别的使用情况中由于各种原因而复杂化,这些原因包括:同一车辆的多个视图在视觉上是多样的并且是语义上相关,这意味着无论给定的视点如何都必定推导出同一身份;精确的车辆重新识别需要提取细微的物理线索,例如在车辆表面上存在灰尘、书面标记或凹痕,以区分同一年、颜色、品牌和/或型号的不同车辆;并且给定在给定数据集中具有车辆的有限年数、颜色、品牌和型号(例如,比人或面部训练数据集中表示的多样性小一半或更小)的情况下,则车辆标签不如人或面部、身份标签更精细。
为了匹配对象的外观,可以生成每个对象的嵌入(或者称为特征向量或者签名)。然后可以使用距离度量来确定嵌入空间中嵌入彼此的接近度。嵌入空间中的嵌入的接近度可以规定多个对象中的两个或更多个对象之间的关系或匹配。例如,跨多个帧的相同对象可具有被确定为彼此接近(例如,在阈值距离内)的嵌入,而不同对象的嵌入可进一步分开(例如,在阈值距离外)。
如本文所描述的,有效嵌入应当是照明、比例和视点不变的,使得即使照明、比例、视点和/或对象外观的其他差异在从任何数量的相机捕获的多个帧上被描绘,相同的对象在嵌入空间中跨帧具有类似的嵌入位置。为了训练深度神经网络(DNN)以准确且高效地预测对象的嵌入,DNN可被训练成使得嵌入对于在此描述的各种因素是不变的。嵌入的嵌入维度可以是DNN在预测嵌入空间的效率以及准确度中的直接因素。例如,嵌入维度越大,可以在每个嵌入中表示越多的上下文信息,同时降低效率并增加系统的运行时间。照此,系统的目标可以是确定最小可能的嵌入维度,该最小可能的嵌入维度仍然允许关于由DNN预测的嵌入空间中的嵌入的可接受的或最优的准确度。在非限制性示例中,如通过测试(本文描述的)验证的,128个单位(或在示例中为256个单位或更少)的嵌入维度可用于本公开的一些实施例,同时仍产生准确的结果。例如,一些常规系统使用1024个单位或2048个单位的嵌入维度,并且与本公开的系统相比以更长的运行时间产生不太准确的结果。这些常规系统还在推理和训练期间需要显著更大的计算资源,因为预测或被训练为预测具有1024个或更多个单位的维度的嵌入在计算上比128个单位更复杂(作为非限制性示例)。通过使用与有效的训练参数(例如,三元组损失、批采样等)组合的相对较小的嵌入维度,如本文中所描述的,较小的嵌入维度仍然产生用于由DNN预测嵌入空间的准确且可用的结果。此外,降低了计算成本和训练时间。
例如,可选择在训练期间使用的损失函数,使得相同对象的嵌入比不同对象的嵌入在嵌入空间中更靠近。在一些示例中,对比损失(contrastive loss)或三元组损失(triplet loss)可被用于训练DNN以计算对象的嵌入。对比损失在每个训练实例处使用传感器数据(例如,由图像数据表示的图像)的两个实例,每个实例描绘相同的对象或不同的对象,其中每个实例被应用于DNN的实例化。例如,第一图像I
三元组损失在每个训练实例处使用传感器数据(例如,由图像数据表示的图像)的三个实例,每个实例描绘相同的对象或不同的对象,其中每个实例被应用于DNN的实例化。例如,第一图像I
然而,当应用于N个样本的数据集时,对比损失和三元组损失两者都具有高计算复杂性。例如,对比损失具有训练复杂度O(N
为了解决该计算复杂度,可采用采样方法来捕获稳健数据集的对于DNN而言更难以准确计算的子集(例如,数据集的在预测嵌入时DNN较不准确的子集)。例如,一些常规方法使用困难(hard)数据挖掘(或采样),其中在每次迭代处,DNN被应用于验证集以挖掘在其上DNN表现差的困难数据。然后只有被挖掘的困难数据被优化器(例如,训练组件)用来增加DNN有效地学习并更快地收敛到可接受的或最优的准确度的能力。然而,因为困难数据挖掘倾向于主要捕获数据中的离群值,并且因为DNN仅被呈现有该困难数据(例如,离群值),所以DNN将离群值与正常数据区分开的能力受损。
照此,为了考虑(并且不仅依赖于)离群值,半困难采样可以用于挖掘数据的中等子集,这些中等子集既不太困难(例如,DNN难以准确地执行)也不太平凡而不能在DNN的训练期间建立有意义的梯度。半困难采样的一些常规方法在中央处理单元(CPU)上使用阻碍DNN收敛的离线方法。照此,在一些实施例中,数据集的样本可直接在图形处理单元(GPU)上以半困难方式挖掘。例如,可从数据集生成包括来自数据集X的P个身份的批次,并且随后针对每个身份P随机地采样K个图像。因此,在一些非限制性实施例中,每个批可以包括PK个图像。在一些示例中,P可等于18且K可等于4,使得每个批为72(PK)个图像。样本可被选择为使得整个训练数据集在训练时期的过程期间被迭代。
一旦确定批次,采样方法例如困难批次(BH)、全部批次(BA)、批次样本(BS)或批次加权(BW),其每一者在本文中更详细地描述,可被用于确定来自每个批的样本的子集,该样本的子集要由优化器用来增加DNN有效地学习并更快地收敛到可接受或最佳准确度的能力。在测试和验证期间,如本文更详细描述的,BS和BW通过产生如使用均值-平均精确度(mAP)和最高k精确度计算的更精确的结果而更有效地执行。然而,BS可以在一些数据集上和根据一些评估度量以比BW类似或更好的精度执行,同时需要更少的样本以由优化器使用(例如,来自每个批的单个样本可以用于BS,而BW可以使用具有不同权重的样本中的一些或全部)。
数据集还可经历使用一个或更多个GPU(例如,NVIDIA的VOLTA GPU)作为硬件和用于软件的机器学习平台(例如,TENSORFLOW)的增强(例如,在线增强)。在一些实施例中,数据增强可以包括图像翻转操作。然而,这不旨在是限制性的,并且除了图像翻转以外或替代图像翻转,可以执行任何其他数据增强操作,诸如旋转、缩放、颜色增强、拉近拉远、裁剪等。
在一些实施例中,DNN可从头(例如,端到端)训练或可从预先存在的或预训练的DNN训练。取决于训练是从头完成的还是使用预训练的DNN来微调的,可采用不同的学习速率调度。例如,在从头训练的情况下,可使用比在从预训练的DNN训练时使用的第二学习速率更大的第一学习速率。一旦DNN架构被确定,其在非限制性实施例中可以是卷积神经网络(CNN),DNN就可使用对比损失或三元组损失在一个或更多个数据集的批(或如本文中所描述的使用采样或挖掘确定的其子集)上进行训练。可以使用优化器,例如,但不限于Adam优化器(例如,在非限制性示例中具有默认参数,ε=10
此外,使用在此描述的DNN架构和训练方法,不需要时空信息(常规系统的主要部分)来跨帧进行准确的对象重新识别(并且具体地,车辆重新识别)。然而,在一些实施例中,可以利用时空信息来进一步提高准确度或用于冗余。
本公开的DNN一旦根据本文描述的训练过程被训练,就可准确且高效地(例如,实时地或接近实时地)计算环境中的对象的嵌入。然后,可以相对于嵌入空间比较嵌入以确定相同或不同的对象,使得可以在从任何数量的相机捕获的帧上重新识别和/或跟踪对象。例如,相机网络(诸如在城市、停车库等中)可以被利用来在对象行进穿过相机的视野时跟踪对象。以此方式,可跟踪对象移动和行为,且所述信息可用于异常检测、图案辨识、交通监视和/或类似物。
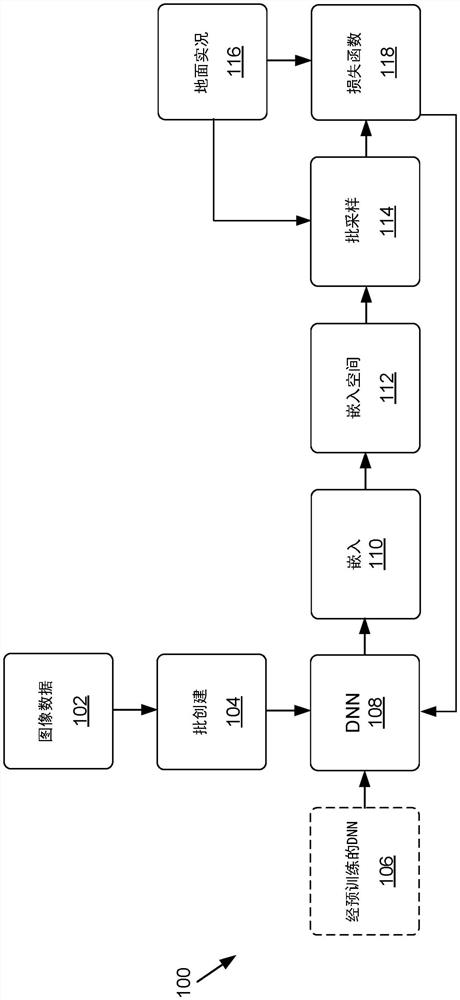
现在参见图1,图1包括根据本公开的一些实施例的训练深度神经网络(DNN)以预测用于对象重新识别的嵌入的过程100的数据流程图。可接收和/或生成表示由任何数量的相机捕获的图像(例如,静止或视频)的图像数据102。例如,图像数据102可以表示由单个相机顺序地捕获的图像、由多个相机同时捕获的图像、或由多个相机随时间捕获的图像。用于训练DNN 108的图像数据102可包括车辆(或其他对象类型)的图像,诸如多个不同车辆类型或身份的(例如,不同视点、照明水平、方向等的)多个图像。例如,可存在第一汽车的多个图像、第二汽车的多个图像等,其中每个不同图像表示车辆的不同视点、照明水平、遮挡水平、方向和/或其他捕获参数。在一些非限制性示例中,图像数据102可以包括来自预先组织的数据集的图像——如本文中更详细描述的VeRi数据集、车辆ID数据集或PKU-VD数据集。
由图像数据102表示的图像可经历批创建104以产生图像的多个批。例如,在一些非限制性实施例中,可以生成包括来自数据集的P个身份的多个批,可以针对每个身份P随机地对X和K个图像进行采样。因此,在一些非限制性实施例中,每个批可以包括P*K个图像。在一些非限制性示例中,P可以等于18并且K可以等于4,这样使得每个批是72(PK)个图像。通过使用此数量的图像,可以有效地生成批中的多样性(diversity),同时仍维持用于训练的相对小的批大小,从而减少总体训练时间并减少计算资源。其他示例可包括针对288(PK)个图像的总批大小使用其他批大小,例如其中P等于18且K可等于16。在使用BW采样变体的情况下,可以使用这种示例批大小,因为更多的样本可以应用于优化器,从而受益于样本中的更大多样性。这些示例批大小作为在测试和验证期间产生准确和有效的结果的示例而提供。然而,这些示例批大小不旨在是限制性的,并且可以使用任何批大小而不脱离本公开的范围。在非限制性实施例中,样本可被选择成使得整个训练数据集在训练时期的过程中被迭代。
各批图像(如由图像数据102所表示的)可作为输入被提供给深度神经网络(DNN)108。在一些示例中,DNN 108可在被用作用于学习嵌入110的DNN 108之前被预训练。例如,预训练的DNN 106可在一个或更多个另外的数据集上(例如,在其他图像数据上)被训练以预测嵌入。在一些示例中,预训练的DNN 106可被训练以预测用于重新识别任务的嵌入。在其他示例中,经预训练的DNN 106可被训练以预测用于其他任务的嵌入,并且关于过程100描述的训练可被用于更新经预训练的DNN 106以生成用于预测用于重新识别任务(诸如车辆重新识别任务)的嵌入110的DNN 108。在其中使用预训练的DNN的实施例中,学习速率可以不同于当DNN 108未从预训练的DNN 106训练时使用的学习速率。例如,在从经预训练的DNN 106训练DNN 108的情况下,可使用比当从头(例如,端到端地)训练DNN 108时使用的第二学习速率更小的第一学习速率。作为非限制性示例,第一学习速率可优选地在0.0002与0.0004之间,更优选地在0.00025与0.00035之间,并且最优选地为0.0003。作为另一个非限制性示例,第二学习速率可以优选地在0.002和0.0005之间,更优选地在0.0015和0.0008之间,并且最优选为0.001。
经预训练的DNN 106和/或DNN 108可包括任何类型的机器学习模型。例如,尽管本文中关于使用神经网络(特别是卷积神经网络(CNN))来描述示例,但这不旨在是限制性的。照此,但不限于,经预训练的DNN 106和/或DNN 108可包括使用线性回归、逻辑回归、决策树、支持向量机(SVM)、朴素贝叶斯、k最近邻(Knn)、K均值聚类、随机森林、降维算法、梯度提升算法、神经网络(例如,自动编码器、卷积、递归、感知器、长/短期记忆(LSTM)、霍普菲尔德、玻尔兹曼、深度信念、解卷积、生成对抗、液态机等)的一个或更多个机器学习模型,和/或其他类型的机器学习模型。
在预训练的DNN 106和/或DNN 108包括CNN的实施例中,CNN的层中的一个或更多个层可包括输入层。输入层可保持与图像数据102相关联的值。例如,当图像数据102是一个或更多个图像时,输入层可将表示一个或更多个图像的原始像素值的值保持为体(volume)(例如,宽度W、高度H和颜色通道C(例如,RGB),例如32x32x3),和/或批大小B(例如,在批创建104之后)。
一个或更多个层可以包括卷积层。卷积层可以计算连接到输入层(例如,输入层)中的局部区域的神经元的输出,每个神经元计算它们的权重与它们连接的输入体中的小区域之间的点积。卷积层的结果可以是另一个体,其中一个维度基于所应用的滤波器的数量(例如,宽度、高度和滤波器的数量,诸如32x32x12,如果12是滤波器的数量)。
一个或更多个层可以包括整流线性单元(ReLU)层。一个或更多个ReLU层可以应用逐元素激活函数,例如max(0,x),例如零阈值化。得到的ReLU层的体可以与ReLU层的输入的体相同。
这些层中的一个或更多个层可以包括池化层。池化层可以沿着空间维度(例如,高度和宽度)执行下采样操作,这可以导致比池化层的输入更小的体(例如,来自32x32x12输入体的16x16x12)。在一些示例中,经预训练的DNN 106和/或DNN 108可以不包括任何池化层。在这样的示例中,可以使用跨步的卷积层代替池化层。在一些示例中,DNN可包括交替的卷积层和池化层。
这些层中的一个或更多个层可包括全连接层。一个或更多个全连接层中的每个神经元可连接到先前体中的每个神经元。在一些示例中,可不使用全连接层来努力增加处理时间和减少计算资源要求。在这样的示例中,在没有使用全连接层的情况下,经预训练的DNN 106和/或DNN 108可被称为完全卷积网络。
在一些示例中,这些层中的一个或更多个层可包括一个或更多个解卷积层。然而,术语解卷积的使用可能是误导性的并且不旨在是限制性的。例如,解卷积层可替代地称为转置卷积层或部分跨步的卷积层。一个或更多个解卷积层可用于对先前层的输出执行上采样。例如,一个或更多个解卷积层可以用于上采样至与输入图像(例如,由图像数据102表示)的空间分辨率相等的空间分辨率,或者用于上采样至下一层的输入空间分辨率。
尽管本文讨论了输入层、卷积层、池化层、ReLU层、解卷积层和全连接层,但这不旨在是限制性的。例如,可以在诸如归一化层、SoftMax层、SoftPlus层和/或其他层类型中使用附加的或替代的层。如本文所述,在一些实施例中,可以不使用用于对嵌入110进行归一化的归一化层来努力减少嵌入110的塌陷。例如,如图4A中所示并且在测试期间,DNN 108在使用三元组损失而没有归一化时的性能好于使用归一化时的性能。
CNN的各层中的至少一些层可包括参数(例如,权重和/或偏差),而其他层可不包括,例如ReLU层和池化层。在一些示例中,参数可由预训练的DNN 106和/或DNN 108在训练期间学习。进一步地,这些层中的一些可以包括附加超参数(例如,学习速率、步幅、时期、内核大小、过滤器数量、用于池化层的池化类型等),诸如一个或更多个卷积层、一个或更多个解卷积层以及一个或更多个池化层,而其他层可以不包括附加超参数,诸如一个或更多个ReLU层。可以使用各种激活函数,包括但不限于ReLU、泄漏ReLU、sigmoid、双曲线正切(tanh)、指数线性单位(ELU)等。参数、超参数和/或激活函数不受限制并且可以取决于实施例而不同。
每个批内的图像数据102可应用于DNN 108,且DNN可计算或预测嵌入110。嵌入可以表示具有嵌入维度的特征向量,其中嵌入表示在嵌入空间112中对应于特定对象(例如,车辆)的位置。训练DNN 108的目标可以是将同一对象的嵌入110预测为更靠近在一起,而不同对象的嵌入110相隔更远。照此,在嵌入空间112内嵌入110更靠近在一起(例如,在阈值距离内)的情况下,确定可以是两个嵌入110属于同一对象。照此,在同一对象的两个或更多个嵌入110彼此靠近,且嵌入110是从两个或更多个不同图像(例如,从不同相机、视点、视角、方向、照明水平等)计算的情况下,可在图像中的每一者中重新识别同一对象以用于执行一个或更多个操作(例如,跟踪对象、检测异常等)。
DNN 108可被训练成计算具有嵌入维度的嵌入110。例如,如本文所述,嵌入维度越大,嵌入110中可能存在的用于区分同一和不同对象的上下文就越多。然而,较大的嵌入维度导致DNN 108的较长的训练时间以及在训练和推理期间计算资源的增加。例如,超过256个单位的嵌入维度可将DNN 108限制为非实时部署,因为DNN 108可能不能计算嵌入110以供实时或近实时地使用。照此,在一些非限制性实施例中,DNN 108的嵌入维度可以优选地等于或小于256个单位,并且更优选地可以是128个单位。如图4A-4D中所指示的,DNN 108的测试和验证已被证明DNN 108甚至在嵌入维度是128个单位时具有可接受的准确度。照此,由于使用了批采样变体(例如,BS和/或BW),使用三元组损失来训练DNN 108、和/或本文中描述的其他训练参数,DNN 108可被训练成计算具有128个单位的嵌入维度的嵌入110,同时产生实现DNN 108的实时部署以用于重新识别任务的准确且高效的结果。
可以将嵌入110应用于嵌入空间112,其中嵌入空间112可以用于检测属于同一对象的嵌入110的集群或组。嵌入空间112可以是在DNN 108的降维之后数据被嵌入其中的空间。在推理期间,嵌入空间112中的嵌入110的位置可以用于重新识别对象和/或确定两个或更多个对象不是同一对象。类似地,在训练期间,当已知两个或更多个嵌入110属于同一对象或不同对象(如在地面实况116中表示的)时,嵌入空间112中的嵌入110的位置可以用于确定DNN 108的准确性,以及使用一个或更多个损失函数118(例如,在一些示例中,三元组损失函数)来更新DNN 108的参数。例如,在DNN 108的预测指示对应于同一对象的两个嵌入110在嵌入空间112中相距较远的情况下,该信息可被用于更新DNN 108,以使得这两个嵌入110被预测为彼此更靠近。类似地,在DNN 108的预测指示对应于不同对象的两个嵌入110在嵌入空间112中靠近在一起的情况下,该信息可以用于更新DNN 108,使得两个嵌入110被预测为彼此分开更远。
可以在批采样114期间使用批采样变体对由DNN 108针对图像数据102的批计算的嵌入110进行采样。例如,三元组损失或对比损失对于实际数据集而言可能是计算上禁止的,因此批采样114可被用于缩减数据点以用于计算损失(例如,用于识别对训练DNN 108更有用的嵌入110)。这可能是有价值的,因为相对于平凡的或不准确的数据点(例如,离群值、异常值等)的计算损失可能损害DNN 108的收敛。在车辆重新识别的背景下,针对相同身份从不同视图(例如,侧视图和前视图)进行采样可能比重复考虑来自相同视图的采样信息更多。
对于非限制性示例,如在此至少关于图2A-2C所描述的,可以使用各种批采样变体。例如,可使用全部批次(BA)、困难批次(BH)、批次加权(BW)、批次样本(BS)或另一采样变体。在一个或更多个非限制性示例中,如图4A-4D所示,BW和BS可以在训练之后提供关于DNN108的预测的最准确的结果。
BA是均匀采样技术,其为该批中的所有样本提供统一的权重。例如,并且参照图2A,每个样本可被使用(例如,由优化器使用损失函数118),并且每个样本可被给予统一的权重(例如,1)。然而,统一的权重分布可以忽略重要的棘手的(或困难)样本的贡献,因为这些棘手的样本通常被这平凡的(或容易)样本战胜(outweight)。BH的特征在于针对每个批的困难数据挖掘,其中仅最难的正和负样本(例如,DNN 108最难以准确地计算)用于每个锚样本。然而,最困难的样本通常是离群值,并且离群值可能导致不准确性。例如,当事实上计算是准确的并且标记是不正确的时,错误标记的数据(例如,不正确的地面实况116)可导致样本被诊断为难的,从而导致不准确的数据被用于训练。
为了补偿BA和BH的缺点,可以使用BW和/或BS。BW采用加权方案,其中基于样本与相应锚的距离对样本进行加权,从而与平凡样本相比给予信息、更困难的样本更多的重要性。BS使用锚到样本距离的分布来挖掘针对该锚的正和负数据。例如,BS将所有距离视为概率,并且这些概率被给到多项式分布生成器(或分类分布生成器)。然后,生成器的输出指示应当用于训练的样本中的负样本和/或正样本。该样本可以是正和负中的每一个的单个样本。这样,类似于BH,可以给单个样本全部权重,或者权重为1。在一些示例中,距离的值可能不加到1(如一般针对分布所假定的),但这不存在问题,因为底层实现固有地解决此问题。使用BS还通过使用概率性采样方法来避免确定性采样,从而为错误标记的数据或者为数据中的其他离群值或异常值提供离群值保护。
参考图2A,图2A是根据本公开的一些实施例的包括用于计算各个采样变体的权重的示例等式的表。表100总结了使用不同批次采样变体对正p和负n进行采样的不同方式。在表100中,a是锚样本,N(a)是对应锚a的负样本的子集,P(a)是对应锚a的正样本的子集,w
图2B是根据本公开的一些实施例的包括嵌入距锚嵌入的示例距离的图表202。例如,图表202包括九个不同样本的距锚(在嵌入空间112中)的距离。图表202可以表示针对正样本的距离,并且类似的图表可以用于负样本(除了针对负样本更短的距离将被惩罚更多)。在一些示例中,距离可被归一化(如在图表202中),而在其他示例中,距离可不被归一化。
图2C包括图表204A-204D,示出了根据本公开的一些实施例的各个采样变体的权重。例如,图表204A包括在距离图表202的距离上使用BA的图示。在这样的示例中,每个样本将被给予相同的权重(例如,在该非限制性示例中为0.1)。图表204B包含使用BH的说明,其中给予最难样本(例如,预测为距锚最远的正样本,即使它们属于同一对象)全部权重(例如,在此非限制性示例中为1.0)。图表204C包括使用BW的说明,其中样本各自基于其与锚的距离而加权,使得正样本的较远距离比较近距离更重地加权。此加权将针对负样本而反转,其中较近的样本将比负样本更重地加权。图表204D包括使用BS的图示,其中每个距离被转换成概率,并且多项式分布生成器生成指示样本7是用于训练的最有效样本的输出。这可能是因为对于与样本7相对应的0.8的距离存在更高的概率,从而摆脱使用BH捕获的样本9的潜在离群值。照此,由于采样技术的概率性质,可以使用BS采样变体来捕获最相关的样本。
再次参考图1,一旦使用批采样114挖掘了正和/或负样本,所挖掘的样本然后可以由使用损失函数118的优化器使用以训练DNN 108。照此,因为用于训练的样本已经被挖掘(例如,在优选实施例中使用BW和/或BS),所以与常规系统相比计算资源被减少,因为训练集被微调并且因此导致更快的收敛。另外,DNN 108可能在训练之后更准确,因为离群值被从训练集中修剪掉,并且更多信息数据点被使用(或相对于BW更重地加权)以代替更平凡的数据点。
在一些实施例中,损失函数118可包括对比损失函数或三元组损失函数。然而,如本文所描述的,三元组损失已被示为用于训练DNN 108的有效损失函数(如至少在图4A中指示的)。使用三元组损失的DNN 108的此准确度可以是通过在同一项中使用正样本和负样本两者所提供的附加上下文的结果。三元组损失迫使来自相同类别的数据点比来自任何其他类别的数据点更接近彼此。在非限制性示例中,三元组损失函数可由以下等式(1)表示:
l
三元组损失的另一表示包括下面的等式(2):
l
照此,可根据以下等式(3)来获得训练时期中的总损失:
在一些实施例中,三元组损失函数中的裕度α可以由SoftPlus函数ln(1+exp(·))替换,以避免调节裕度的需要。
参考图3,图3是根据本公开的一些实施例的使用三元组损失来训练DNN以预测嵌入的图示。例如,表示锚图像202A的第一图像数据可以被应用于DNN 108A的实例化以生成嵌入110A,表示正图像202B的第二图像数据可以应用于DNN 108B的实例化以生成嵌入110B,并且表示负图像202C的第三图像数据可以应用于DNN 108C的实例化以生成嵌入110C。地面实况116可以指示正图像202B包括与锚图像202A相同的车辆,并且负图像202C包括与锚图像202A不同的车辆。照此,作为DNN 108的优化器或训练机器的部分,嵌入110A、110B和110C可被应用于三元组损失函数204,以更新DNN 108的参数(例如,权重和偏差)。例如,在正图像202B中的车辆远离嵌入空间112中的锚图像202A的车辆的情况下,三元组损失函数204可以用于更新DNN 108以预测嵌入110B在随后的迭代中更靠近嵌入110A。类似地,在负图像202C中的车辆接近嵌入空间112中的锚图像202A的车辆的情况下,三元组损失函数204可以用于更新DNN108,以在随后的迭代中将嵌入110C预测为更远离嵌入110A。在一些示例中,如在此所描述的,可以使用批采样变体(如BS或BW)来选择和/或加权正图像202B和负图像202C。
为了测试和验证训练、批采样变体、超参数和DNN架构的不同组合,使用了不同评估度量。例如,使用均值精确度(mAP)和最高k准确度来评估和比较不同方法。例如,在重新识别评估设置中,可以存在查询集合和图库集合。对于查询集合中的每个车辆,目的或目标可以是从图库集合检索类似身份。照此,用于查询图像q的AP(q)可根据以下等式(4)来定义:
其中k是排名,P(k)是排名k处的精度,N
其中Q是查询图像的总数。
现在参考图4A,图4A是根据本公开的一些实施例的表格400,其包括使用对比损失或三元组损失以及归一化或没有归一化层对数据集进行测试的结果。例如,表格400包括VeRi数据集的示例结果,VeRi数据集包括图库集合中的1678个查询图像和11579个图像。对于每个查询图像,图库集合包含具有相同查询身份但取自不同相机(关键评估标准)的图像,因为由不同相机捕获的同一车辆包括在视觉上不相似的样本。表格400包括对VeRi数据集使用三元组损失和对比损失、以及对嵌入使用归一化层和不对嵌入使用归一化层的结果。如图所示,BS、三元组损失和无归一化层的组合相对于mAP、top-1和top-5产生最准确的结果,而BA、三元组损失和无归一化相对于top-2产生最准确的结果(尽管BS仅稍微不太有效)。
现在参见图4B,图4B是根据本公开的一些实施例的包括使用不同采样变体对数据集进行的测试结果的表402。例如,表402包括采用PKU-VD训练集的结果,该PKU-VD训练集包括两个子数据集VD1和VD2。这两个训练集都包括约400,000个训练图像,并且每个子数据集的测试集被分成三个参考集:小(VD1:106,887个图像;VD2:105,550个图像)、中(VD1:604,432个图像;VD2:457,910个图像)以及大(VD1:1,097,649个图像;VD2:807,260个图像)。由于PKU-VD数据集的大小,DNN 108可从头训练。另外,由于类内样本的数目,在一些实施例中可增加用于三元组损失的批大小。表402示出了在PKU-VD数据集的两个子数据集上的不同批采样变体的mAP。如所指示的,对于VD1,BW优于小训练集的其他采样变体,并且BH优于VD1的中等和大型数据集上的其他采样变体。然而,关于VD2,BW优于小型、中等和大型数据集中的每一个的每个其他采样变体。此外,对于所有数据集,采样变体中的每一个优于BA。
现在参见图4C和图4D,图4C和图4D分别是根据本公开的一些实施例的表404和406,包括使用各种采样变体对数据集进行的测试结果。例如,表404和406包括具有包括车辆的前视图和后视图的车辆ID训练集的结果。在车辆ID训练集中包括小(800个身份)、中(1600个身份)、大(2400个身份)和超大(13164个身份)。对于每个参考集合,随机地选择用于每个身份的范例或锚,并且构建图库集合。该过程重复十次以获得平均的评估度量。表404和406中的结果包括对DNN不使用归一化层进行嵌入的结果。表404使用18x16的批大小(PK),表406使用18x4的批大小(PK)。如表格404和406所指示的,BS和BW胜过其他采样变体。
现在参见图5,在此描述的方法500的每个框包括可以使用硬件、固件和/或软件的任何组合执行的计算过程。例如,不同功能可由执行存储在存储器中的指令的处理器执行。方法500还可以体现为存储在计算机存储介质上的计算机可用指令。仅举几例,方法500可以由独立应用、服务或托管服务(独立地或与另一托管服务组合)或另一产品的插件来提供。此外,通过举例的方式,关于图1的过程100来描述方法500。然而,此方法可另外或替代地由任何系统或系统的任何组合执行,所述系统包括但不限于本文中所描述的系统或系统的任何组合。
图5是示出根据本公开的一些实施例的用于训练深度神经网络以预测用于对象重新识别的嵌入的方法500的流程图。在框B502,方法500包括计算表示对应于嵌入空间的嵌入的数据。例如,DNN 108可以计算对应于嵌入空间112的嵌入110。
在框B504处,方法500包括计算锚嵌入和每个正嵌入之间的第一距离集合以及锚嵌入和每个负嵌入之间的第二距离集合。例如,在使用三元组损失的情况下,可以针对每个正嵌入和锚嵌入确定嵌入空间112中的第一距离,并且可以针对每个负嵌入和锚嵌入确定嵌入空间112中的第二距离。
在框B506处,方法500包括确定对应于第一距离的第一分布和对应于第二距离的第二分布。在一个或更多个实施例中,这些分布中的一者或两者可以是多项式分布、分类分布或两者。例如,BS可用于计算正样本的第一多项式分布和负样本的第二多项式分布。
在框B508处,方法500包括选择与第一最高概率相关联的正嵌入和与第二最高概率相关联的负嵌入。例如,可以选择来自该批的多个正嵌入中具有最高概率的正嵌入,并且可以选择来自该批的多个负嵌入中具有最高概率的负嵌入。
在框B510,方法500包括使用正嵌入和负嵌入来训练神经网络。例如,正嵌入和负嵌入可被应用于优化器或训练机器以更新DNN 108的参数。
图6是适合用于实现本公开的一些实施例的示例计算设备600的框图。计算设备600可包括直接或间接耦合以下设备的总线602:存储器604,一个或更多个中央处理单元(CPU)606,一个或更多个图形处理单元(GPU)608,通信接口610,输入/输出(I/O)端口612,输入/输出组件614,电源616,以及一个或更多个呈现组件618(例如,显示器)。
尽管图6的各个框被示出为经由总线602与线路连接,但这并不旨在是限制性的,并且仅是为了清楚起见。例如,在一些实施例中,诸如显示设备之类的呈现组件618可被认为是I/O组件614(例如,如果显示器是触摸屏)。作为另一个示例,CPU 606和/或GPU 608可以包括存储器(例如,存储器604可以表示除了GPU 608的存储器、CPU 606和/或其他组件之外的存储设备)。换言之,图6的计算设备仅是说明性的。在如“工作站”、“服务器”、“膝上型计算机”、“台式机”、“平板电脑”、“客户端设备”、“移动设备”、“手持式设备”、“游戏控制台”、“电子控制单元(ECU)”、“虚拟现实系统”、“车辆计算机”和/或其他设备或系统类型的此类类别之间不做区分,因为所有都被考虑在图6的计算设备的范围内。
总线602可以表示一条或更多条总线,诸如地址总线、数据总线、控制总线或其组合。总线602可包括一种或更多种总线类型,诸如工业标准架构(ISA)总线、扩展工业标准架构(EISA)总线、视频电子标准协会(VESA)总线、外围组件互连(PCI)总线、外围组件互连快速(PCIe)总线和/或另一类型的总线。
存储器604可包括各种各样的计算机可读介质中的任何介质。计算机可读介质可以是可由计算设备600访问的任何可用介质。计算机可读介质可以包括易失性和非易失性介质,以及可移除和不可移除介质。作为示例而非限制性地,计算机可读介质可包括计算机存储介质和通信介质。
计算机存储介质可以包括易失性和非易失性介质和/或可移除和不可移除介质,其以用于存储诸如计算机可读指令、数据结构、程序模块和/或其他数据类型之类的信息的任何方法或技术实现。例如,存储器604可存储计算机可读指令(例如,其表示程序和/或程序元素,例如操作系统)。计算机存储介质可以包括但不限于RAM、ROM、EEPROM、闪存或其他存储器技术、CD-ROM、数字多功能盘(DVD)或其他光盘存储、磁带盒、磁带、磁盘存储装置或其他磁存储设备,或可用于存储所需信息且可由计算设备600访问的任何其他介质。当在本文使用时,计算机存储介质不包括信号本身。
通信介质可以在诸如载波之类的调制数据信号或其他传输机制中包含计算机可读指令、数据结构、程序模块和/或其他数据类型,并且包括任何信息输送介质。术语“调制数据信号”可以指这样的信号,该信号使它的特性中的一个或更多个以这样的将信息编码到该信号中的方式设置或改变。举例而言且非限制性地,通信介质可以包括诸如有线网络或直接有线连接之类的有线介质,以及诸如声音、RF、红外和其他无线介质之类的无线介质。任何以上所述的组合也应当包含在计算机可读介质的范围内。
一个或更多个CPU 606可被配置为执行计算机可读指令,以控制计算设备600的一个或更多个组件执行本文所描述的方法和/或过程中的一个或更多个。CPU 606可用于执行本文中至少关于过程100所描述的功能中的一个或更多个。例如,一个或更多个CPU 606可在关于DNN 108的训练和/或推理期间被用来计算嵌入、执行批采样等。一个或更多个CPU606中的每一个可以包括能够同时处理大量软件线程的一个或更多个核(例如,一个、两个、四个、八个、二十八个、七十二个等)。一个或更多个CPU 606可包含任何类型的处理器,且可包含不同类型的处理器,这取决于所实现的计算设备600的类型(例如,用于移动设备的具有较少核的处理器和用于服务器的具有较多核的处理器)。例如,取决于计算设备600的类型,处理器可以是使用精简指令集计算(RISC)实现的ARM处理器或使用复杂指令集计算(CISC)实现的x86处理器。除了一个或更多个微处理器或诸如数学协处理器之类的补充协处理器之外,计算设备600还可以包括一个或更多个CPU 606。
一个或更多个GPU 608可由计算设备600用来渲染图形(例如,3D图形)和/或执行处理(例如,并行处理、作为通用GPU(GPGPU)的通用处理等)。一个或更多个GPU 608可用于至少相对于过程100执行本文中所描述的功能中的一个或更多者。例如,一个或更多个GPU608可在关于DNN 108的训练和/或推理期间被用于计算嵌入、执行批采样等。一个或更多个GPU 608可以包括能够同时处理数百或数千个软件线程的数百或数千个核。一个或更多个GPU 608可响应于渲染命令(例如,经由主机接口从一个或更多个CPU 606接收的渲染命令)生成用于输出图像的像素数据。一个或更多个GPU 608可包含例如显示存储器之类的用于存储像素数据的图形存储器。显示存储器可作为存储器604的部分而被包括。一个或更多个GPU 708可包含(例如,经由链路)并行操作的两个或更多GPU。当组合在一起时,每个GPU608可生成用于输出图像的不同部分或用于不同输出图像(例如,第一图像的第一GPU和第二图像的第二GPU)的像素数据。每个GPU可包含其自己的存储器,或可与其他GPU共享存储器。
在计算设备600不包含一个或更多个GPU 608的示例中,一个或更多个CPU 606可用于渲染图形和/或执行过程100内的其他任务。
通信接口610可以包括一个或更多个接收器、发送器和/或收发器,其使得计算设备700能够经由包括有线和/或无线通信的电子通信网络与其他计算设备通信。通信接口610可包括用于实现通过多个不同网络中的任何网络进行通信的组件和功能,所述网络诸如无线网络(例如,Wi-Fi、Z波、蓝牙、蓝牙LE、ZigBee等)、有线网络(例如,通过以太网通信)、低功率广域网(例如,LoRaWAN、SigFox等)和/或互联网。
I/O端口612可以使计算设备600能够逻辑地耦合到包括I/O组件614、一个或更多个呈现组件618和/或其他组件的其他设备,其中一些可以被内置到(例如,集成到)计算设备600中。说明性I/O组件614包括麦克风、鼠标、键盘、操纵杆、游戏手柄、游戏控制器、碟形卫星天线、扫描仪、打印机、无线设备等。I/O组件614可以提供处理用户生成的空中手势、语音或其他生理输入的自然用户接口(NUI)。在一些实例中,可将输入传输到适当的网络元件以供进一步处理。NUI可实现语音识别、指示笔识别、面部识别、生物特征识别、屏幕上和屏幕附近的姿势识别、空中姿势、头部和眼睛跟踪以及与计算设备600的显示器相关联的触摸识别(如以下更详细地描述的)的任何组合。计算设备600可包括用于手势检测和识别的深度相机,诸如立体相机系统、红外相机系统、RGB相机系统、触摸屏技术以及这些的组合。另外,计算设备600可以包括使得能够检测运动的加速度计或陀螺仪(例如,作为惯性测量单元(IMU)的部分)。在一些示例中,计算设备600可以使用加速度计或陀螺仪的输出来渲染沉浸式增强现实或虚拟现实。
电源616可包括硬接线电源、电池电源或其组合。电源616可以向计算设备600提供电力以使得计算设备600的组件能够操作。
一个或更多个呈现组件618可包括显示器(例如,监视器、触摸屏、电视屏幕、平视显示器(HUD)、其他显示器类型或其组合)、扬声器和/或其他呈现组件。一个或更多个呈现组件618可以从其他组件(例如,一个或更多个GPU 608、一个或更多个CPU 606等)接收数据,并且输出数据(例如,作为图像、视频、声音等)。
本公开可以在计算机代码或机器可用指令的一般上下文中描述,包括由计算机或其他机器(诸如个人数据助理或其他手持式设备)执行的计算机可执行指令(诸如程序模块)。通常,包括例程、程序、对象、组件、数据结构等的程序模块是指执行特定任务或实现特定抽象数据类型的代码。本公开可以在各种系统配置中实践,包括手持式设备、消费电子产品、通用计算机、车辆计算机、基于云的计算机、客户端/服务器架构、分布式计算机架构、更专业的计算设备等。本公开还可以在其中任务由通过通信网络链接的远程处理设备来执行的分布式计算环境中实践。
如在本文中使用的,关于两个或更多元素对“和/或”的叙述应当解释为仅指一个元素或者元素的组合。例如,“元素A、元素B和/或元素C”可以包括仅元素A,仅元素B,仅元素C,元素A和元素B,元素A和元素C,元素B和元素C,或者元素A、B和C。此外,“元素A或元素B中的至少一个”可以包括元素A中的至少一个,元素B中的至少一个,或者元素A中的至少一个和元素B中的至少一个。进一步,“元素A和元素B中的至少一个”可以包括元素A中的至少一个,元素B中的至少一个,或者元素A中的至少一个和元素B中的至少一个。
本文详细地描述了本公开的主题以满足法定要求。然而,描述本身并不意图限制本公开的范围。相反地,本发明人已经设想到,要求保护的主题也可以以其他的方式具体化,以包括与本文中结合其他当前或未来技术描述的步骤不同的步骤或者相似的步骤的组合。而且,尽管术语“步骤”和/或“框”在本文中可以用来隐含采用的方法的不同元素,但是这些术语不应当被解释为暗示本文公开的各个步骤之中或之间的任何特定顺序,除非明确描述了各个步骤的顺序。
权利要求书(按照条约第19条的修改)
1.一种方法,包括:使用神经网络的一个或更多个实例来计算表示对应于嵌入空间的嵌入的数据,所述嵌入包括对应于锚图像并且描绘第一车辆的锚嵌入、对应于描绘所述第一车辆的图像的多个正嵌入、以及对应于描绘与所述第一车辆不同的第二对象的图像的多个负嵌入;至少部分地基于所述数据,计算所述锚嵌入与所述多个正嵌入中的每个正嵌入之间的第一距离集合以及所述锚嵌入与所述多个负嵌入中的每个负嵌入之间的第二距离集合;确定对应于所述第一距离集合的第一分布和对应于所述第二距离集合的第二分布;从来自所述第一分布的所述多个正嵌入中选择与最高概率相关联的正嵌入,并且从来自所述第二分布的所述多个负嵌入中选择与最高概率相关联的负嵌入;以及使用所述正嵌入和所述负嵌入来训练所述神经网络。
2.根据权利要求1所述的方法,其中当从预训练的模型训练所述神经网络时,以第一学习速率训练所述神经网络,并且当端到端地训练所述神经网络时,以大于所述第一学习速率的第二学习速率训练所述神经网络。
3.根据权利要求2所述的方法,其中所述第一学习速率在0.0002与0.0004之间,并且所述第二学习速率在0.0009与0.002之间。
4.根据权利要求1所述的方法,其中所述嵌入包括等于或小于128个单位的嵌入维度。
5.根据权利要求1所述的方法,其中所述训练所述神经网络包括使用对比损失函数或三元组损失函数中的至少一个。
6.根据权利要求5所述的方法,其中所述三元组损失函数包括SoftPlus函数。
7.根据权利要求5所述的方法,其中所述神经网络不包括用于计算所述数据的归一化层。
8.根据权利要求1所述的方法,其中所述训练所述神经网络包括:生成多批图像,所述多批图像中的每个批包括多个车辆类型和针对所述车辆类型中的每个车辆类型的多个样本。
9.根据权利要求1所述的方法,其中所述训练所述神经网络使用一个或更多个图形处理单元(GPU)。
10.根据权利要求1所述的方法,还包括:在训练之后部署所述神经网络以识别由一个或更多个相机捕获的多个图像上的车辆。
11.根据权利要求1所述的方法,其中在训练所述神经网络期间,忽略除了所述正嵌入之外的其他正嵌入和除了所述负嵌入之外的其他负嵌入。
12.根据权利要求1所述的方法,其中所述第一分布或所述第二分布中的至少一个包括多项式分布或分类分布中的至少一个。
13.一种方法,包括:使用神经网络的多个实例来计算表示对应于嵌入空间的嵌入的数据,所述嵌入包括对应于描绘车辆的锚图像的第一嵌入和对应于描绘所述车辆的图像的多个第二嵌入;至少部分地基于所述数据,确定对应于所述第一嵌入与所述多个第二嵌入中的每个第二嵌入之间的距离的分布;至少部分地基于所述分布,从来自所述分布的所述多个第二嵌入中选择与最高概率相关联的第二嵌入;以及使用所述第二嵌入来训练所述神经网络。
14.根据权利要求13所述的方法,其中所述分布是多项式分布或分类分布中的至少一个。
15.根据权利要求13所述的方法,其中所述训练所述神经网络包括使用对比损失函数或三元组损失函数中的至少一个。
16.根据权利要求15所述的方法,其中当使用所述三元组损失函数时,所述嵌入还包括与描绘除所述车辆之外的另一对象的其他图像相对应的多个第三嵌入,并且所述方法还包括:确定与所述第一嵌入和所述多个第三嵌入中的每个第三嵌入之间的距离相对应的另一分布;以及至少部分地基于所述另一分布,从来自所述另一分布的所述多个第三嵌入中选择与另一最高概率相关联的第三嵌入,其中所述训练所述神经网络还至少部分地基于所述第三嵌入。
17.根据权利要求15所述的方法,其中当使用所述三元组损失函数时,所述三元组损失函数包括SoftPlus函数。
18.一种系统,包括:一个或更多个相机,用于生成表示环境的数据;计算设备,其包括一个或更多个处理设备和通信地耦合至所述一个或更多个处理设备的一个或更多个存储器设备,所述一个或更多个存储器设备在其上存储有编程指令,当所述编程指令由所述处理器执行时,则实现以下项的实例化:车辆标识符,用于使用神经网络并且至少部分地基于所述数据,计算对应于所述环境中的一个或更多个车辆的嵌入,使用分布来训练所述神经网络以识别由所述神经网络计算的训练嵌入的子集,所述训练嵌入的子集用于训练所述神经网络;以及车辆追踪器,用于至少部分地基于所述嵌入通过由所述数据表示的多个帧追踪所述一个或更多个车辆中的车辆。
19.根据权利要求18所述的系统,其中所述分布是多项式分布或分类分布中的至少一个。
20.根据权利要求18所述的系统,其中所述训练嵌入的子集用于使用对比损失函数或三元组损失函数中的至少一个来训练所述神经网络。
21.根据权利要求18所述的系统,其中所述神经网络是使用概率采样方法来进一步训练的。
- 训练神经网络以用于车辆重新识别
- 训练用于图像识别的神经网络的方法和神经网络设备