一种基于密度聚类的科研合作团体发现方法
文献发布时间:2023-06-19 11:39:06
技术领域
本发明涉及合作团体发现领域,特别是一种基于密度聚类的科研合作团体发现方法。
背景技术
科研协作是指科研人员的个人与个人、个人与团体、团体与团体之间为完成同一科研任务而彼此按照计划协同合作的劳动形态。科学研究是一项复杂、艰巨的群体劳动,在科研活动中人与人之间的相互作用直接影响着科研协作和科研计划的完成。在过去相当长的历史时期内,科学研究处于相对分散、缺乏组织的状态中,科学研究是个体进行的“自由研究”,科学研究主要靠那些“大师”和“发明家”来完成。
随着现代科学研究的深入,科研协作的重要性正被越来越多的人们所认识。进行科研协作是攻克科学难关、促进科技进步的需要,而目前如何组织、协调科研协作,是管理工作者面临的一个重要课题。科研领域中存在着许多跨领域的合作,合作往往以论文的形式体现。跟踪和把握专家的合作团队关系,在科教兴国中显得尤为重要。但是,目前科研合作团队的发现主要依托于社区发现相关算法,或是进行人工标注,算法复杂度高、准确率低、耗时长。
发明内容
本发明的目的在于提供一种能够快速、准确的找到给定论文集中的专家合作团队以及核心专家的科研合作团体发现方法,利用密度聚类自适应性好的特点,自动的挖掘出科研团队和科研团队的核心。
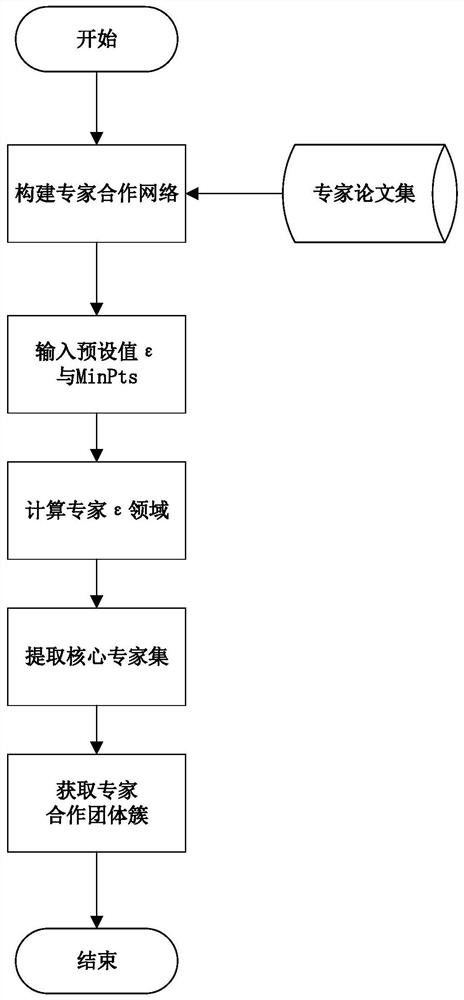
实现本发明目的的技术解决方案为:一种基于密度聚类的科研合作团体发现方法,包括以下步骤:
步骤1,导入批量论文数据,将批量论文数据作为训练集;
步骤2,对论文数据进行预处理,提取专家合作信息,即同一论文下的专家姓名集;
步骤3,利用专家合作信息构造专家合作关系网络,利用Dijkstra算法计算专家与专家之间的最短路径;
步骤4,利用专家之间的最短路径构建每个专家的专家合作∈领域,其中∈表示领域的半径;
步骤5,利用专家合作∈领域中专家的数量,确定核心专家,构建核心专家集;
步骤6,依据核心专家集获得专家合作网络中所有合作团体簇。
进一步地,步骤3所述的利用专家合作信息构造专家合作关系网络,利用Dijkstra算法计算专家与专家之间的最短路径,具体如下:
步骤3.1、根据论文作者列表信息,以作者作为节点,将共同撰写论文的作者用边连接起来,共同撰写论文数的倒数作为边的权重,构造专家合作信息无向加权图G(V,E),节点i与节点j之间边的权重w
其中,V表示专家合作信息无向加权图的点集、E表示专家合作信息无向加权图的边集、Count表示专家之间合作论文的数量;
步骤3.2、利用Dijkstra算法计算专家合作信息无向加权图G中专家与专家之间的最短路径,具体步骤如下:
步骤3.2.1、输入专家合作信息无向加权图G(V,E),输入目标专家姓名作为源点v
步骤3.2.2、用邻接矩阵arcs表示无向加权图,arcs[m][n]表示边 步骤3.2.3、设置集合S记录已求得最短路径的顶点,令集合S初始值为{v 步骤3.2.4、设置数组dist[]记录从源点v 步骤3.2.5、从顶点集合V-S中选出v 步骤3.2.6、修改从源点v 步骤3.2.7、重复步骤3.2.5~步骤3.2.6至集合V-S为空集; 步骤3.2.8、输出数组dist[],其中专家点v 进一步地,步骤4所述的利用专家之间的最短路径构建每个专家的专家合作∈领域,具体如下: 步骤4.1、输入预设值∈以及由步骤3生成的专家合作关系网络; 步骤4.2、遍历专家集,对每一个专家i,选取所有与专家i距离不大于∈的专家作为该专家的∈领域。 进一步地,步骤5所述的利用专家合作∈领域中专家的数量,确定核心专家,构建核心专家集,具体如下: 步骤5.1、输入预设值MinPts以及由步骤4生成的专家的∈领域; 步骤5.2、计算专家的∈领域中专家的总数,若该值大于预设值MinPts,则该专家视为核心专家,将该专家放入核心专家集; 步骤5.3、重复步骤5.2至所有专家均被遍历,并输出核心专家集。 进一步地,步骤6所述的依据核心专家集获得专家合作网络中所有合作团体簇,具体如下: 步骤6.1、在核心专家集中任意选择一个核心专家,找出其所有密度可达的专家并生成该专家的合作团体簇;密度可达专家定义如下: 对于专家i与专家j,若存在专家序列P 若专家j在专家i的∈领域中,则专家j为专家i的密度直达专家; 步骤6.2、从剩余的核心专家中移除步骤6.1中找到的密度可达的专家; 步骤6.3、从更新后的核心专家集中重复执行步骤6.1~6.2直到所有核心专家都被遍历或移除; 步骤6.4、输出专家的合作团体簇。 本发明与现有技术相比,其显著优点在于:(1)利用密度聚类自适应性好的特点,能够自动的挖掘出科研团队和科研团队的核心,方法简单,效率和准确性高;(2)能够快速的找到给定论文集中的专家合作团队以及核心专家,为后续的文献计量提供有效的支撑。 附图说明 图1是本发明基于密度聚类的科研合作团体发现方法的流程示意图。 具体实施方式 一种基于密度聚类的科研合作团体发现方法,包括以下步骤: 步骤1,导入批量论文数据,将批量论文数据作为训练集; 步骤2,对论文数据进行预处理,提取专家合作信息,即同一论文下的专家姓名集; 步骤3,利用专家合作信息构造专家合作关系网络,利用Dijkstra算法计算专家与专家之间的最短路径; 步骤4,利用专家之间的最短路径构建每个专家的专家合作∈领域,其中∈表示领域的半径; 步骤5,利用专家合作∈领域中专家的数量,确定核心专家,构建核心专家集; 步骤6,依据核心专家集获得专家合作网络中所有合作团体簇。 进一步地,步骤3所述的利用专家合作信息构造专家合作关系网络,利用Dijkstra算法计算专家与专家之间的最短路径,具体如下: 步骤3.1、根据论文作者列表信息,以作者作为节点,将共同撰写论文的作者用边连接起来,共同撰写论文数的倒数作为边的权重,构造专家合作信息无向加权图G(V,E),节点i与节点j之间边的权重w
其中,V表示专家合作信息无向加权图的点集、E表示专家合作信息无向加权图的边集、Count表示专家之间合作论文的数量; 步骤3.2、利用Dijkstra算法计算专家合作信息无向加权图G中专家与专家之间的最短路径,具体步骤如下: 步骤3.2.1、输入专家合作信息无向加权图G(V,E),输入目标专家姓名作为源点V 步骤3.2.2、用邻接矩阵arcs表示无向加权图,arcs[m][n]表示边〈v 步骤3.2.3、设置集合S记录已求得最短路径的顶点,令集合S初始值为{v 步骤3.2.4、设置数组dist[]记录从源点v 步骤3.2.5、从顶点集合V-S中选出v 步骤3.2.6、修改从源点v 步骤3.2.7、重复步骤3.2.5~步骤3.2.6至集合V-S为空集; 步骤3.2.8、输出数组dist[],其中专家点v 进一步地,步骤4所述的利用专家之间的最短路径构建每个专家的专家合作∈领域,具体如下: 步骤4.1、输入预设值∈以及由步骤3生成的专家合作关系网络; 步骤4.2、遍历专家集,对每一个专家i,选取所有与专家i距离不大于∈的专家作为该专家的∈领域。 进一步地,步骤5所述的利用专家合作∈领域中专家的数量,确定核心专家,构建核心专家集,具体如下: 步骤5.1、输入预设值MinPts以及由步骤4生成的专家的∈领域; 步骤5.2、计算专家的∈领域中专家的总数,若该值大于预设值MinPts,则该专家视为核心专家,将该专家放入核心专家集; 步骤5.3、重复步骤5.2至所有专家均被遍历,并输出核心专家集。 进一步地,步骤6所述的依据核心专家集获得专家合作网络中所有合作团体簇,具体如下: 步骤6.1、在核心专家集中任意选择一个核心专家,找出其所有密度可达的专家并生成该专家的合作团体簇;密度可达专家定义如下: 对于专家i与专家j,若存在专家序列P 若专家j在专家i的∈领域中,则专家j为专家i的密度直达专家; 步骤6.2、从剩余的核心专家中移除步骤6.1中找到的密度可达的专家; 步骤6.3、从更新后的核心专家集中重复执行步骤6.1~6.2直到所有核心专家都被遍历或移除; 步骤6.4、输出专家的合作团体簇。 下面结合附图和具体实施方式对本发明做进一步的说明。 实施例 结合图1,本发明一种基于密度聚类的科研合作团体发现方法,包括以下步骤: 步骤1,导入批量论文数据; 步骤2,对论文数据进行预处理,提取专家合作信息; 步骤3,利用专家合作信息构造专家合作关系网络,利用Dijkstra算法计算专家与专家之间的最短路径,具体如下: 步骤3.1、根据论文作者列表信息,以作者作为节点,将共同撰写论文的作者用边连接起来,共同撰写论文数的倒数作为边的权重,构造专家合作信息无向加权图G(V,E),节点i与节点j之间边的权重w
其中,V表示专家合作信息无向加权图的点集、E表示专家合作信息无向加权图的边集、Count表示专家之间合作论文的数量。 步骤3.2、利用Dijkstra算法计算合作网络G中专家与专家之间的最短路径,具体步骤如下: 步骤3.2.1、输入专家合作信息无向加权图G(V,E),输入目标专家姓名作为源点v 步骤3.2.2、用邻接矩阵arcs表示无向加权图,arcs[m][n]表示边 步骤3.2.3、设置集合S记录已求得最短路径的顶点,令集合S初始值为{v 步骤3.2.4、设置数组dist[]记录从源点v 步骤3.2.5、从顶点集合V-S中选出v 步骤3.2.6、修改从源点v 步骤3.2.7、重复步骤3.2.5和步骤3.2.6至集合V-S为空集; 步骤3.2.8、输出数组dist[],其中专家v 步骤4,利用专家之间的最短路径构建每个专家的专家合作∈领域,具体如下: 步骤4.1、输入预设值∈以及由步骤3生成的专家合作关系网络; 步骤4.2、遍历专家集,对每一个专家i,选取所有与专家i距离不大于∈的专家作为该专家的∈领域; 步骤5,利用专家合作∈领域中专家的数量,确定核心专家,构建核心专家集,具体如下: 步骤5.1、输入预设值MinPts以及由步骤4生成的专家的∈领域; 步骤5.2、计算专家的∈领域中专家的总数,若该值大于预设值MinPts,则该专家视为核心专家,将该专家放入核心专家集; 步骤5.3、重复步骤5.2至所有专家均被遍历,并输出核心专家集。 步骤6,依据核心专家集获得专家合作网络中所有合作团体簇,具体如下: 步骤6.1、在核心专家集中任意选择一个核心专家,找出其所有密度可达的专家并生成该专家的合作团体簇;密度可达专家定义如下: 对于专家i与专家j,若存在专家序列P 若专家j在专家i的∈领域中,则专家j为专家i的密度直达专家; 步骤6.2、从剩余的核心专家中移除步骤6.1中找到的密度可达的专家; 步骤6.3、从更新后的核心专家集中重复执行6.1-6.2步直到所有核心专家都被遍历或移除; 步骤6.4、输出专家的合作团体簇。 本发明利用密度聚类自适应性好的特点,能够自动的挖掘出科研团队和科研团队的核心,方法简单,效率和准确性高;能够快速的找到给定论文集中的专家合作团队以及核心专家,为后续的文献计量提供有效的支撑。
- 一种基于密度聚类的科研合作团体发现方法
- 一种基于边密度聚类的重叠社区发现方法