一种基于logistic回归的慢性肾病预测方法
文献发布时间:2023-06-19 11:45:49
技术领域
本发明属于计算机应用技术领域,涉及一种基于logistic回归的慢性肾病预测方法。
背景技术
据统计,目前世界上已经高出8.5亿的人口患慢性肾脏病,慢性肾脏疾病者将发展成为慢性肾功能不全、肾衰竭,最终严重可能导致尿毒症。这种病在全世界发病率极高,但是不容易被发现。
Logistic回归分析是常用的处理定性变量的统计方法之一,它是一种根据定量变量或者定性变量来分析、预测因变量的回归分析方法,其在生物、经济等领域用途十分广泛。然而在我们建立模型中,不论是回归问题还是分类问题建模时常会遇到过拟合或者欠拟合现象,一开始我们的模型往往是欠拟合的,当我们不断用算法来优化的时候此时就会出现过拟合。最常见的情况就是随着模型复杂程度的提升,训练集效果越来越好,在测试集上的表现反而越来越差;还有特征太多,数据量太少。如果在训练集上得到的参数值忽高忽低,很可能导致过拟合,这时候就需要用到正则化惩罚,即惩罚数值较大的权重参数,降低它们对结果的影响。
发明内容
发明目的:提出了一种基于logistic回归的慢性肾脏疾病预测方法,该方法可以提取出对因变量有意义的变量,正则化Logistic回归模型能够很好地拟合数据,对预测病人是否患有早期慢性肾脏疾病有较高的准确率。所述包括如下步骤:
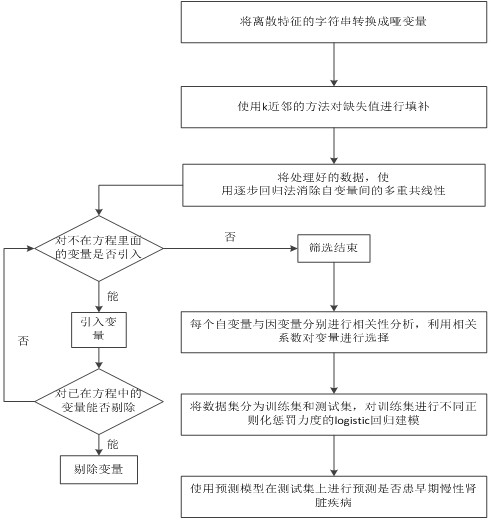
步骤1对早期慢性肾脏疾病数据集的预处理,包括数据集离散变量、连续变量以及缺失数据的处理;
步骤2各个自变量与因变量之间的关系进行相关性分析,从多个生理指标中筛选出与患早期慢性肾脏疾病相关程度较大的变量;
步骤3将数据集分为训练集和测试集,对训练集进行不同正则化惩罚力度的logistic回归建模,得到的分类器在测试集上进行验证是否患早期慢性肾脏疾病。
进一步,上述步骤1中包含下列的步骤:
步骤1.1首先对数据进行整理,将数据集中的离散变量的字符串转换成哑变量;
步骤1.2然后进行缺失值处理,本文k近邻的方法进行填补。k近邻插补法是指利用数据中与缺失值相关的无缺失值,找出距离最近的 k个样本,利用欧式距离函数来衡量这些样本与缺失样本之前的距离。估计值是通过对k个样本对应的缺失项进行距离加权得到的。
进一步,上述步骤2中包含下列的步骤:
步骤2.1对两两变量进行相关性分析,利用相关系数对变量进行选择。此处用的是spearman相关系数;
步骤2.2从相关性分析可以看出自变量
步骤2.3利用相关系数对变量进行选择,与因变量的相关系数绝对值小于0.25的删除。
进一步,上述步骤3中包含下列的步骤:
步骤3.1利用下采样方法使得正负样本平衡,将数据集分成训练集和测试集,对训练集进行五种不同正则化惩罚力度(0.01,0.1,1,10,100)的logistic回归建模,其中的基本过程是首先构建损失函数
式中
步骤3.2预测模型在测试集上进行预测是否患早期慢性肾脏疾病;
步骤3.3最后模型要在整体数据集的测试集进行评估效果。
附图说明
图1.模型流程图;
图2.变量之间相互作用关系的热力图;
图3.因变量与自变量相关性图;
表1.各个数据的异常值检查;
表2.消除多重共线性;
表3.正则化logistic模型召回率。
具体实施方式
一种基于L2正则化logistic回归的早期慢性肾脏疾病预测方法,该方法包括通过使用k近邻法对缺失数据进行填补,利用逐步回归法消除自变量间的多重共线性,根据与因变量相关程度挑选自变量,以及使用正则化Logistic回归模型进行拟合数据,最后实现对病人是否患有早期慢性肾脏疾病的预测。包括下列步骤:
步骤1对早期慢性肾脏疾病数据集的预处理,包括数据集中离散变量、连续变量以及缺失数据的处理;
步骤2各个自变量与因变量之间的关系进行相关性分析,从多个生理指标中筛选出与患早期慢性肾脏疾病相关程度较大的变量;
步骤3将数据集分为训练集和测试集,对训练集进行不同正则化惩罚力度的logistic回归建模,得到的分类器在测试集上进行验证是否患早期慢性肾脏疾病。
所述步骤1中具体包括下列步骤:
步骤1.1首先对数据进行整理,将数据集中的离散变量的字符串转换成哑变量;
步骤1.2然后进行缺失值处理,本文k近邻的方法进行填补。k近邻插补法是指利用数据中与缺失值相关的无缺失值,找出距离最近的 k个样本,利用欧式距离函数来衡量这些样本与缺失样本之前的距离,估计值是通过对k个样本对应的缺失项进行距离加权得到的。
所述步骤2中具体包括下列步骤:
步骤2.1对两两变量进行相关性分析,利用相关系数对变量进行选择,此处用的是spearman相关系数;(其中d代表变量之间的等级差)
步骤2.2从相关性分析可以看出自变量
步骤2.3利用相关系数对变量进行选择,与因变量的相关系数绝对值小于0.25的删除。
所述步骤3中具体包括下列步骤:
步骤3.1利用下采样方法使得正负样本平衡,将数据集分成训练集和测试集,对训练集进行五种不同正则化惩罚力度(0.01,0.1,1,10,100)的logistic回归建模,其中的基本过程是首先构建损失函数
其中
步骤3.2预测模型在测试集上进行预测是否患早期慢性肾脏疾病;
步骤3.3最后模型要在整体数据集的测试集进行评估效果。
一般的logistic回归模型时常容易欠拟合,通过我们不断的优化,经常会遇到过拟合现象。针对过拟合问题,通常会考虑两种方法。第一种是减少特征的数量;第二种是加入正则项。在此我们用到正则化惩罚,即惩罚数值较大的权重参数,降低它们对结果的影响。
下面用一个具体的例子,来简单的说明一下本发明的过程。本实例中的数据集来源于UCI (University of California Irvine),共有400个早期慢性肾脏疾病人的生理指标数据,属于二分类问题,有24项人体的生理指标。具体步骤如下:
如图1所示,一种基于L2正则化logistic回归的早期慢性肾脏疾病预测方法,该方法包括提取出有意义的变量,正则化Logistic回归模型能够很好地拟合数据,对预测病人是否患有早期慢性肾脏疾病有较高的准确率。包括下列步骤:
(1)首先数据预处理,将字符串都转换为哑变量。缺失数据处理的方法有很多种,参考前人的研究本文用k近邻法。查看数据是否还存在缺失,同时查看异常值,如表1所示;
(2)从表1中不难看出,有些变量的标准差非常的大,但是logistic模型无需对数据进行标准化。对处理好的数据进行相关性分析,自变量与因变量的相关程度使用spearman相关系数的值来衡量。变量之间相关性热力图如图2所示;
(3)从图2可以看出,自变量
(4)利用因变量与自变量间的相关系数对自变量进行选择,相关系数绝对值小于0.25的删除。如图3,因此删除x1, x9, x14, x21;
(5)在上述的数据基础上,利用下采样方法使得正负样本平衡,然后将数据分为训练集和测试集,对训练集上进行L2正则化logistic回归建模;
(6)预测模型在全部测试集上进行预测是否患早期慢性肾脏疾病,此处用召回率来展示我们所建模型的好坏,本文L2正则化logistic回归模型五折交叉(结果如下表3) 在惩罚力度为1的时候模型最佳,召回率为93%,在相同的数据条件下logistic模型下召回率为81.25%。由此可见我们的模型是具有参考价值的。
表1.各个数据的异常值检查
表2.消除多重共线性
表3.正则化logistic模型召回率
- 一种基于logistic回归的慢性肾病预测方法
- 一种基于Logistic回归算法的劳资纠纷预测方法