文本识别方法、装置及计算机存储介质
文献发布时间:2023-06-19 11:49:09
技术领域
本申请实施例涉及文本识别技术领域,特别涉及一种文本识别方法、装置及计算机存储介质。
背景技术
关系三元组的抽取处理过程主要包括,输入一段文本,通过规则或者模型的方法抽取句子中包含的实体以及关系,以此来构成一个关系三元组(s,p,o),其中s(subject)表示主实体,o(object)表示客实体,p(predicate)表示两实体间的关系特征。
比如,针对“姚明,1980年9月12日出生于上海市徐汇区”的文本,其中可包含有关系三元组(姚明,出生地,上海市徐汇区)。提取文本中的三元组是建立知识图谱重要的一个步骤,在大数据时代的今天,从大量非结构化的数据当中自动提取关系三元组建立结构化数据的知识图谱是非常有价值的,可以应用于信息抽取、搜索、问答系统和推荐系统等多个领域。
目前主流的关系三元组提取处理方法大都是通过模型的方式进行抽取,比较有代表性的两个方向是管道方式(pipeline)和联合方式(end-to-end)。
其中,管道方式主要是先进行文本的实体抽取,是一个序列化标注问题,然后将抽取的实体进行两两组合以构建关系矩阵或者进行关系识别,然而,这种方式在第二阶段会产生大量无意义的实体对,由于误差的累计,导致了关系三元组整体抽取的准确率有限。
再者,联合方式则是通常将实体抽取和关系识别放在同一个任务当中,其中共享embedding主干网络,然而,这种方式由于将两个任务结合在一起,导致模型的训练难度较大,同时对于一个包含多个相同关系的文本,三元组抽取准确率往往不及管道方式。
发明内容
鉴于上述问题,本申请提供一种本文识别方法、装置及计算机存储介质,可提高文本识别结果的准确率,并提高文本识别的处理效率。
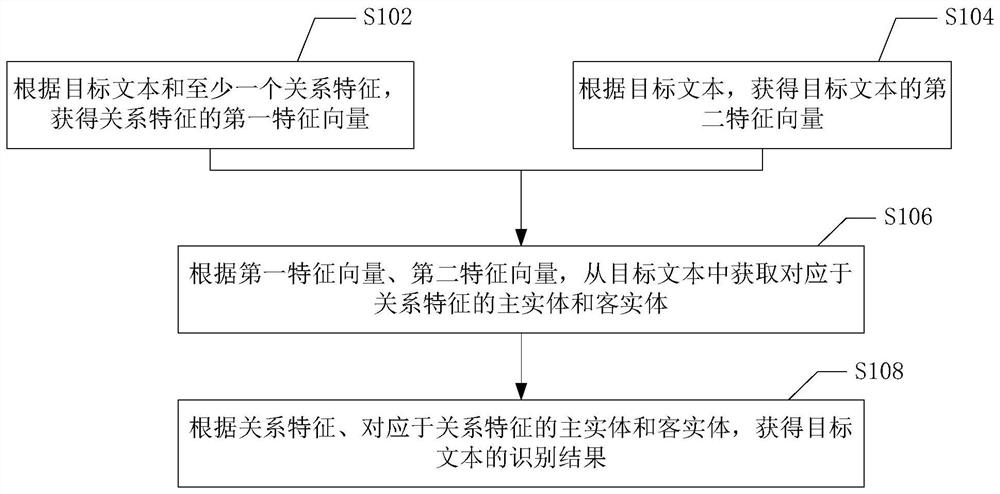
本申请第一方面提供一种文本识别方法,其包括:根据目标文本和至少一个关系特征,获得所述关系特征的第一特征向量;根据所述目标文本,获得所述目标文本的第二特征向量;根据所述第一特征向量、所述第二特征向量,从所述目标文本中获取对应于所述关系特征的主实体和客实体;以及根据所述关系特征、对应于所述关系特征的所述主实体和所述客实体,获得所述目标文本的识别结果。
本申请第二方面提供一种计算机存储介质,所述计算机存储介质中储存有用于执行上述第一方面所述的文本识别方法的各所述步骤的指令。
本申请第三方面提供一种文本识别装置,其包括:特征获取模块,用于根据目标文本和至少一个关系特征,获得所述关系特征的第一特征向量,并根据所述目标文本,获得所述目标文本的第二特征向量;以及文本识别模块,用于根据所述第一特征向量、所述第二特征向量,从所述目标文本中获取对应于所述关系特征的主实体和客实体,并根据所述关系特征、对应于所述关系特征的所述主实体和所述客实体,获得所述目标文本的识别结果。
综上所述,本申请实施例提出了一种从关系识别到实体抽取的关系三元组管道抽取方法,不仅可识别出目标文本中所包含的多种关系,且通过将关系特征对应的编码特征向量与目标文本对应的编码特征进行融合,可以提高关系对应实体的抽取准确率。
再者,本申请实施例提供的文本识别技术不仅可减少现有管道抽取方式中需处理大量无意义实体对的问题,以适用于当目标文本中包含有多个关系特征的情况下的关系三元组的抽取处理,可以提高文本识别处理效率。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请实施例中记载的一些实施例,对于本领域普通技术人员来讲,还可以根据这些附图获得其他的附图。
图1为本申请第一实施例的文本识别方法的流程示意图。
图2为图1所示的文本识别方法的处理流程实施例图。
图3为本申请第二实施例的文本识别方法的流程示意图。
图4为本申请第三实施例的文本识别方法的流程示意图。
图5为本申请第四实施例的文本识别方法的流程示意图。
图6为本申请第六实施例的文本识别装置的架构示意图。
元件标号
600:文本识别装置;602:特征获取模块;604:文本识别模块。
具体实施方式
为了使本领域的人员更好地理解本申请实施例中的技术方案,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本申请实施例一部分实施例,而不是全部的实施例。基于本申请实施例中的实施例,本领域普通技术人员所获得的所有其他实施例,都应当属于本申请实施例保护的范围。
呈上所述,目前的关系三元组抽取方式主要存在识别准确性不高且处理效率低下的问题,有鉴于此,本申请提供一种文本识别方法、装置及计算机存储介质,可以改善上述现有技术存在的种种技术问题,以下将结合各附图详细描述本申请的各实施例。
第一实施例
图1示出了本申请第一实施例的文本识别方法的流程示意图。如图所示,本实施例的文本识别方法主要包括以下步骤:
步骤S102,根据目标文本和至少一个关系特征,获得关系特征的第一特征向量。
可选地,本实施例的方法还可包括根据预设文本长度将目标语料切分为满足预设文本长度的至少一个目标文本。
例如,可根据语言识别模型所支持的预设文本长度,将一个长文本在保证句子完整的条件下进行拆分,获得满足预设文本长度的一个或多个目标文本。
可选地,本实施例的方法还可包括基于预设文本处理规则,针对目标语料执行预处理。
于本实施例中,预设文本处理规则至少包括针对目标文本执行数据去噪处理,例如,去除或替换目标文本中的未知编码字符。
请配合参考图2,于本实施例中,可通过语言识别模型(例如BERT模型)针对拆分后的各目标文本进行文本的嵌入,以获得目标文本的编码特征向量(嵌入特征)。
具体地,若将目标文本表示为s
而后,再将目标文本的编码特征向量输入到Dense+Sigmoid模块中,得到语义信息更强的特征表示,借以识别目标文本中可能包含的多种关系特征,进而获得关系特征的第一特征向量。
于本实施例中,针对一个目标文本,可以指定至少一个关系特征。
例如,针对“姚明,1980年9月12日出生于上海市徐汇区”的目标文本,其关系特征可包括“出生日期”、“出生地”等。
步骤S104,根据目标文本,获得目标文本的第二特征向量。
可选地,可针对目标文本执行编码,获得目标文本中各字符对应的各编码特征,再根据各字符对应的各编码特征,获得目标文本的第二特征向量。
请参考图2,于本实施例中,可利用BERT模型获得目标文本的第二特征向量
于本实施例中,目标文本的第二特征向量的获取原理与上述目标文本的编码特征向量的获取原理的基本相同,故不再不予赘述。
于本实施例中,步骤S102和步骤S104的执行顺序不分先后,可根据实际需求进行任意调整(例如同时执行或先后执行),本申请对此不作限制。
步骤S106,根据第一特征向量、第二特征向量,从目标文本中获取对应于关系特征的主实体和客实体。
于本实施例中,可通过融合第一特征向量、第二特征向量,并根据融合结果从目标文本中获取对应于各关系特征的各主实体和各客实体。
例如,针对“姚明,1980年9月12日出生于上海市徐汇区”的目标文本,关于“出生日期”的关系特征,其对应的主实体可为“姚明”,客实体可为“1980年9月12日”,关于“出生地”的关系特征,其对应的主实体可为“姚明”,客实体可为“上海市徐汇区”。
步骤S108,根据关系特征、对应于关系特征的主实体和客实体,获得目标文本的识别结果。
可选地,可根据关系特征、对应于关系特征的主实体和客实体,生成包含关系特征、主实体、客实体的关系三元组。
于本实施例中,关系三元组可表示为(P,S,O),其中,s(subject)表示主实体,o(object)表示客实体,p(predicate)表示关系特征(参考图2)。
例如,针对“姚明,1980年9月12日出生于上海市徐汇区”的目标文本,关于“出生日期”的关系特征,可获取(“姚明”“出生日期”“1980年9月12日”)的关系三元组。
综上所述,本申请实施例根据目标文本和至少一个关系特征,获得关系特征的第一特征向量以及目标文本的第二特征向量,再通过融合第一特征向量和第二特征向量,以从目标文本中获取对应于关系特征的主实体和客实体,并基于关系特征及其对应的主实体、客实体,获得目标文本的各关系特征的识别结果。借此,本申请可识别出目标文本中包含的多种关系特征,并可提高目标文本的识别结果的准确性。
第二实施例
图3示出了本申请第二实施例的文本识别方法的流程示意图。如图所示,本实施例的文本识别方法为上述步骤S102的具体实施方案,其主要包括以下处理步骤:
步骤S302,根据目标文本,获得目标文本的编码特征向量。
可选地,可针对目标文本执行编码,获得目标文本中各字符对应的各编码特征,再根据各字符对应的各编码特征,获得目标文本的编码特征向量。
可选地,可利用BERT模型针对目标文本执行编码,获得目标文本中各字符对应的各编码特征。
于本实施例中,各字符对应的各编码特征为具有预设维度的各特征子向量。
于本实施例中,编码特征的预设维度可为128的任意指数的幂值,即128的一次方、二次方、三次方等等。
较佳地,所述预设维度可介于128至1024之间
可选地,可根据各编码特征的预设维度和目标文本包含的字符数,获得目标文本的特征矩阵。
例如,假设编码特征的预设维度为d,目标文本包含的字符数为n,则可使用n*d的特征矩阵来表示目标文本。
步骤S304,根据编码特征向量、关系特征,获得目标文本包含或不包含关系特征的关系识别结果。
可选地,可根据关系特征、目标文本的特征矩阵(即n*d),获得目标文本的第一参数矩阵,再根据第一概率换算规则、第一参数矩阵、编码特征向量,获得目标文本包含或不包含关系特征的关系识别结果(P)。
可选地,可利用Sigmoid函数得到上述关系识别结果,亦即,目标文本可能包含的各种关系特征的概率。
于本实施例中,第一概率换算规则可表示为:
P=sigmoid(W
其中,P表示目标文本包含或不包含关系特征的关系识别结果,W
于本实施例中,各参数的下标t用于标识token。
可选地,可根据关系识别结果(P)与第一预设概率阈值,若关系识别结果(P)大于第一预设概率阈值,表示目标文本包含关系特征,反之,若关系识别结果(P)不大于第一预设概率阈值,则表示目标文本不包含关系特征。
于本实施例中,第一预设概率阈值可介于0.5至0.8之间。
优选地,可将第一预设概率阈值设置为0.6。
请参考图2,于本实施例中,针对输入的目标文本设置有n个关系特征,其中,关系特征1和关系特征i的关系识别结果(P)分别为0.98和0.91,均超过了第一预设概率阈值,则可得出当前识别的目标文本中包含有关系特征1和关系特征i。
步骤S306,根据关系识别结果,针对目标文本包含的关系特征执行编码,获得关系特征的第一特征向量。
于本实施例中,可根据关系识别结果,提取目标文本包含的关系特征,例如,图3中的关系特征1和关系特征i,再针对提取的各关系特征进行重新编码,以获得各关系特征对应的各第一特征向量(c
可选地,可整合各关系特征对应的各第一特征向量(c
第三实施例
图4示出了本申请第三实施例的文本识别方法的流程示意图,本实施例的文本识别方法主要示出了上述步骤S306的具体实施方案,其主要包括以下处理步骤:
步骤S402,根据关系识别结果,提取目标文本包含的关系特征。
例如,于图2所示实施例中,可以看出当前待识别的目标文本包含有关系特征1和关系特征i,则提取这两个关系特征。
步骤S404,针对提取的关系特征执行编码,获得关系特征中各关系字符对应的各字符向量。
可选地,可使用任意一种word2vec文本嵌入方式获得各关系特征对应的嵌入(embedding),并将其表示为T
步骤S406,根据预设均值换算规则针对各字符向量执行均值计算,获得关系特征的第一特征向量。
于本实施例中,预设均值换算规则可表示为:
其中,c
第四实施例
图5示出了本申请第四实施例的文本识别方法的流程示意图。本实施例的文本识别方法主要示出了上述步骤S106的具体实施方案,如图所示,本实施例的文本识别方法主要包括以下步骤:
步骤S502,根据第一特征向量,获得关系特征的待融合特征向量。
可选地,可根据目标文本、关系特征,获得目标文本的第二参数矩阵,再根据预设向量转换规则、第一特征向量、第二参数矩阵,获得关系特征的待融合特征向量。
于本实施例中,预设向量转换规则表示为:
e
其中,e
于本实施例中,第二参数矩阵(w
可选地,可利用前馈神经网络FF模块,以根据关系特征的第一特征向量(c
步骤S504,融合待融合特征向量和第二特征向量,获得融合特征向量。
可选地,可针对待融合特征向量和第二特征向量执行concate融合处理,以获得融合特征向量。
具体地,可将步骤S502所获得的关系特征的待融合特征向量(e
步骤S506,根据融合特征向量,获得目标文本中的各字符为实体字符或非实体字符的各字符识别结果。
请配合参考图2,于本实施例中,可将步骤S504所获得的融合特征向量(Token′)输入Dense+Softmax模块中,以针对每个编码特征(token编码)进行判断并实现实体抽取。
于本实施例中,可利用Softmax函数得到目标文本中的每个字符是否是实体部分的字符识别结果(P′)。
可选地,可首先根据目标文本、关系特征,获得目标文本的第三参数矩阵,再根据第二概率换算规则、融合特征向量、第三参数矩阵,获得目标文本中的各字符对应的各字符识别结果(P′)。
于本实施例中,第二概率换算规则表示为:
P′=softmax(W
其中,P′表示目标文本中的各字符对应的各字符识别结果,W
于本实施例中,第三参数矩阵(W
于本实施例中,可根据字符识别结果(P′)与第二预设概率阈值,若字符识别结果(P′)大于第二预设概率阈值,表示字符为实体字符,反之,若字符识别结果(P′)不大于第二预设概率阈值,表示字符为非实体字符。
于本实施例中,第二预设概率阈值可介于0.5至0.8之间。
步骤S508,根据各字符的各字符识别结果,第一特征向量,从目标文本中获取对应于关系特征的主实体和客实体。
可选地,可根据各字符的各字符识别结果(P′),从目标文本中提取各实体字符,并根据第一特征向量对应的关系特征,从各实体字符中获取对应于关系特征的至少一个主实体(S)和至少一个客实体(O)。
具体地,可根据字符识别结果(P′),从目标文本中提取属于实体的各个字符(参考图2中的S-B,S-I,O-B,O-I),并去除属于非实体的各个字符,亦即,无效字符(参考图2中以空心圈方式所标识的字符识别结果)。
于本实施例中,可根据第一特征向量(即图2中的c
再者,于图2所示的实施例中,S-B代表主实体的起始字符,S-I代表主实体的中间字符,O-B代表客实体的起始字符,O-I代表客实体的中间字符,其中,主实体/客实体的起始字符为一个,而主实体/客实体的中间字符可为零个、一个或多个,视依主实体/客实体所包含的字符数量而定,例如,假设主实体为“姚明”,则其对应的主实体起始字符(S-B)为“姚”以及其对应的主实体中间字符为“明”。再如,假设客实体为“上海市徐汇区”,则其对应的客实体起始字符(O-B)为“上”,而“海”、“市”、“徐”、“汇”、“区”则均为客实体中间字符(O-I)。
以下将以列举方式详细说明本申请“关系三元组”的抽取原理:
例如,假设目标文本为“姚明,1980年9月12日出生于上海市徐汇区”,其所包含的关系特征包括有“出生日期”和“出生地”。
其中,针对关系特征(P)“出生日期”,所提取的主实体(S)为“姚明”,客实体(O)为“1980年9月12日”,据此,可以获得(“姚明”“出生日期”“1980年9月12日”)的关系三元组。
再者,针对关系特征(P)“出生地”,所提取的主实体(S)为“姚明”,客实体(O)为“上海市徐汇区”,据此,可以获得(“姚明”“出生地”“上海市徐汇区”)的关系三元组。
又如,假设目标文本为“战狼的主演包括吴京、卢靖姗、吴刚等”,其所包含的关系特征包括有“主演”,则针对关系特征(P)“主演”,所提取的主实体(S)可包括“战狼”,而客实体(O)则包括有三个,即“吴京”、“卢靖姗”、“吴刚”,则针对关系特征“主演”,可以获得三个关系三元组,亦即(“战狼”“主演”“吴京”)、(“战狼”“主演”“卢靖姗”)、(“战狼”“主演”“吴刚”)。
综上所述,本申请第二实施例至第四实施例所提供文本识别方法,通过引入Sigmoid函数,可以识别目标文本中包含的多种关系特征。此外,通过将目标文本中所包含的关系特征进行编码,并与目标文本中各字符编码进行融合,可将关系类型嵌入到实体抽取模型,从而提高关系特征对应实体(主实体和客实体)的抽取准确率,从而提高文本识别结果的准确性。
再者,本申请所提供基于管道抽取方式所实现的文本识别技术,可以有效减少现有管道抽取方式中需处理大量无意义的实体对的问题,且针对目标文本中存在有多个相同关系的情况,亦可生成与之数量相对应的多组三元关系组,从而进一步提高文本识别结果的准确性。
第五实施例
本申请第五实施例提供一种计算机存储介质,所述计算机存储介质中存储有用于执行上述第一实施例至第四实施例中任意实施例所述的文本识别方法的各所述步骤的指令。
第六实施例
图6示出了本申请第六实施例的本文识别装置的架构示意图。如图所示,本实施例的文本识别装置600主要包括:特征获取模块602和文本识别模块604。
特征获取模块602用于根据目标文本和至少一个关系特征,获得所述关系特征的第一特征向量,并根据所述目标文本,获得所述目标文本的第二特征向量。
可选地,特征获取模块602还用于根据预设文本长度将目标语料切分为满足所述预设文本长度的至少一个所述目标文本。
可选地,特征获取模块602还用于基于预设文本处理规则,针对所述目标语料执行预处理;其中,所述预设文本处理规则至少包括数据去噪处理。
可选地,特征获取模块602还用于根据所述目标文本,获得所述目标文本的编码特征向量;根据所述编码特征向量、所述关系特征,获得所述目标文本包含或不包含所述关系特征的关系识别结果;根据所述关系识别结果,针对所述目标文本包含的所述关系特征执行编码,获得所述关系特征的第一特征向量。
可选地,特征获取模块602还用于针对所述目标文本执行编码,获得所述目标文本中各字符对应的各编码特征;以及根据各所述字符对应的各所述编码特征,获得所述目标文本的所述编码特征向量。
可选地,特征获取模块602还用于利用BERT模型针对所述目标文本执行编码,获得所述目标文本中各字符对应的各编码特征。
可选地,特征获取模块602还用于根据各所述编码特征的所述预设维度和所述目标文本包含的字符数,获得所述目标文本的特征矩阵;其中,所述预设维度为128的任意指数的幂值,较佳地,所述预设维度介于128至1024之间。
可选地,特征获取模块602还用于根据所述关系特征、所述目标文本的所述特征矩阵,获得所述目标文本的第一参数矩阵;根据第一概率换算规则、所述第一参数矩阵、所述编码特征向量,获得所述目标文本包含或不包含所述关系特征的所述关系识别结果;所述第一概率换算规则表示为:
P=sigmoid(W
其中,所述P表示所述关系识别结果,所述W
可选地,特征获取模块602还用于根据所述关系识别结果与第一预设概率阈值,若所述关系识别结果大于所述第一预设概率阈值,表示所述目标文本包含所述关系特征;其中,所述第一预设概率阈值可介于0.5至0.8之间,优选地,所述第一预设概率阈值为0.6。
可选地,特征获取模块602还用于根据所述关系识别结果,提取所述目标文本包含的所述关系特征;针对提取的所述关系特征执行编码,获得所述关系特征中各关系字符对应的各字符向量;根据预设均值换算规则针对各所述字符向量执行均值计算,获得所述关系特征的所述第一特征向量;所述预设均值换算规则表示为:
其中,所述c
可选地,特征获取模块602还用于针对所述目标文本执行编码,获得所述目标文本中各字符对应的各编码特征;以及根据各所述字符对应的各所述编码特征,获得所述目标文本的所述第二特征向量。
可选地,特征获取模块602还用于利用BERT模型针对所述目标文本执行编码,获得所述目标文本中各字符对应的各编码特征。
文本识别模块604用于根据所述第一特征向量、所述第二特征向量,从所述目标文本中获取对应于所述关系特征的主实体和客实体,并根据所述关系特征、对应于所述关系特征的所述主实体和所述客实体,获得所述目标文本的识别结果。
可选地,文本识别模块604还用于根据所述第一特征向量,获得所述关系特征的待融合特征向量;融合所述待融合特征向量和所述第二特征向量,获得融合特征向量;根据所述融合特征向量,获得所述目标文本中的各字符为实体字符或非实体字符的各字符识别结果;以及根据各所述字符的各所述字符识别结果,所述第一特征向量,从所述目标文本中获取对应于所述关系特征的所述主实体和所述客实体。
可选地,文本识别模块604还用于根据所述目标文本、所述关系特征,获得所述目标文本的第二参数矩阵;根据预设向量转换规则、所述第一特征向量、所述第二参数矩阵,获得所述关系特征的所述待融合特征向量;所述预设向量转换规则表示为:
e
其中,所述e
可选地,文本识别模块604还用于针对所述待融合特征向量和所述第二特征向量执行concate融合处理,获得所述融合特征向量。
可选地,文本识别模块604还用于根据所述目标文本、所述关系特征,获得所述目标文本的第三参数矩阵;根据第二概率换算规则、所述融合特征向量、所述第三参数矩阵,获得所述目标文本中的各所述字符对应的各所述字符识别结果;所述第二概率换算规则表示为:
P′=softmax(W
其中,所述P表示所述字符识别结果,所述W′
可选地,文本识别模块604还用于根据所述字符识别结果与第二预设概率阈值,若所述字符识别结果大于所述第二预设概率阈值,表示所述字符为实体字符;其中,所述第二预设概率阈值可介于0.5至0.8之间。
可选地,文本识别模块604还用于根据各所述字符的各所述字符识别结果,从所述目标文本中提取各所述实体字符;以及根据所述第一特征向量对应的所述关系特征,从各所述实体字符中获取对应于所述关系特征的至少一个所述主实体和至少一个所述客实体。
可选地,文本识别模块604还用于根据所述关系特征、对应于所述关系特征的所述主实体和所述客实体,生成包含所述关系特征、所述主实体、所述客实体的关系三元组。
综上所述,本申请实施例提供的文本识别方法、装置及计算机存储介质,通过引入Sigmoid函数,可以识别目标文本中包含的多种关系特征。
再者,通过针对关系特征进行编码,并与目标文本中对应的每个字符的编码进行融合,以将关系特征嵌入到实体抽取模型中,可以提高关系特征对应实体的抽取准确性,从而提高文本识别结果的准确性。
此外,本申请可有效减少现有管道抽取方式中需处理大量无意义实体对的问题,以提高文本识别处理效率,亦可适用于在目标文本中存在多个相同关系的情况下的关系三元组的抽取处理。
最后应说明的是:以上实施例仅用以说明本申请实施例的技术方案,而非对其限制;尽管参照前述实施例对本申请进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本申请各实施例技术方案的精神和范围。
- 图像文本识别方法、装置、计算机设备及计算机存储介质
- 图像中文本的识别方法、装置、计算机设备及计算机存储介质