一种基于结构化数据的预测系统
文献发布时间:2023-06-19 11:57:35
技术领域
本发明涉及一种预测系统,特别涉及一种基于结构化数据的预测系统,属 于人工智能学习预测技术领域。
背景技术
迄今为止,大多数企业都依赖结构化数据进行数据存储和预测分析。关系 数据库管理系统(RDBMS)已经成为业界采用的主流数据库系统,关系数据库已 经成为实际上存储和查询结构化数据的标准,而结构化数据对大多数业务的操 作都是至关重要的。结构化数据中往往包含着大量的信息,这些信息往往可以 用于进行数据驱动的决策或是识别风险和机会。从数据中提取见解用于决策需 要高级分析,尤其是深度学习,它比统计聚合要复杂得多。
形式上,结构化数据指的是可以用表格来表示的数据类型。可以看作是一 个由n行(元组/样本)m列(属性/特征)组成的逻辑表,它是通过选择、投影和连接 等核心关系操作从关系数据库中提取出来的。预测建模是学习依赖属性y对决 定属性x的函数依赖性(预测函数),即,f∶x→y。其中x通常称为特征向量, y为预测目标。针对结构化数据进行预测的主要挑战实际上是如何通过交叉特 征来建模这些属性之间的依赖关系和相关性,即所谓的特征相互作用。这些交 叉特征通过捕获原始输入特征的相互作用来创建新特征。具体来说,一个交叉 特征可以定义为
现有对数据进行关系建模并用于目标预测的方法主要分为2类:隐式建模 和显式建模。典型的隐式建模方法是深度神经网络(DNNs),如CNNs、LSTM等。 但DNNs只适用于一些特定数据类型,例如,CNNs在图像领域的应用,以及 LSTM在序列数据上的应用。然而,把DNNs应用到关系表中的结构化数据时, 可能不会产生有意义的结果。具体来说,结构化数据的属性值之间存在内在的 相关性和依赖性,而这种特性之间的相互作用关系对于预测分析是必不可少的。 虽然理论上,只要有足够的数据和容量,DNN可以近似任何目标函数,但传统 DNN网络层善于捕获的相互作用是可加性的,因此,要为这样相乘的相互作用 建模,就需要过分庞大并且越来越难以理解的模型,这些模型往往由多层叠加 而成,层之间还有非线性的激活函数。先前的研究也提出,用DNNs隐式建模 这样的交叉特征可能需要大量的隐藏单元,这大大增加了计算成本,并且也使 DNNs更加难以解释;如文献AlexandrAndoni,Rina Panigrahy,Gregory Valiant,and Li Zhang.2014. Learning Polynomialswith Neural Networks.In Proceedings of the 31th International Conference onMachine Learning,ICML.所述。
在关系分析中,DNNs的首选替代方案是明确地对特征交互进行建模,从而 在特征归因方面获得更好的性能和可解释性。然而,可能的特征交互的数量在 组合上是很大的。因此,显式交叉特征建模的核心问题是如何识别正确的特征 集,同时确定相应的交互权值。大多数现有的研究通过捕获交互阶数限制在预 定义的个数范围内的交叉特征来回避这一问题。然而,随着最大阶数的增加, 交叉特征的数量仍然接近指数增长。AFN(WeiyuCheng,Yanyan Shen,and Linpeng Huang. 2020.Adaptive Factorization Network:Learning Adaptive-Order Feature Interactions.In 34th AAAI Conference onArtificial Intelligence.)则更进一步,它利用对数神经元对交叉特征进行建模(J.Wesley Hines.1996.A logarithmic neural network architecture for unboundednon-linear function approximation.In Proceedings of Intemational Conferenceon Neural Networks(ICNN’96).IEEE,1245-1250.),每个神经元 将特征转化为对数空间,从而将多个特征的幂转化为可学习的系数,具体来说, 即
我们认为交叉特征应该只考虑某些输入特征,并且,特征相互作用应该动 态地对单个输入建模。其基本原理是,并非所有的输入特征对交叉项都是建设 性的,使用不相关的特征进行建模可能会引入噪声,从而降低有效性和可解释 性。特别是,在实际应用中学习模型的部署不仅强调了准确性,同时还强调了 效率和可解释性。值得注意的是,理解学习模型的一般行为和整个逻辑(全局可 解释性),并为所做出的特定决策提供理由(局部可解释性)对于高风险应用中的 关键决策制定至关重要,如医疗保健或金融行业。尽管许多黑盒模型(如DNNs) 具有强大的预测能力,但它们以隐式的方式对输入进行建模,这种方式令人费 解,有时还可能学习到一些令人意想不到的模式。就此而言,明确地用最小组 成特征集自适应地建模特征关系,会在有效性、效率和可解释性方面提供合理 的先验知识。
发明内容
本发明的目的在于针对现有技术的上述部分或全部不足,提供一种基于结 构化数据的预测系统,包括预处理模块和预测模块;预处理模块将所述结构化 数据元组x的每个属性值转换为嵌入向量表示后输出给预测模块,预测模块使用 多个指数神经元基于所述嵌入向量建模所述x的交叉特征,然后将所有所述交叉 特征聚合构建所述x的特征向量,最后基于所述特征向量进行分类预测。
作为优选,所述将属性值转换为嵌入向量表示的过程如下:当所述属性值 为数值型时,先根据该属性值域范围缩放到(0,1]区间内,再与预学习的嵌入向 量相乘;当所述属性值为分类型时,直接根据其值索引对应预学习的嵌入向量。
作为优选,所述建模所述x的特征相互作用时,阶数非固定。
作为优选,所述指数神经元的个数为K×o个,其中,K表示注意头的个数, o表示每个注意头的所述指数神经元的数目,K和o都是自然数;每个注意头的所 有所述指数神经元共享其双线性注意函数的权重矩阵W
每个注意头的第i个所述指数神经元y
其中,i,⊙表示哈达玛积,exp(·)函数和相应的指数w
w
其中,
其中,
作为优选,所述聚合为向量拼接。
作为优选,基于所述特征向量进行分类预测前先通过多层感知器MLP捕获 元素的非线性特征交互,并获得编码关系的向量表示h:
其中,n
然后基于所述h进行分类预测。
作为优选,所述分类预测通过下式进行:
其中,
作为优选,将所述预测系统与DNN结合进行目标预测。
作为优选,所述系统还包括存储模块,对所述结构化数据提供底层存储支 持,为所述预测模块的训练提供基于DBMS的逻辑表的抽象功能,以及在模型部 署后,为具体应用的学习任务提供运行时数据收集、整理、转发至预测模块的 功能;所述收集包括训练后的指数神经元参数配置、权重,以及当前预测实例 及其权重,所述整理包括统计全局高频交互项、全局属性重要性排名、局部属 性重要性排名。
作为优选,所述系统还包括功能模块,功能模块有预测单元、全局解释单 元和局部解释单元组成,预测单元提供输入数据的预测结果输出,全局解释单 元对所述具体应用的学习任务的整体逻辑,提供解释性支持,输出每一个属性 的标量值,指示其全局重要性,以及所述全局高频交互项;局部解释单元针对 单个待预测的样本,提供逐样本的局部性解释支持,输出对应于所述样本的每 一个属性的标量值,指示其局部重要性,以及对应于所述样本的交互项。
作为优选,所述系统还包括应用模块,提供对结构化数据应用的端到端的 支持,对系统其它模块的接口提供调度和封装。
另一方面,本发明还提供了一种电子设备,所述电子设备包括:
至少一个处理器;以及,
与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被 所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使 所述至少一个处理器能够执行前述的一种基于结构化数据的预测系统。
另一方面,本发明还提供了一种非暂态计算机可读存储介质,该非暂态计 算机可读存储介质存储计算机指令,该计算机指令用于使该计算机执行前述的 一种基于结构化数据的预测系统。
另一方面,本发明还提供了一种计算机程序产品,包括存储在非暂态计算 机可读存储介质上的计算程序,该计算机程序包括程序指令,当该程序指令被 计算机执行时,使该计算机执行前述的一种基于结构化数据的预测系统。
有益效果
与现有技术相比,本发明提出的一种基于结构化数据的预测系统,具有如 下特点:
1、通过指数神经元建模交叉特征,克服了对数神经元输入必须为正的限制, 提高了神经元适用场景;
2、提出的指数神经元能够建模任意阶的交叉特征,提升了交叉特征建模的 有效性;
3、通过指数神经元以及多头门控注意力机制能够根据输入数据动态并有 选择性地建模任意阶的交叉特征,提升特征建模的准确性和效率;
4、交叉特征建模方法遵循白盒设计,建模过程更加透明,因而在关系分析 处理中更具解释性;
5、通过注意重校准权重的门控机制能够动态捕捉对应于输入样本的交互 项,提供模型决策的可解释性,从而得到人们的信任并提供新的见解,促进人 们对某些领域的理解。
6、通过对所有指数神经元的全局权重vi加和平均并排序,可使人们加深对 于决策的影响因素及其重要程度的理解。
7、通过对所有指数神经元的动态特征交互权重wi加和平均并排序,可使人 们加深对于当前输入决策的影响因素及其重要程度的理解。
附图说明
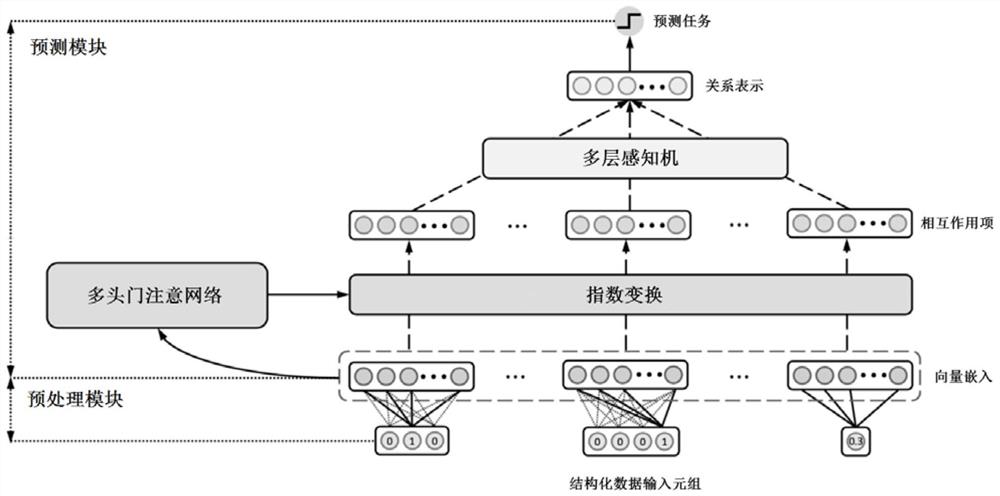
图1为本发明实施例一所述系统的优选实施方式结构组成示意图;
图2为本发明实施例一所述系统的结构组成示意图;
图3为Lime、Shape和本发明分别针对数据集Frappe和Diabetes130的全局 特征归因;
图4为Frappe数据集上的一个代表性输入实例的ARM-Net(左)的局部特 征归因以及由Lime(右上)和Shap(右下)给出的局部特征重要性权重;
图5为Diabetes130数据集上的一个代表性输入实例的ARM-Net(左)的局 部特征归因以及由Lime(右上)和Shap(右下)给出的局部特征重要性权重。
具体实施方式
下面结合附图,具体说明本发明的优选实施方式。
为了后续描述的方便,将结构化数据表示为一个逻辑表T,其中包含n行 和m列,具体来说,每一行可以表示为一个元组(x,y)=(x
实施例一实现了本发明所述的一种基于结构化数据的预测系统,如图2所 示,包括预处理模块和预测模块;预处理模块将所述x的每个属性值转换为嵌入 向量表示后输出给预测模块,预测模块使用多个指数神经元基于所述嵌入向量 建模所述x的交叉特征,然后将所有所述交叉特征聚合构建所述x的特征向量, 最后基于所述特征向量进行分类预测。
预处理模块可以采用任何现有方法将当前元组的每个属性值转换为嵌入向 量,如FM方法,双向嵌入方法等。
较优的,可以对结构化数据的数值型属性和分类型属性分别处理:对于数 值型属性,先根据该属性值域范围缩放到(0,1]区间内,再与预学习的嵌入向量 相乘;对于分类型属性,直接根据其值索引对应预学习的嵌入向量。该种嵌入 方式可以将向量嵌入过程纳入本发明方法的整体学习过程,使得嵌入向量表达 更具针对性,因不同预测场景的不同而不同。举例来说,当一个公司想要对月 销售额进行预测时,提供的x包含属性域 (month、regionID、storeID、productID),则m=4,4个属性分别为月份、 地区ID、商店ID和产品ID,此处四个属性均是分类型属性,可以通过训练得到 所有对应分类的嵌入向量,如1-12月的嵌入向量,执行预测任务时,如果month=3, 则直接使用对应于3月份的嵌入向量即可。
预测模块使用的指数神经元不同于对数神经元,不要求输入必须为正,从 而降低了对输入数据的要求,一个指数神经元建模一个特征相互作用,即交叉 特征。
进一步的,建模时不限定相互作用阶数,而是根据当前数据自适应确定阶 数,可以提高所获取的特征相互作用的准确性和效率。
进一步的,设置指数神经元的个数为K×o个,其中,K表示注意头的个数, o表示每个注意头的所述指数神经元的数目,K和o都是自然数;每个注意头的所 有所述指数神经元共享其双线性注意函数φ
每个注意头的第i个所述指数神经元y
其中,i,⊙表示哈达玛积,exp(·)函数和相应的指数w
w
其中,
其中,
预测模块将每个指数神经元输出的交叉特征聚合时可以采用各种方法,如 加和平均,加权等等,本例采用拼接方法,即将所有指数神经元输出的特征相 互作用向量拼接得到一个大向量,对于上述指数神经元,得到的特征向量维度 为K·o·n
其中,n
进一步的,基于特征向量进行分类预测时,分类预测可以通过下式进行:
其中,
其中
进一步的,为了便于将本发明系统用于各类预测任务(学习任务)的训练 (学习)以及预测,并提供相应预测的解释,设置本发明系统还包括存储模块。 存储模块提供了结构化数据底层的存储支持。同时,存储模块还为预测模块的 训练提供了逻辑表的抽象功能,以及在模型部署后,为具体应用的学习任务提 供运行时数据收集、整理、转发至预测模块的功能。
结构化数据(或关系数据、表格数据)指的是可以用表格来表示的数据类型。 结构化数据物理存储在一组由若干行和列组成的表(关系){T
为具体应用的学习任务(或逻辑表T的学习)提供运行时数据收集、整理、 转发至预测模块的功能;所述收集包括训练后的指数神经元参数配置、权重, 以及当前预测实例及其权重,所述整理包括统计全局高频交互项、全局属性重 要性排名、局部属性重要性排名。预测模块在进行预测前需要先进行学习(或 训练),即确定K、o、α等超参数和所有指数神经元的全局权值v
进一步的,为便于人们了解预测模块的预测机制和预测结果,设置系统还 包括功能模块,由预测单元、全局解释单元和局部解释单元组成,主要提供三 个运行时功能:预测,全局解释性以及局部解释性。预测单元的输入为与学习 时一样的结构化数据,可以是单个样本向量,也可以是多个样本组成的矩阵输 入,其将输入逐样本转到预处理模块及预测模块进行预测,并将其预测模块反 馈的预测结果输出。全局解释单元针对整个模型(或具体应用的学习任务,如 app使用预测、点击预测、健康预测等)的整体逻辑,提供解释性支持。全局解 释单元将输出存储模块存储的对每一个属性的标量值,指示该属性的全局重要性。同时,还基于每个神经元捕捉到的历史交互项提供索引,输出存储模块存 储的经整理的高频的交互项特征。局部解释单元针对单个待预测的样本,提供 逐样本的局部性解释支持,输出对应于样本的每一个属性的标量值,指示其局 部重要性。同时,还可以动态地针对每个样本,输出捕捉到的交互项特征。
进一步的,有足够多隐藏单元的深度神经网络DNN是一种通用近似器,在 捕捉非线性特征交互作用方面具有很强的能力,因此可以将上述K×o个神经元构 成的网络(简称ARM-Net)与DNN结合进行更为有效的预测,此时预测结果
其中w
进一步的,为便于组成系统各模块的功能可以被方便使用,设置系统还包 括应用模块,提供对结构化数据应用的端到端的支持,该模块没有也无需统一 的输入输出,主要功能为对前述的存储模块、预处理模块、预测模块以及功能 模块的接口提供调度和封装,并对特定的应用提供定制化的适配。
前述的各模块可以单独适用,也可以组合适用,如图1所示的即为其中优 选的系统组成结构,包括存储模块(RDBMS)、预处理模块(Preprocessing Module)、预测模块(Prediction Module)、功能模块(Functionalities)和应用模 块(Applications),系统可为各种应用场景(如广告Advertising,推荐 Recommendation、健康分析HealthcareAnalytics)提供预测及其解释。
通过上述本发明预测方法提高了结构化数据关系建模的有效性、可解释性 和效率:
1、有效性
大多数现有的特征交互建模研究要么以预定义的最大交互阶数静态捕获可 能的交叉特征,要么以隐式的方式建模交叉特征。然而,在不同的输入实例中, 不同的关系应该具有不同的组成属性。有些关系是有信息的,而另一些可能只 是噪音。因此,以静态方式建模交叉特征不仅参数和计算效率低,而且可能是 无效的。特别地,每个指数神经元的输出y
2、可解释性
可解释性度量了模型所做的决策可以被人类理解的程度,从而得到用户的 信任并提供新的见解。目前已经存在解释黑盒模型如何工作的事后解释方法, 包括基于扰动的方法、基于梯度的方法和基于注意的方法。然而,另一个模型 给出的解释往往不可靠,这可能会产生误导。另外,本发明遵循白盒设计,并 且建模过程更加透明,因而在关系分析处理中更具解释性。
具体地说,每个特征交互项y
3、效率
除了有效性和可解释性之外,模型复杂性是实际应用中模型部署的另一个 重要标准。为了简化分析和减少超参数的数目,我们将所有嵌入、注意向量的 大小设置为n
对于ARM模块,K·o个指数神经元可在复杂度O(Komn
试验结果
使用五个真实数据集(app推荐(Frappe)、电影推荐(MovieLens)、分类 点击率预测(Avazu、Criteo)和医疗健康(Diabetes130))对本发明(ARM-Net、 ARM-Net+)和现有五类特征交互建模方法进行比较。
五个数据集的统计数据及本发明ARM网络中搜索到的最佳超参数见表1: 数据集统计和ARM-Net最佳参数配置(Table1:Dataset statistics and best ARM-Netconfigurations),表中给出了不同数据集(Dataset)的元组(实例)数(Tuples)、 属性域数目(Fields)和不同特征数(Features),以及对应数据集的本发明网络 的最佳超参数(ARM-Net Hyperparameters)。
Table 1:Dataset statistics and best ARM-Net configurations.
五类特征交互建模方法为:
(1)线性回归(LR),在不考虑特征交互的情况下,将输入属性与其各自 的重要性权重进行线性聚合;
(2)对二阶特征交互作用进行建模的方法,即FM,AFM;
(3)捕捉高阶特征交互作用的方法,即HOFM,DCN,CIN和AFN;
(4)基于神经网络的方法,即DNN,以及图神经网络GCN和GAT。
(5)通过DNNs集成了显式交叉特征建模和隐式特征交互建模的模型, 即Wide&Deep、KPNN、NFM、DeepFM、DCN+、xDeepFM和AFN+。
使用AUC(ROC曲线下的面积,越大越好)和Logloss(交叉熵,越小越 好)作为评价指标。对于AUC和Logloss,在采用的基准数据集上,0.001水平 的改近被认为是显著的。我们将数据集分成8:1:1,分别用于训练、验证和测试, 报告五次独立运行的评估指标的平均值,并在验证集上采取了提前停止的策略。
试验中采用Adam优化器,学习率搜索范围为0.1~1e-3,所有模型的batch size定为4096。特别地,我们对较小的数据集Diabetes130采用1024的batch size, 对于较大的数据集Avazu,则每1000个训练步骤进行一次评估。实验是在Xeon (R)Silver 4114CPU@2.2GHz(10核)、256G内存和GeForce RTX 2080Ti的 服务器上进行的。模型在PyTorch1.6.0和cuda10.2中实现。
比较结果见表2:相同训练数据集下的总体预测性能(Table2:Overallprediction performance with the same training settings)。
从表2中可以看出:
1.使用单个模型的显式交互建模。
将ARM网络与单一结构的基线模型进行比较,这类基线模型可以显式地捕 获一阶、二阶和高阶交叉特征。基于表2结果,我们有以下发现:
Table 2Overall prediction performance with the same trainingsettings.
首先,ARM-Net在AUC上始终优于显式建模相互作用的基线模型。更好 的预测性能证实了ARM-Net跨数据集和领域的有效性,包括应用推荐(Frappe)、 电影标签推荐(MovieLens)、点击率预测(Avazu和Criteo)和医疗再入院预测 (Diabetes130)。
其次,高阶模型(例如HOFM和CIN)通常比低阶模型(例如LR和FM) 有更好的预测性能,这验证了高阶交叉特征对预测的重要性,高阶交叉特征的 缺失会大大降低模型的建模能力。
第三,AFN和ARM-Net都显著优于固定阶的基线模型,这验证了以自适应 和数据驱动的方式建模任意阶特征交互的有效性。
最后,ARM-Net的AUC明显高于一般表现最好的基线模型AFN。
ARM网络的良好性能主要归功于指数神经元和门控注意机制。具体来说, AFN中对数变换正输入的限制限制了它的表示,而ARM-Net则通过在指数空间 中建模特征交互来避免这个问题。此外,ARM-Net的多头门控注意力不像AFN 那样静态地建模交互,而是选择性地过滤噪声特征,并动态地生成交互权重, 以反映每个输入实例的特征。因此,ARM-Net可以捕获更有效的交叉特征,以 便在每个输入的基础上获得更好的预测性能,并且由于这种运行时灵活性, ARM-Net的参数效率更高。如表1所示,对于不同规模的数据集,最好的ARM-Net只需要几十到几百个指数神经元,而最好的AFN一般需要一千多个神 经元才能获得最佳结果,例如,在大型数据集Avazu上,ARM网络和AFN分 别需要32个和1600个神经元。
2.基于神经网络的模型和集成模型。
基于表2结果,我们有以下发现:
(1)尽管没有显式地对特征交互进行建模,但是相对于其他单一结构的 基线模型,最佳的基于神经网络的模型通常具有更强的预测性能。特别是,基 于注意力机制的图网络GAT在Avazu和Diabetes130上获得了明显高于其他单 一结构模型的AUC。然而,它的性能并不像ARM-Net那样稳定,不同的数据集 之间差异很大,例如,GAT在Frappe和MovieLens上的性能比DNN和ARM-Net 差得多。
(2)DNN的模型集成显著提高了它们各自的预测性能。这可以在整个基 线模型中一致地观察到,例如DCN+、xDeepFM和AFN+,这表明DNNs捕获 的非线性相互作用是对显式捕获的相互作用的补充。
(3)ARM-Net实现了与DNN相当的性能,ARM-Net+进一步提高了性能, 在所有的基准数据集上都获得了最好的整体性能。
总之,这些结果进一步证实了ARM-Net对任意阶特征交互的有选择地、动 态地建模的有效性。
对于解释性的试验结果
本发明通过在两个具有代表性的领域,即Frappe上的用户应用程序使用预 测和Diabetes130上的糖尿病患者的再入院预测,展示了ARMOR的可解释性结 果。具体来说,Frappe上的学习任务是根据给定使用上下文预测应用程序的使 用状态。上下文包括10个属性域,{user_id,item_id,daytime,weekday,weekend, location,is_free,weather,country,city},主要描述移动终端用户的使用模式; 对于Diabetes130,学习任务是通过分析糖尿病患者再入院的相关因素及其他信 息来预测再入院的可能性。共有43个属性域用于预测,我们展示了10个最重 要的属性域进行了说明。两个数据集的属性域的解释都是公开的(Linas Baltrunas, Karen Church,Alexandros Karatzoglou,and NuriaOliver.2015.Frappe:Understanding the Usage and Perception of Mobile AppRecommendations In-The-Wild.arXiv preprint arXiv:1505.03014(2015).以及BeataStrack, Jonathan P DeShazo,Chris Gennings,Juan L Olmo,Sebastian Ventura,Krzysztof J Cios,and John N Clore.2014. Impact of HbA1c measurement onhospital readmission rates:analysis of 70,000clinical database patientrecords. BioMed research international 2014(2014).),通过这些解释可以验证ARM-Net产生的可解 释性结果。
对于这两个数据集,首先展示了通过聚集指数神经元的值向量获得的各个 属性域的全局特征重要性,并将ARM-Net的全局特征归因与两种被广泛采用的 解释方法Lime(Marco Túlio Ribeiro,Sameer Singh,and Carlos Guestrin.2016."Why Should ITrust You?": Explaining the Predictions of Any Classifier.In Proceedings ofthe 22nd ACM SIGKDD.ACM,1135-1144.)和 Shap(Scott M.Lundberg and Su-InLee.2017.A Unified Approach to Interpreting Model Predictions.In Advances inNeural Information Processing Systems 30:Annual Conference on NeuralInformation Processing Systems,USA.4765-4774.)进行了比较。这两种方法采用基于线性回归和博弈论的输 入扰动的解释方法来识别待解释模型的特征重要性。具体来说,在Frappe和 Diabetes130数据集上Lime和Shap的解释结果分别基于表现最佳的单结构基线模型DNN和GAT(Petar Velickovic,Guillem Cucurull,Arantxa Casanova,AdrianaRomero,Pietro Liò, and Yoshua Bengio.2018.Graph Attention Networks.In 6thInternational Conference on Learning Representations,ICLR.),两种方法给出的全局特征重要性是通过对测试数据集所有实 例的局部特征归因进行聚合得到的。然后,我们以相应的频率(Frequency)和 阶数(Orders)显示ARM-Net捕获的顶级交互项(InteractionTerm),它们分别 表示每个实例的平均出现次数和为每个交互项捕获的特征数量。我们还通过显 示ARM模块通过聚集分配的特征交互权重来说明局部解释,并再次将ARM-Net 的局部特征归因结果与Lime和Shap进行比较。
全局可解释性。我们在图3中说明了全局特征归因,并在表3和表4中分 别总结了ARM-Net捕获的两个数据集的高频交互项。
Table 3:Top Global Interaction Terms for Frappe.
Table 4:Top Global Interaction Terms for Diabetes 130.
从图3中,可以看到在Frappe数据集上,ARM-Net识别的最重要的特征是 {user_id,item_id,is_free}。对这些属性的全局关注是合理的,因为user_id和 item_id标识用户和item,是协同过滤等学习任务中使用的两个主要特征,is_free 表示用户是否为应用付费,这与用户对应用的偏好高度相关。同样地,在 Diabetes130数据集上,ARM-Net确定的最重要特征包括{急诊评分、住院评分、 诊断数},这与文献(Beata Strack,Jonathan PDeShazo,Chris Gennings,Juan L Olmo,Sebastian Ventura, Krzysztof J Cios,andJohn N Clore.2014.Impact of HbA1c measurement on hospital readmission rates:analysis of 70,000clinical database patient records.BioMed researchinternational 2014(2014).)中logistic回归模 型估计的属性域系数是一致的。我们还注意到,ARM-Net提供的全局特征重要 性与两种通用的解释方法(即Lime和Shap)是一致的。同时,我们注意到 ARM-Net提供的全局特征重要性相对更可靠,因为ARM-Net本质上就支持全局 特征归因,其建模过程更透明,而Lime和Shap通常被用作一种通过近似来解 释其他“黑盒”模型的媒介。
从表3中Frappe数据集上的顶级全局交互项中,可以发现:首先,交互项 建模最频繁的属性域包括use_id、item_id和is_free,这与图3中的全局特征重 要性是一致的。其次,这些交互项在交互建模中经常出现,比如交互项(工作 日,地点,is_free),(item_id,is_free,city)和(user_id,is_free)的频率分别 为3.71,3.36和2.88,这表明这些(具有不同交互权重的)交叉特征在每个实 例中被使用了多次(注意,每个实例的推理都有K·o交互项)。第三,交互项的 阶数多为2和3,这说明为交互建模识别合适的属性集是必要的,而通过列举所 有可能的特征组合来捕获交叉特征效率极低并且是无效的,这可能会引入噪声。
从表4中列出的针对Diabetes130数据集的顶级全局交互项中,可以观察到 交互项中最常建模的属性域是相当多样化的,这表明不同的指数神经元确实捕 获了不同的交叉特征,这在建模特征交互时参数效率更高。此外,顶层交互项 的阶数小于3,并且存在许多一阶项,这表明对于一些数据集,例如Diabetes130, 建模高阶的交叉特征可能是不必要的。
局部可解释性。图4显示了Frappe数据集上的一个代表性输入实例的 ARM-Net的局部特征归因,其中显示了三个代表性指数神经元的交互权重和所 有神经元的平均权重。我们可以注意到不同的指数神经元以稀疏的方式选择性 地捕捉不同的交叉特征。例如,Neuron3捕获特征交互项(item\id,weekend, country),这表示对于这个特定的实例,Neuron3对这三个属性有响应。此外, 该实例的聚合交互权重显示item_id、is_free和user_id是三个最具区分性的属性, 这与图3中的全局解释结果一致。我们还通过图4中的Lime(Marco Túlio Ribeiro, Sameer Singh,and Carlos Guestrin.2016."Why Should ITrust You?":Explaining the Predictions of Any Classifier.In Proceedings ofthe 22nd ACM SIGKDD.ACM,1135-1144.)和Shap(Scott M.Lundberg and Su-InLee.2017.A Unified Approach to Interpreting Model Predictions.In Advances inNeural Information Processing Systems 30:Annual Conference on NeuralInformation Processing Systems,USA.4765-4774.)说 明了局部特征归因。我们可以注意到,尽管Lime和Shap都和ARM-Net一样, 将item_id、user_id和city作为的三个最重要的特征,但是Lime也赋予了其他 特征很大的重要性权重,例如is_free、country。这表明外部解释方法可能并不 一致,也不一定可靠,因为它们只是待解释的模型的近似。
图5给出了Diabetes130数据集上相似的局部特征归因结果。我们可以发现, 不同的指数神经元侧重于不同的交叉特征。具体来说,Neuron1和Neuron2分别 更关注emergency_score和diag_1_category,Neuron3更关注num_diagnoses。此 外,对于这一特定的糖尿病患者,最后五个特征,即emergency_score, inpatient_score,diag_1_category,num_diagnoses以及diabetes_med是再入院 预测中最有用的属性。通过这种局部解释,ARM-Net可以支持更个性化的分析 和管理。
随着机器学习模型在医疗保健、金融投资和推荐系统等各个领域发挥越来 越重要的作用,对模型透明度和可解释性的需求越来越高,这有助于调试学习 模型,也有利于模型的验证和改进。此外,一个可解释的模型也可促进对某些 领域的理解,从而才能产生对分析结果的信任。
作为全局或局部可解释性的一种简单而有效的方法是特征归因,它根据所 用特征的权重和大小来确定输入实例的特征重要性。值得提到的是,基于博弈 论模型,Shapley值评估了预测中每个特征的重要性,LIME使用线性模型通过 输入扰动对模型进行局部逼近,从而提供不局限于某具体模型的局部解释。 Grad-CAM为基于CNN的模型提供了基于梯度加权类激活映射的可视化解释, 以突出局部区域。
同时,也有结合领域的专业知识而提出的针对特定领域的模型解释方法。 例如,在医疗分析和金融领域,越来越多地采用深度模型来实现高预测性能; 然而,这种关键和高风险的应用强调了对可解释性的需要。特别是,注意力机 制被广泛采用,通过可视化注意力权重来促进深度模型的可解释性。通过将注 意力机制整合到模型设计中,许多研究成功实现了可解释的医疗分析。具体而 言,Dipole用三种注意机制在诊断预测中支持访问级解释。RETAIN和TRACER 可以支持访问级别和特征级别的解释。然而,大多数现有方法的一个固有限制 是,它们的可解释性是建立在单个输入特征的基础上的,而忽略了关系分析所必需的特征交互。
特征交互建模。交叉特征通过相应组成特征的乘积来显式地建模属性域之 间的特征交互,这对于不同应用程序的预测分析非常重要,例如应用程序推荐 和点击预测。许多现有的工作使用DNNs隐式地捕捉交叉特征。然而,用DNNs 隐式地建模相乘的特征交互需要大量的隐藏单元,这使得建模过程效率低下, 同时在实践中难以解释。
许多模型提出显式地捕获交叉特征,这通常能获得更好的预测性能。在这 些研究中,一些模型捕捉了二阶特征相互作用,另一些则模拟了在预定义的最 大阶内的高阶特征相互作用。最近的工作AFN提出用对数神经元来模拟任意阶 的交叉特征,但这也有着对数变换对输入限制的局限性和运行时的灵活性限制。 本发明ARM-Net则基于门控多头注意机制提出了自适应地使用指数神经元建模 特征相互作用的方法,该模型准确、高效、可解释性强。其核心思想是通过交 叉特征有选择地、动态地建立属性依赖和相关性模型。首先将输入特征转化为 指数空间,然后自适应地确定每个交叉特征的交互权重和交互阶数。为了对任 意阶交叉特征进行动态建模和选择性过滤噪声特征,我们提出了一种新的稀疏 注意机制来生成给定输入元组的交互权重。因此,本发明ARM-Net能够以输入 感知的方式识别信息量最大的交叉特征,从而在推理过程中获得更准确的预测 和更好的解释性。对真实数据集的大量实验研究证实,与现有模型相比, ARM-Net始终具有优越的预测性能,全局可解释性和针对单个实例的局部可解 释性。
描述于本公开实施例中所涉及到的模块、单元可以通过软件的方式实现, 也可以通过硬件的方式来实现。其中,模块、单元的名称并不构成对该模块或 单元本身的限定,其次,本公开实施例中所涉及到的模块、单元的功能划分只 是一种逻辑划分,并不构成对该模块或单元本身的限定,可选的,还可以做其 它方式的划分,如本公开将含有功能a、b、c、d、e、f、g的系统划分为A(包 含a、b功能)、B(包含c、d、e、f功能)、C(包含g功能)模块,那么其它 任何包含a、b、c、d、e、f、g功能的系统都属于本发明的保护范围,无论其模 块如何划分,如将a、b、e划分为D模块,c、f、g划分为E模块,d划分为F 模块。
应当理解,本发明的各部分可以用硬件、软件、固件或它们的组合来实现。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于 此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到 的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围 应以权利要求的保护范围为准。
- 一种基于结构化数据的预测系统
- 一种基于熵权法的压力容器结构化数据质量评估方法