一种基于注意力对抗生成网络的无监督图像除雨方法
文献发布时间:2023-06-19 12:02:28
技术领域
本发明涉及计算机视觉领域,主要涉及是一种可以进行无监督学习并且能够提高图片除雨效果的神经网络模型,经过网络模型处理后的图像可见度得到显著提升。主要应用于图像风格转换和自动驾驶目标识别的数据增强等方面。
背景技术
雨水会导致捕获的图像和视频的视觉质量下降。雨水条纹(尤其是在大雨中)会对背景造成严重的遮挡。雨水堆积会导致无法单独看到远处的雨水条纹,并且与水颗粒一起在背景上形成一层面纱,这大大降低了背景的对比度和可见度。人类视觉和许多计算机视觉算法都遭受这种图像损坏的困扰,因为常见的计算机算法假定天气晴朗,不会单独考虑雨水条纹和雨水堆积的干扰。但在实际应用工况下,雨天是尤为常见的的一种天气状况,因此,提高有雨图像的质量对于后续图像的应用非常必要。
传统的除雨方法使用简单的线性映射转换,对输入的变化没有鲁棒性。雨水又具有不同的方向,密度和大小会导致传统的方法无法达到理想效果。近年来,基于深度学习的卷积层和非线性层的方法比传统方法具有明显的优势。这些方法在特征表示和处理效果都有了较大的提高。对于输入的变化有了更高的鲁棒性。但是神经网络的训练依托于大量的数据,并且绝大多数的网络需要输入相互匹配的同场景有雨与清晰图像样本对,这对数据集的构建增加了难度。
发明内容
本发明针对以上问题,提出了一种引入注意力机制的对抗生成网络无监督除雨方法,可有效克服在生成对抗网络训练时所要求成对数据获取困难的问题,并引入了注意力机制,使得网络在处理图像时聚焦于有雨区域,输出更为理想无雨图像。
本发明的技术方案为:按以下步骤进行图像处理:
步骤1、构建数据集:收集具有信息相关性的类似场景雨图和清晰图片作为网络训练数据集,并对所有图片做预处理;
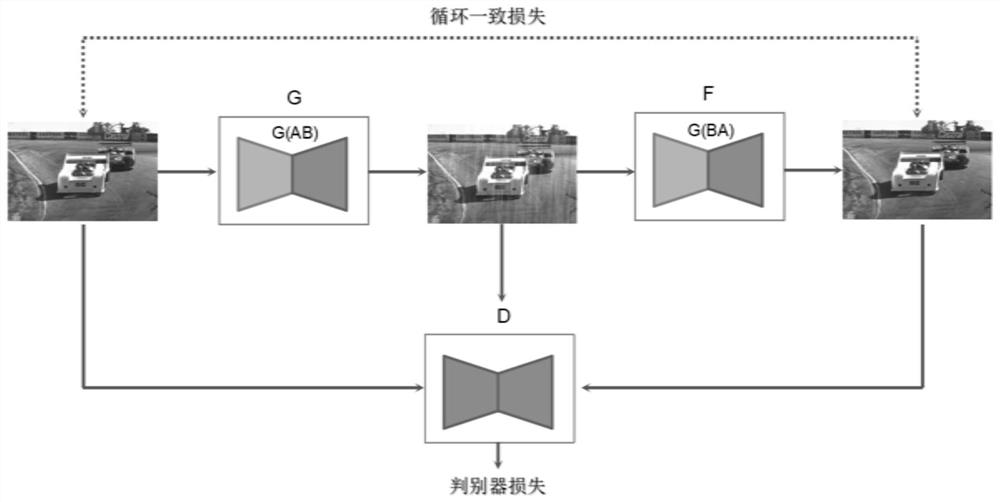
步骤2、搭建卷积神经网络:构建的卷积神经网络包括三个子网络:生成器G、生成器F,判别器D;生成器G输入源域无雨图片x和目标域非对应有雨图像r,输出生成目标域有雨图片G(x,r);生成器F输入是生成器G生成的有雨图片G(x,r)和源域无雨图像x,输出生成的源域无雨图片F(G(x,r),x);生成器F的生成过程是源域图片x的重建过程,设计生成器F的重构损失使F(G(x,r),x′)和源域图片x相似,这样一张源域图片经过G变为目标域图片,目标域图片再经过F转换回源域图片;G和F为一个互逆的过程,一张图片依次经过G和F,图片保持不变;
步骤3、训练:训练判别器D,训练生成器G,训练生成器F;
步骤4、实际使用:训练完成后,将生成器F单独采用,完成输入有雨图像完成交叉验证与测试,得到处理完后无雨图像。
步骤2中生成器F详细参数如下:生成器F由两个子网络组成:注意力循环网络和语义自动编码器;
注意力循环网络详细参如下:将注意力循环网络的循环参数设定为5,每一次循环中包括残差网络、卷积长短期记忆网络两个部分,图像首先进入残差网络中,残差网络共有9层,第一层是32个具有3*3卷积核大小的滤波器,填充方式为SAME,对四维张量图做滑步为1的滑动卷积提取特征,第一层卷积后接Leaky-relu激活函数层。之后的八层同样是32个具有3*3卷积核大小的滤波器,填充方式为SAME,滑步为1的卷积层和Leaky-relu激活函数层;每两层做一次同等映射。随后将卷积后的特征图输入到卷积长短期记忆网络中;卷积长短期记忆网络包含一个输入门一个输入门i
其中X
语义自编码器详细参数如下:语义自编码器由上采样与下采样两部分构成;上采样首先经过四层卷积核为3*3,步长为2的卷积层,滤波器的个数分别为64,128,256,填充方式为SAME,每一层都接Leaky-Relu激活函数层并做实例归一化的处理。然后经过三层具有256个卷积核为3*3滤波器的空洞卷积,扩张率分别为2,4,8,16。空洞卷积在不通过池化层;不降低分辨率,不引入额外的参数与计算量的情况下增大感受野。之后再经过两层具有256个卷积核为3*3滤波器的卷积层;下采样包换2个反卷积层,第一层为128个卷积核为4*4的滤波器做步长为1/2的分步卷积,接着一层平均池化层,并做实例归一化的处理;然后将上采样第二层输出与此层输出合并成下一层输入。第二层为64个卷积核为4*4的滤波器做步长为1/2的分步卷积,随后接一层平均化层并做实例归一化;然后将上采样第一层输出与此层输出合并成下一层输入;在经历完上下采样后最后通过一个具有3个3*3卷积核的滤波器,且步长为1的卷积层作为F生成器的输出。
步骤2中生成器G的详细参数如下:生成器G与F的差异体现在注意力机制,生成器G的输入是源域无雨图像和并非相对应的目标域有雨图像,为生成器G与判别器D提供成对的数据集,使整个除雨网络实现无监督学习;相较于生成器F生成器G去除了卷积长短期记忆网络,也去除了注意力机制。
判别器D的详细参数如下:首先是7个卷积层,每个卷积层卷积核模板大小都为5*5,步长都为1,激活函数都为Leakey-ReLU,从最后三个卷积层提取特征并进行对应元素相乘生成注意力图。
步骤3中训练判别器D具体为,判别器输入为G生成的有雨图片作为标签,与真实无语图片和生成器F输出无雨图片;在注意力图指导下,采用极大似然估计来描述图像之间的差距,其损失函数可以表示为:
L
其中O是生成器F语义自编码器的输出,X是原域真实无雨图像X,A
L
步骤3中训练生成器G具体为,将真实源域图像X与非对应有雨图像输入,同时利用上一步训练的判别器D来训练生成器G,判别器D参数固定。生成器G的损失如下面公式所示:L
步骤3中训练生成器F具体为,生成器F的输入是G生成器产生的有雨图像和源域真实无雨图像以及二进制掩码M,二进制掩码M产生是有两张图像的灰度图相减所得到;利用注意力循环网络时间维度上输出的注意力图A
L
其中L
L
L
发明的有益效果为:
一、将循环对抗生成网络应用于除雨任务之中,使网络可以输入非匹配图像进行非监督训练。
二、将注意力机制引入到生成器F,使网络可以产生更好的局部图像恢复,也可以用于判别网络的聚焦评估。
三、在语义自编码器使用三层空洞卷积,在不通过池化层;不降低分辨率;不引入额外的参数与计算量的情况下增大网络的感受野。
四、采用一个判别器代替原循环对抗生成网络的两个判别器,将网络精简且减少计算量,提高判别器的判别能力,进而提升生成器的图像恢复能力。
五、可有效克服在生成对抗网络训练时所要求成对数据获取困难的问题,使得网络在处理图像时聚焦于有雨区域,输出更为理想无雨图像。
附图说明
图1为本发明注意力循环生成对抗除网络的模型示意图;
图2为本发明生成器F中注意力循环网络示意图;
图3为本发明生成器F中语义自编器网络示意图;
图4为重建损失示意图。
具体实施方式
为能清楚说明本专利的技术特点,下面通过具体实施方式,并结合其附图,对本专利进行详细阐述。
本发明如图1-4所示,按以下步骤进行图像处理:
首先通过步骤1进行数据集的搭建以及预处理,将数据集按照比例70%,15%,15%划分为训练集,验证集与训练集。之后步骤2搭建好网络模型,步骤3对判别器D进行训练,并分别对生成器G与F进行训练。步骤4从训练好的模型中单独提取出生成器F进行交叉验证与测试。
步骤1、构建数据集:收集具有信息相关性的类似场景雨图和清晰图片作为网络训练数据集,数据来源包括网上开源图片数据库以及自建图片数据集,并对所有图片做预处理;步骤1中的预处理包括利用pytorch中的transforms模块将图片数据尺寸调整为240*360,并且利用transform模块将图片随机裁剪与翻转和归一化,提高网络的鲁邦性。将两类图片数据按照相关度划分为不同的批次,每批次图像对的数量相当。
步骤2、搭建卷积神经网络:构建的卷积神经网络包括三个子网络:生成器G、生成器F,判别器D;生成器G输入源域无雨图片x和目标域非对应有雨图像r,输出生成目标域有雨图片G(x,r);生成器F输入是生成器G生成的有雨图片G(x,r)和源域无雨图像x,输出生成的源域无雨图片F(G(x,r),x);生成器F的生成过程是源域图片x的重建过程,设计生成器F的重构损失使F(G(x,r),x′)和源域图片x相似,这样一张源域图片经过G变为目标域图片,目标域图片再经过F转换回源域图片;G和F为一个互逆的过程,一张图片依次经过G和F,图片保持不变;保证图片在源域和目标域转换的过程中,重要特征不会丢失;因为如果G输出生成目标域有雨图片G(x,r)的过程中,如果生成器G不保留源域图片x的重要特征,F生成的源域图片F(G(x,r),x)将会和源域图片x有很大的不同;所以只有G和F在生成过程中都保留输入图片的重要特征,这种重建才能完成,这样背景重要信息才得以保留。判别器有两个作用:(1)使得生成器F生成的源域无雨图片F(G(x,r),x)和源域图片x在真实性方面尽量一致,即生成的源域无雨图片F(G(x,r),x)通过判别器的真假判别输出为真,提升图像的除雨效果;(2)使得生成器G生成的目标域有雨图片G(x,r)尽可能属于目标域,产生更为真实的下雨效果。
步骤2中生成器F详细参数如下:生成器F由两个子网络组成:注意力循环网络和语义自动编码器;注意力循环网络的目的是在输入图像中寻找需要注意的区域,这些区域主要是雨点区域及其周围的结构,这同样是语义自编码器需要聚焦的区域,使得生成器可以产生更好的局部图像恢复,也可以用于判别网络的聚焦评估。
注意力循环网络详细参如下:本发明中将注意力循环网络的循环参数设定为5,每一次循环中包括残差网络、卷积长短期记忆网络两个部分,图像首先进入残差网络中,残差网络共有9层,第一层是32个具有3*3卷积核大小的滤波器,填充方式为SAME,对四维张量图做滑步为1的滑动卷积提取特征,第一层卷积后接Leaky-relu激活函数层。之后的八层同样是32个具有3*3卷积核大小的滤波器,填充方式为SAME,滑步为1的卷积层和Leaky-relu激活函数层;每两层做一次同等映射。随后将卷积后的特征图输入到卷积长短期记忆网络中;卷积长短期记忆网络包含一个输入门一个输入门i
其中X
语义自编码器详细参数如下:语义自编码器由上采样与下采样两部分构成;上采样首先经过四层卷积核为3*3,步长为2的卷积层,滤波器的个数分别为64,128,256,填充方式为SAME,每一层都接Leaky-Relu激活函数层并做实例归一化的处理。然后经过三层具有256个卷积核为3*3滤波器的空洞卷积,扩张率分别为2,4,8,16。空洞卷积在不通过池化层;不降低分辨率,不引入额外的参数与计算量的情况下增大感受野。之后再经过两层具有256个卷积核为3*3滤波器的卷积层;下采样包换2个反卷积层,第一层为128个卷积核为4*4的滤波器做步长为1/2的分步卷积,接着一层平均池化层,并做实例归一化的处理;然后将上采样第二层输出与此层输出合并成下一层输入。第二层为64个卷积核为4*4的滤波器做步长为1/2的分步卷积,随后接一层平均化层并做实例归一化;然后将上采样第一层输出与此层输出合并成下一层输入;在经历完上下采样后最后通过一个具有3个3*3卷积核的滤波器,且步长为1的卷积层作为F生成器的输出。
步骤2中生成器G的详细参数如下:生成器G与F的差异体现在注意力机制,生成器G的输入是源域无雨图像和并非相对应的目标域有雨图像,为生成器G与判别器D提供成对的数据集,使整个除雨网络实现无监督学习;相较于生成器F生成器G去除了卷积长短期记忆网络,也去除了注意力机制。具体来说就是上述残差网络和自编码器所组成。
判别器D的详细参数如下:首先是7个卷积层,每个卷积层卷积核模板大小都为5*5,步长都为1,激活函数都为Leakey-ReLU,从最后三个卷积层提取特征并进行对应元素相乘生成注意力图。旨在指导判别器在聚焦局部区域判别输出图片是真是假。最后进入输出维度为1024的全连接层。
步骤3、训练:训练判别器D,训练生成器G,训练生成器F;
步骤3中训练判别器D具体为,判别器输入为G生成的有雨图片作为标签,与真实无语图片和生成器F输出无雨图片;在注意力图指导下,采用极大似然估计来描述图像之间的差距,其损失函数可以表示为:
L
其中O是生成器F语义自编码器的输出,X是原域真实无雨图像X,A
L
步骤3中训练生成器G具体为,将真实源域图像X与非对应有雨图像输入,同时利用上一步训练的判别器D来训练生成器G,判别器D参数固定。生成器G的损失如下面公式所示:L
步骤3中训练生成器F具体为,生成器F的输入是G生成器产生的有雨图像和源域真实无雨图像以及二进制掩码M,二进制掩码M产生是有两张图像的灰度图相减所得到;利用注意力循环网络时间维度上输出的注意力图A
L
其中L
L
L
步骤4、实际使用:训练完成后,将生成器F单独采用,完成输入有雨图像完成交叉验证与测试,得到处理完后无雨图像。
具体来说,根据网络模型与损失函数的设计使用Python语言与Pytorch深度学习框架实现图2和图3所示组成生成器F的循环网络和语义自编码器的模型,以及上述生成器G和辨别器D的模型。之后将划分好的训练集输入网络中进行训练,当损失函数很小或者不变化时候表示训练完成。最后将生成器F单独采用,完成输入有雨图像完成交叉验证与测试,得到处理完后无雨图像。
本发明具体实施途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以作出若干改进,这些改进也应视为本发明的保护范围。
- 一种基于注意力对抗生成网络的无监督图像除雨方法
- 一种基于生成对抗网络的无监督多模态图像转换方法