基于深度学习和混合噪声数据增强的运动想象脑电信号分类方法
文献发布时间:2023-06-19 12:14:58
技术领域
本发明属于计算机软件领域,是一种用于识别运动想象肢体部位的基于深度学习和混合噪声数据增强方法的脑电信号分类方法。
背景技术
近年来,脑机接口(Brain Computer Interface,BCI)领域的研究受到国内外研究者的广泛关注。脑机接口是一种通过脑电信号等大脑放出的生物信号来实现大脑和机器通讯的系统,不依赖于外围神经和肌肉等大脑输出信息的常用途径,主要应用于康复医学等领域,可以辅助针对残障人士的治疗与复健,为患有严重神经肌肉疾病的患者开发新的辅助交流和控制技术。脑机接口分为侵入式和非侵入式脑机接口两类。其中,侵入式脑机接口虽具有信号的分辨率和信噪比和较高的优点,但还需要高昂的手术费用,并需要定期进行医学检查,具有较高的风险。非侵入式脑机接口虽然信噪比相对较低,但是使用成本和风险远低于侵入式脑机接口,因此受到更加广泛的关注。非侵入式脑机接口以脑电信号(Electroencephalography,EEG)、脑磁信号(Magnetoencephalography,MEG)和功能性近红外信号(functional near-infrared spectroscopy,fNIRS)等信号作为输入。其中,脑电信号作为大脑神经元电生理信号在头皮总和的表征,在非侵入式脑机接口中应用最广泛。基于脑电信号的非侵入式脑机接口分为主动式和响应式两类。主动式以基于运动想象(MotorImagery,MI)的脑机接口为主。基于运动想象的脑机接口是一种无需外部刺激、由用户主动调控、可体现自主运动意图的脑机接口范式,是最重要、研究最广泛的范式之一。基于运动想象的脑机接口主要研究运动想象脑电信号的分类问题。运动想象脑电信号的分类以想象特定部位的运动而产生的脑电信号作为输入数据,根据其特征,利用分类模型判定其类别,从而识别受试者欲产生运动的身体部位。目前,运动想象脑电信号的分类研究主要存在脑电信号信噪比低、样本量较小的问题。
为了解决信噪比低、难于分类的问题,研究者利用机器学习和深度学习方法实现对脑电信号特征的提取与分类。机器学习方法中,共空间模式(Common Spatial Pattern,CSP)、滤波器组共空间模式(Filter Bank Common Spatial Pattern,FBCSP)和基于黎曼几何的方法(Riemannian geometry-based methods)的分类准确率较高,但仍有待进一步提升。近些年,研究者发现深度学习方法比机器学习方法可以获得更好的分类效果。Schirrmeister等人提出DeepConvNet(深层卷积网络)和ShallowConvNet(浅层卷积网络)方法,通过对比发现轻量的浅层神经网络可以更好地解码运动想象脑电信号的特征。Lawhern等人结合FBCSP和浅层神经网络的思想,提出了EEGNet方法,在公开数据集上得到了和FBCSP方法相近的分类准确率(66%),同时还将该方法应用于其他范式。Wu等人结合FBCSP方法中滤波器组的思想和ShallowConvNet方法,提出MSFBCNN(Multiscale FilterBank Convolutional Neural Network,多尺度滤波器组卷积神经网络)方法改进ShallowConvNet的准确率。Borra等人兼顾可解释性和轻量化的思想,提出Sinc-ShallowNet(基于Sinc函数的浅层网络)方法,在公开数据集上得到了72.8%的分类准确率。从上述研究可发现,轻量化和滤波器组的思想在基于深度学习的运动想象脑电信号的分类研究中起到了关键的作用。
为了解决样本量较小的问题,深度学习领域常用的数据增强方法可用于扩充运动想象脑电数据的样本量,从而满足深度学习方法对数据量的需求,提高方法的准确率和稳定性。运动想象脑机接口领域常用的数据增强方法主要包括3种:添加噪声(noiseadding)、划窗(slicing window)和对抗生成网络(Generative Adversarial Networks,GAN)。其中,对抗生成网络常用于增强时频表示(time-frequency representation)的脑电信号;划窗适合于处理原始脑电信号,且在结合层数较深的神经网络(如DeepConvNet等)使用时效果较好,搭配浅层神经网络的效果不显著甚至会降低准确率;添加噪声主要结合浅层神经网络使用,可用于增强原始脑电信号或时频表示的脑电信号。结合3种方法的常用网络结构和数据特点可以看出,处理原始脑电信号的浅层神经网络适合通过添加噪声的方法进行数据增强。
结合上述对现有方法的分析,本发明提出基于经验模态分解的混合噪声数据增强方法和FB-Sinc-ShallowNet方法(Filter Bank Sinc-ShallowNet,滤波器组Sinc-ShallowNet),以解决脑电信号信噪比低和样本量小的问题。通过对比实验和消融实验,本发明验证了提出方法可以有效提高运动想象脑电信号的分类准确率。
发明内容:
①提出基于经验模态分解的混合噪声数据增强方法。该方法将EMD方法提取出的原始信号的主要信息添加到高斯白噪声中形成混合噪声,将其添加到原始信号以合成新的训练样本实现数据增强。
②提出FB-Sinc-ShallowNet方法以提高分类准确率。
③用欧式对齐(Euclidean Alignment,EA)方法对数据进行预处理以进一步提高分类准确率。
本发明具有以下优点:
(1)使用经验模态分解提取出和原信号最相关的成分,与特定信噪比的白噪声混合生成新数据用于数据增强,比直接添加白噪声生成的新样本的效果更好。
(2)FB-Sinc-ShallowNet方法结合了轻量化和滤波器组的思想,通过学习4组不同频段的滤波器组对输入信号进行带通滤波和特征提取,以较快的收敛速度训练出准确率较高的分类模型。
使用欧式对齐对脑电数据进行预处理可以减少不同时间的脑电样本的差异,降低分类难度。
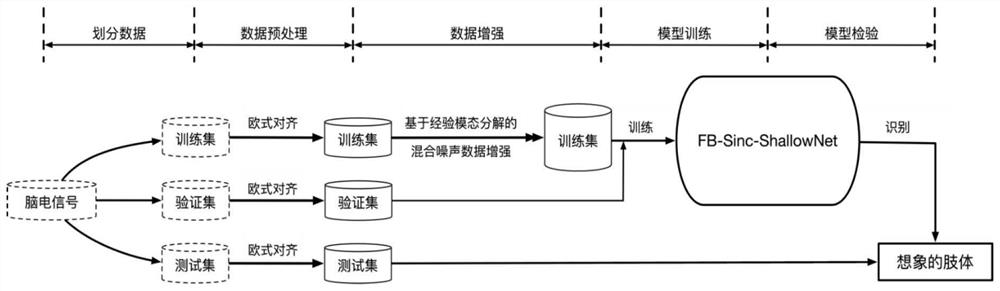
1.一种基于深度学习和混合噪声数据增强的运动想象脑电信号分类方法,其特征在于,包括以下步骤:
步骤1.将脑电信号数据集划分为训练集、验证集和测试集。对3个集合的数据分别进行欧式对齐预处理;
步骤2.对训练集数据进行基于经验模态分解的混合噪声数据增强,扩充训练集样本数量至原来的2倍;
步骤3.将扩充后的训练集与验证集输入到FB-Sinc-ShallowNet方法中训练模型;
步骤4.对测试集的数据进行分类,识别受试者运动想象的肢体部位。
2.根据权利要求1所述的分类方法,其特征在于,使用基于经验模态分解的混合噪声数据增强方法扩充样本,具体为:
对原始信号进行经验模态分解(Empirical Mode Decomposition,EMD)得到最相关的IMF(Intrinsic Mode Functions,本征模态函数)成分,估计IMF能量并计算阈值以过滤出信号的主要信息,将其与白噪声混合并调整混合噪声的信噪比,之后添加到原始信号中以生成高质量的样本。
具体步骤为:
步骤1:EMD与IMF成分筛选:对原始信号进行经验模态分解,得到多个IMF成分,保留相关系数大于等于0.1的IMF成分,舍弃其他IMF成分,从而筛选出和原信号最相关的IMF成分。
步骤2:估计IMF成分的能量:假设第一个IMF成分中包含原信号中绝大多数噪声,以第一个IMF成分为基准估计其他IMF成分中的噪声能量值;
步骤3:基于自适应阈值过滤IMF成分:以每个极值点左右两侧相邻零点所划分的区间作为单位,将每个IMF成分划分为若干个区间,按照极值从小到大排列,从小到大依次求能量的累加和直到累加能量达到IMF成分的噪声能量估计值(临界值),以达到临界值前的极值作为阈值筛选划分的区间,保留极值大于等于阈值的区间的信号并过滤掉其他区间的信号,从而提取出原信号中的有效成分;
步骤4:生成混合噪声:基于原信号的有效成分生成特定信噪比的白噪声序列,与原信号的有效成分求和得到混合噪声;
步骤5:生成新样本:将混合噪声与原始信号求和,得到新样本,与原数据一并用作训练集数据。
3.根据权利要求1所述的分类方法,其特征在于,使用欧式对齐方法对样本进行预处理,具体为:
步骤1:已知一个受试者的样本为X,包含N个样本。计算所有样本的协方差矩阵的算术平均值;
步骤2:求算数平均值矩阵中每个元素的平方根的倒数得到变换矩阵;
步骤3:对每个样本乘上变换矩阵实现欧式对齐。
4.根据权利要求1所述的分类方法,其特征在于,使用FB-Sinc-ShallowNet(滤波器组Sinc-ShallowNet)方法进行分类,具体为:
输入信号分成4份分别送入浅层神经网络的4个分支中,每个分支包含一个SincConv层、一个深度卷积层和一个池化层。4个分支的输出最终合并成一个特征图(feature map),经过丢弃层(Dropout)进行正则化,并通过Flatten层转为一维向量后用SoftMax函数进行分类。具体步骤如下:
步骤1:将输入信号分成4份,送入4个分支;
步骤2:每个分支用SincConv层(Sinc卷积层)计算输入信号与FIR(FiniteImpulse Response)滤波器的时域卷积。
步骤3:每个分支用批归一化层调整特征权值的大小以提高网络训练的速度;
步骤4:每个分支用深度卷积层将每个通道的卷积结果分开计算,提取空域信息;
步骤5:每个分支用批归一化层调整特征权值的大小以提高网络训练的速度;
步骤6:每个分支用一个ELU激活函数进行非线性操作;
步骤7:每个分支用一个平均池化层压缩特征图的时域信息;
步骤8:将4组特征图合并,用丢弃层进行正则化,随机丢弃一半的神经元的特征;
步骤9:将所有特征图压缩成一个一维向量,输入到SoftMax函数中进行分类。
附图说明
图1发明总体流程图
图2基于经验模态分解的混合噪声数据增强方法流程图
图3FB-Sinc-ShallowNet方法流程图
图4数据集实验时间示意图
具体实施方式
本发明将经验模态分解方法与白噪声数据增强方法结合,提出基于经验模态分解的混合噪声数据增强方法,通过提取原始信号的主要信息与白噪声进行混合,提高生成样本质量,从而训练出准确率更高、稳定性更强的分类器;同时结合轻量、收敛速度快的FB-Sinc-ShallowNet方法进一步提高分类准确率,为运动想象脑电信号分类提供了高效稳定的深度学习方法。
图1可以分解为本发明的几个步骤。
步骤一,将脑电信号数据集划分为训练集、验证集和测试集。对3个集合的数据分别进行欧式对齐预处理;
步骤二,对训练集数据进行基于经验模态分解的混合噪声数据增强,扩充训练集样本数量至原来的2倍。
步骤三,将扩充后的训练集与验证集输入到FB-Sinc-ShallowNet方法中训练模型。
步骤四,对测试集的数据进行分类,识别受试者运动想象的肢体部位。
在详细说明具体方法前,先对本发明要解决的问题和涉及的符号进行定义。运动想象脑电信号数据由一组多通道幅值(magnitude)时间序列和事件标记构成。经过预处理后,可以从多通道幅值时间序列提取出样本和标签。脑电信号的样本和标签分别表示为一个维度为N×E×T的矩阵X和一个长度为N的向量y,其中N表示样本个数,E表示通道个数,T表示采样点个数。样本i在通道e上时刻t的样本数据记为X
一、基于经验模态分解的混合噪声数据增强方法
为了解决样本数量N较少的问题,在运动想象脑机接口领域,添加噪声的数据增强方法将均值为0的白噪声添加到脑电信号中。然而,由于脑电信号具有低信噪比的特点,直接添加噪声生成的样本具有更低的信噪比,限制了数据增强的效果。为了提高生成样本的质量,本发明提出基于经验模态分解的混合噪声数据增强方法,对原始信号进行经验模态分解(Empirical Mode Decomposition,EMD)得到最相关的IMF(Intrinsic ModeFunctions,本征模态函数)成分,估计IMF能量并计算阈值以过滤出信号的主要信息,将其与白噪声混合并调整混合噪声的信噪比,之后添加到原始信号中以生成高质量的样本,如图2所示。该方法包含4个步骤:EMD与IMF成分筛选、估计IMF能量、基于自适应阈值过滤IMF成分和生成混合噪声。下面分别对这4个步骤进行说明。
1.1EMD与IMF成分筛选
首先对原始信号进行经验模态分解。记样本i在通道e上的信号X
之后,计算信号S和每个IMF成分的相关系数,保留相关系数大于等于0.1的IMF成分(共J′个),舍弃其他IMF成分,从而筛选出和原信号最相关的IMF成分。相关系数定义为:
1.2估计IMF成分的能量
估计IMF成分的能量的方法常用于信号降噪,其假设第一个IMF成分中包含原信号S中绝大多数噪声,以第一个IMF成分为基准估计其他IMF成分中的噪声能量值。第一个IMF成分的能量通过式3估计。
其余IMF成分的能量通过式4估计。其中,H指Hurst指数,β
1.3基于自适应阈值过滤IMF成分
估计每个IMF成分的能量后,以每个极值点左右两侧相邻零点所划分的区间作为单位,将每个IMF成分划分为若干个区间,用于自适应地计算每个IMF成分能量对应极值的阈值,保留极值大于等于阈值的区间的信号并过滤掉其他区间的信号,从而提取出原信号中的有效成分。具体分为以下两步:
(1)计算极值的阈值
将第j′个IMF成分划分成P个区间,按照极值从小到大排列,记排序后区间的极值为
取第q个区间的极值的绝对值作为阈值T
(2)过滤IMF成分
记第j′个IMF成分的区间为IMF
将所有J′个IMF成分都进行基于自适应的阈值过滤后,将IMF成分求和,得到信号
S′,如式7所示。其中,IMF
1.4生成混合噪声
提取出原信号的主要信息S′后,基于S′生成特定信噪比的白噪声序列。令信噪比SNR=sdB,可通过式9计算白噪声的能量E
之后,创建长度为T、均值为0、标准差为std的白噪声序列构成的向量a=[a
生成混合噪声后,将其添加到原始信号中。第i个样本的第e个通道的原始信号X
二、FB-Sinc-ShallowNet方法
为了解决脑电信号信噪比、难于分类的问题,本发明结合轻量化和滤波器组的思想,提出FB-Sinc-ShallowNet(滤波器组Sinc-ShallowNet)方法,在Sinc-ShallowNet方法的基础上学习多组带通滤波器,从不同的频段提取脑电信号的特征,以进一步提高模型的分类准确率。该方法的网络结构如图3所示。输入信号分成4份分别送入浅层神经网络的4个分支中,每个分支包含一个SincConv层、一个深度卷积层和一个池化层。4个分支的输出最终合并成一个特征图(feature map),经过丢弃层(Dropout)进行正则化,并通过Flatten层转为一维向量后用SoftMax函数进行分类。下面对每层进行详细说明。
2.1SincConv层
SincConv层(Sinc卷积层)计算输入信号与FIR(Finite Impulse Response)滤波器的时域卷积,从而实现以较少的参数提取输入信号中更有意义的特征,同时具备收敛快速的优点。不同于传统时域卷积层,SincConv层以频率下限f
y[T]=x[T]*h(T,f
其中,x[T]表示长度为T的信号,y[T]表示长度为T的滤波后信号,h(T,f
h[T,f
其中,sinc(·)表示sinc函数,定义为:
式11所定义的卷积核函数由式13所定义的带通滤波器通过傅里叶逆变换(inverse Fourier transform)得到。
其中,rect(·)表示频域的矩形函数,其相位是线性的。为了减少阻带的震荡、使其过度更加平滑以构建效果更好的带通滤波器,在核函数中引入Hamming窗函数,如式14所示。
其中L表示时域卷积核的长度。
SincConv层的初始化参数决定了其学习到的带通滤波器的频段范围。记f
在SincConv层之后有一个批归一化层(Batch Normalization),用于调整特征权值的大小以提高网络训练的速度。该层将一个小批次(mini batch)内的特征图进行均值为0、方差为1的归一化,缓解“内部协变量偏移”(internal covariate shift)现象,从而减少训练过程中分布的变化,加快模型的训练。在用于运动想象脑机接口领域的研究中,批归一化层通常添加在时域卷积和空域卷积之后,因此本发明也在SincConv层后添加一个批归一化层,并将其参数设为m=0.99,∈=1e-3以提高稳定性。
m是动量,∈是一个用于防止分母为0的极小数。
2.2深度卷积层与池化层
在每个浅层网络的分支中,经过SincConv层提取时域信息和批归一化层加速后,特征图被输入到深度卷积层(DepthwiseConv2D)中提取空域信息。该层在计算卷积时将每个通道的卷积结果分开计算,不像普通卷积层一样将多通道的结果合并。同时,卷积核大小设为E×1(在图3中E=22)可以一次计算所有通道的特征值,在EEGNet中也得到应用。此外,为了防止梯度变化过大,在该层对梯度进行了最大范数约束,范数最大值为1。
在深度卷积层后,有一个批归一化层和ELU(Exponential Linear Unit)激活函数层。前者用于加速训练,参数设置同之前的批归一化层;后者用于提高模型的分类性能。ELU在运动想象脑机接口领域的研究中表现出比其他激活函数更好的性能,其定义如式15所示。
其中,参数α设为1。经过激活函数后,用一个平均池化层来压缩特征图的时域信息以减少参数量。池化层的大小设为1×109,步长为1×23,其含义是以约0.1秒的步长提取0.5秒的深层时域特征。
2.3分支合并与分类
经过四个分支的特征提取与压缩后,将4组特征图合并。每个分支有64个1×15的特征图,合并后得到256个1×15的特征图。整合4个分支的信息后,用丢弃层进行正则化。丢弃层通过随机舍弃部分神经元的方式来简化模型结构,防止过拟合现象。本发明将丢弃层的丢弃率设为0.5,即随机丢弃一半的神经元的特征。
最后,将所有特征图压缩成一个一维向量,输入到SoftMax函数中进行分类。同时,在最后一层添加了最大范数约束对模型进行正则化(最大范数为0.5),以防止出现过拟合现象。
三、欧式对齐预处理方法
欧式对齐(Euclidean Alignment,EA)方法是He等人提出的一种迁移学习方法,通过对不同受试者的脑电信号做统一的矩阵变换,使其协方差矩阵的均值变为单位阵,从而减少不同受试者之间的差异,提高跨受试者(cross subject)实验的效果(跨受试者实验指用其他受试者的脑电数据训练模型,预测新受试者的样本的类别)。在本发明的单受试者(within subject)研究中,训练数据和测试数据均来自同一受试者,但采集自不同的时间,使用欧式对齐方法可以缓解时间差异对脑电特征的影响。因此,本发明采用欧式对齐方法对训练数据和测试数据进行预处理,以进一步提高模型的分类效果。
欧式对齐方法在计算变换矩阵时不需要样本的标签,仅需要样本数据。已知一个受试者的样本为X,包含N个样本。计算所有样本的协方差矩阵的算术平均值,如式16所示。
之后求算数平均值矩阵中每个元素的平方根的倒数得到变换矩阵,对每个样本乘上变换矩阵实现欧式对齐,如式17所示。
此时计算对齐后的样本的协方差矩阵的算术平均值,可得单位阵,如式18所示:
实验及结果:
为了验证提出方法的效果,本发明在公开的运动想象数据集BCI Competition IVIIa上进行实验,编程实现了提出方法和DeepConvNet、ShallowConvNet、EEGNet和Sinc-ShallowNet等现有方法,通过对比实验验证提出方法的效果,同时针对本发明的3点发明内容进行消融实验(Ablation Study)验证了3点发明内容在提出方法中的有效性。下面对实验过程和结果进行详细说明。
1.数据集与预处理方法
本发明使用BCI Competition IV Dataset IIa数据集进行实验。该数据集是第4届BCI竞赛上的公开数据集,其中包含9个受试者的左手、右手、双脚和舌头共4类运动想象脑电信号。这些脑电信号采集自22个电极,共包含576次试验(即样本个数为576)。这576个样本采集自两天,每天的实验记为1个session。每个session中包含4个类别的样本,每个类别包含72个样本。所有样本均已打标签(即标记该样本对应哪个部位的运动想象)。实验的时间设计如图4所示。每次实验先有一个固定的十字显示在屏幕上,在第2秒时会给出一个提示,之后第3秒受试者开始进行运动想象,持续3秒。由于不同受试者的脑电特征差异较大,因此进行脑电信号的分类实验需要为每个受试者单独计算分类准确率,并求多个受试者分类准确率的平均值作为模型的性能指标。
本发明沿用了在现有方法中常用的数据预处理方法,以更公平地与现有方法进行对比。首先,对原始脑电信号用3阶4-40Hz的巴特沃斯带通滤波器进行带通滤波,过滤出所需频段的信号。之后,对滤波后信号做指数移动均值标准化(衰减因子设为0.999),以减少数值差异对模型效果的影响。最后,提取出展示提示后0.5秒至2.5秒的数据作为一个样本。每个样本为一个1×22×500的矩阵,如图3顶部所示。预处理后,每个session包含288个样本。同其他现有方法,实验以第一个session的数据训练模型,以第2个session的数据测试模型的效果。
2.模型训练过程
开始训练之前,将经过预处理后的数据进行划分。将第2个session的288个样本用作测试集,第1个session的288个样本中80%的数据(约230个)作为训练集,其余20%的数据(约58个)作为验证集。划分数据后,对三个集合均进行欧式对齐预处理。之后,对训练集数据进行基于经验模态分解的混合噪声数据增强,扩充训练集样本至460个。之后开始训练。
实验中所有方法的训练均采用交叉熵损失函数,以Adam方法作为优化器,学习率均设为0.001,其余参数使用Adam方法的默认值。批训练的批大小(batch size)均设为64。Sinc-ShallowNet和提出方法的SincConv层的参数以具体实施方式中描述的方法进行初始化,其余参数均用Xavier均匀分布初始化方法进行初始化。
模型的训练分为2个阶段,和现有方法的设置相近。第一阶段的最大迭代次数设为800,且当验证集损失函数达到最低时提前结束训练,以防止过拟合现象并节省训练时间。在第二阶段中,将验证集数据合并入训练集数据中进行训练,当验证集损失值小于第一阶段训练集损失值时提前结束训练,最大迭代次数仍设为800。记录第二次迭代过程中验证集损失值最低时的模型,用其预测测试集样本,记录测试集准确率。对9个受试者分别进行上述模型训练和测试,得到9组测试集准确率,记录其平均值作为最终的模型准确率。实验用one-sided Wilcoxon符号秩检验方法来检测提出方法与现有方法的准确率均值之间差异的显著性,并使用α=0.05的错误发现率(False Discovery Rate,FDR)方法对多重比较的结果进行校正,从而减少多次进行比较带来的误差。
3.实验结果
(1)对比实验
将提出方法和现有方法进行对比实验,实验结果如表1所示。从表1结果可以看出,本发明提出的FB-Sinc-ShallowNet方法的准确率均值高于现有方法,且与所有对比方法做Wilcoxon符号秩检验的p-value均小于0.05,具有显著性,说明提出方法的性能优于对比方法;同时,提出方法的标准差与其他方法相比最低,说明提出方法的稳定性最高。
表1对比实验结果表
(2)消融实验
为了验证提出方法的3个发明内容的有效性,本发明进行了3组消融实验,分别使用如下方法进行模型的训练和测试:(1)不做基于经验模态分解的混合噪声数据增强时的FB-Sinc-ShallowNet;(2)不做欧式对齐预处理,但做基于经验模态分解的混合噪声数据增强时的FB-Sinc-ShallowNet;(3)不使用滤波器组结构,即用Sinc-ShallowNet方法结合基于经验模态分解的混合噪声数据增强与欧式对齐预处理。实验结果如表2所示。从表2可以看出,去掉3个发明内容的任何一个进行实验,得到的准确率均值均低于完整的提出方法,且做Wilcoxon符号秩检验的p-value均小于0.05,具有显著性,说明提出的3个发明内容均是有效且必不可少的;同时,提出方法准确率的标准差也是最低的,说明3个发明内容都具备时,提出方法具有更高的稳定性。
表2消融实验结果表
- 基于深度学习和混合噪声数据增强的运动想象脑电信号分类方法
- 基于混合模型的运动想象脑电信号分类方法