基于编解码器网络和引导图的抠图方法
文献发布时间:2023-06-19 13:49:36
技术领域
本发明涉及的是一种图像处理领域的技术,具体是一种基于编解码器网络和引导图的抠图方法。
背景技术
抠图(Image Matting)是通过输入的图像产生一个前景蒙版用于将前景物体(要抠出的物体)与背景分离,一般抠图问题被建模为求解公式I
发明内容
本发明针对现有基于三元图的抠图技术,无法采用草图或点击图实现抠图的不足,提出一种基于编解码器网络和引导图的抠图方法,通过三元图、草图、点击图或全灰输入作为引导图均可以通过简单操作实现精确抠图。
本发明是通过以下技术方案实现的:
本发明涉及一种基于编解码器网络和引导图的抠图方法,根据原图绘制一张引导图并通过编解码器网络进行第一次预测得到前景蒙版,根据预测的前景蒙版对原引导图进行修改并由编解码器网络再次进行预测,循环往复直到获得精确前景蒙版,随后通过精确前景蒙版和输入图像获得要抠出的前景。
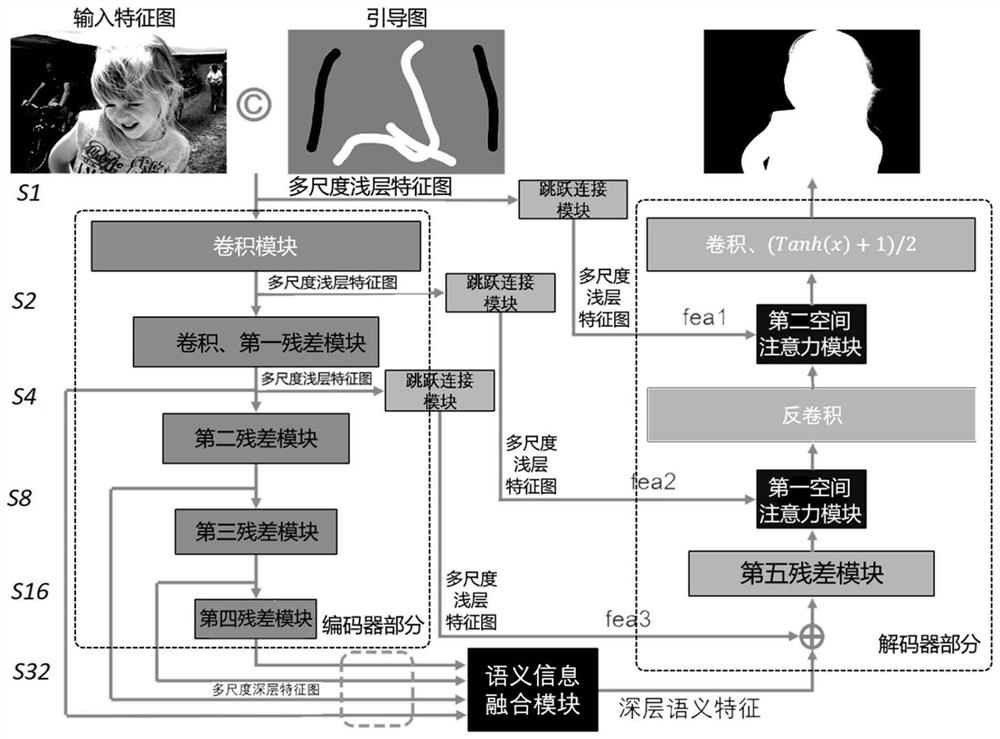
所述的编解码器网络包括:编码器、语义信息融合模块、跳跃连接模块和解码器,其中:编码器从输入图像和引导图在通道上连接而成的输入特征图中分别提取出多尺度深层特征图并输出至语义信息融合模块、提取出多尺度浅层特征图并通过跳跃连接模块输出至解码器;语义信息融合模块根据多尺度深层特征图进行特征融合与上采样,得到包含前景的轮廓信息的深层语义特征;解码器对深层语义特征进行上采样,同时与多尺度浅层特征图进行融合,最终得到前景蒙版。
所述的语义信息融合模块,包括:特征金字塔增强单元(FPEM)和联合上采样单元(JPU)级联,其中:特征金字塔增强单元从主干网络中提取多尺度特征并进行融合,增强语义信息,联合上采样单元将增强后的特征上采样得到深层语义特征。
所述的编解码器网络,通过基于深度学习的方法、使用公开抠图数据集进行基于渐进式三元图形变的训练,具体为:在训练过程中,随着训练步数的增加,输入网络的引导图中表示前景的区域面积与输入图像中前景区域的面积之比逐渐减少,输入网络的引导图中表示背景的区域面积与输入图像中背景区域的面积之比逐渐减少。输入神经网络的确定信息的量逐渐减少,使编解码器网络学会利用引导图中给定的有限的前景和背景信息预测前景蒙版。
所述的训练,其训练集和测试集使用的都是公开抠图数据集,其中训练集包含一定数量的前景图及其相应的前景蒙版,同时包含一定数量的背景图,测试集包含测试图片及相应的前景蒙版;损失函数使用L1、L2损失。
技术效果
本发明整体解决现有技术难以在保持抠图精度的同时减轻用户输入难度的缺陷,以及现有技术难以对抠图结果进行进一步优化的问题;本发明在训练过程中逐渐减少引导图中前景和背景的面积,使引导图逐渐从三元图变为草图,逐渐减少输入神经网络的确定信息的量,能够提升神经网络的鲁棒性,使其学会利用引导图中给定的前景和背景信息预测前景蒙版,而不是局限于三元图或草图的单个域中。用户可以根据前一次预测的前景蒙版在原引导图上进行修改,在没有预测正确的区域增加一些提示前景和背景的笔画,在局部增加引导图的信息,随后再次进行预测,循环往复,直到获得满意的抠图效果。
附图说明
图1为本发明网络结构示意图;
图2a和图2b分别为基于渐进式三元图形变的训练的流程图和效果图;
图3为语义信息融合模块的流程示意图;
图4a和图4b分别为迭代式优化抠图方法的流程图和效果图;
图5为主干网络及跳跃连接模块结构示意图;
图6为解码器部分结构示意图;
图7为渐进式三元图形变流程以及曲线粗细与训练步数的关系示意图;
具体实施方式
如图4a所示,为本实施例涉及的一种基于编解码器网络和引导图的抠图方法,根据原图绘制一张引导图并通过编解码器网络进行第一次预测得到前景蒙版,根据预测的前景蒙版对原引导图进行修改并由编解码器网络再次进行预测,循环往复直到获得精确抠图结果。
如图1所示,所述的前景蒙版,根据RGB图像与引导图在通道维度上连接成的特征图,使用本实施例编解码器网络得到。
如图3、图5、图6所示,所述的编解码器网络包括:编码器部分、语义信息融合模块、三个跳跃连接模块以及包含空间注意力模块的解码器部分,其中:三个跳跃连接模块分别设置于编码器部分和解码器部分之间并输出多尺度浅层特征图,语义信息融合模块接收编码器部分输出的多尺度深层特征图并输出至解码器部分,解码器部分输出精确抠图结果。
如图1所示,所述的编码器部分在训练阶段的输入特征图S1为RGB图和引导图在通道上连接而成,具体为输入特征图S1∈R
所述的第一至第四残差模块,均包括主分支和下采样分支,其中:主分支包含两层3*3卷积及相应的谱归一化、批次归一化以及ReLU激活函数,下采样分支包含一层平均池化层、一层1*1卷积及相应的谱归一化、批次归一化。经过主分支和下采样分支处理的特征图将会进行元素对应相加,相加的结果经过一层ReLU激活函数作为残差模块的输出。
所述的跳跃连接模块分别将输入特征图S1、2倍下采样特征图S2和4倍下采样特征图S4得到尺寸分别为fea1∈R
如图1和图3所示,所述的语义信息融合模块包括:特征金字塔增强单元(FPEM)和联合上采样单元(JPU),其中:特征金字塔增强单元从主干网络中提取多尺度特征并进行融合,增强语义信息,联合上采样单元将增强后的特征上采样得到深层语义特征。
所述的融合具体为:将4倍、8倍、16倍和32倍下采样特征图S4、S8、S16和S32特征图进行多尺度特征融合,输出为128*128*128、128*64*64、128*32*32和128*16*16大小的特征图。
所述的上采样具体为:将128*64*64、128*32*32和128*16*16大小的特征图进行融合并上采样,得到512*64*64大小的特征图,进行双线性插值之后得到512*128*128大小的特征图,与之前FPEM输出的大小为128*128*128的特征图在通道上连接,随后经过一层卷积层的处理,得到深层语义特征SFM_OUT∈R
如图6所示,所述的解码器部分包括:第五残差模块和两个空间注意力模块,其中:第五残差模块根据来自语义信息融合模块输出的深层语义特征SFM_OUT∈R
所述的第五残差模块包括:主分支和上采样分支,其中:主分支包含两层反卷积及相应的谱归一化、批次归一化以及ReLU激活函数,上采样分支包含一层最近邻采样层、一层1*1卷积及相应的谱归一化、批次归一化。经过主分支和上采样分支处理的特征图将会进行元素对应相加,相加的结果经过一层ReLU激活函数作为残差模块的输出。
如图2a和图2b所示,所述的编解码器网络,采用基于渐进式三元图形变的训练,在训练过程中逐渐减少引导图中前景和背景的面积,使引导图逐渐从三元图变为草图,逐渐减少输入神经网络的确定信息的量,使编解码器网络学会利用引导图中给定的前景和背景信息预测前景蒙版,具体包括:
①对于每一个训练的步数,先从DIM数据集中获取标签的前景蒙版,然后对其进行腐蚀膨胀得到三元图;
所述的腐蚀膨胀是指:首先在1-30的范围随机选择滤波核的大小,之后分别使用该大小的腐蚀滤波核和膨胀滤波核对标签的前景蒙版进行腐蚀和膨胀操作,得到腐蚀图和膨胀图,将腐蚀图中白色前景区域(值为1)和膨胀图中黑色背景区域(值为0)绘制在一张全灰(值为0.5)的图上,就得到三元图。
②在三元图的前景和背景区域分别采样得到关键点,分别使用前景关键点和背景关键点曲线拟合得到曲线函数;
所述的采样是指:在三元图的前景和背景区域按均匀分布随机采样共10个关键点,得到10个关键点的坐标。
所述的曲线拟合是指:每取三个前景关键点或背景关键点使用三次函数拟合出一条曲线,当只有两个点,则得到连接这两个点的直线,当只有一个点,则得到一个圆,其直径等于曲线和直线的粗细。
③根据训练的步数来控制曲线粗细,得到前景草图和背景草图;
所述的控制曲线粗细是指:设置曲线的粗细为d,训练初期d值较大,输出引导图为三元图,训练后期d值较小,输出引导图为草图,将前景关键点得到的曲线、直线和圆以及背景关键点得到的曲线、直线和圆分别按此粗细d以值为1(白色)绘制在两张值为全0(黑色)的图上,得到前景草图和背景草图。
如图7所示,所述的曲线粗细初始值为800,随着训练步数的增加而降低,在530000步的时候是40,之后直到60万步训练结束都保持40。在530000步之前粗细与训练步数的函数关系为
④使用从三元图中得到的前景和背景掩膜除去前景草图和背景草图中多余的部分;
所述的从三元图中得到的前景和背景掩膜是指:三元图分为前景区域(值为1)、过渡区域(值为0.5)和背景区域(值为0),分别根据前景区域和背景区域生成对应的掩膜就是前景和背景掩膜。
⑤将去除多余部分的前景草图和背景草图进行融合得到引导图,随着训练步数的增加,逐渐减小曲线的粗细就能使前景和背景面积逐渐减小,使引导图从三元图逐渐变为草图。
所述的前景草图和背景草图进行融合是指:已经得到去除多余部分的前景草图P
所述的整个神经网络的损失函数为
本实施例涉及的编解码器网络中所有的卷积层都使用谱归一化(SpectralNorm)进行处理。
本实施例在实验测试平台(CPU:AMD R53600,GPU:GTX2080Ti)上进行,使用深度学习框架为Pytorch。
本实施例数据集使用DIM数据集,包含43100张背景和431个前景物体,需要通过程序合成成完整的图片才能送入网络中训练。训练时输入图像的大小调整为512*512,训练步数为60万次迭代,批次大小为10。在训练过程中使用的数据增强方式为随机仿射变换和本发明提出的渐进式三元图形变策略。首先对前景和相应的标签前景蒙版做随机仿射变换,之后使用公式I
本实施例提出的迭代式优化抠图方法。在使用阶段,通过将引导图和原图输入网络来预测出前景蒙版。在这个过程中,很难一次就能够达到理想的效果,因此需要对引导图进行不断地修改。本方法支持保留上一次输入网络的引导图,用户可以在其基础上进行修改。如图4b所示,第一次的抠图效果并不理想,第二次添加一些草图,前景的轮廓已经出来,但是细节部分效果不好,因此可以继续添加一下提示细节的草图,达到更好的效果。通过迭代式优化抠图方法,用户可以不断对引导图进行修改,直到取得理想的效果。
表1 DIM测试集(composition-1k)测试精度
在DIM测试集上进行测试,其中4个评价指标分别为Sum of Absolute Difference(SAD),Mean Square Error(MSE),Gradient error(Grad)以及Connectivity error(Conn)。其中Trimap test表示测试使用三元图,Scribblemap test表示测试使用草图,Clickmap test表示测试使用点击图,No-Guidance test表示输入一张值为0.5的引导图,没有任何前景和背景提示。表中用虚线将所有的方法分为三部分,最上面是基于三元图的方法,中间是无引导信息的抠图方法,下面是本方法。
将本实施例的结果和基于三元图的方法进行比较可以发现在输入三元图的情况下,本方法精度超过所有基于三元图的方法,在输入草图和点击图的情况下本实施例的输入对于用户来说更加简单,同时精度超过所有基于三元图的方法。在无引导信息输入的情况下,本实施例的结果也远远超过之前的无引导信息的抠图方法。对比本实施例的四个测试结果,可以看出给定的引导信息越精确,抠图结果就越好。
与现有技术相比,本发明使用DIM训练集训练能在DIM测试集上达到SAD30.1精度;相比基于三元图的方法,本方法只需草图或点击就能进行抠图,对于简单的前景,用户可以用草图或点击进行抠图,节约时间,对于难度高的前景,用户可以画更详细的三元图将其抠出;进一步可以在上一次输入的引导图的基础上进行修改,不断优化抠图结果。
上述具体实施可由本领域技术人员在不背离本发明原理和宗旨的前提下以不同的方式对其进行局部调整,本发明的保护范围以权利要求书为准且不由上述具体实施所限,在其范围内的各个实现方案均受本发明之约束。
- 基于编解码器网络和引导图的抠图方法
- 一种基于生成对抗网络的像素级人像抠图方法