一种实现隐私信息检索的方法、系统、服务器和客户端
文献发布时间:2023-06-19 18:27:32
技术领域
本说明书实施例属于隐私计算技术领域,尤其涉及一种实现隐私信息检索的方法、系统、服务器和客户端。
背景技术
隐私保护计算(Privacy-Preserving Computing)是在保护数据本身不对外泄露的前提下实现数据分析计算的技术集合,实现数据的可用不可见。通过隐私保护计算技术,可以在充分保护数据和隐私安全的前提下,实现数据价值的转化和释放。
目前实现隐私保护计算的主流技术主要包括三大方向:第一类是以多方安全计算(Secure Multi-Party Computation,SMPC)为代表的基于密码学的隐私计算技术;第二类是以联邦学习(Federated Learning,FL)为代表的人工智能与隐私保护技术融合衍生的技术;第三类是以可信执行环境(Trust Execution Environment)为代表的基于可信硬件的机密计算(Confidential Computing,CC)技术。此外,还包括差分隐私(DifferentialPrivacy,DP)等。差分隐私(Differential Privacy,DP)实际则是对计算结果的保护,而不是针对计算过程;联邦学习、安全多方计算以及机密计算则是对计算过程以及计算过程中间结果进行保护。
第一类的多方安全计算,又包括四大基础技术,分别是混淆电路(GarbledCircuit,GC)、秘密分享(Secret Sharing)、不经意传输(Oblivious Transfer)和同态加密(Homomorphic Encryption,HE)。其中,同态加密是一种特殊的加密算法,在密文基础上直接进行计算,与基于解密后的明文是一样的计算结果,其又包括半同态加密(PartiallyHomomorphic Encryption,PHE)和全同态加密(Fully Homomorphic Encryption,FHE)。
安全多方计算凭借其坚实的安全理论基础提供输入秘密数据的隐私保护能力,实现隐私保护计算过程的安全。目前安全多方计算主要有两条实施技术路线,包括通用安全多方计算和特定问题安全多方计算。前者可以解决各类计算问题,但是这种“万能型”的技术路线通常体系庞大,各种开销较大;后者针对特定问题设计专用协议,如隐私集合求交PSI(Private Set Intersection,PSI),隐私信息检索(Privacy Information Retrieval,PIR)等,往往能够以比通用安全多方计算协议更低的代价得到计算结果,但是需要领域专家针对应用场景进行精心设计,一般无法适用于通用场景且设计成本较高。
隐私集合求交是参与双方在不泄露任何额外信息的情况下,得到双方持有数据的交集。额外的信息指的是除了双方的数据交集以外的任何信息。隐私集合求交在现实场景中非常有用,比如在纵向联邦学习中做数据对齐,或是在社交软件中通过通讯录做好友发现等。
隐私信息检索是客户端从数据库检索信息的一种方法。检索过程中,查询方隐藏查询目标标识,数据服务方提供匹配的查询结果却无法获知具体的查询对象。
发明内容
本说明书的目的在于提供一种实现隐私信息检索的方法、系统、服务器和客户端,包括:
一种实现隐私信息检索的方法,服务端将数据库加密后得到查询基,并发送该查询基至客户端;客户端与服务端对同一目标执行的加/解密采用可交换顺序的加/解密算法;
在一次检索过程中,包括:
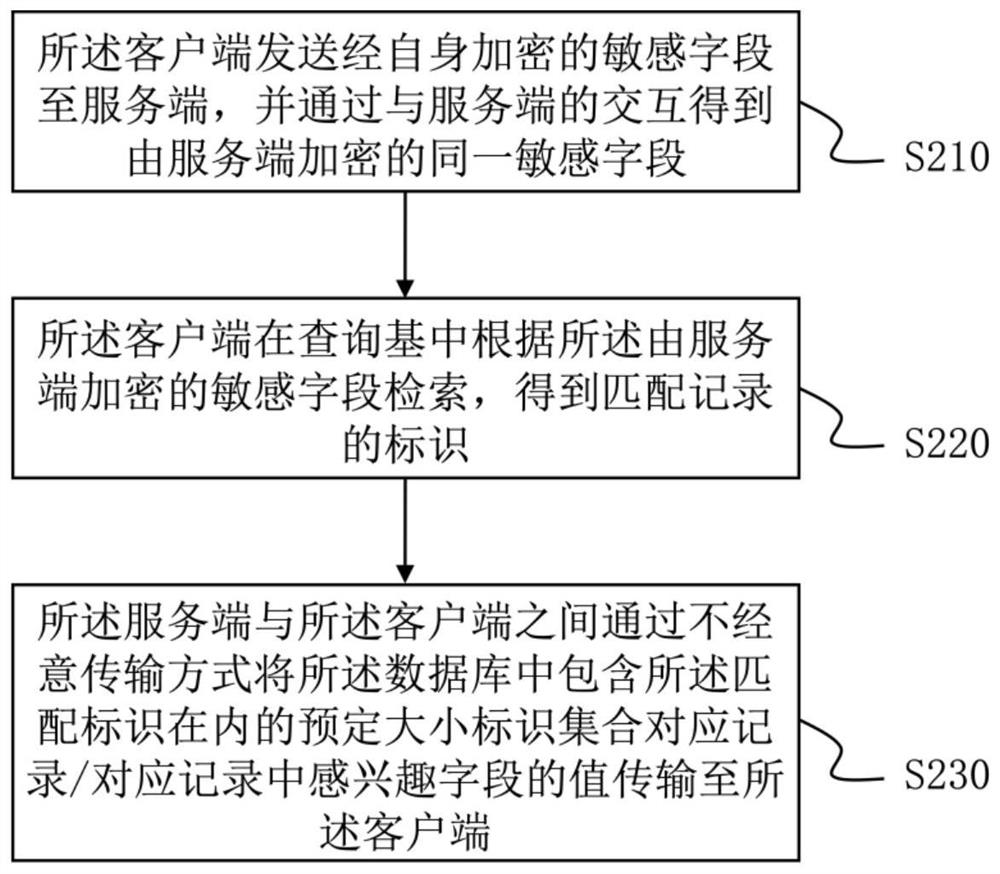
S210:所述客户端发送经自身加密的敏感字段至服务端,并通过与服务端的交互得到由服务端加密的同一敏感字段;
S220:所述客户端在查询基中根据所述由服务端加密的敏感字段检索,得到匹配记录的标识;
S230:所述服务端与所述客户端之间通过不经意传输方式将所述数据库中包含所述匹配标识在内的预定大小标识集合对应记录/对应记录中感兴趣字段的值传输至所述客户端。
一种实现隐私信息检索的系统,包括服务端与客户端,客户端与服务端对同一目标执行的加/解密采用可交换顺序的加/解密算法,且:
所述服务端配置有数据库,并将该数据库加密后得到查询基,并发送该查询基至客户端;
在一次检索过程中:
所述客户端发送经自身加密的敏感字段至服务端,并通过与服务端的交互得到由服务端加密的同一敏感字段;
所述客户端在查询基中根据所述由服务端加密的敏感字段检索,得到匹配记录的标识;
所述服务端与所述客户端之间通过不经意传输方式将所述数据库中包含所述匹配标识在内的预定大小标识集合对应记录/对应记录中感兴趣字段的值传输至所述客户端。
一种实现隐私信息检索的服务端,所述服务端与客户端对同一目标执行的加/解密采用可交换顺序的加/解密算法,且:
所述服务端配置有数据库,并将该数据库加密后得到查询基,并发送该查询基至客户端;
在一次检索过程中:
所述服务端接收所述客户端发送的经自身加密的敏感字段并再次加密后返回至所述客户端;所述服务端还与所述客户端之间通过不经意传输方式将所述数据库中包含所述匹配标识在内的预定大小标识集合对应记录/对应记录中感兴趣字段的值传输至所述客户端。
一种实现隐私信息检索的客户端,该客户端与服务端对同一目标执行的加/解密采用可交换顺序的加/解密算法,且:
所述客户端配置有查询基,所述查询基由所述服务端将数据库加密后得到;
在一次检索过程中:
所述客户端发送经自身加密的敏感字段至服务端,并通过与服务端的交互得到由服务端加密的同一敏感字段;所述客户端还在查询基中根据所述由服务端加密的敏感字段检索,得到匹配记录的标识;所述客户端还与所述服务端之间通过不经意传输方式获得所述数据库中与所述匹配标识对应记录/对应记录中感兴趣字段的值。
上述实施例中,通过将查询基预先配置到客户端的形式,实现不暴露数据库明文的情况下由客户端通过与服务端交互及查询基定位要查询的字段在查询基中的标识,进一步根据标识向服务端发起查询,保证了服务端对数据库的隐私保护,且可以支持结构化查询语句。而且,所述服务端与所述客户端之间传输匹配标识对应记录/对应记录中感兴趣字段的值,采用了不经意传输方式,这样不会暴露客户端的匹配标识至服务器,保护了客户端隐私。
附图说明
为了更清楚地说明本说明书实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本说明书中记载的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1是一实施例的流程示意图;
图2是一实施例的流程示意图。
具体实施方式
为了使本技术领域的人员更好地理解本说明书中的技术方案,下面将结合本说明书实施例中的附图,对本说明书实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本说明书一部分实施例,而不是全部的实施例。基于本说明书中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都应当属于本说明书保护的范围。
如前所述,PIR是客户端从数据库检索信息的一种方法。PIR方案是由Chor B等在1995年提出的解决保护用户查询隐私的方案。PIR方案的主要目的是,保证查询用户向服务器上的数据库提交的查询请求,在用户查询的隐私信息不被泄漏的条件下完成查询,即在检索过程中服务器不知道用户具体查询信息及检索出的数据项。
隐私信息检索的应用场景包括有:
i.病患想通过医药系统查询其疾病的治疗药物,如果以该疾病名为查询条件,医疗系统将会得知该病人可能患有这样的疾病,从而病人的隐私被泄露,通过隐私信息查询可以避免此类泄露问题。
ii.在域名、商标申请过程,用户需要首相向相关数据库提交自己申请的域名或商标信息以查询是否已存在,但有不想让服务提供方知晓自己的申请名称,从而能够抢先注册。
iii.在证券市场中,某用户想查询某个股票信息,但又不能将自己感兴趣的股票泄露给服务方从而影响股票价格和自己的偏好。
一个简单的实现方案是数据库把所有数据发送给客户端,但无法保护数据库安全,即无法保证服务端的隐私。能够同时保证客户端和数据库隐私安全的PIR,称为对称的PIR(Symmetrical PIR,SPIR),同时保证客户端和数据库两者之一隐私安全的PIR,称为非对称的PIR(Asymmetrical PIR,APIR)。根据数据库副本的个数分为多副本PIR和单副本PIR。多副本PIR协议要求多个数据库副本之间不能合谋,这在现实场景中很难满足,因此考虑更多的是单副本PIR。单副本PIR只能达到计算安全(Computational PIR,CPIR)。在大多数PIR方案中,总是假设客户端知道想要检索的是数据库的第几个比特(单比特)。但是在现实场景中,客户端往往是根据关键字检索(并不知道该关键字对应数据库的具体位置),且希望取回的是字符串(多比特)。总而言之,一个实用的PIR通常需要最好同时满足对称、单副本、按关键字检索、返回字符串等多个条件,并达到计算效率和通信效率的平衡。通过同态加密、不经意传输(Oblivious Transfer,OT)、单向陷门函数(One-way TrapdoorFunction)等密码学技术,可以满足或部分满足上述条件。
本说明书提供一种实现隐私信息检索的方法实施例。
该实施例中,服务端(Server)可以预先将数据库加密后得到查询基,并发送该查询基至客户端。
一般的,服务端本地具有数据库,可以供客户端查询。服务端本地的数据库例如为如下:
表1、服务端具有的数据库
上述表1的例子中,包括ID、Name、Age、Native_place这4个字段,例如有id_0,...id_9共10条记录,每一行为一个记录。其中,id_0,...id_9为每一行记录的标识。
为了让客户端可以进行检索,而又不暴露服务端的隐私安全,服务端可以加密该数据库,得到查询基。加密方式可以采用RSA(一种使用广泛的非对称加密算法,1977年由罗纳德·李维斯特(Ron Rivest)、阿迪·萨莫尔(Adi Shamir)和伦纳德·阿德曼(LeonardAdleman)一起提出的)或ECC(Elliptical Curve Cryptography,椭圆曲线密码学)加密。具体的,服务端可以使用RSA私钥/ECC私钥α对数据加密,即对除了ID列的其它每个字段(即每个单元格中的数据)采用RSA私钥/ECC私钥α进行加密。
采用ECC加解密算法的情况下,具体的,服务端可以生成一个秘密值α并妥善保存,该秘密值α也就是ECC私钥。此外,服务端可以将name字段的值通过一个哈希函数转换为椭圆曲线上的一个点,可以表达为Hash(C)或表达为H(C)。
根据椭圆曲线上标量乘法的运算性质,椭圆曲线上的一个点P和一个整数k,计算Q=kP很容易,且得到的结果Q也是该椭圆曲线上的一个点;反之,如果知道椭圆曲线上的一个点对P、Q,求解Q=kP中使等式成立的k的值很难。
这里,根据椭圆曲线上的标量乘法运算α·H(C)很容易计算得到,但是知道α·H(C)的结果和H(C)却很难推算出α的值。很难得到α的值的情况下,知道α·H(C)的结果,也很难得到知道H(C)的值。
进而,服务端采用秘密值α加密后的数据库如下所示:
表2、服务端采用ECC私钥加密后的查询基
需要说明的是,上述hash函数,不仅能将原始输入转换为固定长度和格式的输出,还能将输出转换为椭圆曲线上的一个点的x轴坐标。例如采用curve25519这样的椭圆曲线,任意的256bits数据都可以作为这条椭圆曲线上的一个合法的x轴坐标。相应的,可以采用sha256或sha3-256,也可以采用sha384、sha512或者sha3-384、sha3-512的结果中截取256bits。更广泛的说,任意hash值(不局限于hash结果是256bits)可以对椭圆曲线的阶取模,取模结果与生成元点乘之积(标量乘法)即为该椭圆曲线上的一个点。
进而,服务端可以将该查询基发送至需要进行检索的客户端。一种方式中,服务端可以直接发送该查询基至客户端,例如直接发送至客户端的设备,或者发送至客户端的代理服务器之类;另一种方式中,服务端可以在一个统一资源定位系统(Uniform ResourceLocator,URL)上发布该查询基,进而客户端可以从该URL上获取该查询基。
相应的,客户端可以接收到该查询基,并将接收到的查询基保存在本地。
类似的,采用RSA的情况下,服务端可以生成一个秘密值α并妥善保存,该秘密值也就是RSA私钥。此外,服务端可以将name字段的值通过一个哈希函数转换为椭圆曲线上的一个点,可以表达为Hash(C)或表达为H(C)。
根据模幂运算的性质,已知秘密值α,对于一个大质数q和底数g,计算p=g
这里,根据模拟运算计算(H(C))
进而,服务端采用秘密值α加密后的数据库如下所示:
表3、服务端采用RSA私钥加密后的查询基
进而,服务端可以将该查询基发送至需要进行检索的客户端。类似的,服务端可以直接发送该查询基至客户端,例如直接发送至客户端的设备,或者发送至客户端的代理服务器之类;另一种方式中,服务端可以在一个统一资源定位系统(Uniform ResourceLocator,URL)上发布该查询基,进而客户端可以从该URL上获取该查询基。
相应的,客户端可以接收到该查询基,并将接收到的查询基保存在本地。
S110:客户端发送经自身加密的敏感字段至服务端,并通过与服务端的交互得到由服务端加密的同一敏感字段。
例如,客户端的检索条件为Age字段值为25,而25为敏感字段,即不希望让对端知道。为了避免让服务端知道客户端检索条件是Age字段的值25,客户端可以将该25加密。例如,采用RSA/ECC私钥加密,客户端采用的加密算法与服务端生成查询基采用的加密算法相同。
具体的,采用RSA私钥加密的情况下,客户端自身生成秘密β并妥善保存。进而,客户端可以采用自身私钥β对25加密。具体的,可以是对25或对25的hash值加密。这里以对25的hash加密为例加以说明,对25直接加密的情况类似,客户端与服务端采用相同的hash算法。例如,客户端采用与服务端相同的大质数q作为模数。客户端可以将对25采用β对25的hash值进行RSA加密,得到(H(25))
另一方面,客户端也可以构造检索语句,并将检索语句中的敏感字段加密后得到隐私字段,并用隐私字段替换敏感字段,将替换后的隐私检索语句发送至服务端。
例如,客户端构造的查询语句为select Name where Age=25。
为了保护隐私,即不让服务端获得查询的是Age=25这个条件,例如是将其中的25隐私保护起来,结果如下:
select Name where Age=?
其中,?表示替换后的检索语句。
具体的,客户端可以将25用RSA私钥加密。例如,客户端可以将对25采用与服务端相同hash函数进行hash计算,进而采用β对25的hash值进行RSA加密,得到(H(25))
select Name where Age=(H(25))
如前所述,(H(25))
采用ECC私钥加密的情况下,客户端采用与服务端相同的椭圆曲线,即具有相同的椭圆曲线参数和生成元。客户端自身生成秘密β并妥善保存。进而,客户端可以采用自身私钥β对25加密。具体的,可以是对25的hash值加密,客户端与服务端采用相同的hash算法。例如,客户端可以采用β对25的hash值进行ECC加密,得到β·H(25)。则客户端发送至服务端的敏感字段可以为β·H(25),其中,β·H(25)表示敏感字段的值25的密文。
另一方面,客户端也可以构造检索语句,并将检索语句中的敏感字段加密后得到隐私字段,并用隐私字段替换敏感字段,将替换后的隐私检索语句发送至服务端。
例如,客户端构造的查询语句为select Name where Age=25。
为了保护隐私,即不让服务端获得查询的是Age=25这个条件,例如是将其中的25隐私保护起来,结果如下:
select Name where Age=?
其中,?表示替换后的检索语句。
具体的,客户端可以将25用ECC私钥加密。例如,客户端采用与服务端相同的椭圆曲线,即具有相同的椭圆曲线参数和生成元。客户端可以将检索语句中的敏感字段用自身ECC私钥加密后替换,将替换后的隐私检索语句发送至服务端。例如客户端自身生成秘密β并妥善保存。此外,客户端可以将对25采用与服务端相同hash函数进行hash计算,进而采用β对25的hash值进行ECC加密,得到β·H(25)。则客户端发送至服务端的查询语句例如为如下:
select Name where Age=β·H(25)
如前所述,β·H(25)为密文,即为上面检索语句中的“?”代表的内容,服务端获得后并不能知晓其中的β和25。
所述客户端通过与服务端的交互得到由服务端加密的同一敏感字段,可以包括服务端采用自身密钥对由客户端加密的敏感字段再次加密后发送至客户端,客户端采用自身密钥对两次加密后的敏感字段解密得到由服务端加密的敏感字段。该内容的核心是需要找到一个满足连续两次加密操作(两方先后加密)可以交换顺序进行解密的加密算法。根据ECC的密码学性质,双方约定采用相同的椭圆曲线,即具有相同的椭圆曲线参数和生成元,各自持有私钥α和β,加密操作为用α(或β)进行标量乘法运算,不论先用α加密后用β加密还是先用β加密后用α加密,都可以用相同或不同的顺序解密,即可以对加密结果用不同的顺序解密。类似的,根据RSA的密码学性质加密,双方约定采用一个相同的大质数q和原根g,各自持有私钥α和β,加密操作为用α(或β)求幂并用q取模,不论先用α加密后用β加密还是先用β加密后用α加密,都可以用相同或不同的顺序解密,即可以对加密结果用不同的顺序解密。整体来说,这里客户端和服务端对同一目标执行的加/解密采用可交换顺序的加/解密算法。
具体的,可以是服务端收到隐私检索语句后,对隐私字段再次加密后返回至客户端,也可以是服务端收到客户端发送的经客户端自身加密的敏感字段后,服务端对加密的敏感字段再次用服务端自身密钥加密后返回至客户端。进而,客户端采用自身密钥对两次加密后的敏感字段解密得到由服务端加密的敏感字段。
例如,情况1:服务端可以接收到客户端发送的(H(25))
服务端可以对加密后的敏感字段(亦即隐私字段)再次加密,并将再次加密后的敏感字段返回至客户端。具体的,服务端可以对隐私字段(H(25))
例如,情况1':服务端可以接收到客户端发送的隐私检索语句select Name whereAge=(H(25))
服务端可以对隐私字段再次加密,并将再次加密后的隐私字段返回至客户端。
具体的,服务端可以对隐私字段(H(25))
例如,情况2:服务端可以接收到客户端发送的β·H(25)。
服务端可以对隐私字段再次加密,并将再次加密后的隐私字段返回至客户端。具体的,服务端可以对隐私字段β·H(25)采用自身的ECC私钥α进行再次加密,得到α·β·H(25)。
例如,情况2':服务端可以接收到客户端发送的隐私检索语句select Name whereAge=β·H(25)。这样,服务端可以获得该隐私检索语句中的隐私字段β·H(25)。
服务端可以对隐私字段再次加密,并将再次加密后的隐私字段返回至客户端。
具体的,服务端可以对隐私字段β·H(25)采用自身的ECC私钥α进行再次加密,得到α·β·H(25),具体过程类似上述,这里不再赘述。
服务端采用自身密钥对由客户端加密的敏感字段(即隐私字段)再次加密后发送至客户端后,客户端可以采用自身密钥对两次加密后的隐私字段解密得到由服务端加密的敏感字段。
例如,对应上面情况1和1',客户端接收到服务端发送的((H(25))
对应上面情况2和2',客户端接收到服务端发送的α·β·H(25),其中的标量乘法运算存在性质如下:α·β·H(25)=β·α·H(25)。进而,客户端可以采用自身私钥β的逆元β
需要说明的是,RSA中,根据欧拉定理,pk·sk=1mod(p-1)·(q-1),其中p和q两个大质数,所以pk和sk互为逆元。类似的,ECC中,pk=sk*G,G为ECC选定曲线上的的一个生成元,所以pk和sk也是互为逆元。
S120:客户端在查询基中根据所述由服务端加密的敏感字段检索,得到匹配记录的标识,并将该标识返回至服务端。
S110执行后,客户端可以得到由服务端加密的同一敏感字段。
客户端可以基于该由服务端加密的敏感字段在查询基中查询。例如,客户端解密后得到由服务端加密的隐私字段α·H(25)或(H(25))
所述客户端将匹配记录的标识返回至服务端,可以包括两种情况。
一种是S110中,客户端构造检索语句,并将检索语句中的敏感字段加密后得到隐私字段,并用隐私字段替换敏感字段,将替换后的隐私检索语句发送至服务端的情况。该情况下,客户端可以直接将匹配记录的标识返回至服务端。
另一种是S110中,客户端发送经自身加密的敏感字段的值至服务端的情况。该情况下,S120中,客户端可以构造检索语句,例如检索语句为:
select Name where ID=id_1
这样,S120中,客户端可以将构造的上述检索式发送至服务端,该检索式中包含了匹配记录的标识,并指示感兴趣的字段是Name,也就是select后面紧跟的字段名称。
换句话说,S110和S120这两个步骤中,可以选择在其中的一个步骤中发送检索式,该检索式中包含了感兴趣字段。
S130:服务端返回所述数据库中所述标识对应记录中的感兴趣字段的值至客户端。
仍然按照上述例子,服务端接收到客户端发来的标识后,可以在所述数据库中查找所述标识对应记录,并按照S110或S120的感兴趣字段取出查找到的记录中的相应值,并将该取出的感兴趣字段的值返回至客户端。例如,返回id_1对应记录中的Name=B,即返回B至客户端。
上述实施例中,通过将查询基预先配置到客户端的形式,实现不暴露数据库明文的情况下由客户端通过与服务端交互及查询基定位要查询的字段在查询基中的标识,进一步根据标识向服务端发起查询,得到标识对应记录中的感兴趣字段的值。相对于传统的多副本PIR,显然不需要多个副本数据库之间不能合谋的前提假设,实用性更好。相对于传统的单副本PIR中只能实现比特位检索的情形,本实施例不需要关注要检索的关键字在数据库中的具体位置(比特位置),可以实现字符串的查询,且可以支持结构化查询语句(Structured Query Language,SQL)。本实施例中数据库仍然保持在服务端,同时将数据库加密得到的查询基配置到客户端,以便于客户端检索时基于查询基进行数据定位以得到记录的标识,同时查询基的加密特性使得客户端不会获得数据库的内容,保证了服务端对数据库的隐私保护。整体来说,本实施例中数据库、查询基的形式,在一个服务端配置数据库和一个客户端配置查询基的情况下可以称为“非对称双副本”,在多个客户端配置查询基的情况下可以称为“非对称多副本”。
上述实施例中,通过SQL查询语句,客户端可以发起对感兴趣字段的查询,例如上述select Name...中要查询的Name字段。这在一定程度上暴露了客户端的感兴趣字段。另一种方式中,可以查询符合条件的记录,即符合条件的整行数据,这样可以保护客户端的隐私,但是需要服务端返回整条记录,这就一定程度上暴露了服务端的整行数据。例如S110/S120中通过“select*where Age=?”或“select*where ID=id_1”这样的检索语句。这样,服务端返回的结果可以是id_1这条的记录,例如如下:
id_1 B 25 shanghai
另外,为了保证传输过程的安全,所述服务端可以加密返回所述数据库中所述标识对应记录/对应记录中感兴趣字段的值至所述客户端。例如,服务端可以采用与客户端协商所得的对称密钥对数据库中所述标识对应记录/对应记录中感兴趣字段的值加密后返回至所述客户端,或者采用所述客户端的非对称密钥中的公钥对数据库中所述标识对应记录/对应记录中感兴趣字段的值加密后返回至所述客户端,从而客户端可以用自身私钥解密,以及采用数字信封方式等等。
上述S120中,客户端直接将匹配得到的ID返回至服务端,虽然可以从服务端获得该ID对应的记录或记录中的感兴趣字段,如S130,但是,这会一定程度上暴露客户端的隐私,即会让服务端知道客户端想查询的标识是id_1。为了保护客户端的隐私,可以通过下述实施例中的方式实现:
S210:客户端发送经自身加密的敏感字段至服务端,并通过与服务端的交互得到由服务端加密的同一敏感字段。
例如,客户端的检索条件为Age字段值为25,而25为敏感字段,即不希望让对端知道。为了避免让服务端知道客户端检索条件是Age字段的值25,客户端可以将该25加密。例如,采用RSA/ECC私钥加密,客户端采用的加密算法与服务端生成查询基采用的加密算法相同。
具体的,采用RSA私钥加密的情况下,客户端自身生成秘密β并妥善保存。进而,客户端可以采用自身私钥β对25加密。具体的,可以是对25或对25的hash值加密。这里以对25的hash加密为例加以说明,对25直接加密的情况类似,客户端与服务端采用相同的hash算法。例如,客户端采用与服务端相同的大质数q作为模数。客户端可以将对25采用β对25的hash值进行RSA加密,得到(H(25))
采用ECC私钥加密的情况下,客户端采用与服务端相同的椭圆曲线,即具有相同的椭圆曲线参数和生成元。客户端自身生成秘密β并妥善保存。进而,客户端可以采用自身私钥β对25加密。具体的,可以是对25的hash值加密,客户端与服务端采用相同的hash算法。例如,客户端可以采用β对25的hash值进行ECC加密,得到β·H(25)。则客户端发送至服务端的敏感字段可以为β·H(25),其中,β·H(25)表示敏感字段的值25的密文。
所述客户端通过与服务端的交互得到由服务端加密的同一敏感字段,可以包括服务端采用自身密钥对由客户端加密的敏感字段再次加密后发送至客户端,客户端采用自身密钥对两次加密后的敏感字段解密得到由服务端加密的敏感字段。该内容的核心是需要找到一个满足连续两次加密操作(两方先后加密)可以交换顺序进行解密的加密算法。根据ECC的密码学性质,双方约定采用相同的椭圆曲线,即具有相同的椭圆曲线参数和生成元,各自持有私钥α和β,加密操作为用α(或β)进行标量乘法运算,不论先用α加密后用β加密还是先用β加密后用α加密,都可以用相同或不同的顺序解密,即可以对加密结果用不同的顺序解密。类似的,根据RSA的密码学性质加密,双方约定采用一个相同的大质数q和原根g,各自持有私钥α和β,加密操作为用α(或β)求幂并用q取模,不论先用α加密后用β加密还是先用β加密后用α加密,都可以用相同或不同的顺序解密,即可以对加密结果用不同的顺序解密。整体来说,这里客户端和服务端对同一目标执行的加/解密采用可交换顺序的加/解密算法。
具体的,可以是服务端收到客户端发送的经客户端自身加密的敏感字段后,服务端对加密的敏感字段再次用服务端自身密钥加密后返回至客户端。进而,客户端采用自身密钥对两次加密后的敏感字段解密得到由服务端加密的敏感字段。
例如,情况1:服务端可以接收到客户端发送的(H(25))
服务端可以对加密后的敏感字段(亦即隐私字段)再次加密,并将再次加密后的敏感字段返回至客户端。具体的,服务端可以对隐私字段(H(25))
例如,情况2:服务端可以接收到客户端发送的β·H(25)。
服务端可以对隐私字段再次加密,并将再次加密后的隐私字段返回至客户端。具体的,服务端可以对隐私字段β·H(25)采用自身的ECC私钥α进行再次加密,得到α·β·H(25)。
服务端采用自身密钥对由客户端加密的敏感字段(即隐私字段)再次加密后发送至客户端后,客户端可以采用自身密钥对两次加密后的隐私字段解密得到由服务端加密的敏感字段。
例如,对应上面情况1,客户端接收到服务端发送的((H(25))
对应上面情况2,客户端接收到服务端发送的α·β·H(25),其中的标量乘法运算存在性质如下:α·β·H(25)=β·α·H(25)。进而,客户端可以采用自身私钥β的逆元β
需要说明的是,RSA中,根据欧拉定理,pk·sk=1mod(p-1)·(q-1),其中p和q两个大质数,所以pk和sk互为逆元。类似的,ECC中,pk=sk·G,G为ECC选定曲线上的的一个生成元,所以pk和sk也是互为逆元。
S220:客户端在查询基中根据所述由服务端加密的敏感字段检索,得到匹配记录的标识。
S210执行后,客户端可以得到由服务端加密的同一敏感字段。
客户端可以基于该由服务端加密的敏感字段在查询基中查询。例如,客户端解密后得到由服务端加密的隐私字段α·H(25)或(H(25))
S230:服务端采用不经意传输方式返回所述数据库中包含所述匹配标识在内的预定大小标识集合对应记录中的感兴趣字段的值至客户端。
S220中,客户端并不将匹配得到的ID返回至服务端,这样服务端无法获知客户端想要查找的是哪一条或哪几条记录;S210中客户端发送的经过客户端加密的敏感字段使得服务端也无法获知客户端查找的敏感字段将命中哪一条或哪几条记录,而只有客户端自己知道。这样,保护了客户端的隐私。但是,最终仍需要完成检索,这就需要服务端将客户端想查询的记录返回至客户端。
这里,服务端可以采用不经意传输方式。
不经意传输(Oblivious Transfer,OT)可以基于RSA、ECC等实现,可以实现2选1、n选1和m选1、m选k(k 首先,发送者生成两对不同的公私钥,并公开两个公钥,记这两个公钥分别为公钥1和公钥2。假设接收者希望知道m1,但不希望发送人知道他想要的是m1。接收者生成一个随机数r,再用公钥1对r进行加密,传给发送者。发送者用自身的两个私钥对这个加密后的r进行解密,用私钥1解密得到r1,用私钥2解密得到r2。显然,只有r1是和r相等的,r2则是一串毫无意义的数(也是解密结果)。但发送者不知道接收者加密时用的哪个公钥,因此发送者也不知道自己算出来的r1和r2中的哪个才是真的r。发送者接收到m1和m2后,用r1对m1进行对称加密,用r2对m2进行对称加密,并将两个对称加密结果发送至接收者。接收者本地具有的r=r1,所以接收者用r对发来的两个结果分别进行对称解密可以得到m1,但是无法解密得到m2,这是因为接收者所具有的r≠r2,接收者也就无法用正确的对称密钥进行解密得到m2的值。这个过程中,发送者也不知道接收者算出的是m1和m2中的哪一个。 有了2选1作为基础,可以将2个公私钥对扩展为n个公私钥对,就成为了n选1的OT。n选1的核心在于,服务端用n个不同密钥分别加密所述数据表中的n个记录/对应记录中感兴趣字段的值得到n个加密结果,并发送该n个加密结果至客户端;客户端采用匹配标识对应的密钥解密所述服务端发送的n个加密结果中匹配标识对应的1个加密结果。 结合本说明书上述实施例,假设服务端的数据表中具有总计n条记录,这样,客户端的查询基中相应的也具有n条加密的记录。为了方便,数据记录的ID按照顺序标识为id_0、id_1、id_2、...id_n-1。一个简单的实施流程如下: S231:服务端预先生成n对不同的公私钥对并公开公钥。 这里的n等于数据库中的记录的数量。 服务端生成n对不同的公私钥对(pk-sk;pk是publick key,表示公钥;sk是secretkey,表示私钥;公钥可以公开,私钥需要保密),例如分别是pk S232:客户端生成随机数r,并用期望获得的ID对应的公钥对r进行加密后发送至服务端。 这里假设客户端希望获得id_1的那条记录,同时不希望服务端知道客户端想要获得的记录是id_1的那条。这样,客户端可以采用pk S233:服务端接收到加密的r后,用n个私钥分别对其解密。 服务端分别用sk 显然,只有r1是和r相等的,因为只有用sk S234:服务端将数据库中每条记录按照序号采用对应序号的解密结果进行对称加密,将对称加密后的结果发送至客户端。 例如,服务端将id_0这条记录采用r0进行对称加密,将id_1这条记录采用r1进行对称加密,...,将id_n-1这条记录采用r(n-1)进行对称加密,并将这n个对称加密结果发送至客户端。 S235:客户端采用所述随机数r对所述对称加密结果中期望获得的ID对应的加密结果进行对称解密,得到检索结果。 客户端采用所述随机数r对所述对称加密结果中期望获得的ID对应的加密结果进行对称解密。具体的,例如上述S232中客户端期望获得的是id_1对应的那条记录/记录中的感兴趣字段的值,则客户端采用对应的公钥pk 当然,为了减少计算量,客户端可以仅采用所述随机数r对所述n个对称加密结果中期望获得的ID对应的加密结果进行对称解密,即客户端仅采用r对id_1的加密结果进行解密,从而获得id_1的对应记录/对应记录中感兴趣字段的值,而无须采用r对id_0、id_2、...、id_n-1这些对称加密结果进行对称解密,因为客户端可以知道这些加密结果并非采用r进行的对称加密,即使采用r进行对称解密也无法解出正确结果。 为了更清楚的呈现,这里对客户端采用所述随机数r对所述n个对称加密结果进行对称解密,进行如下解释: S234中,服务端用r0、r1、r2、...、r(n-1)分别对对应的id_0、id_1、...、id_n-1这些记录/记录中的感兴趣字段的值进行对称加密: Enc(id_0,r0),其中r0≠r; Enc(id_1,r1),其中r1=r; Enc(id_2,r2),其中r2≠r; ... Enc(id_n-1,r(n-1)),其中r(n-1)≠r; 上述Enc表示加密(Encrypt),Enc()括号中的前一部分的id_0、id_1、id_2、...、id_n-1表示n条记录/n条记录中感兴趣字段的值,后一部分的r0、r1、r2、...、r(n-1)表示加密密钥。 S235中,客户端采用随机数r对所述对S234中的加密结果进行对称解密。具体的,客户端采用所述随机数r对下述内容分别进行对称解密: Dec(Enc(id_0,r0),r),其中r0≠r; Dec(Enc(id_1,r1),r),其中r1=r; Dec(Enc(id_2,r2),r),其中r2≠r; ... Dec(Enc(id_n-1,r(n-1),r),其中r(n-1)≠r; 上述Dec表示解密(Decrypt),Dec()中的前一部分表示解密对象,这里也就是上面的加密结果,Dec()中的后一部分表示解密采用的密钥。 可见,客户端只能解密得到id_1的那条记录,而无法推测出其它记录。这是因为服务端只有对id_1的那条记录采用了随机数r进行对称加密,而对其它ID采用的并非随机数r进行的对称加密,而客户端也无法获得除r1=r以外的r0、r2、...、r(n-1)。 需要说明的是,S231可以是在S230之后,或者是在S230之前,这里并不限制。 上面是所述客户端在查询基中检索得到匹配记录的数量为1时,通过n选1不经意传输,将所述数据库中包含所述匹配标识在内的所有所述标识对应记录/对应记录中感兴趣字段的值传输至所述客户端。 上述实施例中,服务端并不知道客户端查询的是哪个或哪些ID,而是将数据库中的所有记录均加密返回至客户端,保护了客户端的隐私。但是,S233中,服务端用n个私钥分别对接收到加密的r进行解密,这样进行大量的非对称解密计算,需要消耗大量的CPU和内存资源。并且,S234中传输n个对称加密后的结果也将占用大量带宽。尤其是当n的数量比较大时,服务端的计算量较大,带宽占用也较大。 此外,可能匹配的结果大于1,例如为k条(k>1),则可以通过n选k不经意传输来实现。关于n选k,一种实现方案是将n个记录中的每k个组成一个集合,每个集合对应一个公私钥对,这样总计会有 需要说明的是,上述的r也可以是非对称密钥中的公钥,这样,客户端接收到由r加密的结果后,可以采用自身的私钥对其解密得到结果。即S234和S235中,服务端将id_0这条记录采用r0进行非对称加密,将id_1这条记录采用r1进行非对称加密,...,将id_n-1这条记录采用r(n-1)进行非对称加密,并将这n个加密结果发送至客户端,客户端接收到这些加密的结果后,可以采用自身私钥对其中期望获得的ID对应的加密结果进行非对称解密得到结果。下面也类似,不再重复。 基于此,本说明书给出以下增加了构造混淆集的一种实施方式: S310:客户端发送经自身加密的敏感字段至服务端,并通过与服务端的交互得到由服务端加密的同一敏感字段。 例如,客户端的检索条件为Age字段值为25,而25为敏感字段,即不希望让对端知道。为了避免让服务端知道客户端检索条件是Age字段的值25,客户端可以将该25加密。例如,采用RSA/ECC私钥加密,客户端采用的加密算法与服务端生成查询基采用的加密算法相同。 具体的,采用RSA私钥加密的情况下,客户端自身生成秘密β并妥善保存。进而,客户端可以采用自身私钥β对25加密。具体的,可以是对25或对25的hash值加密。这里以对25的hash加密为例加以说明,对25直接加密的情况类似,客户端与服务端采用相同的hash算法。例如,客户端采用与服务端相同的大质数q作为模数。客户端可以将对25采用β对25的hash值进行RSA加密,得到(H(25)) 采用ECC私钥加密的情况下,客户端采用与服务端相同的椭圆曲线,即具有相同的椭圆曲线参数和生成元。客户端自身生成秘密β并妥善保存。进而,客户端可以采用自身私钥β对25加密。具体的,可以是对25的hash值加密,客户端与服务端采用相同的hash算法。例如,客户端可以采用β对25的hash值进行ECC加密,得到β·H(25)。则客户端发送至服务端的敏感字段可以为β·H(25),其中,β·H(25)表示敏感字段的值25的密文。 所述客户端通过与服务端的交互得到由服务端加密的同一敏感字段,可以包括服务端采用自身密钥对由客户端加密的敏感字段再次加密后发送至客户端,客户端采用自身密钥对两次加密后的敏感字段解密得到由服务端加密的敏感字段。该内容的核心是需要找到一个满足连续两次加密操作(两方先后加密)可以交换顺序进行解密的加密算法。根据ECC的密码学性质,双方约定采用相同的椭圆曲线,即具有相同的椭圆曲线参数和生成元,各自持有私钥α和β,加密操作为用α(或β)进行标量乘法运算,不论先用α加密后用β加密还是先用β加密后用α加密,都可以用相同或不同的顺序解密,即可以对加密结果用不同的顺序解密。类似的,根据RSA的密码学性质加密,双方约定采用一个相同的大质数q和原根g,各自持有私钥α和β,加密操作为用α(或β)求幂并用q取模,不论先用α加密后用β加密还是先用β加密后用α加密,都可以用相同或不同的顺序解密,即可以对加密结果用不同的顺序解密。整体来说,这里客户端和服务端对同一目标执行的加/解密采用可交换顺序的加/解密算法。 具体的,可以是服务端收到客户端发送的经客户端自身加密的敏感字段后,服务端对加密的敏感字段再次用服务端自身密钥加密后返回至客户端。进而,客户端采用自身密钥对两次加密后的敏感字段解密得到由服务端加密的敏感字段。 例如,情况1:服务端可以接收到客户端发送的(H(25)) 服务端可以对加密后的敏感字段(亦即隐私字段)再次加密,并将再次加密后的敏感字段返回至客户端。具体的,服务端可以对隐私字段(H(25)) 例如,情况2:服务端可以接收到客户端发送的β·H(25)。 服务端可以对隐私字段再次加密,并将再次加密后的隐私字段返回至客户端。具体的,服务端可以对隐私字段β·H(25)采用自身的ECC私钥α进行再次加密,得到α·β·H(25)。 服务端采用自身密钥对由客户端加密的敏感字段(即隐私字段)再次加密后发送至客户端后,客户端可以采用自身密钥对两次加密后的隐私字段解密得到由服务端加密的敏感字段。 例如,对应上面情况1,客户端接收到服务端发送的((H(25)) 对应上面情况2,客户端接收到服务端发送的α·β·H(25),其中的标量乘法运算存在性质如下:α·β·H(25)=β·α·H(25)。进而,客户端可以采用自身私钥β的逆元β 需要说明的是,RSA中,根据欧拉定理,pk·sk=1mod(p-1)·(q-1),其中p和q两个大质数,所以pk和sk互为逆元。类似的,ECC中,pk=sk·G,G为ECC选定曲线上的的一个生成元,所以pk和sk也是互为逆元。 S320:客户端在查询基中根据所述由服务端加密的敏感字段检索,得到匹配记录的标识。 S310执行后,客户端可以得到由服务端加密的同一敏感字段。 客户端可以基于该由服务端加密的敏感字段在查询基中查询。例如,客户端解密后得到由服务端加密的隐私字段α·H(25)或(H(25)) S330:服务端采用不经意传输方式返回所述数据库中包含所述匹配标识在内的预定大小标识集合对应记录中的感兴趣字段的值至客户端。 S310中客户端发送的经过客户端加密的敏感字段使得服务端也无法获知客户端查找的敏感字段将命中哪一条记录,而只有客户端自己知道。这样,保护了客户端的隐私。但是,最终仍需要完成检索,这就需要服务端将客户端想查询的记录返回至客户端。 上述图2对应的实施例给出了n选1不经意传输的实现方式,这里,可以采用m选1的不经意传输,其中m 结合本说明书上述实施例,假设服务端的数据表中具有总计n条记录,这样,客户端的查询基中相应的也具有n条加密的记录。为了方便,数据记录的ID按照顺序标识为id_0、id_1、id_2、...id_n-1。一个简单的实施流程如下: S331:服务端预先生成n对不同的公私钥对并公开公钥。 服务端生成n对不同的公私钥对(pk-sk;pk是publick key,表示公钥;sk是secretkey,表示私钥),例如分别是pk S332:客户端生成包含期望获得ID在内的m大小的混淆集,并生成随机数r,并用期望获得的ID对应的公钥对r进行加密后与混淆集一并发送至服务端。 这里假设客户端希望获得id_1的那条记录,同时不希望服务端知道客户端想要获得的记录是id_1的那条,便生成m大小的混淆集,m=4时这个混淆集例如为:{id_1,id_2,id_3,id_4}。 这4个ID与公钥对例如存在以下对应关系: pk pk pk pk 客户端可以采用pk 此外,客户端可以将混淆集连同检索语句一并发送至服务端。这样,客户端可以采用pk select Name where ID={id_1,id_2,id_3,id_4}|Enc(r,pk 其中,“|”用于分割前面的检索语句和后面的加密后的随机数,下同。 S333:服务端接收到混淆集和加密的r后,用对应的m个私钥分别对加密的r进行解密。 服务端分别用sk 显然,只有r1是和r相等的,因为只有用sk 此外,服务端接收到混淆集{id_1,id_2,id_3,id_4}后,可以从混淆集中得知客户端想要获取的数据是混淆集中4个ID中的1个,但不确定是其中哪一个,从而保护了客户端隐私。 S334:服务端将混淆集中指定的记录采用对应序号的解密结果进行对称加密,将对称加密后的结果发送至客户端。 例如,服务端将id_1这条记录采用r1进行对称加密,将id_2这条记录采用r2进行对称加密,将id_3这条记录采用r3进行对称加密,将id_4这条记录采用r4进行对称加密,并将这4个对称加密结果发送至客户端。 S335:客户端采用所述随机数r对所述对称加密结果中期望获得的ID对应的加密结果进行对称解密,得到检索结果。 客户端采用所述随机数r对所述对称加密结果中期望获得的ID对应的加密结果进行对称解密。具体的,例如上述S332中客户端期望获得的是id_1对应的那条记录/记录中的感兴趣字段的值,则客户端采用对应的公钥pk 当然,为了减少计算量,客户端可以仅采用所述随机数r对所述4个对称加密结果中期望获得的ID对应的加密结果进行对称解密,即客户端仅采用r对id_1的加密结果进行解密,从而获得id_1的对应记录/对应记录中感兴趣字段的值,而无须采用r对id_2、id_3、id_4这些对称加密结果进行对称解密,因为客户端可以知道这些加密结果并非采用r进行的对称加密,即使采用r进行对称解密也无法解出正确结果。 上述S331~S335仅是示例性的一种实现方式。在另一种实现方式中,可以将混淆集的构建和传输与OT协议的执行进行解耦,用OT协议来传输密钥。具体的,一方面,客户端可以将m大小的混淆集发送至服务端,当然客户端知道m大小的混淆集中的第几个是真正想要获得的结果的标识,另一方面,服务端可以生成m个对称密钥,通过m选1的OT,客户端可以获得其中指定的一个对称密钥,即客户端获得真正想要获得结果的那个标识对应的对称密钥。这样,服务端可以将客户端混淆集中m个标识对应的记录采用对应的对称密钥加密后发送至客户端,从而客户端对其中真正想要获得的结果采用正确的对称密钥解密,从而得到结果。其中,服务端可以预先生成生成m个对称密钥,这样可以在进行OT交互之前批量完成密钥准备的工作,而不会占用OT协议执行的时间。 上面是所述客户端在查询基中检索得到匹配记录的数量为1时,通过m选1不经意传输,服务端将所述混淆集中指明的m个标识对应记录/对应记录中感兴趣字段的值传输至所述客户端。此外,可能匹配的结果大于1,例如为k条(k>1),则可以通过m选k不经意传输来实现。m选k不经意传输的核心在于,客户端构造m大小的混淆集并发送至服务端,1 以下介绍本说明书一实施例中的实现隐私信息检索的系统,包括服务端与客户端,客户端与服务端对同一目标执行的加/解密采用可交换顺序的加/解密算法,且: 所述服务端配置有数据库,并将该数据库加密后得到查询基,并发送该查询基至客户端; 在一次检索过程中: 所述客户端发送经自身加密的敏感字段至服务端,并通过与服务端的交互得到由服务端加密的同一敏感字段; 所述客户端在查询基中根据所述由服务端加密的敏感字段检索,得到匹配记录的标识; 所述服务端与所述客户端之间通过不经意传输方式将所述数据库中包含所述匹配标识在内的预定大小标识集合对应记录/对应记录中感兴趣字段的值传输至所述客户端。 以下介绍本说明书一实施例中的实现隐私信息检索的服务端,所述服务端与客户端对同一目标执行的加/解密采用可交换顺序的加/解密算法,且: 所述服务端配置有数据库,并将该数据库加密后得到查询基,并发送该查询基至客户端; 在一次检索过程中: 所述服务端接收所述客户端发送的经自身加密的敏感字段并再次加密后返回至所述客户端;所述服务端还与所述客户端之间通过不经意传输方式将所述数据库中包含所述匹配标识在内的预定大小标识集合对应记录/对应记录中感兴趣字段的值传输至所述客户端。 以下介绍本说明书一实施例中的实现隐私信息检索的客户端,该客户端与服务端对同一目标执行的加/解密采用可交换顺序的加/解密算法,且: 所述客户端配置有查询基,所述查询基由所述服务端将数据库加密后得到; 在一次检索过程中: 所述客户端发送经自身加密的敏感字段至服务端,并通过与服务端的交互得到由服务端加密的同一敏感字段;所述客户端还在查询基中根据所述由服务端加密的敏感字段检索,得到匹配记录的标识;所述客户端还与所述服务端之间通过不经意传输方式获得所述数据库中与所述匹配标识对应记录/对应记录中感兴趣字段的值。 在20世纪90年代,对于一个技术的改进可以很明显地区分是硬件上的改进(例如,对二极管、晶体管、开关等电路结构的改进)还是软件上的改进(对于方法流程的改进)。然而,随着技术的发展,当今的很多方法流程的改进已经可以视为硬件电路结构的直接改进。设计人员几乎都通过将改进的方法流程编程到硬件电路中来得到相应的硬件电路结构。因此,不能说一个方法流程的改进就不能用硬件实体模块来实现。例如,可编程逻辑器件(Programmable Logic Device,PLD)(例如现场可编程门阵列(Field Programmable GateArray,FPGA))就是这样一种集成电路,其逻辑功能由用户对器件编程来确定。由设计人员自行编程来把一个数字系统“集成”在一片PLD上,而不需要请芯片制造厂商来设计和制作专用的集成电路芯片。而且,如今,取代手工地制作集成电路芯片,这种编程也多半改用“逻辑编译器(logic compiler)”软件来实现,它与程序开发撰写时所用的软件编译器相类似,而要编译之前的原始代码也得用特定的编程语言来撰写,此称之为硬件描述语言(Hardware Description Language,HDL),而HDL也并非仅有一种,而是有许多种,如ABEL(Advanced Boolean Expression Language)、AHDL(Altera Hardware DescriptionLanguage)、Confluence、CUPL(Cornell University Programming Language)、HDCal、JHDL(Java Hardware Description Language)、Lava、Lola、MyHDL、PALASM、RHDL(RubyHardware Description Language)等,目前最普遍使用的是VHDL(Very-High-SpeedIntegrated Circuit Hardware Description Language)与Verilog。本领域技术人员也应该清楚,只需要将方法流程用上述几种硬件描述语言稍作逻辑编程并编程到集成电路中,就可以很容易得到实现该逻辑方法流程的硬件电路。 控制器可以按任何适当的方式实现,例如,控制器可以采取例如微处理器或处理器以及存储可由该(微)处理器执行的计算机可读程序代码(例如软件或固件)的计算机可读介质、逻辑门、开关、专用集成电路(Application Specific Integrated Circuit,ASIC)、可编程逻辑控制器和嵌入微控制器的形式,控制器的例子包括但不限于以下微控制器:ARC 625D、Atmel AT91SAM、Microchip PIC18F26K20以及Silicone Labs C8051F320,存储器控制器还可以被实现为存储器的控制逻辑的一部分。本领域技术人员也知道,除了以纯计算机可读程序代码方式实现控制器以外,完全可以通过将方法步骤进行逻辑编程来使得控制器以逻辑门、开关、专用集成电路、可编程逻辑控制器和嵌入微控制器等的形式来实现相同功能。因此这种控制器可以被认为是一种硬件部件,而对其内包括的用于实现各种功能的装置也可以视为硬件部件内的结构。或者甚至,可以将用于实现各种功能的装置视为既可以是实现方法的软件模块又可以是硬件部件内的结构。 上述实施例阐明的系统、装置、模块或单元,具体可以由计算机芯片或实体实现,或者由具有某种功能的产品来实现。一种典型的实现设备为服务器系统。当然,本说明书不排除随着未来计算机技术的发展,实现上述实施例功能的计算机例如可以为个人计算机、膝上型计算机、车载人机交互设备、蜂窝电话、相机电话、智能电话、个人数字助理、媒体播放器、导航设备、电子邮件设备、游戏控制台、平板计算机、可穿戴设备或者这些设备中的任何设备的组合。 虽然本说明书一个或多个实施例提供了如实施例或流程图所述的方法操作步骤,但基于常规或者无创造性的手段可以包括更多或者更少的操作步骤。实施例中列举的步骤顺序仅仅为众多步骤执行顺序中的一种方式,不代表唯一的执行顺序。在实际中的装置或终端产品执行时,可以按照实施例或者附图所示的方法顺序执行或者并行执行(例如并行处理器或者多线程处理的环境,甚至为分布式数据处理环境)。术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、产品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、产品或者设备所固有的要素。在没有更多限制的情况下,并不排除在包括所述要素的过程、方法、产品或者设备中还存在另外的相同或等同要素。例如若使用到第一,第二等词语用来表示名称,而并不表示任何特定的顺序。 为了描述的方便,描述以上装置时以功能分为各种模块分别描述。当然,在实施本说明书一个或多个时可以把各模块的功能在同一个或多个软件和/或硬件中实现,也可以将实现同一功能的模块由多个子模块或子单元的组合实现等。以上所描述的装置实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。 本说明书是参照根据本说明书实施例的方法、装置(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。 这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。 这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。 在一个典型的配置中,计算设备包括一个或多个处理器(CPU)、输入/输出接口、网络接口和内存。 内存可能包括计算机可读介质中的非永久性存储器,随机存取存储器(RAM)和/或非易失性内存等形式,如只读存储器(ROM)或闪存(flash RAM)。内存是计算机可读介质的示例。 计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(PRAM)、静态随机存取存储器(SRAM)、动态随机存取存储器(DRAM)、其他类型的随机存取存储器(RAM)、只读存储器(ROM)、电可擦除可编程只读存储器(EEPROM)、快闪记忆体或其他内存技术、只读光盘只读存储器(CD-ROM)、数字多功能光盘(DVD)或其他光学存储、磁盒式磁带,磁带磁磁盘存储、石墨烯存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。按照本文中的界定,计算机可读介质不包括暂存电脑可读媒体(transitory media),如调制的数据信号和载波。 本领域技术人员应明白,本说明书一个或多个实施例可提供为方法、系统或计算机程序产品。因此,本说明书一个或多个实施例可采用完全硬件实施例、完全软件实施例或结合软件和硬件方面的实施例的形式。而且,本说明书一个或多个实施例可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。 本说明书一个或多个实施例可以在由计算机执行的计算机可执行指令的一般上下文中描述,例如程序模块。一般地,程序模块包括执行特定任务或实现特定抽象数据类型的例程、程序、对象、组件、数据结构等等。也可以在分布式计算环境中实践本本说明书一个或多个实施例,在这些分布式计算环境中,由通过通信网络而被连接的远程处理设备来执行任务。在分布式计算环境中,程序模块可以位于包括存储设备在内的本地和远程计算机存储介质中。 本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于系统实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本说明书的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。 以上所述仅为本说明书一个或多个实施例的实施例而已,并不用于限制本本说明书一个或多个实施例。对于本领域技术人员来说,本说明书一个或多个实施例可以有各种更改和变化。凡在本说明书的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在权利要求范围之内。
- 一种舌象检测方法、装置、客户端、服务器及系统
- 一种文件系统快照回滚后客户端缓存失效的实现方法
- 一种软件客户端自动登录的方法、装置及互联网服务器
- 一种实现隐私信息检索的方法、系统、服务器和客户端
- 一种实现隐私信息检索的方法、系统、服务端和客户端