一种基于词向量的人车关联分析方法
文献发布时间:2023-06-19 18:34:06
技术领域
本发明公开了一种人车关联分析方法,尤其涉及一种基于词向量的人车关联分析方法,属于计算机应用技术领域。
背景技术
随着我国经济实力的快速增长及人民群众出行需求的急剧增加,中国道路交通运输行业实现了跨越式发展。中国机动车保有量、驾驶人数量、道路里程持续增长。然而,伴随而来的是我国的交通安全面临着极大挑战,现有警力和交通指挥设施已无法适应交通管理和城市发展需求,机动车交通违法行为日益增多,与车辆相关的刑事案件和治安案件数量不断增加,道路交通中行人的违法行为屡见不鲜。因此,利用大数据、人工智能等新一代信息技术实现交通大数据的智能分析,对违法行为进行提前预判、精准打击,是解决我国交通安全问题的重要手段。
人车关联分析是智慧交通安全事件处理的关键问题,通过大量的交通数据建立人与车的关联关系,能够实现通过车牌号获取到驾驶人的手机信息,或者借助手机信息获取到车辆信息,再借助手机位置数据了解驾驶人的运动轨迹,并关联驾驶人基本信息实现违法行为的提前侦测和预判。因此,人车关联分析意义重大。当前的人车关联分析主要是通过建立时空轨迹向量,然后利用相似度方法计算轨迹之间的相似度实现匹配。然而,这种方法通常不考虑轨迹中时间因素的影响,也就是说在不同时间中出现的类似轨迹也可能被认为是相似轨迹,会导致匹配错误。
发明内容
本发明的目的是针对上述问题,提供一种基于词向量的人车关联分析方法。该方法将手机的IMSI码和车牌号形成配对,然后利用词嵌入模型进行训练,分别获取IMSI码和车牌号的向量,然后利用相似度匹配方法计算IMSI码和车牌号的相似度进行匹配。该方法能有效解决时间因素带来的影响,有效提高人车关联的准确率。
为实现上述目的,本发明的技术方案是:
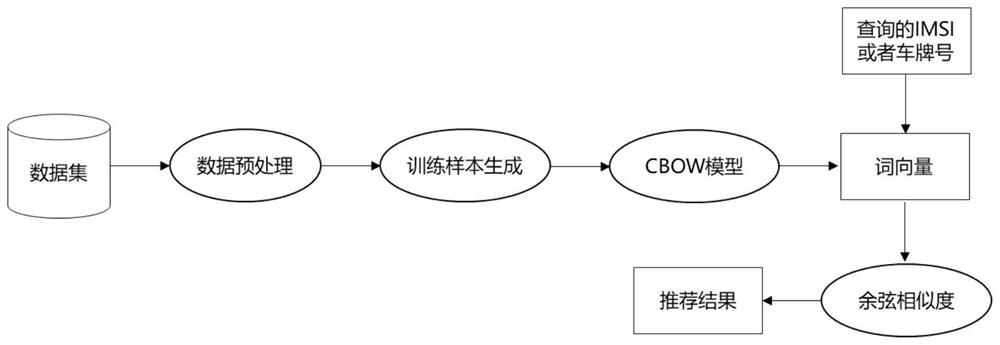
一种基于词向量的人车关联分析方法,包括以下步骤:
步骤1:交通卡口通过两种不同的现有设备分别收集手机的IMSI码和车辆的车牌号,分别使用S=(s
步骤2:由于交通拥堵情况或者交通事故带来的影响,卡口中收集的数据可能存在大量的重复数据,同时常驻人口和常驻车辆会对最终的关联分析产生影响,因此需要对数据进行预处理,删除大量重复数据。具体实现如下:
步骤2-1、常驻人口数据移除:
如果某个IMSI码在连续的指定的一段时间ConTime内被捕捉至少num次,则从S中删除所有与该IMSI码有关的数据;同理,如果某个车牌号码在连续的指定的一段时间ConTime内被捕捉至少num次,则从R中删除所有与该车牌号有关的数据。
步骤2-2、无效数据过滤:
如果某个IMSI码或者车牌号仅在一个卡口中被捕获,则删除与该IMSI码或者车牌号有关的所有数据。
步骤2-3、将经过预处理的数据集合表示为S'=(s'
步骤3:训练样本数据生成:
将同一个卡口的S'和R'中的数据按时间段进行切分。以00:00:00为起始时间,设置时间间隔gap,将所有在该时间间隔gap内收集到的IMSI码和车牌号形成一条样本数据d,将所有卡口形成的样本数据的集合表示为D=(d
步骤4:每一个样本d
步骤5:初始化CBOW模型中的参数矩阵W
步骤6:定义CBOW在固定的窗口大小z下利用中心词的上下文向量预测这个中心词的向量。假设中心词向量为V
步骤7:隐藏层的向量表示h再根据CBOW中另一参数矩阵W'
步骤8:CBOW的实际输出与真实的目标输出相差较大,CBOW模型采用反向传播算法持续优化参数矩阵W
步骤9:对于任意两个单词t
步骤10:输入一个车牌号码(或IMSI码),将所有IMSI码(或车牌号)根据相似度从大到小进行排序,得到最终的推荐结果序列。
与现有技术相比,本发明的有益效果在于:
本发明涉及的基于词向量的人车关联分析方法,可以有效获取人车的关联关系,提高问题求解效率。本发明中通过将手机IMSI码和车牌号码形成配对,并利用词嵌入方法进行训练,分别获取IMSI码和车牌号码的词向量,可以有效避免时间因素带来的影响。另外通过对数据规模进行约简,有效降低算法计算代价。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明提出的基于词向量技术的人车关联分析方法流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
数据源:通过在深圳市部分交通路口部署设备,收集了5天内的交通数据。总共包含56个卡口,其中仅21个卡口包含车牌号数据。每个卡口收集到的IMSI码和车牌号相关数据条数存在较大区别,总共收集到了15,815,764条数据,其中涉及IMSI码的数据条数为14,968,620条,涉及车牌号的数据条数为847,144条。总计涉及158,496个不同车牌号和1,248,597个不同的手机IMSI码。
步骤1:交通卡口通过两种不同的设备分别收集手机的IMSI码和车辆的车牌号,分别使用S=(s
步骤2:由于交通拥堵情况或者交通事故带来的影响,卡口中收集的数据可能存在大量的重复数数据,同时常驻人口和常驻车辆会对最终的关联分析产生影响,因此需要删除这些数据。
步骤2-1,常驻人口数据移除,如果某个IMSI在连续的一段时间ConTime(ConTime=2小时)内被捕捉至少num(num=5)次,则从S中删除所有与该IMSI码有关的数据;同理,如果某个车牌号码在连续的一段时间ConTime内被捕捉至少num次,则从R中删除所有与该车牌号有关的数据。
步骤2-2,无效数据过滤,如果某个IMSI码或者车牌号仅在一个卡口中被捕获,则删除该IMSI码或者车牌号的所有相关数据。
步骤2-3、将经过预处理的数据集合表示为S'=(s'
步骤3:训练样本数据生成,将同一个卡口的S'和R'中的数据按时间段进行切分。以00:00:00为起始时间,设置时间间隔gap(gap=5分钟),将所有在该时间段收集到的IMSI码和车牌号形成一条样本数据d,将所有卡口形成的样本数据的集合表示为D=(d
步骤4:每一个样本d
步骤5:初始化CBOW模型中的参数矩阵W
步骤6:定义CBOW在固定的窗口大小z(z=50)下利用中心词的上下文向量预测这个中心词的向量。假设中心词向量为V
步骤7:隐藏层的向量表示h再根据W'
V
其中V
步骤8:实际的输出与真实的输出相差较大,CBOW模型采用反向传播算法持续优化W
最终得到W
步骤9:对于任意两个单词t
步骤10:输入一个车牌号码(或IMSI码),将所有IMSI码(或车牌号)根据相似度从大到小进行排序,得到最终的推荐结果序列。
- 一种基于雷达的人车识别门禁系统及方法
- 一种基于加窗词向量特征的短文本情感分析方法
- 一种基于大数据的人车关联分析系统及方法
- 基于轨迹相似度匹配的人车关联分析方法及系统