一种代价优化的类不平衡二元自相关过程异常识别算法
文献发布时间:2023-06-19 19:27:02
技术领域
本发明属于机器学习中不平衡数据集代价敏感型分类方法技术领域,涉及一种代价优化的类不平衡二元自相关过程异常识别算法。
背景技术
机器学习技术在人工智能领域的兴起,为制造过程的质量控制带来了新的思路。其中一种是控制图模式识别(CCPR),它将统计过程状态定义为正常模式和异常模式,并使用机器学习方法来识别这些模式,以判断过程是否失控,并识别发生了何种异常。由于二元自相关过程的CCPR在实际生产中的普遍存在,近几十年来对它也进行了一定程度的研究。例如,Hwang和Wang提出了一种基于神经网络的监测双变量自相关过程的模型,实验证明该模型在检测中小均值漂移方面优于传统的控制图。Fountoulaki和Karacapilidis提出了一种由多个神经网络组成的混合模型,用于在线检测二元自相关过程异常,得到了较好的结果。Yu Wei和Bo提出了一种用于二元自相关过程控制的粒子群优化随机森林(RF)模型,并通过实验验证了其较好的性能。
在实际生产中通常很难获得足够多的异常过程模式样本,大多数关于CCPR的研究都使用蒙特卡罗模拟方法来生成合成数据用于训练和测试其模型。然而,一个被忽视的重要事实是,在工业环境中通常存在着分布不均匀,即可用的异常模式样本数明显少于正常模式样本数。结果,训练的识别模型将偏向正常模式(多数类或反类),导致异常模式(少数类或正类)的较差性能。鉴于二元自相关过程在实际生产中的广泛存在,我们对其进行了不平衡学习研究,提出了一种基于CSLSTM的过程模式识别模型。并不是简单地根据两类之间的不平衡率(IR)来确定二分类模型的误分类代价参数,而是引入了粒子群优化(PSO)算法。
发明内容
针对上述问题,本发明提供一种代价优化的类不平衡二元自相关过程异常识别算法,提出了一种粒子群优化的代价敏感长短期记忆模型(PSO-CSLSTM),用于识别不平衡数据集上的二元自相关过程模式。
为实现上述目的,本发明采用以下技术方案。
一种不平衡二元自相关过程异常识别的优化代价算法,包括以下步骤:
步骤1:利用Mont-Carlo仿真生成二元自相关过程类别不平衡的四种模式数据集D;
步骤2:按照一定比例将数据集D划分为训练集S、验证集G和测试集T;
步骤3:基于训练集S和验证集G,利用PSO计算最优相对代价参数,并训练出多个两分类CSLSTM作为基分类器;
步骤4:将训练好的两分类CSLSTM通过OVR策略构建成多分类模型,基于测试集T进行性能测试。
优选的,所述步骤1中利用Mont-Carlo仿真方法合成二元自相关过程模式样本集对模型进行训练和测试,仿真不同数量的正常样本(4000)和异常样本(每种偏移幅度的样本数为50),反映过程模式数据集的类别不平衡,其中,三种异常模式为S-X
优选的,所述步骤2中按照比例(6∶2∶2)划分为训练集S、验证集G和测试集T。通过训练集S训练分类器,验证集G得出相对代价值,再应用测试集对模型进行测试并与对比模型进行比较。
优选的,所述步骤3PSO方法获取四个二分类器的相对代价值,选用AUC
优选的,所述步骤4中构建有四个两分类器,选择OVR方法来构造多分类模型。
优选的,所述步骤4评价PSO-CSLSTM模型的最终效果,并与对比模型进行比较。
与现有技术对比,本发明具备以下优异效果:
在CCPR的实际应用中,通常只能获得不平衡数据集来训练分类模型。也就是说,异常模式样本的数量远少于正常模式样本的数量。提出了一种代价优化的类不平衡二元自相关过程异常识别算法。该模型采用代价敏感的LSTM作为基本的二分类模型,通过OVR策略构建多类分类器,其关键代价参数由PSO确定。基于Mont-Carlo模拟方法生成的非平衡二元自相关过程模式数据集的一系列实验验证了该模型的有效性。结果表明,该模型在专门为多类不平衡学习定义的几个性能指标上优于属于浅层学习模型或深度学习模型的一些其他比较模型。此外,基于粒子群算法的误分类代价参数优化也是一种有效的代价敏感分类策略。
附图说明
图1是二元自相关过程的四种基本模式示意图;
图2是基于OVR方法构建MCS-LSTM模型示意图;
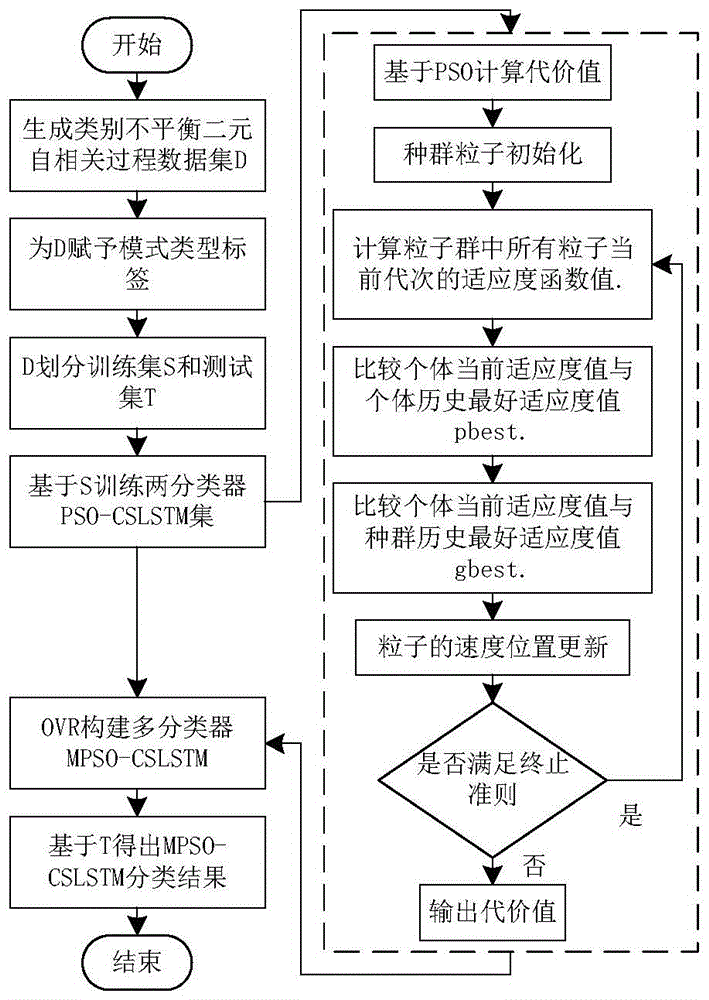
图3是类不平衡二元自相关过程异常识别的优化代价过程图;
图4是PSO优化的收敛过程图;
图5是优化前后ROC曲线对比图。
具体实施方式
下面对本发明的较佳实施例进行详细阐述,以使本发明的优点和特征能更易于被本领域技术人员理解,从而对本发明的保护范围做出更为清楚明确的界定。
一种代价优化的类不平衡二元自相关过程异常识别算法,包括以下步骤:
步骤1:利用Mont-Carlo仿真生成二元自相关过程类别不平衡的四种模式数据集D;
步骤2:按照一定比例将数据集D划分为训练集S、验证集G和测试集T;
步骤3:基于训练集S和验证集G,利用PSO计算最优相对代价参数,并训练出多个两分类CSLSTM作为基分类器;
步骤4:将训练好的两分类CSLSTM通过OVR策略构建成多分类模型,基于测试集T进行性能测试。
所述步骤1中利用Mont-Carlo仿真方法合成二元自相关过程模式样本集对模型进行训练和测试,仿真不同数量的正常样本(4000)和异常样本(每种偏移幅度的样本数为50),反映过程模式数据集的类别不平衡,其中,三种异常模式为S-X
表1数据集的具体参数
所述步骤2中按照比例(6∶2∶2)划分为训练集S、验证集G和测试集T。通过训练集S训练分类器,验证集G得出相对代价值,再应用测试集对模型进行测试并与对比模型进行比较。
所述步骤3PSO方法获取四个二分类器的相对代价值,选用AUC
表2:两类分类问题的成本矩阵
步骤3.2:直接确定IR值为代价参数,这种做法并不总是有效的方法,尽管它确实容易实施,因为除了不平衡率之外,通常还有许多影响因素可能导致分类性能的恶化,例如小样本量,类重,存在噪声和边界实例。因此,将IR粗略地设置为不能在两个类之间获得最优的性能折衷,甚至严重损害多数类的准确性,而不能有效地提高少数类的准确性。
粒子群算法(PSO)作为一种经典的智能搜索优化算法被应用于估计成本参数的最优值。该值被定义为粒子群算法的粒子,并在每次迭代中更新,然后引入到CS-LSTM的训练过程中,CS-LSTM在给定验证数据集上获得的AUC
v(t+1)=ωv(t)+c
x(t+1)=x(t)+v(t+1) (2)
成本参数优化过程如图3所示。粒子群算法被用于这项研究,以确定每个OVR个体分类器的相对代价参数。首先,将一群粒子(种群规模等于30)初始化为随机分布的0.5~2倍IR的值,然后在适应度值的指导下进行粒子群优化迭代,直到实现收敛。在我们的研究中,粒子群优化算法重复了30次,选择了其中5次效果显著的粒子群优化算法绘制收敛过程曲线图。由于篇幅所限,图4中只给出了OVR个体分级机与其余分级机之间的曲线图。可以看出,适应度值(AUC
为了验证粒子群优化算法对误分类代价参数的优化是否真的有效,我们在图5中对比了每个OVR个体分类器及其优化的代价参数的ROC曲线,以及同一分类器的代价参数粗略设置为IR值的ROC曲线。从曲线可以看出,优化后的四个OVR个体分类器都得到了改善,因为优化后的分类器的曲线可以包围未优化的分类器的曲线。特别是计算的AUC
如图2所示,所述步骤4中构建有四个两分类器,选择OVR方法来构造多类别模型。步骤4.1:代价敏感策略主要是针对二分类模型提出的,不容易推广到多类分类模型。随着类别数量的增加,解决分类问题将变得更加困难,尤其是在同时存在多个多数类或少数类的不平衡数据的情况下。因此,通常采用分解策略将多类分类问题转化为一组简单的两类分类问题来求解。
步骤4.2:不平衡多分类问题的特点主要体现在类别间和多类别间样本数量的不平衡。类别之间样本数量的不平衡导致训练的分类模型偏向大多数类别。为了将CSLSTM应用于类别不平衡的多类型分类,一种有效的方法是构建基于二分类CSLSTM的多分类模型。
步骤4.3:二分类模型构造多分类模型常用的分解策略有OVO方法和OVR方法。考虑到OVR方法只需要构造与类别数量相同的二元分类器,在效率上具有优势,这远远少于OVO方法,并且对于在线识别异常过程模式是必不可少的,我们选择OVR方法来构造多类别模型。
步骤4.3:评价PSO-CSLSTM模型的最终结果,结合相对代价值,引入CSLSTM模型,构建PSO-CSLSTM模型。
基于表3所示的多类混淆矩阵来计算不平衡多类分类的性能评估度量。首先,通过公式(3)-(6)从多类混淆矩阵计算每个OVR个体分类器的四个宏观指标。
表3:多类混淆矩阵
TP
/>
基于四个宏观指标,通过公式(7)-(10)计算四个度量,即Precision
选取的对比模型包括两种,一种是代价敏感的浅层学习模型,另一种是代价敏感的深度学习模型。对于第一种,我们具体选择了CSDT(代价敏感决策树)、CSLR(代价敏感逻辑回归)和CSSVM(代价敏感支持向量机)。同时,选择CSCNN(代价敏感卷积神经网络)作为对比深度学习模型。粒子群算法也被应用到这些模型中,以获得它们的对应的优化成本参数,即PSO-CSDT,PSO-CSSVM,PSO-CSLR和PSO-混CSCNN。对每个模型进行训练,以获得具有相同训练数据集和测试数据集的多类混淆矩阵,如表4所示。在此基础上,如表5所示,根据公式(7)-(10)计算出各自的性能度量。
表4:比较模型的混淆矩阵
表5:多分类评价指标比较
从表5可以看出,所提出的PSO-CSLSTM模型获得了四个性能度量中的三个的最佳值。因此,该模型对于非平衡数据集下的二元自相关过程的模式识别具有优越性。同时,我们可以看到,该模型在精度上和PSO-CSSVM相同。这可能是因为生成的数据集的规模不是很大,SVM擅长小样本学习。所提出的模型可以在更大的数据集上获得更好的性能。此外,与根据IR值粗略确定相比,通过PSO优化成本参数,每个模型在每个性能指标上都有一定程度的改进。这清楚地表明,粒子群优化方法确定误分类成本参数工作良好。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 一种检测二元自相关过程异常的代价敏感层次分类模型
- 一种风力发电机组启机过程异常识别算法