考虑不确定状态的序列化决策智能体实现系统及方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及的是一种神经网络应用领域的技术,具体是一种考虑不确定状态的序列化决策智能体实现系统及方法。
背景技术
在当前的大数据和信息化背景下,受限于海量数据和用户有限的手动调控能力,往往需要序列化决策智能体协助用户完成各种优化目标。如在工业自动化领域、互联网工业领域和自动驾驶领域,用户会利用序列化决策智能体进行实时调控达成工业参数调控、流量分配、自动驾驶等目标。序列化决策智能体的效率和优化问题非常重要。
构建序列化决策智能体的问题,其任务是在未来环境未知的前提下,根据观测到的反馈信息,实时调整策略来提升最终优化效果。近年来,很多基于该思想的序列化决策方法被提出。这些构建方法大都假设决策智能体能够实时观测到真实反馈,从而合理的调整实时决策策略。但是,现有的决策智能体,都忽略真实环境中的反馈延迟性带来的特征不确定性,不论这些策略调控方法的理论效果如何,若其无法获得真实的反馈,决策的效果便会大打折扣。
反馈特征不确定性,是线上真实环境区别于离线理想环境的一条重要性质。它是由真实环境反馈的复杂性和随机性所决定的。以互联网工业领域为例,独立运营者们使用自动决策智能体制定策略,从而竞争流量来达成转化效果。但是竞得的流量是否会发生转化行为,转化行为何时发生,都具有较大的不确定性。转化行为的延迟可长达几小时甚至几天,这对具有高反馈实时性要求的序列化决策智能体的决策效果有较大的影响,会带来优化效果的损失,并且增加超限风险。
所述的独立运营者是指互联网中具有流量需求的特殊用户,其会和其他独立运营者竞争流量,以达成引流效果,从而达成自己的转化目标。
所述的竞争过程是指平台接收到每位独立运营者的竞争策略后,会按一定的规律分配流量,并扣除胜者相应的费用。
所述的转化是指独立运营者引流的诉求,如“带货网红”类独立运营者定义的转化行为是流量发生购买行为。
所述的超限风险是指独立运营者会为决策智能体设置单位转化成本,即竞得一次转化所需的花费。而因为种种原因,序列化决策智能体的竞拍结果导致真实的单位转化成本超过独立运营者设置的预期值,则被称为超限现象。超限现象意味着序列化决策智能体没有很好的完成目标任务,是其设计中应当考虑的重点。
发明内容
本发明针对现有技术存在的上述不足,提出一种考虑不确定状态的序列化决策智能体实现系统及方法,在进行序列化决策时利用特征分布与强化学习方法,通过构建智能体,以较低的复杂度成本,显著的提高智能体序列化决策时的优化效果。
本发明是通过以下技术方案实现的:
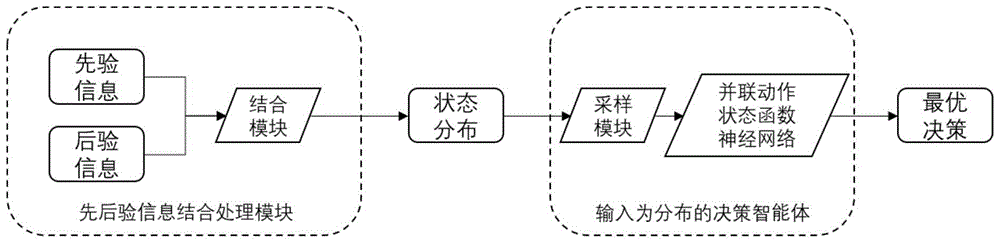
本发明涉及一种考虑不确定状态的序列化决策智能体实现系统,包括:前后验信息结合处理模块、输入为分布的决策智能体模块,其中前后验信息结合处理模块根据先验的预估信息和后验的真实反馈信息,进行两种信息的综合利用处理,得到转化量和单位转化成本参数的分布;输入为分布的决策智能体模块根据单位转化成本参数的分布信息,从其中进行采样获得对应的离散分布,并将分布输入并联的动作状态神经网络中,就得到参考不确定状态下的最优决策。
本发明涉及一种基于上述系统的考虑不确定状态的序列化决策智能体实现方法,包括:
步骤1、结合前链路传递的先验转化信息、智能体真实观测的后验转化信息和即时反馈信息,利用转化延迟分布模型得到当前智能体竞得流量的单位转化成本的分布。
所述的前链路传递的先验转化信息是指:互联网工业领域中,在智能体决策之前,平台会提供给其某一条流量i的预估转化率pcvr
所述的真实观测的后验转化信息是指:在智能体竞得一条流量后,在某一时刻观测该流量转化结果,若可以观测到流量转化,称为正后验信息;尚未观测到该流量转化,称为负后验信息。
所述的即时反馈信息是指:智能体的实时花费,决策周期剩余的时间等信息,这些信息具有即时反馈性和确定性。
所述的转化延迟分布模型是指:在流量最终转化的前提下,流量转化延迟的分布,即当流量最终发生转化,其转化延迟小于τ
步骤2、对序列化决策问题进行形式化建模,并利用强化学习方式获得确定状态下的解。
所述的形式化建模指是指:在离线阶段将所有流量属性已知的决策问题建模成线性规划问题,在存在预算约束与单位转化成本约束的前提下,智能体尽量多的选取高性价比的流量,具体为:优化目标:
所述的线性规划问题在离线环境中存在最优解,最优决策形式为
所述的所有流量属性已知是指利用往期数据构建的模拟环境,其中智能体能够获知全天内的所有流量的价值信息v
所述的强化学习方式是指:将形式化建模得到的线性规划问题进一步建模为马尔科夫决策过程(MDP)问题,再使用策略(Policy)深度神经网络和动作状态函数(Q value)深度神经网络近似拟合该决策过程,具体为:对于t+1时刻的状态s
所述的策略深度神经网络根据智能体当前所处状态,得到智能体策略动作,当智能体获知当前的状态s时,其参考该深度神经网络确定决策动作。
所述的动作状态函数深度神经网络根据智能体当前所处状态与智能体的决策动作,得到动作状态函数值的深度神经网络,当智能体获得当前的状态s时,其可以获知每一种决策a所对应的剩余时间收益和,为Q(s,a),其中Q(s,a)即为对应状态s和决策动作a下的动作状态函数。
步骤3、考虑当前状态的不确定性,参考当前状态的离散分布,利用不确定状态理论,结合强化学习模型中的动作状态函数深度神经网络,构建序列化决策智能体用于协助独立流量运营者在平台开展的流量分配环境中进行资源分配决策。
所述的状态不确定性是指:在真实环境中,某些物理量的反馈存在延迟(如单位转化成本信息),决策智能体无法获取当前的准确状态。而决策智能体依赖实时状态进行决策。可以使用对应的分布信息表达该物理量的不确定性。
所述的离散分布是指:对于有限的N个可能的状态,智能体可以获知其当前所处特定状态s
所述的不确定状态理论是指:
技术效果
本发明利用转化延迟联系前后验信息;输入为分布形式的能够处理不确定状态的决策模型。相比现有技术,本发明达成了对于相关参数的更准确估计,并构建出参数的可能分布;达成了更加稳定和高效的决策方式,独立运营者竞得流量的转化效果,并且可以减少独立运营者的超限现象。
附图说明
图1为本发明实施的流程图。
图2为实施工业场景的示意图。
图3为实施例效果示意图
具体实施方式
如图1所示,为本实施例涉及一种考虑不确定状态的序列化决策智能体实现系统及方法,包括:
第一步、结合前后验信息构建单位转化成本的分布:序列化决策智能体需要参考实时转化量和单位转化成本信息进行决策。在智能体对于已竞得流量的最终转化量的估计过程中,有效信息包括先验信息和后验信息。先验信息为预估转化率,相对确定,后验信息会随着时间发展不断演化,具体包括:
1.1)对于已经发生点击的流量,引入事件
1.2)对于流量在t时刻的转化总量的预估重新定义为
1.3)在上述物理意义的等价下计算得:
1.4)经过上述建模后,转化量总量表达为异质独立伯努利变量的累加和形式,可以通过中心极限定理还原为分布形式,该分布为最终转化总量可能结果的分布;转化总量分布呈现出高斯分布的形式,表达智能体对于环境不确定性的认知;单位转化成本的分布由实时花费除以上述转化量分布得到。
第二步、把参考单位转化成本的决策过程建模成不确定状态下的连续决策问题,具体为:经过上述建模后则将在线决策问题重新建模为存在状态不确定性的序列决策问题。可以据此设计考虑输入状态为分布形式的序列化决策智能体。
本实施例中包括序列化决策算法GQOUS,具体是指:根据优化问题的约束条件,使用强化学习的方式构建确定性环境下的决策模型:该模型将当前所处状态作为参考,进行决策,具体步骤包括:
i)借助Yue He等人在《A Unified Solution to Constrained Bidding inOnline Display Advertising》(KDD’2020)一文中提出的训练过程和方法,构建确定性环境下的动作状态函数模型。初始化模型参数,使用往期样本,令模型在模拟环境中不断与环境进行交互,进行确定性模型的训练。设置惩罚项来进行模型行为调控。获得确定性条件下的决策模型和对应的动作状态函数模型Q(s,a),留作备用。
ii)在线的不确定环境中,序列化决策智能体观测到当前的状态分布信息。智能体从该连续分布中进行分位数采样,获得该状态分布对应的离散分布b(s)。
iii)智能体参考离散分布进行决策,对于离散分布中N个可能的状态s
iv)获得能使全局动作状态函数取得最大值决策动作a
所述的往期样本指某一天内的流量记录,其中包括每条流量的预估点击率、预估转化率、赢得该流量所需的决策等。
所述的模拟环境指利用一天内的往期样本,模拟智能体进行在线决策竞争流量的过程。
所述的惩罚项指若智能体在模拟环境中模拟结果出现超限现象,应当对其获得的收益进行相应削减,为超限控制的目的。
所述的确定性条件指不存在反馈延迟的理想条件,在该条件下智能体可以准确的获得其决策依赖的所有信息。
经过具体实际实验,在一个模仿线上环境的仿真工业场景中,该场景提供一天内的百万量级流量信息,包含每条流量的时间、预估点击率、预估转化率以及竞得该流量所需的花费等信息。在试验中,为贴合线上环境的转化行为特征,为其中模拟的转化赋予稀疏性和延迟性。设置USCB算法的policy模型和Q-value模型作为对比项,设置GQOUS算法为实验项。构建两类对比实验:
实验一:统计1000个不同流量分配场景的平均效果,每个流量分配场景运行一次;实验二:重复同一流量分配场景1000次,考察1000次的平均效果,共取5个场景作对比。
所述的实验中的稀疏性是指对模拟竞得的流量的点击和转化结果通过0-1采样获得,
此处采样依据的参数是流量的预估点击率和预估转化率;
所述的实验中的延迟性是指对于判定为转化的流量,根据延迟分布随机赋予其转化延迟,智能体只有持有该流量的时间超过该延迟才能观测到其转化。
如表1所示,为模拟实验的5个流量分配场景重复1000次平均结果的比较。对比USCB算法的策略深度神经网络、动作状态函数深度神经网络与GQOUS算法的效果。其中参数G为相对转化量值,P为超限率值。从表中可以看出,相比于其他两种方法,GQOUS算法构建的决策智能体在单流量分配场景的平均意义上具有更高转化量收益,且能够有效降低超限率。
表1
如表2所示,为模拟实验的1000个不同流量分配场景的平均效果的比较。其中参数G为相对转化量值,P为超限率值。从图中可以看出,GQOUS算法构建的智能体在不同广告计划上提高在天级别的竞得转化量结果,并且显著降低计划超限率。从中可以得出结论,GQOUS算法构建的序列化决策智能体具有较强的范化性和通用性。
表2
如图3所示,为GQOUS算法和其他两种算法对应智能体在1000次重复单一场景的实验中的最终转化量结果统计。从图中可以看出,GQOUS算法的竞得转化量的数量普遍较高,转化结果的众数为2,其最终结果具有更高的稳定性。从中可以得出结论,GQOUS的优化效果更高,且鲁棒性优秀。
与现有技术相比,本发明通过前后验信息结合的方法,构建出了当前的状态分布,令智能体对当前状态的认知更加清晰;再通过输入为分布的决策智能体,可以在存在延迟反馈的环境中,显著提高决策智能体的优化效果,并降低超限现象(指最终的单位转化成本大于独立运营者预设的值)发生的概率;实现离线训练和线上推理过程的解耦,引入的额外计算代价非常低;实现简单,可以部署到现有的强化学习决策框架中。
上述具体实施可由本领域技术人员在不背离本发明原理和宗旨的前提下以不同的方式对其进行局部调整,本发明的保护范围以权利要求书为准且不由上述具体实施所限,在其范围内的各个实现方案均受本发明之约束。
- 考虑预测不确定性的机票购买决策方法和系统
- 考虑源荷双重不确定性的电力系统多阶段鲁棒机组组合决策方法
- 一种考虑决策依赖不确定的电力系统运行可靠性评估方法