一种基于深度学习的安全头盔佩戴标准判断方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及计算机数字图像处理技术领域,尤其涉及一种基于深度学习的安全头盔佩戴标准判断方法。
背景技术
目标检测是常见的图像处理任务之一,基于深度学习技术的当前目标检测方法已成为主流。因此,为了确保建筑工地人员在生产和施工中的生产活动的安全性,可以将目标检测算法应用于头盔佩戴的检测。图像和视频场景中的物体检测任务一直是计算机视觉和图像处理领域的研究热点。同时,生产和施工安全是社会高度关注的话题。物体检测是计算机视觉领域的三个基本任务之一,它与图像处理的另外两个基本任务:图像分类和图像语义分割并行不悖。物体检测是指在输入图像中寻找目标物体。它包括两个子任务:物体分类和物体定位。它不仅需要识别图像中目标物体的类型,还需要标定物体在图像中的位置,从而实现对物体类别的判断和物体定位的目的。
基于传统方法的目标检测方法过程过于复杂:需要获取前景目标信息或使用滑动窗口遍历图像中的各个尺度和像素,然后提取候选区域的特征信息,再利用提取的图像特征建立数学模型或使用支持向量机(SVM)和AdaBoost等分类器来识别特征信息。传统的目标检测方法包括基于像素的方法、基于特征匹配的方法、基于频域的方法和基于识别的方法。传统的目标检测方法存在一些缺点:例如,基于滑动窗口的目标区域检测方法耗时长,窗口冗余;基于人工提取的特征信息在面对环境条件变化时鲁棒性较差;对于大数据,视频或图片信息的处理能力差,计算能力有限。这些缺点决定了传统的目标检测方法只能在特定的背景下,在单一的场景下达到一定的效果。但在开放环境中,在角度变化、光照不足、天气变化等客观因素的影响和干扰下,其检测的准确性和正确性难以保证,模型的泛化能力差。此外,基于传统目标检测方法的人工特征设计需要依赖大量的先验知识,具有一定的主观性,而且三步检测过程繁琐、复杂,计算成本高,不能满足实时性要求。
近年来,随着人工智能领域的快速发展,计算机视觉作为人工智能的一个重要研究方向,也迎来了第三次高潮。计算机科学技术对我们的生活有很大的影响,如数学建模,医疗,贸易隐私,人机交互,工业,新媒体和社会交流等等。深度学习在计算机视觉中发挥着越来越重要的作用。智能人机交互的应用场景很多。目标检测是计算机视觉领域的一个研究热点。大量基于卷积神经网络(CNN)的优秀目标检测算法取得了巨大成功。这也为目标检测的未来发展方向和产业落地提出了新的研究思路。
在建筑施工现场,施工人员进入工地佩戴安全帽是安全生产建设中必要的安全措施。安全帽不仅可以抵消一部分高空坠物的冲击力,还可以降低施工人员从高空坠落后头部的碰撞程度,甚至可以挽救施工人员的生命。目前,一些建筑工地出现伤亡事故,其根本原因是施工人员没有按照操作规范进行作业。由于天气炎热、疏于监管等各种客观因素,在很多实际的施工现场,工人往往忽视了这些安全规定,出现了不佩戴安全头盔的情况时有发生。作为构建安全生产视频监控的一项重要技术,安全帽佩戴检测对于煤矿、变电站、建筑工地等实际高危作业现场场景具有非常重要的应用价值和意义。
虽然普通的后台监控可以在一定程度上缓解这种违规操作,但也会增加企业的人力和经济成本,而且长期人工监控容易产生疲劳,导致监控责任的疏忽、遗漏或误判。同时,人工监控方式具有一定的主观性,被监控人员的情绪和状态、工作经验、性格、生活状况等,安全判断容易产生强烈的主观性,公平性难以保证,监督职能能否最终落实也难以保证。研究表明,当一个人同时观察两个监控屏幕时,他将在10分钟内错过45%的有用信息,22分钟内错过95%的有用信息。同时观察多个监控屏幕会造成更多的分心。因此,人工肉眼监控有很大的局限性。
因此,迫切需要一种针对复杂施工现场场景的自动化、智能化安全帽检测算法,对施工现场情况进行全面实时检测。一旦发现违规操作并及时报警,达到实时纠错的目的,避免施工风险和隐患。从而保证现场施工的安全。
目前,国内外一些学者已经对安全帽的识别进行了研究。由于安全帽最明显的特征是颜色特征,所以大多数研究工作集中在利用颜色信息进行安全帽检测。Du等人提出了机器学习和图像处理相结合的方法用于视频序列中的安全帽检测。他们的工作主要有三个部分:第一部分是基于Haar-like面部特征的人脸检测;第二部分是运动检测和皮肤颜色检测,以减少误报;第三部分是面部区域上方的颜色信息被用于头盔检测。Park等人使用定向梯度直方图(HOG)特征进行行人检测,然后使用颜色直方图进行头盔检测。Wen等人提出了一种称为改进的Hough变换的圆圈检测方法,该方法被用于ATM监控系统中的安全头盔检测。Rubaiyat和Toma等人首先将图像的频域信息与流行的人体检测算法,即直方图梯度图相结合,用于检测建筑工人,然后使用颜色和圆圈。虽然已经取得了一定的成果,但根据不同的外部环境,安全帽检测算法的识别率容易受到影响。总的来说,国内外对安全帽检测方法的研究是一致的。现有的方法可以实现特定场景下对安全帽的检测和识别,但仍存在环境要求高、应用场景单一、识别率波动大、易受环境干扰等问题。难以满足人体卧姿、躺姿、弯腰等一系列问题,如半蹲、多姿、多目标的识别,因此检测和识别环境适应性不高强、检测精度不高的问题。
发明内容
针对现有技术中所存在的不足,本发明基于深度学习技术,在YOLOv3算法的基础上进行改进,结合图像处理技术对图像特征进行分析,提供了一种改进的头盔自动识别算法,解决了现有技术中检测和识别环境适应性不高强、检测精度不高的问题。
根据本发明的实施例,一种基于深度学习的安全头盔佩戴标准判断方法,其包括如下步骤:
步骤一,获取视频流并解码成若干帧图片;
步骤二,将步骤一中获取的每一帧图片发生到识别网络以识别头盔并检测头盔的位置;
步骤三,经判断未戴头盔则判断为不符合佩戴标准,反之则将人的头部位置用不同颜色的预测框标注成锚定框区域;
步骤四,对步骤三中的锚定框区域进行像素统计,将人的头部位置正常佩戴时各种颜色头盔的颜色像素比例的经验阈值进行细化,对头盔进行预测和判断,将头盔像素比例低的锚定框区域去除,归为不符合佩戴标准,并在图片上标注;
其中,识别网络包括YOLO v3网络。
进一步地,还包括步骤五,根据下式进行判断:
Z=η(y)·α+η(r)·β,
式中:α和β分别为权重系数,η(y)是YOLOv3网络的目标对象识别输出的置信度,η(r)是像素特征统计的结果,Z为头盔标准佩戴检测的置信度:Z处于正常范围内,判断为符合安全头盔的戴标准,反之判断为不符合安全头盔标准。
进一步地,YOLO v3网络包括Darknet-53和YOLO层,其中Darknet-53用于提取图像特征,Darknet-53包括53个卷积层,输入图像被缩放为416×416,并被送到Darknet-53网络进行特征提取。
进一步地,Darknet-53特征提取网络输出四种比例的特征图,大小分别为13×13、26×26、52×52和104×104。
进一步地,用于预测的是尺寸为13×13的特征图,然后将其上采样为26×26的特征图,在卷积过程中,上采样后的特征图与尺寸为26×26的特征图相结合,作为第二次预测,用这种方法得到尺寸为52×52和104×104的特征图,作为第三和第四次预测,然后通过FPN,不同尺度的特征图被融合,多尺度策略被用来帮助网络模型同时学习不同层次的特征信息,最后,融合后的特征被输入到YOLO层进行类别预测和边界框回归。
进一步地,YOLO v3使用锚框机制来预测目标边界框,并对标记的边界框的大小进行K-均值聚类,得到一组具有固定大小的初始候选框,YOLO v3在数据集上使用K-均值聚类算法,得到九组先验框:(10,13)、(16,30)、(33,23)、(30,61)、(62,45)、(59,119)、(116,90)、(156,198)、(373,326)。
进一步地,对于输入图像,YOLO v3根据特征尺度将其划分为S×S网格,每个网格分别预测目标,以预测三个不同大小的边界框,以及四个偏移坐标和边界框的置信度,所以每个网格得到的张量大小如下:
S×S×[3×(a+b+N)],
式中:a表示预测边界框的坐标(t
进一步地,当目标的中心位置落在某个网格中时,网格负责预测目标的边界框信息,并输出相对位置(t
Confidence=Pr(object)×CIoU,
式中:Pr(object)用于判断是否将要检测到的目标包括在预测的边界框中,在获得所有预测的边界框后,设置一个阈值,删除置信度较低边界框,然后在其他边界框上执行非最大抑制,以获取目标边界框。
进一步地,CIoU的计算公式如下:
/>
式中:b,b
进一步地,对于每个网格,到坐标偏移量(c
b
b
式中:t
相比于现有技术,本发明具有如下有益效果:
改进了YOLOv3网络结构,引入多尺度融合和多规模预测机制;修改算法模型分类器的最后一层;通过K-均值聚类方法维度聚类确定模板框的数量;增加不同尺度的特征图的类型和数量,以提高小目标对象的检测能力;引入Complete-IoU(CIOU)损失功能,以使训练过程迅速融合;将深度学习方法与传统图像特征处理方法的组合结合起来,提高了预测的准确性。
附图说明
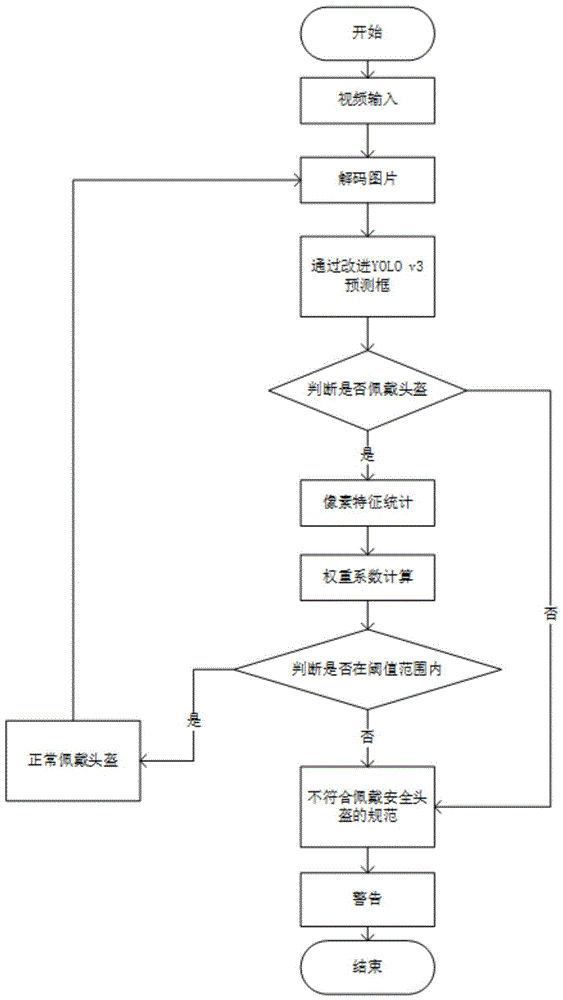
图1为本发明实施例的原理流程图。
具体实施方式
下面结合附图及实施例对本发明中的技术方案进一步说明。
如图1所示,本实施例提供了一种基于深度学习的安全头盔佩戴标准判断方法,具体实施时可由本领域技术人员采用计算机软件技术运行,方法包括如下步骤:
步骤1,从监控终端设备输入视频流,然后将视频流解码成若干帧图片;
步骤2,将由步骤1获得的每一帧图片发送到优化的YOLOv3网络,用于识别头盔和检测头盔的位置;
步骤3,YOLOv3包括特征提取部分和目标预测部分,主要包括Darknet-53和YOLO层,作为一个骨干网络,Darknet-53主要用于提取图像特征;Darknet-53是一个全卷积网络,包含53个卷积层,并引入了一个残差结构;首先,输入图像被缩放为416×416,并被送到Darknet-53网络进行特征提取,Darknet-53特征提取网络输出三种比例的特征图,大小分别为13×13、26×26、52×52;
为了进一步提高对小目标位置的检测精度,提高对不同尺寸检测目标的感知和灵敏度,改进YOLOv3的多尺度预测模块,采用13×13、26×26、52×52、104×104的特征图尺寸进行特征学习,进一步地,本申请将下采样的较小的特征图上采样到最大尺寸的特征图,然后进行卷积,以提高网络对较小目标的检测能力;
首先用于预测的是尺寸为13×13的特征图,然后将其上采样为26×26的特征图,在卷积过程中,上采样后的特征图与尺寸为26×26的特征图相结合,作为第二次预测,用这种方法得到尺寸为52×52和104×104的特征图,作为第三和第四次预测,然后通过FPN,不同尺度的特征图被融合,多尺度策略被用来帮助网络模型同时学习不同层次的特征信息,最后,融合后的特征被输入到YOLO层进行类别预测和边界框回归;
YOLOv3使用锚框机制来预测目标边界框,并对标记的边界框的大小进行K-均值聚类,得到一组具有固定大小的初始候选框,YOLOv3在数据集上使用K-均值聚类算法,得到九组先验框:(10,13)、(16,30)、(33,23)、(30,61)、(62,45)、(59,119)、(116,90)、(156,198)、(373,326);
对于输入图像,YOLOv3根据特征尺度将其划分为S×S网格,每个网格分别预测目标,可以预测三个不同大小的边界框,以及四个偏移坐标和边界框的置信度,所以每个网格得到的张量大小如下:
S×S×[3×(a+b+N)](1)
在上面的公式中,a表示预测边界框的坐标(t
Confidence=Pr(object)×IoU(2)
在公式中,Pr(object)用于判断是否将要检测到的目标包括在预测的边界框中,它是1时,如果不是,则为0,IoU是预测边界框和标签边界框的交点比,虽然IoU计算方法对目标尺度具有鲁棒性,能够较好地反映回归得到的目标边界盒的质量,但仍存在两个问题:第一种情况是,在损失函数中,当预测的边界盒和标注的边界盒不重叠时,梯度为0,此时,梯度在训练过程中消失,无法继续优化;第二种情况是,当预测边界框与标注边界框的IoU相同时,检测效果可能有较大差异;
根据图像算法理论,可以知道边界盒回归与预测边界盒和标签边界盒的重叠面积、中心点距离和长宽比有关,但IoU只考虑了重叠面积这个因素,而忽略了中心点距离和长宽比这两个几何因素,这种考虑是不够的,方法也是不合适的;因此,在充分考虑重叠面积、中心点距离和长宽比三个因素的基础上,本申请提出用CIoU的计算方法来代替原来YOLOv3坐标回归损失计算的均方误差函数,CIoU的计算公式如下:
/>
上式中,b,b
Confidence=Pr(object)×CIoU(6)
在获得所有预测的边界框后,设置一个阈值,删除置信度较低边界框,然后在其他边界框上执行非最大抑制(NMS),以获取目标边界框;
对于每个网格,到坐标偏移量(c
b
b
其中t
修改算法模型的最后一层的分类器,采用K-均值聚类方法,通过维度聚类确定锚框的数量k,k是一个超参数;
在本发明中,只有戴头盔或不戴头盔两种情况,这个具体任务的网络结构被修改:最终输出张量维度被修改为3×(5+2)=21,它可以减少网络运算量,提高目标检测模型的准确性和速度,其中,3=12/4(12是锚框的数量,4是不同尺度的特征图的类别数量),5是指每个预测框的坐标信息(x、y、w、h)和置信度,2是分类的数量;
步骤4,如果由步骤3中改进后的YOLOv3判断被框物体为头盔类,则进一步对预测框标注区域进行像素统计,将人的头部位置正常佩戴时各种常见颜色头盔的颜色像素比例的经验阈值进行细化,对头盔进行预测和判断,将头盔像素比例低的锚定框区域去除,归为不符合佩戴标准,并在图片上标注;
根据视觉识别系统的规定,在一般建筑工地场景中,头盔有四种颜色:白色(领导者),蓝色(经理),黄色(建筑工人)和红色(外部人员):
表1安全帽颜色阈值表
表1显示了这四个头盔的颜色阈值:计数并输出上述RGB值阈值间隔中预测的锚框区域中的像素数,并计算出满足按要求的像素的比例,这些像素的比例达到了总体数量的像素总数锚框区域;
步骤5,综合考虑改进后的YOLOv3网络的置信度和像素特征统计,通过分配相应的权重,输出头盔是否规范佩戴的最终结果并在图片上显示,设置两个系数重量α和β,然后将它们乘以预测的锚框置信度以及预设颜色像素与锚框像素像素(像素特征统计)的总面积的比率,以获得头盔标准佩戴检测的置信度,值范围为(0,1),然后对其进行判断:
Z=η(y)·α+η(r)·β(11)
η(y)是YOLOv3网络的目标对象识别输出的置信度,而η(r)是像素特征统计的结果,分别乘以其重量和重量,最后,获得一个值Z,然后判断Z是否在正常阈值范围内,如果Z在正常阈值范围内,可以判断为符合安全头盔的戴标准;否则,它可以判断为不符合安全头盔标准;最后,根据判断结果,发出警告信息,以及时纠正不符合安全头盔标准的行为。
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
- 一种基于深度学习的驾驶员安全带佩戴识别方法
- 基于多任务深度学习的骑行人员未佩戴头盔行为检测方法
- 一种安全头盔佩戴检测系统及安全头盔