一种在复杂噪声环境下的高度不平衡分类方法
文献发布时间:2023-06-19 19:30:30
所属技术领域
本发明涉及在复杂噪声环境下的不平衡分类应用技术领域,具体涉及一种在复杂噪声环境下的高度不平衡分类方法。
背景技术
高度不平衡分类问题是指数据集中多数类样本与少数类样本的比值大于9的分类问题。它在日常生活中一直都很常见,如在金融风控项目中,逾期的用户比例总是远远小于未逾期的用户比例。所以,会导致模型偏向多数类样本的贡献,从而忽略少数类样本所富含的丰富信息,特别是混有噪声的高度不平衡数据会使得模型预测错误。但是现有方法都只考虑到单个噪声情形下的高度不平衡问题,与现实世界中噪声大都是复杂噪声相矛盾。因此,本发明提出了首个关于复杂噪声结合高度不平衡数据的处理模型。
复杂噪声一般是由服从不同概率分布的多种噪声叠加而成。针对复杂噪声的处理,现有的方法有:如出自《IEEE图像处理汇刊》的论文:He et al.【He R,Zhang Y,Sun Z,et al.Robust subspace clustering with complex noise[J].IEEE Transactions onImage Processing,2015,24(11)(出版日):4001-4013.(期刊号)】,主题翻译为“复杂噪声下的鲁棒子空间聚类”,该论文提出了鲁棒子空间聚类方法,并利用非凸逆熵来处理复杂噪声;又如出自《模式识别》的论文:Guo et al.【Guo X,Xie X,Liu G,et al.Infraredsmall-dim target detection based on Markov random field guided noise modeling[J].Pattern Recognition,2019(出版年),93:55-67.(期刊号)】,主题翻译为“基于马尔可夫随机场引导噪声模型的红外弱小目标检测”,该论文借助了有限混合指数(MoEP)分布来处理复杂噪声;再如出自《IEEE地球科学与遥感汇刊》的论文:Zhang et al.【Zhang C,vander Baan M.Seismic signal matching and complex noise suppression by Zernikemoments and trilateral weighted sparse coding[J].IEEE Transactions onGeoscience and Remote Sensing,2020(出版年),60:1-10.(期刊号)】,主题翻译为“矩和三边加权稀疏编码的地震信号匹配和复杂噪声抑制”,该论文采用了在修改的块匹配框架内使用三边加权稀疏编码(TWSC)方法来对复杂噪声的进行衰减处理。以上论文提出的方法,都是针对与图像领域以及地理领域,但是对于不平衡分类领域,目前仅限于研究单个噪声以及单个噪声结合高度不平衡数据集或者混合噪声结合不平衡数据集,主要有以下4种方法:1、出自《信息科学》的论文:RSMOTE【Chen B,Xia S,Chen Z,et al.RSMOTE:A self-adaptive robust SMOTE for imbalanced problems with label noise[J].InformationSciences,2021(出版年),553:397-428.(期刊号)】,主题翻译为“一种用于带有标签噪声的不平衡问题的自适应鲁棒SMOTE(Synthetic Minority Oversampling Technique)合成少数类过采样技术”,该论文引入相对密度与绝对密度计算样本的混度程度,并按照混度程度赋予少数类别样本一定权重,依据权重在安全区域内生成更多的样本,混度区域内生成少量样本;2、出自《基于知识的系统》的论文:SW框架【Li M,Zhou H,Liu Q,et al.SW:Aweighted space division framework for imbalanced problems with label noise[J].
Knowledge-Based Systems,2022(出版年),251:109233.(期刊号)】,主题翻译为“一种用于带标签噪声的不平衡问题的加权空间划分框架”,该论文采用自适应完全随机树方法,通过给予少数类实例权重以便于辨别少数类实例中存在的噪声信息,考虑到噪声的生成问题,SW框架根据权重计算出新实例产生的位置,使得样本位于安全位置;3、先验合成过采样技术,出自《信息科学》的论文:(NRAS)【Rivera W A.Noise reduction a priorisynthetic over-sampling for class imbalanced data sets[J].InformationSciences,2017(出版年),408:146-161.(期刊号)】,主题翻译为“针对类不平衡数据集的一种带降噪的先验合成过采样方法”,该论文提出了在新实例产生之前先对少数类样本集进行降噪处理后,删除少数类样本集合中被视为噪声的样本点,并按照不平衡比率f从其余的少数实例群体中生成新的样本点;4、出自《信息科学》的论文:UFFDFR【Zheng M,Li T,ZhengX,et al.UFFDFR:Undersampling framework with denoising,fuzzy c-meansclustering,and representative sample selection for imbalanced dataclassification[J].Information Sciences,2021(出版年),576:658-680.(期刊号)】,主题翻译为“具有去噪、模糊c均值聚类和不平衡数据分类代表性样本选择的欠采样框架”,该论文提出首先将原始数据集划分为多数类样本和少数类样本,然后将划分后的多数类样本进行去噪、模糊c均值聚类以及代表性样本选择三个阶段处理,最后将处理好的多数类样本与少数类样本重新结合生成新的训练集,减少噪声为数据集带来的干扰。然而,纵观以上4种方法,在高度不平衡分类领域对于复杂噪声的处理,目前,还尚未有解决方法。
综上所述,目前的工作进展可以分为以下4方面:1)只针对复杂噪声进行削减处理;2)只针对单一噪声进行降噪处理;3)只针对高度不平衡数据进行平衡处理;4)单一噪声联合高度不平衡数据集进行建模;4)混合噪声结合不平衡数据集抑制复杂噪声。现有的方法大多都是对于图像处理、医学数据等方面的复杂噪声进行处理,据我们所知,针对复杂噪声结合高度不平衡数据集的情况尚未出现。因此,关于复杂噪声结合高度不平衡数据集的问题有待解决。
发明内容
本发明所解决的技术问题是:针对现有的技术方法的不足,提出了一种在复杂噪声环境下的高度不平衡分类方法,作为迄今为止第一个提出处理带有复杂噪声的高度不平衡数据集的分类器,不需要引入额外的参数,而且简单、高效、适用于任何场景;作为复杂噪声样本分类器,减少了数据冗余;作为高度不平衡数据分类器,有效地区分了多数类与少数类以及混合样本的边界,提高了模型的泛化能力。
为了解决以上技术问题,本发明采用的技术方案为:
一种在复杂噪声环境下的高度不平衡分类方法,包括以下步骤:
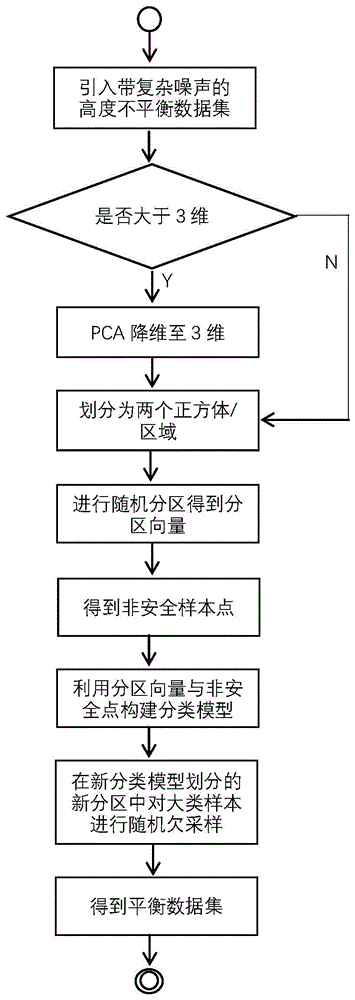
步骤1):设有高度不平衡数据集D,其中M表示多数类样本,N表示少数类样本,通过PCA把D降维到三维空间中,然后将这个三维空间划分为两个相同大小的相连接的正方体,同时判断降维之后的样本点属于哪一个正方体,进而将样本点划分到正确的正方体中;
步骤2):对划分后的每个正方体内部的特征空间进行随机划分为k个分区,k的计算方法为:
并从划分后每个分区中选择一个分区向量来表示其特征,分区向量s
其中,i为随机分区的序号,x
步骤3):引入非安全样本点来携带样本特征与噪声信息,非安全样本点指数据集D中的一个少数类样本x
∑
其中,j表示序号,F(·)是示性函数;
步骤4):分别在两个正方体内利用分区向量与非安全点进行多项式拟合得到多数类与少数类的划分模型,然后在新形成的各个分区M
所述步骤1)包括以下详细子步骤:
子步骤1.1)将带有复杂噪声的高度不平衡数据集D划分为训练集D'和测试集T;
子步骤1.2)将步骤1.1)所得的带有复杂噪声的高度不平衡训练数据集进行PCA降维,即可得到3维数据集;
子步骤1.3)找到步骤1.2)得到的3维数据集分别在x、y、z三轴上的最大值和最小值;
子步骤1.4)依据步骤1.3)得到的三轴上的最大值和最小值进行正方体划分,分别划分为2个正方体C1、C2;
子步骤1.5)使用convhull()凸包函数等,计算了给定区域的面积或体积,来判断训练集是否在三维点集形成的凸包内,并以bool值的形式返回,如果在,则返回1,否则返回0;
子步骤1.6)将步骤1.5)得到的3维空间内部的点的bool形式转换成int类型,并以数组形式返回每个正方体内部的点。
所述步骤2)包括以下详细子步骤:
子步骤2.1)分别对步骤2)所得的两个正方体内的样本点进行区域划分
子步骤2.2)首先对第一个正方体内部的样本点进行区域划分,依据步骤1.6)得到的第一个正方体内部的点,重复步骤2.4)-2.9),即可得到随机分区向量集S1
子步骤2.3)接着对第二个正方体内部的样本点进行区域划分,依据步骤1.6)得到的第二个正方体内部的点,重复步骤2.4)-2.9),即可得到随机分区向量集S2
子步骤2.4)根据训练数据集D',可以分别获得多数类样本集M和少数类样本集N;
子步骤2.5)分别计算多数类样本集M和少数类样本集N的数量;
子步骤2.6)由公式
子步骤2.7)将正方体随机划分成k个相等的分区,即i=1,2,…k;
子步骤2.8)得到分区i中M
子步骤2.9)所有的中心向量S
所述步骤3)包括以下详细子步骤:
子步骤3.1)分别对步骤1)的进行区域划分后两个正方体进行引入非安全样本点;
子步骤3.2)首先对第一个正方体引入非安全样本点,依据步骤1.6)得到的第一个正方体内部的点,重复步骤3.4)-3.12),即可得到非安全样本点集d1
子步骤3.3)接着对第二个正方体引入非安全样本点,依据步骤1.6)得到的第一个正方体内部的点,重复步骤3.4)-3.12),即可得到非安全样本点集d2
子步骤3.4)将训练数据集D'划分为多数类样本集(major_data_arr)和少数类样本集(minor_data_arr);
子步骤3.5)抽取训练样本集、训练样本标签以及原始少数类样本的特征集和标签值;
子步骤3.6)根据NearestNeighbors模型训练样本集;
子步骤3.7)依据训练之后的样本集,进而可以获取每一个少数类样本点周围最近的n_neighbors-1个点的位置矩阵;
子步骤3.8)通过步骤3.7)获取到的位置矩阵,进而获取到标签矩阵;
子步骤3.9)对步骤3.8)得到的标签矩阵的每一行向量相加,进而得到一个数组n_maj;
子步骤3.10)使用bitwise_and()函数对n_maj数组进行按位与后得到bool值;
子步骤3.11)根据步骤3.10)得到的bool值进而得到index下标;
子步骤3.12)依据步骤3.11)得到的index下标,从而抽取出危险样本数据集
子步骤3.13)将步骤2.2)所得的随机分区向量集S1
子步骤3.14)将步骤2.3)所得的随机分区向量集S2
所述步骤4)包括以下详细子步骤:
子步骤4.1)对步骤3.13)得到的数组Sd1
子步骤4.2)将步骤3.15)拟合的两个分类器f1(x)、f2(x)分别对各自的正方体内的样本点进行边界划分,这样就更新原来各正方体内的分区的分类边界。此时分区i中多数类与少数类分别记为M
子步骤4.3)计算每个分区的不平衡比率(ir);
子步骤4.4)对每个分区中的多数类进行欠采样,每个分区中的大类样本随机抽取的样本数不超过该分区中小类样本的1.5倍;
子步骤4.5)合并欠采样后大类样本与小类样本得到平衡数据集D”。
本发明为解决现实世界的数据中的不平衡以及噪声的关键问题---在复杂噪声环境下的高度不平衡分离方法提供了一种新的方法和思路。首先将带有复杂噪声数据集划分到两个正方体中,与此同时,对划分的两个正方体进行区域划分,为了得到分区的更多信息,因此,引入了分区向量,同时,为了弥补分区点的不足问题,也为了更好的区分多数类样本点与少数类样本点的边界,所以,引入了非安全样本点,并采用非安全样本点和分区向量结合的的方式经由多项式拟合形成了两个分类器,分别对两个正方体进行采样。该模型作为迄今为止第一个提出处理带有复杂噪声的高度不平衡数据集的分类器,不需要引入额外的参数,而且简单、高效、适用于任何场景;作为复杂噪声样本分类器,减少了数据冗余;作为高度不平衡数据分类器,有效地区分了多数类与少数类以及混合样本的边界,提高了模型的泛化能力。
本发明基于复杂噪声结合高度不平衡数据集方法具有以下优点:1)在谷歌学术中对复杂噪声结合高度不平衡数据进行搜索,并未发现与此方向有关的研究,因此,提出了第一个复杂噪声结合高度不平衡数据集处理模型;2)该方法作为目前为止第一个提出复杂噪声结合高度不平衡数据集的欠采样模型,具体来说,考虑到复杂噪声在高度不平衡数据集中的普遍性,因此,模拟噪声分布特征来增强模型的决策能力;3)该方法作为一种通用的方法,不需要引入额外的参数,而且可以结合传统分类器,加速大多数分类器的性能,提高模型的分类精度;4)在15个KEEL(https://sci2s.ugr.es/keel/datasets.php)上的高度不平衡数据集(ir>9)上,采用了7种目前最先进的处理方法进行对比实验,实验结果表明,模型表现较好。
附图说明
图1为本发明实施例方法的基本流程示意图。
图2为本发明实施例方法中三维空间中的带有复杂噪声的高度不平衡数据集示意图。
图3为本发明实施例方法中带有复杂噪声的高度不平衡数据集的正方体划分示意图。
具体实施方式
下面结合附图和具体的实施方式对本发明作进一步说明。
实施例1:
本发明的实施主要包括三项内容:1)将带有复杂噪声的高度不平衡数据集划分到两个正方体中;2)分别对两个正方体进行区域划分,得到随机分区向量集,同时引入非安全样本点集,对分区向量集与非安全样本点集进行多项式拟合得到分类模型;3)根据分类模型调整原来两个正方体内随机分区的类别边界,然后对各分区中的多数类的样本进行随机欠采样。下面分别阐述这3个环节的具体实施方式。
1)将带有复杂噪声的高度不平衡数据集划分到两个正方体中。
采用PCA降维,将多维带有复杂噪声的高度不平衡数据集映射到三维空间中,然后进行正方体划分,采用convhull()凸包函数等划分到两个正方体内。
2)分别对两个正方体进行区域划分。
3)对划分之后的两个正方体内部按不平衡率计算分区个数,然后将样本随机划分到这些分区中,并使得各分区中的样本数目尽可能相等。再计算得到随机分区向量集。
4)计算得到非安全样本点集。
5)合并分区向量集与非安全样本点集,然后利用多项式拟合得到分类模型,再对各分区进行边界调整。
6)对调整后的各分区的大类样本进行随机欠采样,得到平衡后的数据集。
参见图2,本发明将多维带有复杂噪声的高度不平衡数据集映射到三维空间中,以便于对于带有复杂噪声的高度不平衡数据集进行正方体划分。
参见图3,本发明对带有复杂噪声的高度不平衡数据集进行正方体划分,划分为两个正方体。
在本实施例中,采用了KEEL(https://sci2s.ugr.es/keel/datasets.php)上的15个高度不平衡数据集(ir>9)在性能一般的PC上进行实验,如表1。
表1例1所用高度不平衡数据集
然后在上述数据集中人工叠加高斯噪声、泊松噪声与随机噪声来模拟复杂噪声。其中,模拟高斯噪声的高斯分布的参数设置为mu=0,sigma=1;模拟泊松噪声的泊松分布的参数设置为lam=0.77。然后针对每一个样本将所生成的噪声直接叠加进去从而得到复杂噪声的高度不平衡数据集。
发明人采用微软Win10操作系统,以Pycharm作为开发平台,利用python语言编程,实现了复杂噪声结合高度不平衡数据集的欠采样模型。每个数据集随机分成两部分:75%用于进行训练,25%用于进行测试,为了提高实验的准确率,每次实验进行了10次以计算平均分类精度。利用本方法得到平衡数据集后采用DT决策树进行分类预测,取得了很好的效果,结果如表2。
表2例1所得到的分类结果
- 一种适用于复杂强噪声环境下短波莫尔斯信号的语音增强方法
- 一种基于深度学习的复杂噪声环境下的雷达信号恢复方法