基于自注意力机制的时空LSTM网络雷达回波序列预测方法
文献发布时间:2024-01-17 01:26:37
技术领域
本发明属于雷达回波序列预测技术领域,具体涉及基于自注意力机制的时空LSTM网络雷达回波序列预测方法。
背景技术
降水临近预报是人们日常生活中不可或缺的一部分,对于各行业和社会的决策都有着重要的意义,有效的对降水进行预测能够更好的指导人们的日常工作和生活;当前的降水临近预报技术主要是通过判断大气和气流的运动轨迹来实现对降水强度和区域的预测,其中,短时临近降水预报作为主要研究的热点,通过收集的历史帧雷达回波序列数据对未来序列帧进行预测,从而使用未来帧的强度和区域判断降水临近预报情况。当前主要的方法是通过深度学习技术,利用历史雷达序列数据进行训练,构建预训练模型,通过预训练模型来对未来帧预测,根据预测结果判断降水情况,通过不断改进深度学习网络的结构,从而进一步提高雷达回波序列预测的准确性;这些研究扩展了对降水临近预报的认识,为提高预报准确性和决策支持能力提供了新途径。
发明内容
本发明的目的是提供基于自注意力机制的时空LSTM网络雷达回波序列预测方法,提高短时临近降水的雷达回波序列预测能力。
本发明所采用的技术方案是,基于自注意力机制的时空LSTM网络雷达回波序列预测方法,具体按照以下步骤实施:
步骤1、将CKIM雷达回波数据集分为训练集和测试集,并进行预处理,得到序列图像;
步骤2、采用自注意力机制替代ST-LSTM单元中的遗忘门机制,形成SA-ST-LSTM单元;
步骤3、使用SA-ST-LSTM单元搭建编码-注意力-解码网络;
步骤4、将训练集送入编码-注意力-解码网络中进行训练,得到编码-注意力-解码的训练模型;
步骤5、将测试集送入编码-注意力-解码的训练模型中进行测试,得到未来帧的图像预测结果和预测数据。
本发明的特点还在于,
步骤1中,CKIM雷达回波数据集的训练集包含了120000张图像,测试集包含了30000张图像,训练集包含24000个序列,测试集包含6000个序列;将两个数据集中所有图像的尺寸调整至101×101×1,并进行归一化处理,得到序列图像。
步骤2中,具体为:
在ST-LSTM单元中,由于遗忘门的过饱和性导致长期记忆C
式中,t表示时间步长,l代表堆叠层数,
出门;
步骤3中,具体为:
采用3层CNN和3层SA-ST-LSTM单元进行交叉堆叠形成编码-解码结构,其中,在水平方向上,SA-ST-LSTM单元的长期记忆状态C
其中,
将3层的SA-ST-LSTM单元和3层的CNN进行堆叠形成解码结构,将经过注意力机制的
步骤4中,具体为:将训练集以连续5帧作为一个序列输入,10帧作为一个序列真实值,通过MSE损失函数进行优化,从而得到以该数据集收敛的预训练模型,通过预训练模型来实现对雷达回波的预测,从而判断降水情况。
本发明有益效果是:本发明提出了SA-ST-LSTM单元并设计了编码-注意力-解码网络,与传统的ST-LSTM相比,SA-ST-LSTM单元引入了注意力机制替换了遗忘门机制,采用超参数对长期记忆和短期记忆的调节来处理遗忘门中灾难性遗忘问题;在编码-解码网络上提出了编码-注意力-解码网络,该网络采用CNN和SA-ST-LSTM单元的交叉方式来实现对特征的有效提取,加入注意力机制来延缓编码-解码网络中长期记忆逐渐遗忘问题,提高了雷达回波序列预测的性能。
附图说明
图1是本发明基于自注意力机制的时空LSTM网络雷达回波序列预测方法中自注意力机制的计算过程图;
图2是本发明基于自注意力机制的时空LSTM网络雷达回波序列预测方法中SA-ST-LSTM单元注意力内部模块图;
图3是本发明基于自注意力机制的时空LSTM网络雷达回波序列预测方法中SA-ST-LSTM单元结构图;
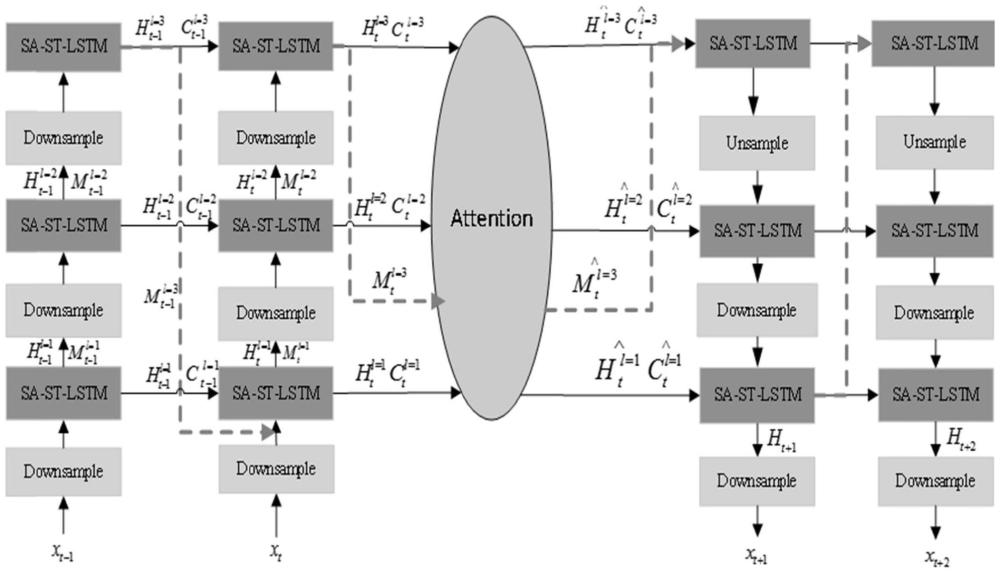
图4是本发明基于自注意力机制的时空LSTM网络雷达回波序列预测方法中编码-注意力-解码网络结构图。
图5是本发明实施中CKIM数据集雷达回波预测图;
图6是本发明实施中HSS阈值τ为30降水预测十帧指标图;
图7是本发明实施中CSI阈值τ为30降水预测十帧指标图;
图8是本发明实施中超参数α设置对SA-ST-LSTM单元的影响图;
图9是本发明实施中不同SA-ST-LSTM单元中α取值可视化雷达回波图。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明基于自注意力机制的时空LSTM网络雷达回波序列预测方法,具体按照以下步骤实施:
步骤1、将CKIM雷达回波数据集均分为训练集和测试集,对数据集进行预处理,得到序列图像;
具体为:CKIM雷达回波数据集的训练集包含了120000张图像,测试集包含了30000张图像,训练集包含24000个序列,测试集包含6000个序列,选择每个序列为5帧作为输入,10帧作为输出;将两个数据集中的所有图像的尺寸调整至101×101×1,并进行归一化处理,得到序列图像;
步骤2、在ST-LSTM单元的基础上进行改进,采用自注意力机制替代了ST-LSTM单元中的遗忘门机制,通过调节超参数α的方式实现对长期记忆和短期记忆状态更新的调节,从而解决在进行预测过程中ST-LSTM单元出现的灾难性遗忘问题,减少ST-LSTM单元在传输过程中信息无法更新导致的梯度消失现象;
自注意力模块被提出是用于输入的全局依赖性,在图像中,自注意力模块通过二元关系函数中计算特征图的不同位置之间的成对关系,来捕获长范围的时空依赖关系。而后通过这些关系计算出所关注的特征,自注意力模块通常使用点击来计算注意力打分,这里查询向量和键向量的维度是相同的。图1展示了使用的自注意力机制的计算过程,原始特征C
其中Softmax的表达式如下:
在ST-LSTM单元中,由于遗忘门的过饱和性导致长期记忆C
式中,t表示时间步长,l代表堆叠层数,
步骤3、使用SA-ST-LSTM单元搭建编码-注意力-解码网络;
通过CNN和SA-ST-LSTM单元交叉堆叠的方式实现对特征的进一步提取,其次,向编码-解码结构中加入注意力机制,延缓了长期记忆在解码过程中出现的逐步遗忘现象,最终构成了编码-注意力-解码网络;
具体为:采用3层CNN和3层SA-ST-LSTM单元进行交叉堆叠形成编码-解码结构,其中,在水平方向上,SA-ST-LSTM单元的长期记忆状态C
其中,
在雷达回波序列预测的编码-解码结构中,都是由时空序列单元进行堆叠的,而时空序列单元的捕捉空间信息能力不如卷积层强大,因此,加入卷积层进行特征提取后能够进一步提高网络对于空间信息捕获能力,得到更加清晰的预测图像,其次,由于长期记忆信息会在解码过程中通常会出现逐渐遗忘的趋势,为了进一步增强捕获重要信息的能力,在编码和解码的过程中加入了注意力机制,使得编码后得到的矢量的长期记忆C
步骤4、将训练集送入编码-注意力-解码网络中进行训练,得到编码-注意力-解码的训练模型;
将训练集以连续5帧作为一个序列输入,10帧作为一个序列真实值,通过MSE损失函数进行优化,从而得到以该数据集收敛的预训练模型,通过预训练模型来实现对雷达回波的预测,从而判断降水情况。
步骤5、将测试集送入编码-注意力-解码的训练模型中进行测试,得到测试数据和预测图像;
将测试集以序列的方式输入到训练模型中进行测试,CKIM雷达回波数据集来测试最终的预测效果,最后,将得到的输出结果转换成图像进行保存,得到未来帧的图像预测结果和预测数据。
实施例
使用CKIM雷达回波数据集评估了SA-ST-LSTM单元构成的编码-注意力-解码网络,在分析中用简写EnADe(ST-LSTM)和EnADe(SA-ST-LSTM)结构代表了以ST-LSTM单元为基础的编码-注意力-解码网络和以SA-ST-LSTM单元为基础的编码-注意力-解码网络,分析了网络的数据实验结果和预测图像结果,并通过了天气预测图像的消融实验,分析了SA-ST-LSTM单元中α的取值情况。采用了平方损失函数对网络进行训练和测试,CKIM雷达回波的实验结果和预测图像在SA-ST-LSTM单元的超参数α为0.7下进行,所有实验在Pytorch中实现,RTX 3080Ti GPU上进行。EnADe(SA-ST-LSTM)网络的超参数设置如表1所示:
表1超参数设置
通过将CKIM雷达回波的训练集放入网络中进行训练,而后使用训练模型进行测试得到评估指标结果:
表2CKIM雷达回波序列任务
表2是不同阈值下的HSS和CSI数据、HSS、CSI的平均数据和平方误差损失函数的数据,EnADe(SA-ST-LSTM)网络相比于其他网络的预测结果更为准确,可以看到,EnADe(SA-ST-LSTM)网络的平方损失函数相较于PredRNN下降了6.7%,其平均的HSS和CSI则分别提高了2.5%和2.9%,证明了EnADe(SA-ST-LSTM)网络单元和结构在雷达回波序列预测问题上有足够的潜能。图5展示了CKIM雷达回波数据集的预测结果,网络的性能有了很大的提升,有效的解决了雷达回波序列预测问题强度和区域的不同。
图6和图7展示了阈值τ为30时的HSS和CSI逐帧效果。从图中可以看到,EnADe(SA-ST-LSTM)网络的逐帧预测结果普遍高于所有网络,在临近帧的表现更加优异,这表明了EnADe(SA-ST-LSTM)网络能够不仅能够有效的捕获临近帧的突变现象,而且还能够提高长期帧的预测结果,使得在进行雷达回波预测任务时能够预测到更多强度较高的区域,证明了EnADe(SA-ST-LSTM)网络有效的提高了时空序列预测的鲁棒性和准确性。
从图8可以看到在取不同的α值的网络损失函数的波动,不同的α对预测结果产生了很大的影响,这是因为在α控制着长期信息和短期信息的更新状况,当α=0.9时,这时的网络处于灾难性遗忘状态,因此其损失函数较大,说明了灾难性遗忘的发生对时空序列预测的影响,而在α=0.1时,这时单元的信息更新情况较快,虽然效果相比灾难性遗忘的情况较好,但是短期信息的更新较快会带来梯度消失现象,当α=0.7时预测的效果和性能最好,由图可以看到网络的性能结果保持在一定区间之内,这种波动被认为是由于网络在长期记忆和短期记忆在交叉融合过程中占据的定量形成的,α=0.7时占据了70%的定量,短期记忆占据了30%的定量,这时候的效果达到了目前网络的最优,网络在雷达回波的预测效果达到的最好。
图9中展示了在不同α取值时出现的情况,包含了α从0.1到0.9,代表长期记忆和短期记忆信息的占比量,在进行前两帧预测时,所有的实验结果相差不大,这是长期记忆所携带的趋势性信息造成的,从第3帧开始,不同α取值所得到的结果差异性开始显现,当α值为0.1或0.2时,由于长期记忆状态占据太多,网络处于灾难性遗忘状态,这种情况下网络只能在趋势信息下更新,信息逐渐呈现遗忘的趋势,因此,从预测图像中明显可以看出强度区域逐渐消失,无法得到准确的预测结果。当α值为0.8或0.9时,网络的处于短时记忆信息频繁更新状态,这种情况下,长期记忆信息趋势占比小,图像对当前时刻的信息更新过快,这种情况会导致网络在多步预测过程中出现梯度消失现象,从图像中可以看出,网络从第3帧之后的图像变化趋势较快,但是无法对长期信息得到充分保证,效果较差,当α值为0.7时,网络的预测性能最好,这时的长期记忆和短期记忆占比相当,长期记忆从先前的网络状态中学习到了趋势性信息,这种信息作为了时空序列单元的类似先验部分,而短时信息通过当前时刻的趋势信息不断更新,使得网络的性能达到了最佳状态,从而有效解决了灾难性遗忘导致的饱和问题。
- 基于注意力机制的时空神经网络雷达回波外推预报方法
- 一种基于自注意力机制和预测递归神经网络的气象雷达回波外推方法及系统