一种实体关系导向的语言模型测试方法
文献发布时间:2024-01-17 01:26:37
技术领域
本发明属于计算机科学领域中的软件分析测试领域。本发明提出了一种面向人工智能方 向、自然语言处理领域中语言模型的测试方法,用于测试语言模型的输出。从而使得开发者 能够根据测试结果分析模型输出是否存在问题,对未来的自然语言处理领域中的模型测试问 题具有借鉴意义。
背景技术
自然语言处理(Natural Language Processing)是人工智能领域中的一个重要方向,是利用 计算机技术分析、理解自然语言的学科,与语言学和计算机科学有着密切的联系,包含文本 生成、序列标注、信息抽取,情感分析、机器翻译等领域。其中语言模型是NLP领域中的基 本模型,可以描述为给定文本序列w
●做预训练模型(e.g.BERT,GPT-3),用于后续的自然语言处理任务。
●生成文本,给定文本序列,不断使用w
●判断多个序列中哪个更常见(e.g.“to recognize a speech”vs“to wreck anice beach”),主要应用于语音识别领域。
文本生成任务是语言模型的一个重要应用,可以被形式化的定义为给定文本序列w
●将语言模型中应用到具体的问题当中,查看语言模型在这些任务中的表现,比如机器 翻译,语音识别,文本生成等,通过模型表现评估模型。
●使用困惑度(Perplexity)评估模型。困惑度刻画的是语言模型预测一个语言样本的能 力,语言模型在测试集上的困惑度被表示为测试集中句子可以被语言模型预测出的逆 概率,并使用单词的数量N对结果做归一化处理,在测试集上计算所得的困惑度越小,准确率越高,语言模型也就越好。对于测试集中的一个序列W=w
使用链式规则扩展可得:
现有对语言模型的评估方法都存在不足。将语言模型应用到具体的问题是最好的评估方 法,但是这种方法可能难以操作,无法自动化评估模型的输出,可能需要消耗大量的人力资 源,另一方面运行一个大型的NLP模型可能非常耗时,评估效率低;使用困惑度可以自动化 地通过测试集来对语言模型的输出进行评估,但是测试集上的评估结果不一定准确,而且现 实可能会仅有模型而没有测试集,此时便不能对语言模型进行测试。
现有研究已经通过众包工作定义出了语言模型生成文本的错误,例如语法错误,常识错 误,百科错误等,现有的研究还停留在对错误细分归类的阶段,并没有给出自动化的测试流 程,现阶段对语言模型的测试研究还比较少。
本发明提出的实体关系导向的语言模型测试方法,利用NLP中的命名实体识别、实体关 系抽取、知识图谱等相关任务,对语言模型的生成文本进行测试,下面简要介绍本发明中所 用到的相关任务。
●命名实体识别(Named Entity Recognition,简称NER),是指从文本中识别出具有特 定意义的实体,包括人名、地名、时间、机构名等词组,其过程是从非结构化的文本 中得到专有名词的标注信息,从而获取相关实体。例如,江苏是中国的省份,其中“江 苏”、“中国”都是命名实体,分别表示“省份”实体和“国家”实体。
●实体关系抽取(Entity Relation Extraction),是指在已经完成命名实体识别的基础上, 从非结构化文本抽取出实体之间的关系信息,是文本数据挖掘,信息抽取的核心任务。 实体关系抽取任务可以被形式化的描述为:给定实体e
●知识图谱(Knowledge Graph,简称KG)是一种知识库,其中的数据通过图结构的数 据模型或拓扑整合而成,用顶点表示实体,用边表示实体之间的联系。RDF(Resourcedescription framework)图是一种主流的知识图谱数据模型,RDF图的定义如下,设U, B和L是互不相交的无限集合,分别代表统一资源标识符(URI),空顶点(Blank Node) 和字面量(Literal)。假设s为主语,p为谓语,o为宾语,则(s,p,o)∈(U∪B)×U×(U∪ B×L)称为一个RDF三元组,RDF图是三元组的有限集合。例如
发明内容
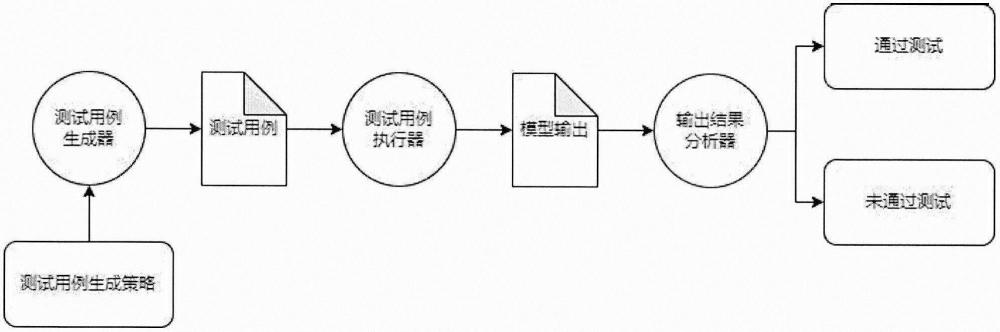
本发明提供了一种实体关系导向的语言模型测试方法,该方法形式化地定义了针对语言 模型地测试流程,并通过实验对测试流程进行验证。方法自动化地通过给定单词构造能够触 发潜在缺陷的测试用例,将测试用例输入语言模型执行并输出生成文本,对文本进行后续测 试并生成测试结果报告,根据测试结果报告分析语言模型的输出存在哪些问题,从而对模型 开发者对模型的优化和调试提供思路,更好地维护模型质量。本发明提出的一种实体关系导 向的语言模型测试方法从语义的角度对模型输出进行评估,操作简单;不需要提供测试集, 仅需模型即可对模型输出进行评估,条件要求低。本发明缺点是只能从特定的角度评估测试 模型输出,不能对语言模型进行全面测试。
假设待测试的语言模型为M,实体关系导向的语言模型测试方法包含以下流程:
1.选取构造输入序列W
2.对wordList中的单词根据指定模式(pattern)构造序列W
3.将序列W
4.对输出序列W
5.对步骤2得到的实体集合中的实体e
6.依次遍历实体关系集合R
7.将出现问题的关系对以及对应实体和实体出现位置( 8.对于每个W 本发明基于命名实体识别、实体关系抽取、知识图谱关系验证这一流程,在自动化构输 入序列后将输入序列送入语言模型,得到输出序列;对输出序列进行命名实体识别后,将相 应实体进行关系抽取,通过构造查询语句判断所抽取的关系是否存在于知识图谱中,根据查 询结果生成测试报告判断输出序列是否存在问题。本发明可以有效的发现生成序列中不符合 知识图中存在关系的序列,并将产生错误的实体对反馈给测试人员;本发明流程简单,从语 义的角度分析语言模型生成文本的错误,并能精确定位错误,完成了自动化的测试流程;同 时本发明可以脱离测试集完成测试流程,方便高效。 附图说明 图1为本发明中一种实体关系导向的语言模型测试方法的总体流程图;图2为本发明中 一种实体关系导向的语言模型测试方法的具体实施方式流程图。 具体实施方式 由于本发明提供的是一个自动化的测试方法,所测试的错误种类可以自行选择,本章节 将测试语言模型生成文本中的地理信息关系错误。我们假设和地理信息相关的输入更容易触 发和地理信息相关的输出,因此选用的构造输入序列的单词、模式均与地理信息相关,所抽 取的实体、关系也全是与地理信息相关的内容。本实验流程采用命名实体识别工具是斯坦福 大学提出的Stanfordcorenlp中的NER工具,采用的关系抽取工具是清华大学提供的基于BERT 的关系抽取模型,采用的知识图谱是维基数据(wikidata),被测试的模型是GPT-2。命名实 体工具、关系抽取工具、知识图谱可以自行选择或者自己训练、研发,相应工具的选择均会 影响测试精度。实验流程图如图1所示,流程简介如下: 1.选取构造输入序列W 2.使用wordList中的单词根据pattern构建句子作为W 3.将输入序列W 4.使用命名实体识别工具对输出序列W 5.使用关系抽取工具对实体集合E 6.构造查询语句查询关系。构造Sparql查询语句,使用维基数据提供的API发送查询 请求,从知识图谱中获取查询结果。也可以将知识图谱下载至本地,从本地完成查询 请求。 7.分析查询结果。输出序列W 8.将所有的生成报告反馈给测试人员。 综上所述,实体关系导向的语言模型测试方法是一种全新的测试方法,它可以自动化 的生成测试用例,完成了获取单词、生成测试用例、输出结果、输出测试、生成测试报告的完整测试流程。生成测试用例过程会根据测试目的针对性选取单词与模式生成测试用例;生成测试报告之后会使用相关工具对输出序列进行命名实体识别,实体关系抽取,构造查询语句查询知识图谱中是否存在该关系,从而完成完整的测试流程。该测试方法 可以有效弥补当今对语言模型的测试工具匮乏的问题,既能从语义的角度考虑输出结果, 又能脱离测试集,使得测试人员能够在没有测试集的情况下完成测试流程。同时不需要 将测试过程带入具体任务,测试流程自动化。 本发明可以为开发者调试和修复语言模型提供指导,从而更好地提升语言模型质量, 对今后语言模型测试方法的研究具有借鉴意义。
- 一种基于Lattice LSTM和语言模型的命名实体识别方法
- 一种基于预训练语言模型的实体关系抽取方法及装置
- 一种基于多种实体注意力和改进预训练语言模型的药物间关系抽取方法