一种基于机器学习的授信客户挖掘方法
文献发布时间:2024-04-18 19:55:00
技术领域
本发明涉及信息处理分析技术领域,具体涉及一种基于机器学习的授信客户挖掘方法。
背景技术
现有授信客户挖掘需基于客户提供的资料,采用人工对客户资料进行资料审批,审核客户的注册资本、注册时间、经营期限、交易时长、毛利润、交易金额、订单数、客单价、回款逾期次数、逾期金额和逾期天数等信息,从而评估出该客户具备的信用等级。但是现有授信客户挖掘方法存在用时较长,审核速度慢,不便于快速实现对授信客户的挖掘。
发明内容
针对现有技术中的上述不足,本发明提供的一种基于机器学习的授信客户挖掘方法解决了现有授信客户挖掘方法存在用时较长,审核速度慢的问题。
为了达到上述发明目的,本发明采用的技术方案为:一种基于机器学习的授信客户挖掘方法,包括以下步骤:
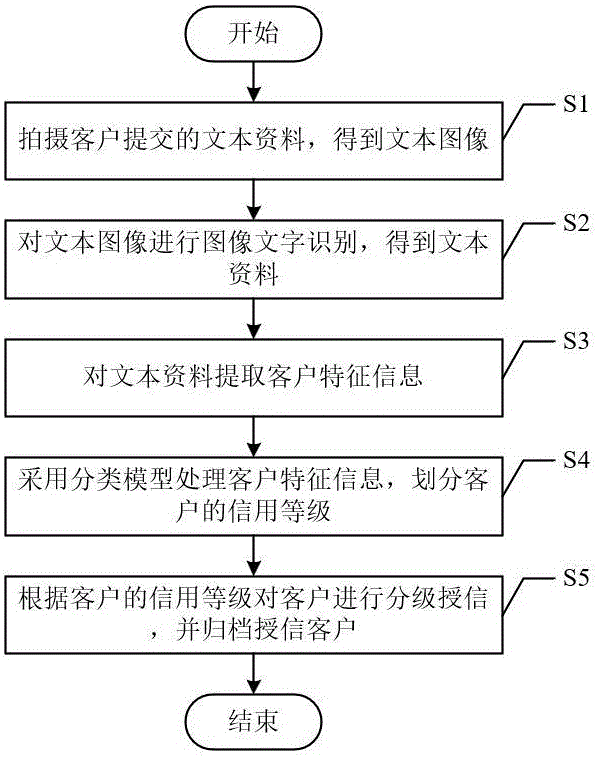
S1、拍摄客户提交的文本资料,得到文本图像;
S2、对文本图像进行图像文字识别,得到文本资料;
S3、对文本资料提取客户特征信息;
S4、采用分类模型处理客户特征信息,划分客户的信用等级;
S5、根据客户的信用等级对客户进行分级授信,并归档授信客户。
进一步地,所述S2包括以下分步骤:
S21、对文本图像提取文字图像;
S22、采用特征提取模型对文字图像进行特征提取,得到图像特征序列;
S23、采用文字识别模型对图像特征序列进行处理,得到文本资料。
进一步地,所述S21包括以下步骤:
S211、对文本图像灰度处理,得到灰度图;
S212、从灰度图中找到所有满足边缘条件的像素点,作为文字像素点,其中,边缘条件为:
,其中,/>
S213、将所有文字像素点的灰度值构成文字图像。
上述进一步地方案的有益效果为:将文本图像灰度化处理,得到灰度图,利用文字像素点的像素值和背景像素点的像素值筛选出文字像素点,一个像素点的临近范围内存在两种像素值,则像素点则大概率为文字像素点,通过计算出两种像素值的差值是否大于距离阈值,若是,则说明两侧的像素值差值较大,同时,该像素点与一侧像素点的像素值相近,其与另一侧像素点的像素值的较远,则进一步确定该像素点为文字上的边缘文字像素点,提取出所有边缘文字像素点,则提取出文字特征,达到快速减少图像特征,又能精确提取出文字像素点的效果。
进一步地,所述S22中特征提取模型包括:第一卷积层、第二卷积层、第三卷积层、第四卷积层、深度卷积层、第一归一化层、第二归一化层、最大池化层、平均池化层、Concat层、第一加法器A1和第二加法器A2;
所述第一卷积层的输入端作为特征提取模型的输入端,其输出端分别与深度卷积层的输入端、最大池化层的输入端、平均池化层的输入端和第二加法器A2的输入端连接;所述第一归一化层的输入端与深度卷积层的输出端连接,其输出端与第二卷积层的输入端连接;所述第一加法器A1的输入端分别与最大池化层的输出端和平均池化层的输出端连接,其输出端与第二归一化层的输入端连接;所述Concat层的输入端分别与第二卷积层的输出端和第二归一化层的输出端连接,其输出端与第三卷积层的输入端连接;所述第三卷积层的输出端与第二加法器A2的输入端连接;所述第四卷积层的输入端与第二加法器A2的输出端连接,其输出端作为特征提取模型的输出端。
上述进一步地方案的有益效果为:本发明将文字图像进行第一卷积层处理,分成多路,输入不同路径,通过深度卷积层所在路径提取深度特征,通过最大池化层提取显著特征,通过平均池化层提取平均特征,连接第一卷积层和第二加法器A2实现恒等映射,解决梯度消失问题,本发明通过多路径方式提取出图像特征序列,保障特征的丰富性。
进一步地,所述归一化层的公式为:
,
其中,
进一步地,所述S23中文字识别模型包括:第一LSTM层、第二LSTM层、注意力层、全连接层和Softmax层;
所述第一LSTM层的输入端与注意力层的第一输入端连接,并作为文字识别模型的输入端;所述第二LSTM层的输入端与第一LSTM层的输出端连接,其输出端与注意力层的第二输入端连接;所述全连接层的输入端与注意力层的输出端连接,其输出端与Softmax层的输入端连接;所述Softmax层的输出端作为文字识别模型的输出端。
进一步地,所述注意力层的表达式为:
,
其中,
上述进一步地方案的有益效果为:本发明将输入注意力层的特征进行加权处理后,根据各个量所占比重体现各个量在输入特征所占比重,避免池化处理抹去数据特征,再进行最大池化和平均池化处理,并分别赋予权重,增加对特征的注意力。
进一步地,所述S4中分类模型为:
,
其中,
上述进一步地方案的有益效果为:在分类模型中,每种客户特征信息均有一个对应的阈值,若客户特征信息小于阈值,则其在分类模型中起到降低客户信用等级的作用,并对每种客户特征信息赋予不同的权重和偏置,实现不同客户特征信息具备不同重要程度,采用双曲正切函数计算出客户的信用程度,并设置比例系数,放大信用程度,便于区分客户的信用等级。
进一步地,所述分类模型的损失函数为:
,
其中,
上述进一步地方案的有益效果为:本发明中采用实际信用等级与预测信用等级的差值平方作为损失函数的主要内容,并借助多次训练的情况,从而使得整体上分类模型能达到较高精度,防止其因为某次精度较高而影响对分类模型训练程度的判断,并且本发明中设置了损失差阈值
综上,本发明的有益效果为:本发明在录取客户资料上,采用图像处理,提取客户资料的文本,从而得到客户特征信息,采用分类模型根据客户特征信息自动划分出客户的信用等级,根据客户的信用等级对客户进行分级授信,实现一种全自动快速的授信客户挖掘方法。
附图说明
图1为一种基于机器学习的授信客户挖掘方法的流程图;
图2为特征提取模型的结构示意图;
图3为文字识别模型的结构示意图。
具体实施方式
下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
如图1所示,一种基于机器学习的授信客户挖掘方法,包括以下步骤:
S1、拍摄客户提交的文本资料,得到文本图像;
S2、对文本图像进行图像文字识别,得到文本资料;
所述S2包括以下分步骤:
S21、对文本图像提取文字图像;
所述S21包括以下步骤:
S211、对文本图像灰度处理,得到灰度图;
S212、从灰度图中找到所有满足边缘条件的像素点,作为文字像素点,其中,边缘条件为:
,其中,/>
在本实施例中,距离阈值根据实验的情况进行设置。
S213、将所有文字像素点的灰度值构成文字图像。
将文本图像灰度化处理,得到灰度图,利用文字像素点的像素值和背景像素点的像素值筛选出文字像素点,一个像素点的临近范围内存在两种像素值,则像素点则大概率为文字像素点,通过计算出两种像素值的差值是否大于距离阈值,若是,则说明两侧的像素值差值较大,同时,该像素点与一侧像素点的像素值相近,其与另一侧像素点的像素值的较远,则进一步确定该像素点为文字上的边缘文字像素点,提取出所有边缘文字像素点,则提取出文字特征,达到快速减少图像特征,又能精确提取出文字像素点的效果。
在本实施例中,根据文本资料的文字与背景的特点可知:
S22、采用特征提取模型对文字图像进行特征提取,得到图像特征序列;
如图2所示,S22中特征提取模型包括:第一卷积层、第二卷积层、第三卷积层、第四卷积层、深度卷积层、第一归一化层、第二归一化层、最大池化层、平均池化层、Concat层、第一加法器A1和第二加法器A2;
所述第一卷积层的输入端作为特征提取模型的输入端,其输出端分别与深度卷积层的输入端、最大池化层的输入端、平均池化层的输入端和第二加法器A2的输入端连接;所述第一归一化层的输入端与深度卷积层的输出端连接,其输出端与第二卷积层的输入端连接;所述第一加法器A1的输入端分别与最大池化层的输出端和平均池化层的输出端连接,其输出端与第二归一化层的输入端连接;所述Concat层的输入端分别与第二卷积层的输出端和第二归一化层的输出端连接,其输出端与第三卷积层的输入端连接;所述第三卷积层的输出端与第二加法器A2的输入端连接;所述第四卷积层的输入端与第二加法器A2的输出端连接,其输出端作为特征提取模型的输出端。
本发明将文字图像进行第一卷积层处理,分成多路,输入不同路径,通过深度卷积层所在路径提取深度特征,通过最大池化层提取显著特征,通过平均池化层提取平均特征,连接第一卷积层和第二加法器A2实现恒等映射,解决梯度消失问题,本发明通过多路径方式提取出图像特征序列,保障特征的丰富性。
所述第一归一化层和第二归一化层的公式为:
,
其中,
S23、采用文字识别模型对图像特征序列进行处理,得到文本资料。
如图3所示,S23中文字识别模型包括:第一LSTM层、第二LSTM层、注意力层、全连接层和Softmax层;
所述第一LSTM层的输入端与注意力层的第一输入端连接,并作为文字识别模型的输入端;所述第二LSTM层的输入端与第一LSTM层的输出端连接,其输出端与注意力层的第二输入端连接;所述全连接层的输入端与注意力层的输出端连接,其输出端与Softmax层的输入端连接;所述Softmax层的输出端作为文字识别模型的输出端。
所述注意力层的表达式为:
,
其中,
本发明将输入注意力层的特征进行加权处理后,根据各个量所占比重体现各个量在输入特征所占比重,避免池化处理抹去数据特征,再进行最大池化和平均池化处理,并分别赋予权重,增加对特征的注意力。
S3、对文本资料提取客户特征信息;
在步骤S2进行了文字识别,从而提取得到文本资料,文本资料在计算机系统中为数据向量,因此,在S3中仅将所需的文字特征向量提取出来,则为客户特征信息,相当于是从存储单元中提取出对应的数据向量,则客户的信息就已知。
S4、采用分类模型处理客户特征信息,划分客户的信用等级;
所述S4中分类模型为:
,
其中,
在分类模型中,每种客户特征信息均有一个对应的阈值,若客户特征信息小于阈值,则其在分类模型中起到降低客户信用等级的作用,并对每种客户特征信息赋予不同的权重和偏置,实现不同客户特征信息具备不同重要程度,采用双曲正切函数计算出客户的信用程度,并设置比例系数,放大信用程度,便于区分客户的信用等级。
在本实施例中,可先对客户特征信息进行归一化处理,保证每个量处于0~1范围,从而便于衡量每个量在分类模型中的分量,在归一化后,客户特征信息阈值可设为0.5。
在本实施例中,客户特征信息的类型包括:注册资本、注册时间、营业范围、经营期限、股东信息、高管信息、交易时长、毛利润、交易金额、订单数和客单价,取其中两种类型“注册资本、注册时间”进行举例说明分类模型,假如注册资本为一千万,设定注册资本最大两千万,则归一化后注册资本类型对应的客户特征信息的值为0.5,注册时间为6年,设定最大年限为30年,则注册时间类型对应客户特征信息的值为0.2,即本发明中描述的客户特征信息为对客户信息量化后的数值。该描述仅为举例说明分类模型的使用,而具体使用过程可根据需求进行设定,具体的需求设定不影响本发明分类模型的结构。
客户特征信息的类型选择,根据每个企业或者银行根据自身营业所看重的方向进行自由选择。
本发明的分类模型实现的是将客户的多种信息进行汇总统计,从而得到客户的信用等级。
所述分类模型的损失函数为:
,
其中,
本发明中采用实际信用等级与预测信用等级的差值平方作为损失函数的主要内容,并借助多次训练的情况,从而使得整体上分类模型能达到较高精度,防止其因为某次精度较高而影响对分类模型训练程度的判断,并且本发明中设置了损失差阈值
本发明中实际的信用等级为根据经验,人为对分类模型的训练样本划分出的标签。
本发明中分类模型训练的精度越高,客户信用等级的划分精度越高。
S5、根据客户的信用等级对客户进行分级授信,并归档授信客户。
在本实施例中,客户的信用等级包括:青铜客户、白银客户、黄金客户、铂金客户和钻石客户,或者一级客户、二级客户、三级客户和四级客户等。
综上,本发明实施例的有益效果为:本发明在录取客户资料上,采用图像处理,提取客户资料的文本,从而得到客户特征信息,采用分类模型根据客户特征信息自动划分出客户的信用等级,根据客户的信用等级对客户进行分级授信,实现一种全自动快速的授信客户挖掘方法。
以上仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种基于机器学习的电能替代潜在客户预测方法
- 基于知识图谱和机器学习算法挖掘银行潜在授信客户方法
- 一种基于机器学习的客户授信额度预测方法