基于分布式智能搜索引擎的高校学者信息检索方法
文献发布时间:2024-04-18 19:58:21
技术领域
本发明涉及高校学者信息技术领域,特别是一种基于分布式智能搜索引擎的高校学者信息检索方法。
背景技术
由互联网之父蒂姆·伯纳斯·李提出语义网络是未来互联网发展的大趋势。传统的互联网只能表示页面之间的链接关系,不能理解页面内容;而语义网络描绘了各种实体间丰富的关系,是能够被机器理解与处理的数据网络。由谷歌提出的知识图谱本质上是语义网络,目的是从语义层面理解用户的搜索意图,提高搜索质量。相比传统搜索引擎,由语义网络与知识图谱技术支撑的新一代搜索引擎能够实现更高的查全率、查准率与智能性。尽管业界已经出现搜狗知立方、百度知心等新型搜索引擎,但是这些搜索引擎仍然是新兴事物,极少受到人们关注。在学术界,构建以科研学者为中心,以语义网络与知识图谱技术为支撑的新一代垂直搜索引擎可打破现有学术信息搜索模式,提高搜索效果。但是专注于提供学术信息管理与文献检索的服务的Aminer、学者网与Social Scholar都没有实现智能搜索与智能推荐。因为新型搜索引擎的构建主要面临信息采集、知识库构建、深度挖掘、语义搜索、知识问答等难题,所以学术界没有出现类似搜索引擎。
对国内外高校学者信息开展收集与检索,可有利于对教师及学者信息进行综合统计分析,获取涉及国家安全的战略信息;可有利于了解科技前沿的热点、重心及其趋势变化;可有利于打造全球最大的高校学者知识图谱和关系网络,理清不同学术流派的人际关系脉络,挖掘具有科研潜力的青年才俊。
经过检索发现公开号为CN108090223B的发明专利申请,公开了一种基于互联网信息的开放学者画像方法,其主要包括:S1利用训练语料,训练主页排序模型和LSTM序列标注模型;S2利用搜索引擎实现开放学者姓名和机构的联合检索结果,利用爬虫获取检索结果信息作为开放学者候选页;S3对于每个开放学者候选页,利用步骤S1训练好的主页排序模型,按照主页概率排序获取候选主页概率列表,从中选取前两个主页作为候选主页,对主页内容进行图片识别和Email抽取,利用抽取结果对两个候选主页做二次判断,选取其中一个候选主页作为最终的学者个人主页;S4在最终的学者个人主页中利用LSTM序列标注模型获取学者的国家/职位信息,结合步骤S3的信息抽取结果,实现开放学者的画像。
但是,采用上述方法进行高校学者信息检索仍然存在如下几个缺点:
(1)搜索引擎的效率、覆盖面、智能化程度不足,无法有效检索世界上主要高等学府的学者信息;
(2)这项专利主要聚焦于高校学者主页识别与信息抽取,其中主页识别算法没有利用网页的多模态信息,因此无法达到较高的识别效果。
发明内容
为解决现有技术中存在的问题,本发明的目的是提供一种基于分布式智能搜索引擎的高校学者信息检索方法,本发明解决了高等学府网站中科研学者信息检索、识别与细粒度抽取等难题。
为实现上述目的,本发明采用的技术方案是:一种基于分布式智能搜索引擎的高校学者信息检索方法,包括以下步骤:
步骤1、获取国内外高等学府主页的网址URL,整理为输入数据;
步骤2、搭建由一个数据节点与多个工作节点构成主从分布式搜索引擎;
步骤3、将所述输入数据输入搭建的分布式搜索引擎中,所述分布式搜索引擎自动根据高校主页网址URL访问高校网站,并基于广度优先遍历的原则,从层层高校官网中获取网页;
步骤4、目标网页识别器根据网页中的图像性、内容性和布局性特征准确识别当前网页是否为学者信息页面;
步骤5、信息提取器根据预定义规则自动抽取学者的细粒度信息;
步骤6、将抽取的细粒度信息集中缓存至数据节点服务器中的MongoDB及MySQL数据库中;
步骤7、URL提取器从页面中提取所有URL;URL过滤器根据链接锚文本过滤掉噪声URL;
步骤8、URL等级队列根据链接锚文本将URL划分不同的等级,并赋予等级标签并存储到等级队列中;调节器根据URL标签的等级,从URL队列中提取URL并送入下载器中;
步骤9、从数据节点服务器中提取学者细粒度信息,基于ElasticSearch构建倒排索引及信息检索功能;
步骤10、从数据节点服务器中提取学者细粒度信息,从学者信息中挖掘出学者之间的任职网络、合著网络及引用网络,构建以学者为核心的知识图谱,并存储进Neo4J图结构数据库中,便于后续检索及研究。
作为本发明的进一步改进,在步骤2中,所述分布式智能搜索的各个节点服务器之间通过局域网通信。
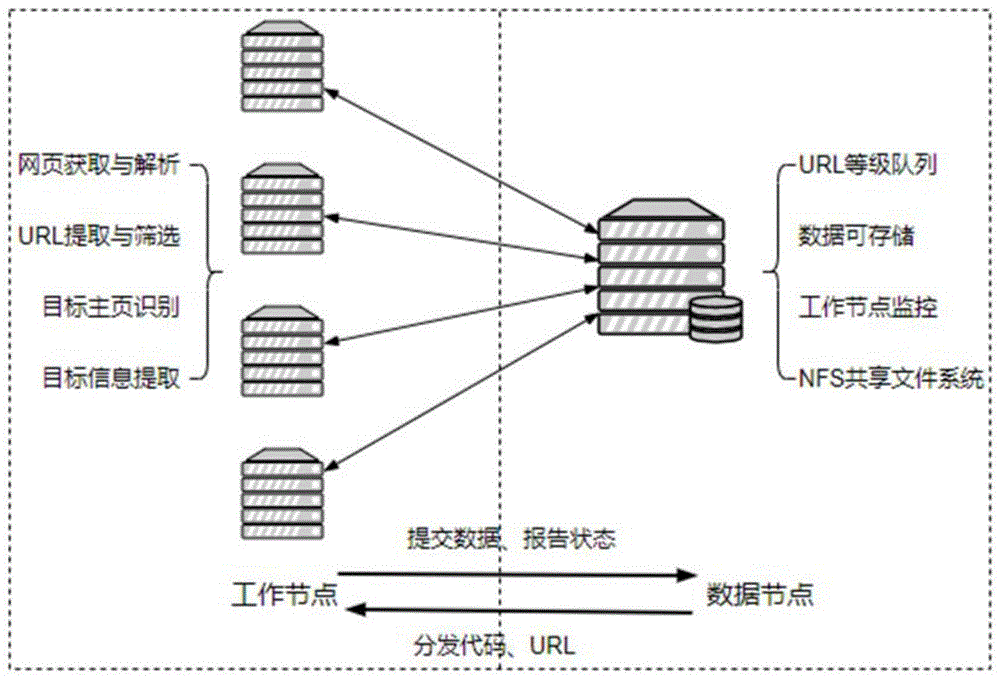
作为本发明的进一步改进,所述步骤2中的数据节点服务器配备URL等级队列、数据库、服务器监控端,用于负责代码与任务URL分发、数据存储、工作节点状态监控三项任务。
作为本发明的进一步改进,所述步骤2中的工作节点服务器配备下载器、URL调节器、URL过滤器、URL提取器、教师主页识别器、页面内容提取器,用于负责网页下载、目标网页识别、目标信息提取、URL提取与筛选、状态汇报五项任务;基于广度优先遍历的原则,工作节点中的下载器从高校官网获取网页,目标识别器判断该网页是否是教工主页,内容提取器从教工主页中提取目标信息;获取的网页需要经过URL提取器、URL过滤器的处理得到纯净的URL。
作为本发明的进一步改进,在步骤3中,所述分布式搜索引擎的工作节点遵循人工预定义的最优访问路径开展网页搜索,其中,最优访问路径为:University/College→School/Department/Program→Faculty homepage。
作为本发明的进一步改进,在步骤4中,所述目标页面识别器包括一个多模态生成对抗网络与一个门限融合网络;其中,所述多模态生成对抗网络包括三个生成器与一个判别器,三个生成器包括文本特征生成器、布局特征生成器与图像特征生成器,多模态生成对抗网络和门限融合网络通过零和博弈达到优化目的;三个所述生成器用于将服从先验高斯分布的噪声向量转化为对应的虚假特征向量,判别器负责判别输入的特征向量是否由生成器合成,并通过损失函数梯度的反向传播,指导生成器改进合成的虚假特征向量,且三个生成器通过拼接合成的虚假特征向量,达到信息共享的目的。
作为本发明的进一步改进,所述门限融合网络首先利用基于Sigmoid激活函数构建的门限机制从多模态特征向量中提取关键信息,所述多模态特征向量包括文本性特征向量、布局性特征向量与图像性特征向量,然后利用基于克罗内克积构建的融合机制整合这些关键信息向量,最后将整合的特征向量输出到Softmax分类决策层判断该页面是否为学者信息页面。
本发明的有益效果是:
1、本发明构建了一个由一个数据节点与多个工作节点构成主从分布式搜索引擎,可以对海量网页数据的高效搜索。
2、本发明摒弃了传统的暴力搜索方式,本发明设计的搜索引擎遵循人工预定义的最优访问路径“University/College→School/Department/Program→Facultyhomepage”,可以大大降低时间复杂度。
3、本发明的目标识别器基于深度多模态融合识别框架构建,对学者主页的甄别准确率达到93%左右,对各种类型的网页具有较强的稳健性能和泛化性能。
附图说明
图1为本发明实施例的整体框架图;
图2为本发明实施例中工作节点的框架图;
图3为本发明实施例中基于多模态融合的网页识别模型框架图。
具体实施方式
下面结合附图对本发明的实施例进行详细说明。
实施例1
一种基于分布式智能搜索引擎的高校学者信息检索方法,包括以下步骤:
步骤1:获取国内外高等学府主页的网址(URL),整理为输入数据;
步骤2:搭建由一个数据节点与多个工作节点构成主从分布式搜索引擎。
步骤3:将步骤1中的数据集输入步骤2搭建的分布式搜索引擎中,分布式搜索引擎会自动根据高校主页网址(URL)访问高校网站,并基于广度优先遍历的原则,从层层高校官网中获取网页。
步骤4:目标网页识别器会根据网页中的图像性、内容性和布局性特征准确识别当前网页是否为学者信息页面。
步骤5:信息提取器会根据预定义规则自动抽取学者的细粒度信息。例如根据页面布局及命名规则抽取姓名、所属机构、联系方式,根据URL、链接锚文本及头像个数抽取头像信息;根据页面布局抽取学术经历、任职、发表文章等信息。
步骤6:抽取的细粒度信息会集中缓存至数据节点服务器中的MongoDB及MySQL数据库中。
步骤7:URL提取器从页面中提取所有URL。URL过滤器根据链接锚文本过滤掉噪声URL(如新闻URL、图片URL、域名之外的URL)。
步骤8:URL等级队列会根据链接锚文本将URL划分不同的等级,并赋予等级标签(学者信息主页为第一等级、院系主页是第二等级、其他页面是第三等级)并存储到等级队列中。调节器会根据URL标签的等级,从URL队列中提取URL并送入下载器中。这样,就可以提升学者信息页面的访问速度。
步骤9:从数据节点服务器中提取学者细粒度信息,基于ElasticSearch构建倒排索引及信息检索功能。
步骤10:从数据节点服务器中提取学者细粒度信息,从学者信息中挖掘出学者之间的任职网络、合著网络及引用网络,构建以学者为核心的知识图谱,并存储进Neo4J图结构数据库中,便于后续检索及研究。
所述步骤2中的分布式智能搜索引擎是由一个数据节点服务器和多个工作节点服务器组成的主从结构的分布式架构,各个节点服务器之间通过局域网通信。
所述步骤2中的数据节点服务器配备URL等级队列、数据库、服务器监控端等,主要负责代码与任务(URL)分发、数据存储、工作节点状态监控三项任务(如图1所示)。
所述步骤2中的工作节点服务器配备下载器、URL调节器、URL过滤器、URL提取器、教师主页识别器、页面内容提取器等。主要负责网页下载、目标网页识别、目标信息提取、URL提取与筛选、状态汇报五项任务。基于广度优先遍历的原则,工作节点中的下载器从高校官网获取网页,目标识别器判断该网页是否是教工主页,内容提取器从教工主页中提取目标信息。获取的网页需要经过URL提取器、URL过滤器的处理得到较为纯净的URL(如图2所示)。
所述步骤3中的工作节点摒弃了传统的暴力搜索方式,遵循人工预定义的最优访问路径“University/College→School/Department/Program→Faculty homepage”开展网页搜索,大幅度降低时间复杂度。URL等级队列与URL调节器是实现这一技术的关键组件。
所述步骤4中的目标页面识别器(如图3所示)。这个目标页面识别器由一个多模态生成对抗网络与一个门限融合网络构成。其中,多模态生成对抗网络由三个生成器(文本特征生成器、布局特征生成器与图像特征生成器)与一个判别器构成,这两组模型通过零和博弈达到优化目的。三个生成器负责将服从先验高斯分布的噪声向量转化为对应的虚假特征向量,判别器负责判别输入的特征向量是否由生成器合成,并通过损失函数梯度的反向传播,指导生成器改进合成的虚假特征向量。为了保持多模态特征向量之间的交互性,三个生成器通过拼接合成的虚假特征向量,达到信息共享的目的。
所述步骤4中的目标页面识别器(如图3所示)。这个目标页面识别器由一个多模态生成对抗网络与一个门限融合网络构成。其中,门限融合网络首先利用基于Sigmoid激活函数构建的门限机制从多模态特征向量(文本性特征向量、布局性特征向量与图像性特征向量)中提取关键信息,然后利用基于克罗内克积构建的融合机制整合这些关键信息向量,最后将整合的特征向量输出到Softmax分类决策层判断该页面是否为学者信息页面。门限融合网络通过在增广的平衡数据集上训练,可以缓解由数据不均衡带来的性能损失,达到提升识别准确性的目的。
实施例2
一种基于分布式智能搜索引擎的高校学者信息检索方法,包括以下步骤:
步骤1:获取国内外高等学府主页的网址(URL),整理为输入数据;
步骤2:搭建由一个数据节点与多个工作节点构成主从分布式搜索引擎。
步骤3:将步骤1中的数据集输入步骤2搭建的分布式搜索引擎中,分布式搜索引擎会自动根据高校主页网址(URL)访问高校网站,并基于广度优先遍历的原则,从层层高校官网中获取网页。
步骤4:目标网页识别器会根据网页中的图像性、内容性和布局性特征准确识别当前网页是否为学者信息页面。
步骤5:信息提取器会根据预定义规则自动抽取学者的细粒度信息,例如姓名、头像、所属机构、联系方式、学术经历、任职、发表文章等。
步骤6:抽取的细粒度信息会集中缓存至数据节点服务器中的MongoDB及MySQL数据库中。
步骤7:URL提取器及URL过滤器会根据预定义规则自动从页面中抽取并筛选有用的URL。
步骤8:URL等级队列及调节器会根据预定义规则,判断每个URL的重要性,并自动调节URL的访问顺序,提升学者信息页面的访问速度。
步骤9:从数据节点服务器中提取学者细粒度信息,基于ElasticSearch构建倒排索引及信息检索功能。
步骤10:从数据节点服务器中提取学者细粒度信息,从学者信息中挖掘出学者之间的任职网络、合著网络及引用网络,构建以学者为核心的知识图谱,并存储进Neo4J图结构数据库中,便于后续检索及研究。
该分布式智能搜索引擎是由一个数据节点服务器与多个工作节点服务器组成的主从分布式架构集群。其中,数据节点服务器配备URL等级队列、数据库、服务器监控端等,主要负责代码与任务(URL)分发、数据存储、工作节点状态监控三项任务。工作节点服务器配备下载器、URL调节器、URL过滤器、URL提取器、教师主页识别器、页面内容提取器等。主要负责网页下载、目标网页识别、目标信息提取、URL提取与筛选、状态汇报五项任务。基于广度优先遍历的原则,工作节点中的下载器从高校官网获取网页,目标识别器判断该网页是否是教工主页,内容提取器从教工主页中提取目标信息。获取的网页需要经过URL提取器、URL过滤器的处理得到较为纯净的URL。
工作节点服务器摒弃了传统的暴力搜索方式,遵循人工预定义的最优访问路径“University/College→School/Department/Program→Faculty homepage”开展网页搜索,大幅度降低时间复杂度。URL等级队列与URL调节器是实现这一技术的关键组件。
目标页面识别器由一个多模态生成对抗网络与一个门限融合网络构成。其中,多模态生成对抗网络由三个生成器(文本特征生成器、布局特征生成器与图像特征生成器)与一个判别器构成,这两组模型通过零和博弈达到优化目的。三个生成器负责将服从先验高斯分布的噪声向量转化为对应的虚假特征向量,判别器负责判别输入的特征向量是否由生成器合成,并通过损失函数梯度的反向传播,指导生成器改进合成的虚假特征向量。为了保持多模态特征向量之间的交互性,三个生成器通过拼接合成的虚假特征向量,达到信息共享的目的。门限融合网络首先利用基于Sigmoid激活函数构建的门限机制从多模态特征向量(文本性特征向量、布局性特征向量与图像性特征向量)中提取关键信息,然后利用基于克罗内克积构建的融合机制整合这些关键信息向量,最后将整合的特征向量输出到Softmax分类决策层判断该页面是否为学者信息页面。门限融合网络通过在增广的平衡数据集上训练,可以缓解由数据不均衡带来的性能损失,达到提升识别准确性的目的。
对国内外高校学者信息开展收集与检索,可有利于对教师及学者信息进行综合统计分析,获取涉及国家安全的战略信息;可有利于了解科技前沿的热点、重心及其趋势变化;可有利于打造全球最大的高校学者知识图谱和关系网络,理清不同学术流派的人际关系脉络,挖掘具有科研潜力的青年才俊。但是百度学术、Google学术等主流学术搜索引擎都不具备以高校学者为核心的信息检索功能。为了弥补相关领域的不足,本实施例通过构建基于多模态融合网页识别技术的分布式智能搜索引擎,收集国内外高等学府在各个领域的科研论文数据与海量学者信息,构建国内最大的科研论文信息库与学者信息库。其中,基于多模态融合的网页识别模型主要利用门限融合网络,整合网页中的图像性、内容性和布局性特征达到提升高校学者主页识别的准确性。此外,针对数据特征不均衡导致识别模型训练效果差的问题,提出了针对图像性、内容性和布局性特征生成的多模态生成对抗网络。
以上所述实施例仅表达了本发明的具体实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
- 一种用于搜索引擎的统一信息检索智能体系统与方法
- 基于搜索引擎的信息检索方法、装置、设备和存储介质