一种彩色可见光与深度图像显著性目标检测方法
文献发布时间:2024-04-18 19:58:21
技术领域
本发明涉及一种显著物体检测技术,尤其是涉及一种彩色可见光与深度图像显著性目标检测方法。
背景技术
显著物体检测(Salient Object Detection,SOD)旨在定位和突出捕获的RGB图像中最突出的区域或物体,它已被广泛用于计算机视觉领域的预处理过程,如图像理解、物体检测、图像分类、语义分割、质量评估、图像检索、图像剪切、图像重定位等。然而,由于RGB图像显著物体检测方法高度依赖于颜色、纹理或轮廓信息,仅仅依靠RGB信息来定位突出的物体仍然是一个具有挑战性的问题,特别是在具有挑战性或复杂的场景中,如遮挡、照明条件差或对比度低的场景。因此,近年来,多模态显著物体检测通过引入互补模态信息来克服上述挑战而变得流行。
热图像可以反映物体的温度,即使是在一些极端的环境中(如光照不足或有雾)也能实现;深度图像包含物体的几何结构信息。因此,RGB-T(RGB图像与热图像)显著物体检测和RGB-D(RGB图像与深度图像)显著物体检测已被证明是通过引入热图像和深度图像作为辅助信息来提高显著物体检测任务的性能的有效方法。与反映物体温度和显示物体轮廓的热图像不同,深度信息包含了丰富的几何结构信息和三维空间布局细节,因此,人们对RGB-D显著物体检测的兴趣大增。
当前针对多模态显著性目标检测还存在以下几个问题:
第一,如何实现跨模态融合。跨模态融合的关键是有效挖掘不同模态之间的共性和差异,然后通过一定的方法增加共性,减少差异。由于采集设备的不同,RGB图像和深度图像之间存在固有的模态差异,其中RGB图像包含丰富的颜色纹理信息,而深度图像包含清晰的几何结构信息。现有的方法主要是利用深度信息来补充RGB图像中结构信息的不足,或者设计复杂的模块来获得融合特征。尽管这些方法在RGB-D显著物体检测任务中表现良好,但它们没有充分利用两种模态之间的信息互补性。因此,通过分析不同模态以及不同层级特征的信息,设计出对应的低级特征融合模块和高级特征融合模块,有效地实现跨模态融合,这对于提高多模态显著性目标检测的准确度有着十分重要的作用。
第二,如何进行跨层次的特征交互。不同层次的特征所代表的信息是不同的,高层次的特征包括语义信息,而低层次的特征包括详细信息。因此,在推断突出对象的过程中,探索不同层次特征的作用是值得的。然而,现有的大多数方法都忽略了这个问题,并且在探索跨层次特征之间的相互作用方面做的努力有限。
发明内容
本发明所要解决的技术问题是提供一种彩色可见光与深度图像显著性目标检测方法,其能够有效地提高显著性目标检测的准确度。
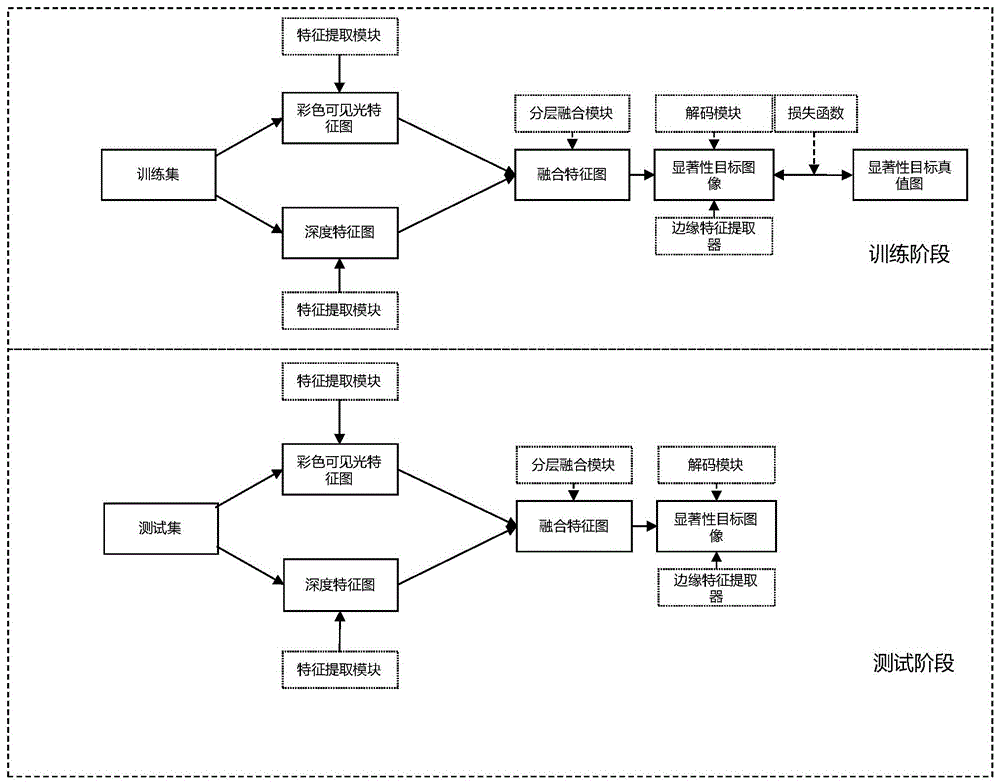
本发明解决上述技术问题所采用的技术方案为:一种彩色可见光与深度图像显著性目标检测方法,该方法首先构建一个包含数对彩色可见光图像及其对应的深度图像的训练集,并搭建一个神经网络;其次将训练集中的数对彩色可见光图像及其对应的深度图像输入到神经网络中进行多轮网络训练,网络训练结束后得到神经网络训练模型;再次使用神经网络训练模型对测试图像对进行预测,预测得到测试图像对的显著性目标图像,其特征在于:所述神经网络主要由特征提取模块、分层融合模块、边缘特征提取器、解码模块构成,所述解码模块由语义引导模块和跨层融合解码器构成,其中:
所述特征提取模块包括两个Swin Transformer骨干网路;第1个SwinTransformer骨干网络的第一层的输入端接收一幅大小为H×W×3的彩色可见光图像,第1个Swin Transformer骨干网络的第一层的输出端输出的特征图记为FR
所述分层融合模块包括三个结构相同的低级特征融合块和两个结构相同的高级特征融合块;第1个低级特征融合块的第一输入端接收FR
所述边缘特征提取器的第一输入端接收FD
所述语义引导模块的第一输入端接收
所述跨层融合解码器的第一输入端接收
训练集的构建过程为:选取至少200对原始彩色可见光图像及其对应的原始深度图像;然后对每幅原始彩色可见光图像及其对应的原始深度图像进行降采样操作,将图像大小降采样为H×W;再将所有大小为H×W的彩色可见光图像及其对应的深度图像构成训练集。
神经网络训练模型的获得过程为:将训练集中的每对彩色可见光图像及其对应的深度图像输入到神经网络中进行网络训练,在每轮网络训练结束之前计算损失函数Loss来优化神经网络,在总共进行250轮网络训练后得到神经网络训练模型;其中,
使用神经网络训练模型对测试图像对进行预测,预测得到测试图像对的显著性目标图像的过程为:任意选取一对原始彩色可见光图像及其对应的原始深度图像;然后对该对原始彩色可见光图像及其对应的原始深度图像进行降采样操作,将图像大小降采样为H×W,并作为测试图像对;再将测试图像对输入到神经网络训练模型中,预测得到测试图像对的显著性目标图像。
所述低级特征融合块主要由第1个卷积层至第10个卷积层、第1个BatchNormalization层至第6个Batch Normalization层、第1个ReLU激活层至第8个ReLU激活层、第1个空间注意力层、第2个空间注意力层、第1个平均池化层、第2个平均池化层、第1个Softmax激活层和第2个Softmax激活层组成;对于第i个低级特征融合块,第1个卷积层的输入端作为第i个低级特征融合块的第一输入端接收FR
其中,i=1,2,3,FR
所述高级特征融合块主要由第11个卷积层至第19个卷积层、第7个BatchNormalization层至第11个Batch Normalization层、第9个ReLU激活层至第15个ReLU激活层、第1个最大池化层、第3个平均池化层、第1个通道注意力层至第3个通道注意力层、第1个Sigmoid激活层组成;对于第j个高级特征融合块,第1个通道注意力层的输入端作为第j个高级特征融合块的第一输入端接收FR
其中,j=4,5,FR
所述语义引导模块主要由第20个卷积层至第29个卷积层、第12个BatchNormalization层、第16个ReLU激活层、第4个平均池化层、第2个Sigmoid激活层和第三个Sigmoid激活层组成;第4个平均池化层的输入端、第21个卷积层的输入端、第22个卷积层的输入端、第23个卷积层的输入端均作为语义引导模块的第二输入端接收
其中,第4个平均池化层为自适应平均池化层,第20个卷积层至第29个卷积层均为2D卷积层,第20个卷积层的输入尺寸为
所述边缘特征提取器主要由第30个卷积层至第38个卷积层、第13个BatchNormalization层、第14个Batch Normalization层、第17个ReLU激活层至第24个ReLU激活层、第1个上采样层、第2个上采样层、第4个通道注意力层组成;第30个卷积层的输入端作为边缘特征提取器的第一输入端接收FD
其中,第30个卷积层至第38个卷积层均为2D卷积层,第30个卷积层的输入尺寸为
所述跨层融合解码器主要由第39个卷积层至第49个卷积层、第15个BatchNormalization层至第20个Batch Normalization层、第25个ReLU激活层至第31个ReLU激活层、第3个上采样层至第12个上采样层、第5个通道注意力层、第3个空间注意力层至第5个空间注意力层组成;第5个通道注意力层的输入端作为跨层融合解码器的第五输入端接收S
其中,第39个卷积层至第49个卷积层均为2D卷积层,第39个卷积层的输入尺寸为
与现有技术相比,本发明的优点在于:
1)本发明方法构建的神经网络采用Swin Transformer骨干网络进行特征提取,从彩色可见光图像和深度图像中提取特征;然后采用低级特征融合块和高级特征融合块对模态信息进行充分的挖掘与融合,并实现了跨层级特征之间的交互;再采用语义引导模块生成语义引导特征,利用语义引导特征来指导低级融合特征的解码,最后加入边缘特征解码出准确的显著目标检测结果。
2)本发明方法基于挖掘不同模态之间的共性,减少不同模态之间的差异有利于多模态特征的融合的事实,在构建的神经网络中通过引入低级特征融合块和高级特征融合块来解决模态之间的差异问题,通过低级特征融合块挖掘两种模态之间的信息,实现两种模态的融合,通过高级特征融合块生成不同模态的权重,实现对模态质量的自适应选择,通过分段融合模块以充分挖掘单一模态的信息,减少不同模态之间的差异,提高彩色可见光与深度图像显著性目标检测的准确性。
3)本发明方法针对特征表示的尺度差异问题,在构建的神经网络中采用了多级细化解码模块,该模块通过使用具有不同感受野的尺度灵活卷积来提取跨模态多尺度特征,并结合高级融合特征生成语义引导特征,对低级融合特征进行引导实现解码,解决不同层级特征之间存在的差异问题,从而有效地提高了彩色可见光与深度图像显著目标检测的准确性。
附图说明
图1为本发明方法的总体实现框图;
图2为本发明方法搭建的神经网络的组成结构示意图;
图3为本发明方法搭建的神经网络中的低级特征融合块的组成结构示意图;
图4为本发明方法搭建的神经网络中的高级特征融合块的组成结构示意图;
图5为本发明方法搭建的神经网络中的语义引导模块的组成结构示意图;
图6为本发明方法搭建的神经网络中的边缘特征提取器的组成结构示意图;
图7为本发明方法搭建的神经网络中的跨层融合解码器的组成结构示意图。
具体实施方式
以下结合附图实施例对本发明作进一步详细描述。
本发明提出的一种彩色可见光与深度图像显著性目标检测方法,其总体实现框图如图1所示,该方法首先构建一个包含数对彩色可见光图像及其对应的深度图像的训练集,并搭建一个神经网络;其次将训练集中的数对彩色可见光图像及其对应的深度图像输入到神经网络中进行多轮网络训练,网络训练结束后得到神经网络训练模型;再次使用神经网络训练模型对测试图像对进行预测,预测得到测试图像对的显著性目标图像,如图2所示,神经网络主要由特征提取模块、分层融合模块、边缘特征提取器、解码模块构成,解码模块由语义引导模块和跨层融合解码器构成,其中:
所述特征提取模块包括两个Swin Transformer骨干网路;第1个SwinTransformer骨干网络的第一层的输入端接收一幅大小为H×W×3的彩色可见光图像,第1个Swin Transformer骨干网络的第一层的输出端输出的特征图记为FR
所述分层融合模块包括三个结构相同的低级特征融合块和两个结构相同的高级特征融合块;第1个低级特征融合块的第一输入端接收FR
所述边缘特征提取器的第一输入端接收FD
所述语义引导模块的第一输入端接收
所述跨层融合解码器的第一输入端接收
在一个具体的实施例中,训练集的构建过程为:选取至少200对原始彩色可见光图像及其对应的原始深度图像;然后对每幅原始彩色可见光图像及其对应的原始深度图像进行降采样操作,将图像大小降采样为H×W;再将所有大小为H×W的彩色可见光图像及其对应的深度图像构成训练集;其中,在该实施例中选取2185对原始彩色可见光图像及其对应的原始深度图像,H=W=384。
在一个具体的实施例中,神经网络训练模型的获得过程为:将训练集中的每对彩色可见光图像及其对应的深度图像输入到神经网络中进行网络训练,在每轮网络训练结束之前计算损失函数Loss来优化神经网络,在总共进行250轮网络训练后得到神经网络训练模型;其中,
在一个具体的实施例中,使用神经网络训练模型对测试图像对进行预测,预测得到测试图像对的显著性目标图像的过程为:任意选取一对原始彩色可见光图像及其对应的原始深度图像;然后对该对原始彩色可见光图像及其对应的原始深度图像进行降采样操作,将图像大小降采样为H×W,并作为测试图像对;再将测试图像对输入到神经网络训练模型中,预测得到测试图像对的显著性目标图像;其中,H=W=384。
三个低级特征融合块的结构相同,只是输入和输出不同,在一个具体的实施例中,如图3所示,所述低级特征融合块主要由第1个卷积层至第10个卷积层、第1个BatchNormalization层(批量归一化层)至第6个Batch Normalization层、第1个ReLU激活层至第8个ReLU激活层、第1个空间注意力层、第2个空间注意力层、第1个平均池化层、第2个平均池化层、第1个Softmax激活层和第2个Softmax激活层组成;对于第i个低级特征融合块,第1个卷积层的输入端作为第i个低级特征融合块的第一输入端接收FR
两个高级特征融合块的结构相同,只是输入和输出不同,在一个具体的实施例中,如图4所示,高级特征融合块主要由第11个卷积层至第19个卷积层、第7个BatchNormalization层至第11个Batch Normalization层、第9个ReLU激活层至第15个ReLU激活层、第1个最大池化层、第3个平均池化层、第1个通道注意力层至第3个通道注意力层、第1个Sigmoid激活层组成;对于第j个高级特征融合块,第1个通道注意力层的输入端作为第j个高级特征融合块的第一输入端接收FR
在一个具体的实施例中,如图5所示,语义引导模块主要由第20个卷积层至第29个卷积层、第12个Batch Normalization层、第16个ReLU激活层、第4个平均池化层、第2个Sigmoid激活层和第三个Sigmoid激活层组成;第4个平均池化层的输入端、第21个卷积层的输入端、第22个卷积层的输入端、第23个卷积层的输入端均作为语义引导模块的第二输入端接收
在一个具体的实施例中,如图6所示,边缘特征提取器主要由第30个卷积层至第38个卷积层、第13个Batch Normalization层、第14个Batch Normalization层、第17个ReLU激活层至第24个ReLU激活层、第1个上采样层、第2个上采样层、第4个通道注意力层组成;第30个卷积层的输入端作为边缘特征提取器的第一输入端接收FD
如图7所示,跨层融合解码器主要由第39个卷积层至第49个卷积层、第15个BatchNormalization层至第20个Batch Normalization层、第25个ReLU激活层至第31个ReLU激活层、第3个上采样层至第12个上采样层、第5个通道注意力层、第3个空间注意力层至第5个空间注意力层组成;第5个通道注意力层的输入端作为跨层融合解码器的第五输入端接收S
为了进一步说明本发明方法的可行性和有效性,对本发明方法进行试验。
在本实施例中,采用本发明方法对彩色可见光与深度图像显著目标检测数据集(NJU2K)进行试验。NJU2K数据集中的训练集包括1485对彩色可见光图像和深度图像,NJU2K数据集中的测试集总共有500对彩色可见光图像和深度图像。
在本实施例中,选用4个常用的客观参量来评估本发明方法的性能,它们分别是S-measure、E-measure、F-measure、Mean Absolute Error(MAE)。表1给出了在NJU2K数据集上采用本发明方法得到的显著性目标图像与标签图像即显著性目标真值图之间的相关性。
表1采用本发明方法在NJU2K数据集上得到的显著性目标图像与标签图像之间的S-measure、E-measure、F-measure、Mean Absolute Error(MAE)
从表1中给出的结果可以发现,本发明方法在现有的彩色可见光与深度图像显著目标检测数据集上取得了较高的S-measure、E-measure、F-measure和较低的MAE,这说明本发明方法取得的显著性目标图像和标签图像之间较为接近,本发明方法可以有效地完成彩色可见光与深度图像的显著目标检测。
- 一种基于深度学习的高分辨率图像显著性目标检测方法
- 一种结合彩色和深度信息的图像显著目标检测方法