一种基于CatBoost模型的熟料立升重预测方法
文献发布时间:2024-04-18 19:58:26
技术领域
本发明涉及水泥工业生产技术领域,具体地,涉及一种基于CatBoost模型的熟料立升重预测方法。
背景技术
在新型干法水泥回转窑熟料烧成过程中,因立升重能反映熟料烧结情况和质量情况,测定立升重具有重要意义,第一衡量质量情况,第二可以反映窑内温度控制高低的标准,故而作为生产中质量检测项目之一,工厂会对熟料立升重进行测定。
熟料立升重是指一定粒度熟料单位容量的重量,以g/L表示,为了及时掌握出窑熟料的质量,除了根据其外观特征进行鉴别外,还可以测定熟料立升重来鉴别熟料的质量。立升重太低或者过高都说明熟料烧制状态不佳。对于结粒大的熟料,其表面积会影响篦冷机的热回收效率。
在现有的水泥生产控制过程中,大部分企业熟料立升重是通过人工检测得到。熟料立升重一般2小时检测一次,或者4小时检测一次,周期长,如要以立升重指导回转窑控制,则滞后性大,随机误差大,不满足控制要求,因此,提供一种及时、快捷预测熟料立升重方法来解决以上提到的技术问题。
发明内容
为了克服现有技术的不足,本发明提供了一种基于CatBoost模型的熟料立升重预测方法,通过对熟料立升重的在线预测,增强对回转窑熟料煅烧过程的控制、质量控制及温度控制,进而对烧成温度进行精准控制,达到节能减排的目的。
本发明的有益效果为:
本发明结合水泥生产工艺的流程,在生料预处理阶段对水泥生产的入料生料成分采集数据计算液相量数据,在烧制过程采用多点数据汇总进行处理,得出烧成带温度计算模型,得到液相量和烧成带温度两个特征维度数据后,利用这两个关键维度数据使用人工智能技术中的CatBoost模型,它基于优秀的GBDT算法,解决了梯度偏差以及预测偏移的问题,在多次训练后模型对水泥生产的入料生料成分和烧制过程数据的处理,减少过拟合的发生,进而提高预测的准确性和泛化能力,训练在达到最佳度量时停止训练,保留的最佳模型在预测效果上表现较高的贴合度,误差均在控制范围内,部署框架从而及时对熟料立升重进行预测,生成的CatBoost模型能够快速的进行实时预测,能够及时对水泥生产的入料配比、燃烧过程中篦冷机的温度进行调整操作,提高篦冷机换热效率,降低热耗,使得水泥生产工艺整体效率能够更加高效,熟料品质有效提高,及时智能化反馈降低工人作业强度。
附图说明:
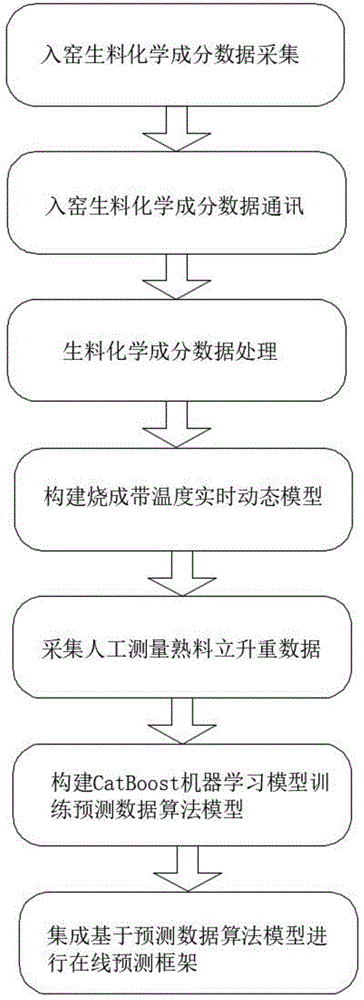
图1为本发明基于CatBoost机器学习的熟料立升重预测方法的流程图;
图2为水泥生产流程图;
图3为本发明所述烧成带温度数据曲线图;
图4为本发明所述Catboost训练过程可视化图;
图5为本发明熟料预测效果与历史数据对比图;
具体实施方式
为了使本发明的发明目的,技术方案及技术效果更加清楚明白,下面结合具体实施方式对本发明做进一步的说明。应理解,此处所描述的具体实施例,仅用于解释本发明,并不用于限定本发明。
参照图1-2,在新型干法水泥回转窑熟料烧成过程中,工艺步骤可以概括分为:水泥原料破碎、原料预均化、配料控制、生料均化、预热分解、回转窑、冷却和熟料库等步骤,整个工艺中包含生料的处理、燃烧和燃烧后处理,每个环节都会影响到熟料的品质,通常在燃烧后对熟料进行熟料立升重的测定,熟料立升重的高低是评定熟料质量和烧成带温度参考依据之一,熟料立升重是指一定粒度熟料单位容量的重量,以g/L表示,为了及时掌握出窑熟料的质量,除了根据其外观特征进行鉴别外,还可以测定熟料立升重以及熟料FCao含量来鉴别熟料的质量。立升重太低,说明熟料欠烧,反之,说明熟料过烧。对于结粒大的熟料,其表面积越小,在篦冷机中换热效率会变差,最终会影响篦冷机的热回收效率。
因立升重能反映熟料烧结情况和质量情况,故而作为生产中质量检测项目之一。测定立升重具有重要意义,第一衡量质量情况,第二可以反映窑内温度控制高低的标准,一般温度高,立升重高;立升重低,对节煤有利;立升重控制稳定,表示窑内温度控制稳定,控制结粒,可以提高换热,降低热耗。在水泥熟料烧成控制过程中,我们最终目标就是控制熟料质量,控制结粒大小,达到节能降耗的目的。故而这个问题若转换为控制立升重,控制结粒大小,那么进行可以提高篦冷机换热效率,降低热耗。
因立升重能反映熟料烧结情况和质量情况,测定立升重具有重要意义,第一衡量质量情况,第二可以反映窑内温度控制高低的标准,故而作为生产中质量检测项目之一,工厂会对熟料立升重进行测定。
影响熟料立升重的主要因素有:生料中所含液相量以及各种的组成比例;熟料的烧结过程及冷却过程;预测熟料立升重需要对生料的成分进行测定,本发明一种基于CatBoost模型的熟料立升重预测方法在生产的工艺中原料预均化的处理后采样生料,进行步骤1生料化学成分数据的采集,所述步骤1的流程包括:S101生料进行破碎和预均化处理后采集样本、S102对生料样本进行磨片处理、S103对生料样本进行压光处理、S104导入荧光分析仪进行检测、S105导出荧光仪数据。采集的数据进行步骤2和步骤3的操作。
在生料进入回转窑再次进行数据采集,由于回转窑的窑体较长,又分为四个带,而烧成带作为煅烧的主要区域,烧成带温度是窑内煅烧情况的直接表现,也是回转窑内最重要的温度。烧成带温度的高低很大程度上决定了水泥熟料质量的高低,因此烧成带温度的高低对熟料立升重也有一定的影响,在实际生产过程中回转窑烧成带温度不能在线实时测量;而目前水泥行业,现场中控操作人员普遍通过工业看火电视系统画面,结合其他窑内生产过程参数,综合判断水泥回转窑烧成带温度和窑况情况。通过汲取现场优秀操作人员工作经验,得知影响回转窑烧成带温度的因素有很多,且相互之间耦合性很强,评估烧成带温度的关键相关特征变量有:窑尾气体分析仪NO
所述步骤4的中,涉及窑尾气体分析仪NO
在实际生产过程中回转窑烧成带温度不能在线实时测量,目前水泥行业,现场中控操作人员普遍通过工业看火电视系统画面,结合其他窑内生产过程参数,综合判断水泥回转窑烧成带温度和窑况情况。通过汲取现场优秀操作人员工作经验,得知影响回转窑烧成带温度的因素有很多,且相互之间耦合性很强,评估烧成带温度的关键相关特征变量有:窑尾气体分析仪NOx、窑前二次风温度,窑主机电流、窑尾烟室温度。在现场使用窑尾气体分析仪NOx,窑前二次风温度通常采用抽气热电偶测量二次风温,窑主机电流通过设备导出数据,窑尾烟室温度采用非接触式的方式进行测定,常见的有辐射式温度计或者光学式、比色式或红外式的温度仪器,在现场进行测定后通过opc接口采集现场DCS数据,OPC是用于过程控制的OLE,以OLE/COM/DCOM技术为基础,采用客户/服务器模式,它的出现为基于应用程序和现场过程控制应用建立了桥梁,它提供了一种通用的数据读取的方式。所述步骤4的流程包括:S401通过opc接口采集现场DCS数据,包括窑尾气体分析仪NOx,二次风温,窑主机电流,窑尾烟室温度等4个数据;采集的数据往往存在误差,所以要对所采集的数据进行进一步处理。对窑尾气体分析仪NOx、窑前二次风温度,窑主机电流、窑尾烟室温度进行均值滤波处理,均值滤波也称为线性滤波,其采用的主要方法为邻域平均法。线性滤波的基本原理是用均值代替原图像中的各个像素值,即对待处理的当前像素点(x,y),选择一个模板,该模板由其近邻的若干像素组成,求模板中所有像素的均值,再把该均值赋予当前像素点(x,y),作为处理后图像在该点上的灰度g(x,y),即g(x,y)=∑f(x,y)/m m为该模板中包含当前像素在内的像素总个数。
对以上4个指标数据集进行归一化数据处理,归一化就是要把需要处理的数据经过处理后限制在需要的一定范围内。首先归一化是为了后面数据处理的方便,其次是保证程序运行时收敛加快。归一化的具体作用是归纳统一样本的统计分布性。归一化在0-1之间是统计的概率分布,归一化在某个区间上是统计的坐标分布。将数据值映射到[0,1]之间。转换公式如下:
S407对所有归一化数据进行权重计算,计算出各个指标的权重,为多指标综合评价提供依据,采用熵权法进行赋值;
给定4个指标数据集{X1,X2,X3,X4},进行归一化指标数据集为{Y1,Y2,Y3,Y4},根据信息论中信息熵的定义,一组数据的信息熵为:
其中,
根据信息熵的计算公式,计算出各个指标的信息熵为{E1,E2,E3,E4},通过信息熵计算各指标的权重:
其中,K=4;
S408计算完四个指标的权重之后,对归一化之后的指标特征进行加权求和得到最终得分,并把得分对应换算成温度,得到烧成带温度数据,将得到的烧成带温度导出如图3所示。
S409将烧成带温度数据记录到数据库C中。
6如权利要求1所述一种基于CatBoost模型的熟料立升重预测方法,所述步骤5的流程包括:
S501人工测定熟料立升重数据,具体操作步骤如下:
S5011人工每小时从熟料机上取出的熟料倒在筛动筛上,启动振动电机,筛动振动筛;
S5012通过筛孔漏入的熟料倒入升重筒内;
S5013用玻璃板将高出升重筒口的熟料刮掉,使其与升重筒面水平,然后称重通过人工称重数据;
S502按照公式以下公式对数据进行计算:
立升重=(总重量-升重筒重量)/升重筒体积(g/l)
S503将计算的立升重数据记录到数据库D中;
所述步骤6的流程包括:
S601读取步骤2中数据B、步骤3中数据库C和步骤5中的数据库D,通过pandas导入通过液相量、烧成带温度、立升重三个维度历史数据;
S602:切分数据,将液相量、烧成带温度、立升重数据整体对应后划分成四份,其中三份划分为训练集,剩下一份划分为测试集;
S603将训练集和测试集导入CatboostRegressor回归器并将其实例化;
S604导入训练集数据,设置训练参数,
S605导入测试集数据,交叉验证效果,拟合训练模型;
S606采用GridSearchCV方法进行自动搜索最优参数调;
S607训练过程当中输出的评估指标,评估指标包括平均绝对误差、均方误差,均方根方差和拟合优度,正常立升重控制;
S608训练过程使用Jupyter Notebook或者TensorBoard中实时监测指标变化,整个训练过程可视化;
S609过拟合检测,保留最佳算法模型;
评估指标包括平均绝对误差、均方误差,均方根方差和拟合优度,正常立升重控制,在实施过程中评价指标结果为平均绝对误差MAE为25.5981、均方误差MSE为966.2837、均方根误差RMSE为31.0851、拟合优度R2为0.6391;
如图4所示展示Catboost训练过程中可视化图,平均绝对误差是所有单个观测值与算术平均值的偏差的绝对值的平均。与平均误差相比,平均绝对误差由于离差被绝对值化,不会出现正负相抵消的情况,因而,平均绝对误差能更好地反映预测值误差的实际情况。对同一物理量进行多次测量时,各次测量值及其绝对误差不会相同,将各次测量的绝对误差取绝对值后再求平均值,并称其为平均绝对误差。因此我们将使用平均绝对误差来评估我们的立升重预测效果。正常立升重控制误差在1200±75左右。我们取得预测平均绝对误差为25.6左右,预测平均绝对误差符合控制要求。
如图4展示立升重预测的效果曲线图,与实际测得立升重值进行对比,数值误差均在控制要求范围内,能够达到预测效果,Catboost模型快速预测,即便应对延时非常苛刻的任务也能够快速高效部署模型。
所述步骤7的流程包括:
S701模型生成后部署成API的形态对外提供服务,设计restfulAPI接口服务;
S202使用Python编写Flask轻量级Web应用框计算,使用BSD授权;
S703采用gunicorn做wsgi容器,部署Python算法接口;
S703使用python+flask+gunicorn框架部署catboost机器学习模型进行实时在线预测。
本发明结合水泥生产工艺的流程,在生料预处理阶段对水泥生产的入料生料成分采集数据计算液相量数据,在烧制过程采用多点数据汇总进行处理,得出烧成带温度计算模型,得到液相量和烧成带温度两个特征维度数据后,利用这两个关键维度数据使用人工智能技术中的CatBoost模型,它基于优秀的GBDT算法,解决了梯度偏差以及预测偏移的问题,在多次训练后模型对水泥生产的入料生料成分和烧制过程数据的处理,减少过拟合的发生,进而提高预测的准确性和泛化能力,训练在达到最佳度量时停止训练,保留的最佳模型在预测效果上表现较高的贴合度,误差均在控制范围内,部署框架从而及时对熟料立升重进行预测,生成的CatBoost模型能够快速的进行实时预测,能够及时对水泥生产的入料配比、燃烧过程中篦冷机的温度进行调整操作,提高篦冷机换热效率,降低热耗,使得水泥生产工艺整体效率能够更加高效,熟料品质有效提高,及时智能化反馈降低工人作业强度。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,其架构形式能够灵活多变,可以派生系列产品。只是做出若干简单推演或替换,都应当视为属于本发明由所提交的权利要求书确定的专利保护范围。
- 一种基于CatBoost模型的交互式门诊量预测可视分析方法及系统
- 一种基于CatBoost和LSTM模型融合的短期负荷预测方法