基于Transformer的目标物体导航方法
文献发布时间:2024-04-18 19:58:26
技术领域
本发明涉及视觉目标物体导航的技术领域,尤其是指一种基于Transformer的目标物体导航方法。
背景技术
在移动机器人与智能家居概念不断发展的背景下,日常家居生活中开始频繁出现移动机器人的身影。而室内导航功能是移动机器人重要的功能之一,随着移动机器人应用场景的丰富,移动机器人需要适应各种各样的未知的家居环境,但是传统的建图导航方法无法满足多种场景下的导航问题。因此,随着深度学习技术的不断发展基于深度强化学习的目标导航方法逐渐兴起,但是现有的方法在效果上和泛化能力上有待提升,如何让移动机器人理解第一视角图像中的语义、位置和物体关系,并通过目标物体名称找到图像中和目标物体关联的物体并执行合适的动作向目标物体方向导航成为亟需解决的问题。
目标物体导航方法是一个未知环境下基于深度强化学习的移动机器人视觉导航系统,将目标物体和图像中的物体关联起来,使得移动机器人能够适应未知的家居环境并完成视觉导航任务。例如,给定目标物体台灯Lamp,移动机器人需要在视觉输入中找到台灯Lamp或者和台灯Lamp关联的物体,并最终导航到台灯前方一米内并执行完成指令。
以往的目标物体导航技术主要存在:在导航过程中,无法找到图像中物体和目标物体的关系,没有发挥目标物体对于移动机器人导航的指导作用,导致导航的效果和泛化能力差。
发明内容
本发明的目的在于克服现有技术的缺点与不足,提出了一种基于Transformer的目标物体导航方法,使用Transformer模型通过编码器和解码器结构,提取当前图像中的语义、位置和物体关系信息,其中多次使用目标物体特征向量作为查询向量发现当前图像和历史图像中与目标物体关联的物体,增强Transformer模型对当前环境和导航过程的认知泛化能力,从而提升导航的效果和泛化能力。
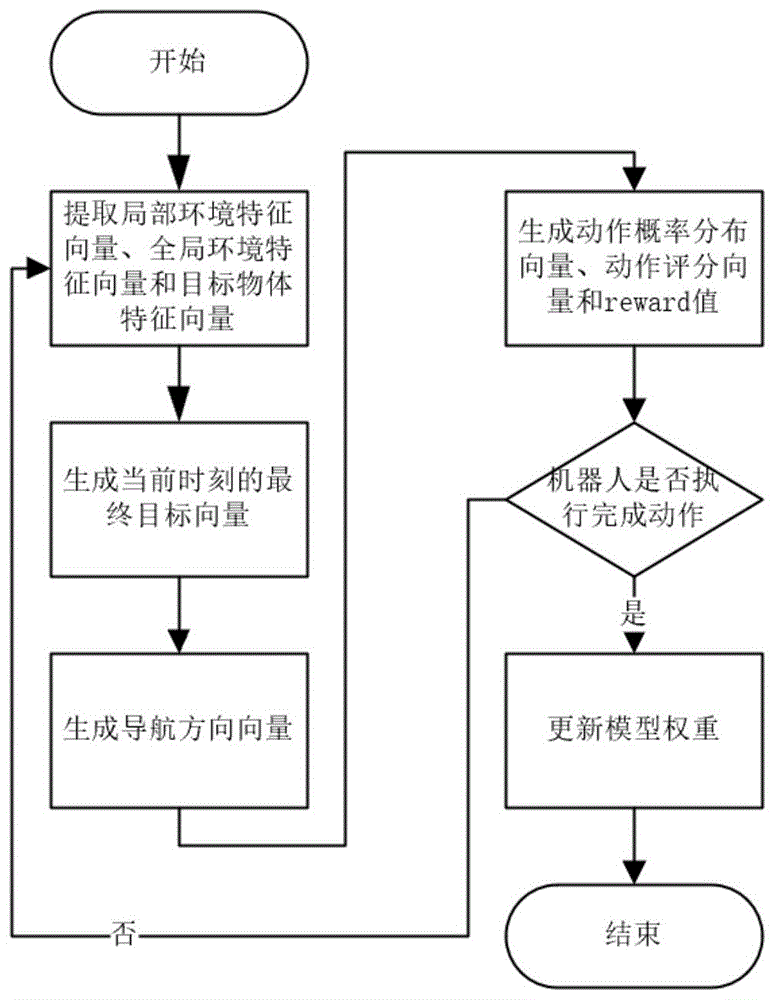
为实现上述目的,本发明所提供的技术方案为:基于Transformer的目标物体导航方法,包括以下步骤:
1)对输入数据的预处理,包括:使用DETR模型对输入的当前时刻环境图片进行提取,得到局部环境特征向量;使用ResNet-18模型对输入的当前时刻环境图片进行提取,得到全局环境特征向量;使用词嵌入模型对目标物体名称嵌入得到目标物体特征向量;
2)将局部环境特征向量、全局环境特征向量和目标物体特征向量输入目标向量Transformer模型得到当前时刻的最终目标向量;
3)将当前时刻的最终目标向量输入导航方向向量Transformer模型得到导航方向向量;
4)将导航方向向量输入到A3C强化学习模型得到当前时刻的动作概率分布向量、动作评分向量和reward值,然后选取动作概率分布向量概率最高的动作执行;
5)重复步骤1)至步骤4),直到机器人执行完成动作,此时一个目标物体导航事件完成,根据不同时刻动作评分向量和reward值更新模型权重。
进一步,在步骤1)中,将当前时刻环境图片输入DETR模型得到局部环境特征向量L
进一步,在步骤2)中,所述目标向量Transformer模型包括视觉编码器、视觉解码器和目标物体解码器,其执行以下操作:通过视觉编码器编码局部环境特征向量得到增强局部环境特征向量,将全局环境特征向量加上位置编码得到增强全局环境特征,将增强局部环境特征向量和增强全局环境特征向量输入视觉解码器得到环境特征向量,将环境特征向量和目标物体特征向量输入目标物体解码器得到当前时刻的初步目标向量,并将当前时刻的初步目标向量通过全连接层降维,将上一时刻的动作概率分布向量通过全连接层升维,将升维后的动作概率分布向量和降维后当前时刻的初步目标向量连结再展平得到当前时刻的最终目标向量。
进一步,所述目标向量Transformer模型使用模仿学习的预训练,使模型能够得到一个好的初始化权重,有利于加快模型正式训练时的收敛速度;模型采用预先机器人在环境中导航的多条示教轨迹作为预训练数据集P={(s
式中,n表示第n条示教轨迹,P(a
进一步,所述步骤2)包括以下步骤:
2.1)使用局部环境特征向量L
L'
式中,Add&Norm()是残差连接和层归一化,Linear()是全连接层,MHA()是多头自注意力机制;
2.2)使用全局环境特征向量G
E
式中,Pos()是位置编码;
将目标物体特征向量T
Lt
将上一时刻的动作概率分布向量a
Lt”
式中,Flatten()是展平,Concate()是连结,LinearUp()是全连接层升维,LinearDown()是全连接层降维。
进一步,在步骤3)中,所述导航方向向量Transformer模型包括视觉编码器和目标物体解码器,其执行以下操作:将当前时刻和上一时刻的最终目标向量堆叠起来并加上位置编码后再输入视觉编码器得到隐层向量,将隐层向量和目标物体特征向量输入目标物体解码器得到导航方向向量。
进一步,所述步骤3)包括以下步骤:
将当前时刻和上一时刻目标向量Transformer模型得到的最终目标向量Lt”
进一步,在步骤4)中,所述A3C强化学习模型包括动作生成网络、动作评分网络和奖惩函数,其执行以下操作;将导航方向向量作为动作生成网络的输入,得到当前时刻的动作概率分布向量,然后选取动作概率分布向量概率最高的动作并执行;将导航方向向量作为动作评分网络的输入,得到当前时刻的动作评分向量,表示动作概率分布向量中概率最高动作的评分;根据奖惩函数生成当前时刻的reward值。
进一步,所述动作生成网络是由一层全连接层构成,输入导航方向向量GT
进一步,所述步骤5)包括以下步骤:
初始时刻给定目标物体名称和当前位置的环境图片,机器人对输入数据预处理,再利用目标向量Transformer模型和导航方向向量Transformer模型分别输出相应的目标向量和导航方向向量,再通过A3C强化学习模型输出一个动作,机器人执行动作到达下一个状态,再次获得目标物体名称和当前位置的环境图片,重复上述过程直到A3C强化学习模型执行完成动作或A3C强化学习模型执行动作次数到达上限自动执行完成动作,此时一个目标物体导航事件完成,根据不同时刻动作评分向量和reward值更新模型权重。
本发明与现有技术相比,具有如下优点与有益效果:
1、本发明使用Transformer模型和目标物体特征向量,可以更好地帮助移动机器人理解图像中的语义、位置、物体关系以及和目标物体的关联。
2、本发明使用Transformer模型提取导航全程的历史上下文并再次使用目标物体特征查询,可以更好地感知导航过程中目标物体的特征信息,并生成导航方向向量。
3、本发明能让机器人根据当前环境图片和目标物体名称进行导航,实验表明所提出的方法具有优秀的性能。
附图说明
图1为本发明逻辑流程示意图。
图2为本发明中提取局部环境特征向量、全局环境特征向量和目标物体特征向量的流程示意图。
图3为本发明中生成初步目标向量的流程示意图。
图4为本发明中生成导航方向向量的流程示意图。
图5为本发明中生成动作概率分布向量和更新模型权重的流程示意图。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
如图1至图5所示,本实施例公开了一种基于Transformer的目标物体导航方法,包括以下步骤:
1)对输入数据的预处理,具体如下:
将当前时刻环境图片输入DETR模型得到局部环境特征向量L
2)将局部环境特征向量、全局环境特征向量和目标物体特征向量输入目标向量Transformer模型,所述目标向量Transformer模型包括视觉编码器、视觉解码器和目标物体解码器,其执行以下操作:通过视觉编码器编码局部环境特征向量得到增强局部环境特征向量,将全局环境特征向量加上位置编码得到增强全局环境特征,将增强局部环境特征向量和增强全局环境特征向量输入视觉解码器得到环境特征向量,将环境特征向量和目标物体特征向量输入目标物体解码器得到当前时刻的初步目标向量,并将当前时刻的初步目标向量通过全连接层降维,将上一时刻的动作概率分布向量通过全连接层升维,将升维后的动作概率分布向量和降维后当前时刻的初步目标向量连结再展平得到当前时刻的最终目标向量;包括以下步骤:
2.1)使用局部环境特征向量L
L'
式中,Add&Norm()是残差连接和层归一化,Linear()是全连接层,MHA()是多头自注意力机制;
2.2)使用全局环境特征向量G
E
式中,Pos()是位置编码;
将目标物体特征向量T
Lt
将上一时刻的动作概率分布向量a
Lt”
式中,Flatten()是展平,Concate()是连结,LinearUp()是全连接层升维,LinearDown()是全连接层降维;
所述目标向量Transformer模型使用模仿学习的预训练,使模型能够得到一个好的初始化权重,有利于加快模型正式训练时的收敛速度;模型采用预先机器人在环境中导航的多条示教轨迹作为预训练数据集P={(s
式中,n表示第n条示教轨迹,P(a
3)将当前时刻的最终目标向量输入导航方向向量Transformer模型,所述导航方向向量Transformer模型包括视觉编码器和目标物体解码器,其执行以下操作:将当前时刻和上一时刻的最终目标向量堆叠起来并加上位置编码后再输入视觉编码器得到隐层向量,将隐层向量和目标物体特征向量输入目标物体解码器得到导航方向向量;包括以下步骤:
将当前时刻和上一时刻目标向量Transformer模型得到的最终目标向量Lt”
4)将导航方向向量输入到A3C强化学习模型,所述A3C强化学习模型包括动作生成网络、动作评分网络和奖惩函数,其执行以下操作;将导航方向向量作为动作生成网络的输入,得到当前时刻的动作概率分布向量,然后选取动作概率分布向量概率最高的动作并执行;将导航方向向量作为动作评分网络的输入,得到当前时刻的动作评分向量,表示动作概率分布向量中概率最高动作的评分;根据奖惩函数生成当前时刻的reward值;
所述动作生成网络是由一层全连接层构成,输入导航方向向量GT
5)重复步骤1)至步骤4),直到机器人执行完成动作,此时一个目标物体导航事件完成,根据不同时刻动作评分向量和reward值更新模型权重,包括以下步骤:
初始时刻给定目标物体名称和当前位置的环境图片,机器人对输入数据预处理,再利用目标向量Transformer模型和导航方向向量Transformer模型分别输出相应的目标向量和导航方向向量,再通过A3C强化学习模型输出一个动作,机器人执行动作到达下一个状态,再次获得目标物体名称和当前位置的环境图片,重复上述过程直到A3C强化学习模型执行完成动作或A3C强化学习模型执行动作次数到达上限自动执行完成动作,此时一个目标物体导航事件完成,根据不同时刻动作评分向量和reward值更新模型权重。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 一种基于transformer的细长类物体目标检测方法
- 基于目标物体的二维图像预测目标物体实时位姿的方法