一种融合AAE和GAN的多模态时间序列异常值检测方法及装置
文献发布时间:2024-04-18 19:58:30
技术领域
本发明属于工业异常检测领域,涉及异常值检测方法,具体是一种融合AAE和GAN的多模态时间序列异常值检测方法及装置。
背景技术
随着制造业数字化和信息化的快速发展,时序数据异常检测在工业领域中变得越来越重要。时序数据是指以时间为自变量的连续性数据集合,常见的时序数据包括温度、压力、电流、振动等工业生产过程中采集的参数和信号,这些数据通常具有高维、非线性和异构性等特点。异常检测是对这些复杂工业时序数据进行监测和分析的关键技术之一。随着人工智能技术的发展,机器学习在工业领域中也得到了广泛应用。将机器学习算法应用到工业时序数据异常检测中,可以为工业生产提供更高效、更精准的解决方案。例如,使用支持向量机、随机森林、深度神经网络等模型做异常检测,可以有效降低误报率和漏报率,提高判别能力和精度。在工业生产过程中,时序数据异常检测是非常重要的一环,它可以帮助企业及时发现异常情况,降低损失、提升效率和质量。同时,现代机器学习技术的发展和应用,为工业时序数据的异常检测提供了更加全面、高效的解决方案,未来机器学习与工业生产的结合将会产生更多价值和创新。
但目前大多异常检测算法通常只使用单一模态数据进行分析,例如仅使用图像数据或文本数据进行异常检测。然而,单一模态数据可能无法提供足够全面和详细的信息,综合多个模态的数据可以提供更丰富的信息,有助于更准确地检测异常。基于以上内容,亟需一种融合AAE和GAN的多模态时间序列异常值检测方法及装置。
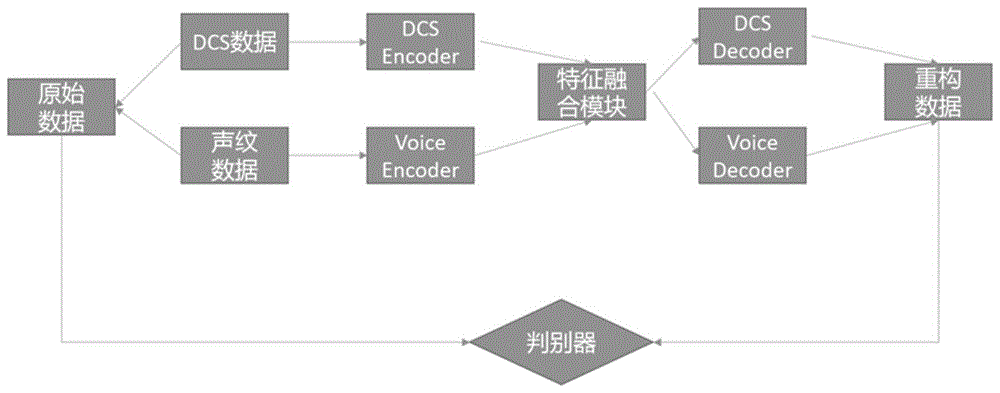
具体通过从实际工业设备上采集的DCS和音频的正常多模态数据训练模型,从而使模型学习到正常数据的特征和重构能力,在异常检测时,则可以通过原始数据与重构数据间的误差来判断数据是否属于异常数据。
发明内容
针对现有技术存在的不足,本发明的目的在于,提供一种融合AAE和GAN的多模态时间序列异常值检测方法及装置,以解决现有技术中异常值检测方法采用单一模态数据进行检测的准确率不高的技术问题。
为了解决上述技术问题,本发明采用如下技术方案予以实现:
一种融合AAE和GAN的多模态时间序列异常值检测方法,具体包括如下步骤:
步骤1,获取多个模态的待检测时序数据,并将其划分为训练集和测试集;
所述的待检测时序数据包括DCS数据和声音数据;
步骤2,将步骤1得到的训练集输入异常检测模型进行训练,得到训练好的异常检测模型;
所述异常检测模型包括生成器和判别器;所述的生成器包括基于注意力机制的自编码器和特征融合模块;所述的基于注意力机制的自编码器包括编码器和解码器,所述的特征融合模块连接在所述的编码器和解码器之间;所述的判别器连接在基于注意力机制的自编码器的输入端;
步骤3,将步骤1得到的测试集输入至训练好的异常检测模型中,得到多个模态的待检测时序数据对应的异常分数;
步骤4,判断所述的异常分数是否大于判别阈值,若是,则测试集中的待检测时序数据为异常数据,若否,则测试集中的待检测时序数据为正常数据。
本发明还包括以下技术特征:
所述的编码器由5个依次相连的Block组成,每个所述的Block包括依次相连的1个注意力层、1个卷积层、1个归一化层和1个LeakyReLU激活层。
所述的注意力层中的自注意力机制的计算过程如下:
S1,将待检测时序数据通过三个线性变换,得到queries、keys和values;
queries表示原始时序数据中需要进行关注的位置;
keys表示每个时刻的时序数据与queries之间的关系;
values表示时序数据每个时刻的具体信息,用于生成最终的上下文表示;
S2,通过下述公式计算得到输出矩阵Attention(Q,K,V),作为自注意力机制的输出;
其中;
Q、K和V分别代表queries、keys和values的矩阵形式;
d
Softmax表示归一化指数函数;
表示queries和keys之间的相似度得分。
所述的特征融合模块包括相连的1个全连接层和1个Sigmoid激活层。
所述的解码器由5个依次相连的Block组成,每个所述的Block包括依次相连的1个反卷积层、1个归一化层和1个LeakyReLU激活层。
所述的异常检测模型在训练过程中的损失函数L
其中:
D表示判别器的函数;
G表示生成器的函数;
x表示真实数据样本;
E为期望;
p
一种融合AAE和GAN的多模态时间序列异常值检测装置,包括数据采集模块、异常分数获取模块和判别模块;
所述的数据采集模块用于获取多个模态的待检测时序数据,并将其划分为训练集和测试集;所述的待检测时序数据包括DCS数据和声音数据;
所述的异常分数获取模块用于将得到的训练集输入异常检测模型进行训练,得到训练好的异常检测模型;以及将测试集输入至训练好的异常检测模型中,得到多个模态的待检测时序数据对应的异常分数;
所述异常检测模型包括生成器和判别器;所述的生成器包括基于注意力机制的自编码器和特征融合模块;所述的基于注意力机制的自编码器包括编码器和解码器,所述的特征融合模块连接在所述的编码器和解码器之间;所述的判别器连接在基于注意力机制的自编码器的输入端;
所述的判别模块用于判断所述的异常分数是否大于判别阈值,若是,则测试集中的待检测时序数据为异常数据,若否,则测试集中的待检测时序数据为正常数据。
本发明与现有技术相比,有益的技术效果是:
(Ⅰ)通过综合多种模态的时序数据,从不同维度获取更全面的信息,相比于单一模态数据,多模态数据能够提供更多丰富的特征,有助于更准确地检测异常;此外,不同模态的时序数据通常包含互补的信息,特征融合模块能够利用不同模态之间的互补性,将它们融合在一起,以提取更丰富的特征表示,有助于减少信息冗余,以及提高了异常检测的效果,解决了现有技术中异常值检测方法采用单一模态数据进行检测的准确率不高的技术问题。
(Ⅱ)自注意力机制用于提取原时序数据中的序列上下文信息,注意力机制能够让异常检测模型自主关注不同时间步的信息,从而提高了异常检测模型对时序数据的建模能力。自注意力机制能够对序列中的每个时间步的信息进行加权处理,使模型更有针对性地关注对当前任务最重要的部分,从而提高模型的表现。在编码模块前向传播学习参数的过程中,通过将Leaky ReLU作为激活函数避免了ReLU的死亡神经元问题,同时对每层参数做了Batch Normalization归一化,使得模型中间的隐层数据的分布相对稳定,减少了模型对底层网络的依赖,提高了整个神经网络的训练速度。
(Ⅲ)本发明中的特征融合模块主要采用多个MLP层,首先将DCS数据编码器与声纹数据编码器输出的特征进行特征融合,再经过MLP层进行特征的进一步提取,再交由后续的解码器对多模态特征进行重建。使用多模态特征融合模块将来自多种模态的数据融合在一起,能够充分挖掘数据中的多重信息,提高异常检测的准确性,并且能够提高异常检测模型的泛化能力,增强模型的鲁棒性,使得模型适用于多种实际应用场景。
(IV)本发明中的解码器采用多层卷积神经网络对经由特征融合模块处理过的多模态特征进行重建,在解码模块前向传播学习参数的过程中,通过将Leaky ReLU作为激活函数避免了ReLU的死亡神经元问题,本发明同时对每层参数做了Batch Normalization归一化,使得模型中间的隐层数据的分布相对稳定,减少了模型对底层网络的依赖,提高了整个神经网络的训练速度。
附图说明
图1为本发明的融合AAE和GAN的多模态时间序列异常值检测方法系统架构图;
图2为本发明中的编码器结构图;
图3为本发明中的特征融合模块结构图。
以下结合实施例对本发明的具体内容作进一步详细解释说明。
具体实施方式
需要说明的是,本发明中的所有零部件,在没有特殊说明的情况下,均采用本领域已知的零部件。
以下给出本发明的具体实施例,需要说明的是本发明并不局限于以下具体实施例,凡在本申请技术方案基础上做的等同变换均落入本发明的保护范围。
参见图1至图3,本发明给出了一种融合AAE和GAN的多模态时间序列异常值检测方法,具体包括如下步骤:
步骤1,获取多个模态的待检测时序数据,并将其划分为训练集和测试集;
待检测时序数据包括DCS数据和声音数据;
步骤2,将步骤1得到的训练集输入异常检测模型进行训练,得到训练好的异常检测模型;
所述异常检测模型包括生成器和判别器;生成器包括基于注意力机制的自编码器和特征融合模块;基于注意力机制的自编码器包括编码器和解码器,特征融合模块连接在编码器和解码器之间;判别器连接在基于注意力机制的自编码器的输入端;
步骤3,将步骤1得到的测试集输入至训练好的异常检测模型中,得到多个模态的待检测时序数据对应的异常分数;
步骤4,判断异常分数是否大于判别阈值,若是,则测试集中的待检测时序数据为异常数据,若否,则测试集中的待检测时序数据为正常数据。
在上述技术方案中,在异常检测模型的训练阶段只使用正常数据进行训练,在测试阶段,由于模型只采用了正常数据进行训练,所以对于正常数据,基于注意力机制的自编码器能够重构输入数据;而对于异常数据,由于其分布与正常数据不同,基于注意力机制的自编码器往往很难重构输入数据,从而产生较大的重构误差。因此,通过设置一个重构误差的阈值,我们可以将重构误差超过该阈值的数据识别为异常数据。
通过综合多种模态的时序数据,从不同维度获取更全面的信息,相比于单一模态数据,多模态数据能够提供更多丰富的特征,有助于更准确地检测异常;此外,不同模态的时序数据通常包含互补的信息,特征融合模块能够利用不同模态之间的互补性,将它们融合在一起,以提取更丰富的特征表示,有助于减少信息冗余,以及提高了异常检测的效果,解决了现有技术中异常值检测方法采用单一模态数据进行检测的准确率不高的技术问题。
编码器由5个依次相连的Block组成,每个Block包括依次相连的1个注意力层、1个卷积层、1个归一化层和1个LeakyReLU激活层。
上述技术方案中,自注意力机制用于提取原时序数据中的序列上下文信息,注意力机制能够让异常检测模型自主关注不同时间步的信息,从而提高了异常检测模型对时序数据的建模能力。自注意力机制能够对序列中的每个时间步的信息进行加权处理,使模型更有针对性地关注对当前任务最重要的部分,从而提高模型的表现。在编码模块前向传播学习参数的过程中,通过将Leaky ReLU作为激活函数避免了ReLU的死亡神经元问题,同时对每层参数做了Batch Normalization归一化,使得模型中间的隐层数据的分布相对稳定,减少了模型对底层网络的依赖,提高了整个神经网络的训练速度。
注意力层中的自注意力机制的计算过程如下:
S1,将待检测时序数据通过三个线性变换,得到queries、keys和values;
queries表示原始时序数据中需要进行关注的位置;
keys表示每个时刻的时序数据与queries之间的关系;
values表示时序数据每个时刻的具体信息,用于生成最终的上下文表示;
S2,通过下述公式计算得到输出矩阵Attention(Q,K,V),作为自注意力机制的输出;
其中;
Q、K和V分别代表queries、keys和values的矩阵形式;
d
Softmax表示归一化指数函数;
表示queries和keys之间的相似度得分。
特征融合模块包括相连的1个全连接层和1个Sigmoid激活层。
在上述技术方案中,特征融合模块主要采用多个MLP层,首先将DCS数据编码器与声纹数据编码器输出的特征进行特征融合,再经过MLP层进行特征的进一步提取,再交由后续的解码器对多模态特征进行重建。使用多模态特征融合模块将来自多种模态的数据融合在一起,能够充分挖掘数据中的多重信息,提高异常检测的准确性,并且能够提高异常检测模型的泛化能力,增强模型的鲁棒性,使得模型适用于多种实际应用场景。
解码器由5个依次相连的Block组成,每个Block包括依次相连的1个反卷积层、1个归一化层和1个LeakyReLU激活层。
在上述技术方案中,解码器采用多层卷积神经网络对经由特征融合模块处理过的多模态特征进行重建,在解码模块前向传播学习参数的过程中,通过将Leaky ReLU作为激活函数避免了ReLU的死亡神经元问题,本发明同时对每层参数做了Batch Normalization归一化,使得模型中间的隐层数据的分布相对稳定,减少了模型对底层网络的依赖,提高了整个神经网络的训练速度。
异常检测模型在训练过程中的损失函数L
其中:
D表示判别器的函数;
G表示生成器的函数;
x表示真实数据样本;
E为期望;
p
本方案中使用AE自编码器作为GAN的生成器,判别器采用多层卷积神经网络结构对原始数据x和生成的数据G(x)进行判断,通过生成器与判别器在训练过程中不断对抗,不断迭代优化,最终生成器可以重建出逼真的原始正常数据,而对于异常数据,生成器重建出来的数据就与原始数据误差很大,模型即可由原始数据与重建数据间的误差进行异常检测。本发明为防止模型过拟合和约束模型参数,在自编码器中加入了正则化项,使用L
本发明还给出了一种融合AAE和GAN的多模态时间序列异常值检测装置,包括数据采集模块、异常分数获取模块和判别模块;
数据采集模块用于获取多个模态的待检测时序数据,并将其划分为训练集和测试集;待检测时序数据包括DCS数据和声音数据;
异常分数获取模块用于将得到的训练集输入异常检测模型进行训练,得到训练好的异常检测模型;以及将测试集输入至训练好的异常检测模型中,得到多个模态的待检测时序数据对应的异常分数;
所述异常检测模型包括生成器和判别器;生成器包括基于注意力机制的自编码器和特征融合模块;基于注意力机制的自编码器包括编码器和解码器,特征融合模块连接在编码器和解码器之间;判别器连接在基于注意力机制的自编码器的输入端;
判别模块用于判断异常分数是否大于判别阈值,若是,则测试集中的待检测时序数据为异常数据,若否,则测试集中的待检测时序数据为正常数据。
实施例:
本实施例给出了一种融合AAE和GAN的多模态时间序列异常值检测方法具体包括以下步骤:
步骤1,获取多个模态的待检测的时间序列数据,包括文本,声音,图像等数据。
步骤2,将上述待检测的多模态时序数据输入经过预先训练的异常检测模型中;所述异常检测模型首先利用基于注意力机制的自编码器(Attention-based AutoEncoder,即AAE)的编码器部分提取待检测的多模态时序数据的隐层特征,然后对提取出来的多个模态的数据的隐层特征进行特征融合得到对应的多模态的融合特征,再基于所述模型的多模态自编码器的解码器部分对多模态的融合特征进行重构获取对应的重构数据,最后根据所述重构数据计算对应的异常分数。
步骤3,将所述测试时序数据的异常分数作为其异常检测结果。
步骤4,通过AUC来评判异常分数的效果。
AUC是用于评估二分类模型性能的指标,通常应用于ROC曲线。ROC曲线绘制了在不同阈值下真阳性率(True Positive Rate)和假阳性率(False Positive Rate)之间的关系。
AUC表示ROC曲线下的面积,取值范围在0到1之间。AUC值越大,表示模型性能越好。AUC的优势在于它不受类别不平衡问题的影响。当数据集中正例和反例数量不平衡时,AUC仍然能够提供一个可靠的评估指标。它是一个综合考虑了真阳性率和假阳性率的指标,适用于评估各种分类器模型。
AUC计算步骤如下:计算真阳性率(True Positive Rate)和假阳性率(FalsePositive Rate)。真阳性率(TPR)是指在实际正例中被正确预测为正例的样本比例。计算方法为:TPR=TP/(TP+FN),其中TP表示真正例(分类器将正实例正确地判定为正类)的数量,FN表示假反例(分类器将正实例错误地判定为反例)的数量。假阳性率(FPR)是指在实际为反例的样本中被错误预测为正例的样本比例。计算方法为:FPR=FP/(FP+TN),其中FP表示假正例(分类器将反例错误地判定为正实例)的数量,TN表示真反例(分类器将反例正确地判定为反例)的数量。根据不同的阈值,绘制ROC曲线。ROC曲线的横轴是FPR,纵轴是TPR。计算AUC,即ROC曲线下的面积。AUC的取值范围在0到1之间,AUC越接近1,表示模型性能越好。
本实施例中采用在实际工业环境中采集的DCS数据与声纹数据作为实验的数据集进行异常检测。本实施例中中的模型在Pytorch上实现,为了训练模型,引入了初始学习率为0.00002的Adam优化器,使用MSELoss作为原始数据与重构数据的损失函数,时序数据的Windows_size为320,Batch_size为64,训练轮次为50轮。整个实验在运行Windows 11操作系统的计算机上进行,采用的是Intel(R)Core(TM)i5-12500HCPU@3.10GHz,显卡是6GB内存的GeForce GTX3060。
实验结果如下:
通过实验验证了本实施例对实际工业环境下多模态的异常时序数据进行异常检测的有效性。
- 一种融合LSTM和GAN的时间序列数据异常检测方法
- 一种时间序列数据的异常值检测方法和装置