基于DNN算子并行的深度学习推理加速方法
文献发布时间:2024-04-18 19:58:30
技术领域
本发明涉及深度学习模型计算加速技术领域,尤其是一种基于DNN算子并行的深度学习推理加速方法,在提高GPU资源利用率的同时降低DNN的推理延时。
背景技术
深度神经网络(DNN)在图像处理、语音识别和虚拟现实等各个业务领域取得了显著的成功。众所周知,DNN推理任务对延时是非常敏感的。例如,出于安全考虑,自动驾驶场景中模型的推理延时要求就十分的严格(例如,在100毫秒内)。为了满足这样的性能要求,现代云数据中心托管了数千个GPU来加速用户的DNN推理。例如,阿里云拥有超过6000个GPU,其中许多GPU的任务就是管理大量的推理请求。
云数据中心中的GPU配备了越来越强的计算能力,这通常超出了单个推理任务的资源需求,导致硬件资源的利用不足和浪费。为了以更少的计算量实现目标模型精度,最近的一些工作专注于在DNN模型中用几个较小的多分支算子代替过往的大算子,这进一步加剧了GPU资源的利用不足。虽然批处理请求或多模型推理任务的并发处理可以缓解GPU资源利用率不高的情况,但由于批处理的数据量上升和多模型间的性能干扰,不可避免地会导致模型推理延时增加。因此,在不影响DNN推理延时的情况下提高GPU利用率势在必行。由于DNN模型通常可以由具有并行算子的有向无环图(DAG)表示,这为人们提供了利用算子并行性来加速GPU上DNN推理同时提高GPU利用率的机会。
现有的算子并行的方法主要有基于二部图转换的方法和基于动态规划的方法。基于二部图转换的方法会引入很大的计算开销,同时其没有考虑算子间的干扰;基于动态规划的方法同样需要长时间的搜索,而且引入了过多的设备间同步,导致性能下降。
发明内容
为了解决上述问题,本发明的目的是提供一种基于DNN算子并行的深度学习推理加速方法,即基于DAG中的无依赖关系的算子和离线收集算子的资源需求的并行调度策略。
实现本发明目的的具体技术方案是:
一种基于DNN算子并行的深度学习推理加速方法,具体包括以下步骤:
步骤1:提交DNN模型与输入数据;
步骤2:根据模型结构生成流分配方案;
将DNN模型转换为计算图模式,以拓扑排序的顺序遍历计算图中的节点;对于每一个节点,遍历其所有父亲节点,直到找到一个父亲节点满足当前节点为其第一个后继节点,然后将当前节点的流设置为与该父亲节点所在的流一致;如果找不到满足条件的父亲节点,则将当前节点的流设置为一个新创建的流;
步骤3:取一个批次数据运行DNN一次,获取运行过程中算子对GPU的资源需求;
利用PyTorch的分析器获取算子运行时信息保存为json格式文件,从json格式文件中解析出所有函数调用时间戳;利用核函数运行开始时间戳一定晚于核函数启动的时间戳的特性,得出算子与其运行时资源需求信息的映射关系,从而确定算子的线程数量、共享内存大小以及寄存器数量;
步骤4:基于步骤3所获取的资源需求以及算子所属类别,确定一个干扰感知且能够降低GPU空闲时间的算子发射顺序;
首先获取所有入度为0的待发射算子,并将这些待发射算子根据算子所属类别即访存密集型与计算密集型分成两个队列,分别为访存队列与计算队列;循环执行以下步骤直到两个队列均为空,即每次发射算子时交替选择两个队列中的非空队列,并从选择后的队列中选择算子资源需求最少的算子进行发射;发射之后更新算子的入度,然后将入度为0的算子根据其所属类别分别添加到访存密集型与计算密集型的两个队列中;
步骤5:基于步骤2的流分配方案与步骤4的算子发射顺序,捕获具体执行过程,生成一个能够在GPU上并行执行算子的CUDA Graph;
将步骤2得到的所有流设置为待捕获模式,同时遍历计算图中的所有节点,为每个节点创建同步事件并创建一个事件列表来保存该节点依赖完成的事件,将每个节点的所有不在同一个流上的父亲节点的同步事件加入该事件列表;根据步骤4的算子发射顺序将算子发射到设置为待捕获模式的流中,运行时控制每个算子必须在其事件列表中的所有依赖事件完成后执行,从而捕获整个执行过程,生成一个能够在GPU上并行执行算子且之后的运行无需再次捕获的CUDA Graph。
本发明解决了GPU中模型推理资源利用率不足与推理速度慢的问题。本发明将DAG中的可并行算子尽量调度到不同的流中,同时降低流同步的开销,实现了算子的并行执行;此外,通过提前获取算子运行的资源需求,通过对算子进行分类与排序,从小到大依次发射,提高了GPU的资源利用率同时降低了模型的推理时延。
附图说明
图1为实施本发明的系统架构图;
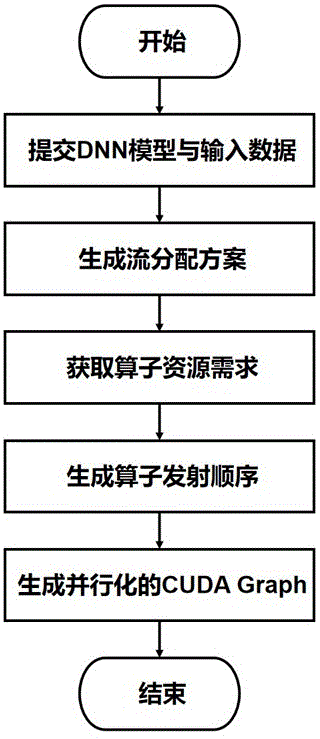
图2为本发明流程图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明的实施方式作进一步地详细描述。本发明设计并实现了一个高效的算子并行调度框架,来提高GPU计算平台下DNN推理的资源利用率同时降低推理时延。
如图1所示,实施本发明的流程包括:用户提交DNN模型与输入数据,流分配器根据DNN模型转换为DAG表示,并根据其生成流分配方案,模型数据收集器获取算子的资源需求,算子发射器生成算子发射顺序,图捕获器综合以上生成一个并行化的CUDAGraph。参阅图2,具体步骤为:
用户提交DNN模型与输入数据,流分配器将DNN模型转换为计算图模式,以拓扑排序的顺序遍历计算图中的节点;对于每一个节点,遍历其所有父亲节点,直到找到一个父亲节点满足当前节点为其第一个后继节点,然后将当前节点的流设置为与该父亲节点所在的流一致;如果找不到满足条件的父亲节点,则将当前节点的流设置为一个新创建的流。
模型数据收集器判断输入数据形状是否之前提交过,是则复用之前的数据信息;否则运行DNN一次,利用PyTorch的分析器获取算子运行时信息保存为json格式文件,从json格式文件中解析出所有函数调用时间戳。利用核函数运行开始时间戳一定晚于核函数启动的时间戳的特性,得出算子与其运行时资源需求信息的映射关系,从而确定算子的线程数量、共享内存大小以及寄存器数量。
算子发射器首先获取所有入度为0的待发射算子,并将这些待发射算子根据算子所属类别(访存密集型与计算密集型)分成两个队列,分别为访存队列与计算队列;循环执行以下步骤直到两个队列均为空,即每次发射算子时交替选择两个队列中的非空队列,并从选择后的队列中选择算子资源需求最少的算子进行发射;发射之后更新算子的入度,然后将入度为0的算子根据其所属类别添加到两个队列中。
图捕获器将流分配器得到的所有流设置为待捕获模式,同时遍历计算图中的所有节点,为每个节点创建同步事件并创建一个事件列表来保存该节点依赖完成的事件,将每个节点的所有不在同一个流上的父亲节点的同步事件加入该事件列表;然后根据算子发射器的算子发射顺序将算子发射到设置为待捕获模式的流中,运行时控制每个算子必须在其事件列表中的所有依赖事件完成后执行,从而捕获整个执行过程,生成一个能够在GPU上并行执行算子且之后的运行无需再次捕获的CUDAGraph。
基于以上功能,系统实现了DNN模型中算子的并行调度,同时考虑了较优的算子发射顺序来提高GPU的资源利用率同时降低模型推理时延。
实施例
为了验证本发明的可行性和优越性,本发明在配备Intel(R)Xeon(R)Gold6240CPU@2.60GHz的NVIDIAA100-PCIe-40GB GPU和配备Intel(R)Core(TM)i9-10920XCPU@3.50GHz的NVIDIA GeForce RTX 2080SUPER-8GB GPU上进行实验。使用PyTorch 2.0、CUDA11.7和cuDNN 8.5.0。实验选择了经典的DNN模型,包括Inception-v3、GoogLeNet、T5和BERT。
评估基准与评估指标:基于本发明实现的调度框架Opara将与以下三种策略进行比较:(1)原生Pytorch,即未采用CUDA Graph优化的原生方法;(2)顺序CUDA Graph,未采用算子并行的顺序执行方法;(3)Nimble,它将计算图转换为二分图,然后识别其最大匹配以确定每个算子所在的流。评估指标为四个关键指标包括DNN推理延时相对加速比、GPU利用率和GPU内存消耗,以及运行时开销。
在推理时延方面,各方法对不同模型的相对加速比的结果如表1所示。
表1各方法对不同模型的相对加速比
从表1中可以看出,Opara在四个经典DNN模型中始终优于其他三个基准方法。具体来说,与现有PyTorch相比,Opara可以实现最低1.85倍到最高4.18倍的加速。这是因为Opara利用CUDA Graph来消除算子发射和函数调用开销。Opara超越顺序CUDA Graph最高达1.68倍,这是因为Opara将DNN中算子并行执行。此外,Opara的性能比Nimble高出1.29倍,因为它在发射每个算子的时候明智地交替调度不同类型且GPU资源消耗最低的算子。此外,Opara启动足够的流来提高并行性(例如,Opara为GoogLeNet创建了28个流,而Nimble为其创建了4个流),这最大化了算子的并行度。
表2各方法下不同模型的GPU利用率
为了进一步揭示Opara的性能提升,继续研究DNN模型执行过程中的GPU利用率(即GPU的SM使用效率)。如表2所示,与表中的其他三个基准相比,Opara在GPU利用率方面表现出了类似的改进。具体来说,由于Opara减少了原有PyTorch的调度开销,因此与原有PyTorch相比,Opara显著提高了GPU利用率。与默认的CUDA Graph相比,Opara将Inception-v3、GoogLeNet、BERT和T5的GPU利用率分别提高了36%、58%、20%和19%。与Nimble相比,Opara将GPU利用率提高了1.01倍到1.42倍,这主要归功于两个事实:(1)Opara中的最大化流分配可以增加算子并行执行的机会;(2)Opara优化了算子的启动顺序,这可以进一步减少GPU空闲时间。
表3各方法下不同模型的GPU显存消耗量
此外,在GPU显存使用量方面,如表3所示,由于DNN算子的并行执行使得同时驻留在GPU显存中的数据量增加,从而导致Opara的峰值GPU显存消耗高于顺序执行(即PyTorch和顺序CUDA Graph)。
表4Opara与Nimble的运行时开销
Opara的运行时开销同样表现优秀,如表4所示,Opara对Inceptionv3、GoogLeNet、T5和BERT的算法计算时间分别为0.50ms、0.27ms、2.80ms和0.58ms。相比之下,Nimble中四个模型的计算时间分别为14.10ms、5.80ms、161.40ms和20.8ms,比Opara的计算时间至少多出一个量级。这是因为Nimble需要对图进行转换,并在二部图中进行穷举搜索。这个过程非常耗时,时间复杂度为O(n
本发明的实施方式还能够提供基于DNN算子并行的深度学习推理加速系统,所述系统包括四个模块:流分配模块,根据模型结构生成流分配方案;模型数据收集模块,运行DNN一次,获取运行过程中算子对GPU的资源需求;算子发射模块,根据获取的算子资源需求以及算子所属类别,确定合理的算子发射顺序;图捕获模块,依据流分配方案与算子发射顺序,捕获最终的具体执行过程,生成一个可在GPU上并行执行算子的CUDA Graph。用户只需提交DNN模型与输入数据到该算子并行加速系统,便可以自动完成算子的高效并行调度,该调度能够提高推理任务在GPU上的资源利用率,同时可以降低模型推理的时延。
- 一种基于多算子融合的深度神经网络推理加速方法和系统
- 一种多压缩版本的云边端DNN协同推理加速方法