动画模型生成方法及装置
文献发布时间:2024-04-18 19:58:30
技术领域
本申请涉及计算机技术领域,特别涉及一种动画模型生成方法。本申请同时涉及一种动画模型生成装置、一种计算设备,以及一种计算机可读存储介质。
背景技术
随着互联网技术的发展,计算机图形学广泛应用于动画制作、游戏人物制作、虚拟现实、人机交互等场景,丰富场景中人物的表情、形态以及动作。通过动画制作的方式,使得各场景中的虚拟人物更加真实生动。
现有技术中,在进行动画制作时,通常采用制作关键帧动画、形变动画等方法。然而,现有的几种动画制作方法操作繁琐,生成动画的效率低,难以满足动画制作需求,因此,亟需一种较为高效的动画模型生成方法实现动画的制作。
发明内容
有鉴于此,本申请实施例提供了一种动画模型生成方法,以解决现有技术中存在的技术缺陷。本申请实施例同时提供了一种动画模型生成装置,一种计算设备,以及一种计算机可读存储介质。
根据本申请实施例的第一方面,提供了一种动画模型生成方法,包括:
确定目标对象的至少两个对象图像,并对至少两个对象图像进行解析,获得所述目标对象的至少两组对象特征数据;
确定与所述目标对象对应的待处理动画模型,并基于至少两组对象特征数据对所述待处理动画模型的模型特征参数进行更新,获得至少两个对象图像分别对应的动画帧;
利用至少两个对象图像分别对应的动画帧构建初始动画模型。
可选地,所述确定目标对象的至少两个对象图像,包括:
利用包括至少两个图像采集维度的图像采集设备,采集目标对象的至少两个深度对象图像。
可选地,所述利用包括至少两个图像采集维度的图像采集设备,采集目标对象的至少两个深度对象图像,包括
确定所述图像采集设备的至少两个图像采集维度中,每个图像采集维度对应的摄像头;
基于各图像采集维度对应的摄像头采集目标对象的至少两个深度对象图像。
可选地,任意一组对象特征数据的确定,包括:
在所述目标对象为面部对象的情况下,在对象图像中提取面部器官形态数据,并将所述面部器官形态数据作为对象特征数据;
在所述目标对象为人体对象的情况下,在对象图像中提取人体动作数据,并将所述人体动作数据作为对象特征数据。
可选地,所述确定与所述目标对象对应的待处理动画模型之后,还包括:
确定所述待处理动画模型预置的模型特征参数,将所述模型特征参数调整至预设的参数区间。
可选地,所述确定与所述目标对象对应的待处理动画模型之后,还包括:
针对所述待处理动画模型创建动画控制器,并建立所述动画控制器与所述待处理动画模型之间的控制连接。
可选地,所述基于至少两组对象特征数据对所述待处理动画模型的模型特征参数进行更新,获得至少两个对象图像分别对应的动画帧之后,还包括:
针对所述待处理动画模型创建动画状态机,并利用所述动画状态机对各对象图像对应的动画帧中的任意对象特征进行调整和/或测试。
可选地,所述利用至少两个对象图像分别对应的动画帧构建初始动画模型,包括:
按照所述至少两个对象图像分别对应的图像顺序,对所述至少两个对象图像分别对应的动画帧进行连接,获得初始动画模型。
可选地,所述利用所述至少两个对象图像分别对应的动画帧构建初始动画模型之后,还包括:
对所述初始动画模型进行播放操作,并获取所述初始动画模型的动画状态图像,且将所述动画状态图像作为动画表情存储。
可选地,所述利用至少两个对象图像分别对应的动画帧构建初始动画模型之后,还包括:
确定对象材质参数和/或对象骨骼参数;
基于所述对象材质参数和/或所述对象骨骼参数对所述初始动画模型进行形态调整,获得目标动画模型。
根据本申请实施例的第二方面,提供了一种动画模型生成装置,包括:
确定模块,被配置为确定目标对象的至少两个对象图像,并对至少两个对象图像进行解析,获得所述目标对象的至少两组对象特征数据;
更新模块,被配置为确定与所述目标对象对应的待处理动画模型,并基于至少两组对象特征数据对所述待处理动画模型的模型特征参数进行更新,获得至少两个对象图像分别对应的动画帧;
构建模块,被配置为利用至少两个对象图像分别对应的动画帧构建初始动画模型。
根据本申请实施例的第三方面,提供了一种计算设备,包括:
存储器和处理器;
所述存储器用于存储计算机可执行指令,所述处理器执行所述计算机可执行指令时实现所述动画模型生成方法的步骤。
根据本申请实施例的第四方面,提供了一种计算机可读存储介质,其存储有计算机可执行指令,该指令被处理器执行时实现所述动画模型生成方法的步骤。
根据本申请实施例的第五方面,提供了一种芯片,其存储有计算机程序,该计算机程序被芯片执行时实现所述动画模型生成方法的步骤。
本申请提供的动画模型生成方法,通过确定目标对象的至少两个对象图像,并对至少两个对象图像进行解析,获得目标对象的至少两组对象特征数据;确定与目标对象对应的待处理动画模型,并基于至少两组对象特征数据对待处理动画模型的模型特征参数进行更新,获得至少两个对象图像分别对应的动画帧;利用至少两个对象图像分别对应的动画帧构建初始动画模型。基于对对象图像进行解析获得的对象特征数据,对待处理动画模型的模型特征参数进行更新,进而获得初始动画模型,使得初始动画模型能够表现对象图像中目标对象的形态、表情的信息,进而提高初始动画模型的生成效率,简化初始动画模型的制作流程。
附图说明
图1是本申请一实施例提供的一种动画模型生成方法的结构示意图;
图2是本申请一实施例提供的一种动画模型生成方法的流程图;
图3是本申请一实施例提供的一种动画模型生成方法的动画模型示意图;
图4是本申请一实施例提供的一种应用于表情动画制作的动画模型生成方法的处理流程图;
图5是本申请一实施例提供的一种动画模型生成装置的结构示意图;
图6是本申请一实施例提供的一种计算设备的结构框图。
具体实施方式
在下面的描述中阐述了很多具体细节以便于充分理解本申请。但是本申请能够以很多不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本申请内涵的情况下做类似推广,因此本申请不受下面公开的具体实施的限制。
在本申请一个或多个实施例中使用的术语是仅仅出于描述特定实施例的目的,而非旨在限制本申请一个或多个实施例。在本申请一个或多个实施例和所附权利要求书中所使用的单数形式的“一种”、“所述”和“该”也旨在包括多数形式,除非上下文清楚地表示其他含义。还应当理解,本申请一个或多个实施例中使用的术语“和/或”是指并包含一个或多个相关联的列出项目的任何或所有可能组合。
应当理解,尽管在本申请一个或多个实施例中可能采用术语第一、第二等来描述各种信息,但这些信息不应限于这些术语。这些术语仅用来将同一类型的信息彼此区分开。例如,在不脱离本申请一个或多个实施例范围的情况下,第一也可以被称为第二,类似地,第二也可以被称为第一。
首先,对本发明一个或多个实施例涉及的名词术语进行解释。
ARkit:增强现实(AR)平台,它通过在设备的摄像头中捕捉和分析环境,将虚拟元素与现实场景结合起来,并显示在设备屏幕上。它支持光线估计、面部跟踪、虚拟物理效果和用户触摸交互等功能,并为开发人员提供了一组API,可帮助他们创建出色的AR应用程序。
Unity:实时3D互动内容创作和运营平台。包括游戏开发、美术、建筑、汽车设计、影视在内的所有创作者,借助Unity将创意变成现实。Unity平台提供一整套完善的软件解决方案,可用于创作、运营和变现任何实时互动的2D和3D内容,支持平台包括手机、平板电脑、PC、游戏主机、增强现实和虚拟现实设备。
Timeline:unity自带的时间线插件,是一种时间轴编辑工具,可用于编辑和控制动画片段。可以很好的实现动效等内容。同时扩展简单,是游戏开发不可获取的一个重要组件。
动画状态机(Animation State Machine):一种用于控制复杂动画的工具。它将动画分成多个状态,每个状态定义了一种动画行为。在运行时,根据当前状态的不同,播放对应的动画。动画状态机可以根据游戏进程或角色状态等条件来控制动画的切换,以达到更加自然的动态效果。
在本申请中,提供了一种动画模型生成方法。本申请同时涉及一种动画模型生成装置、一种计算设备,以及一种计算机可读存储介质,在下面的实施例中逐一进行详细说明。
计算机图形学一直以来都致力于实现逼真的角色面部表情,这对于游戏、虚拟现实和增强现实等领域都具有重要意义。传统的角色面部表情制作方法通常需要复杂的骨骼绑定、动画制作和表情捕捉等步骤,操作繁琐且效果有限。因此,本实施例提供了一种动画模型生成方法,实现动画的高效生成。
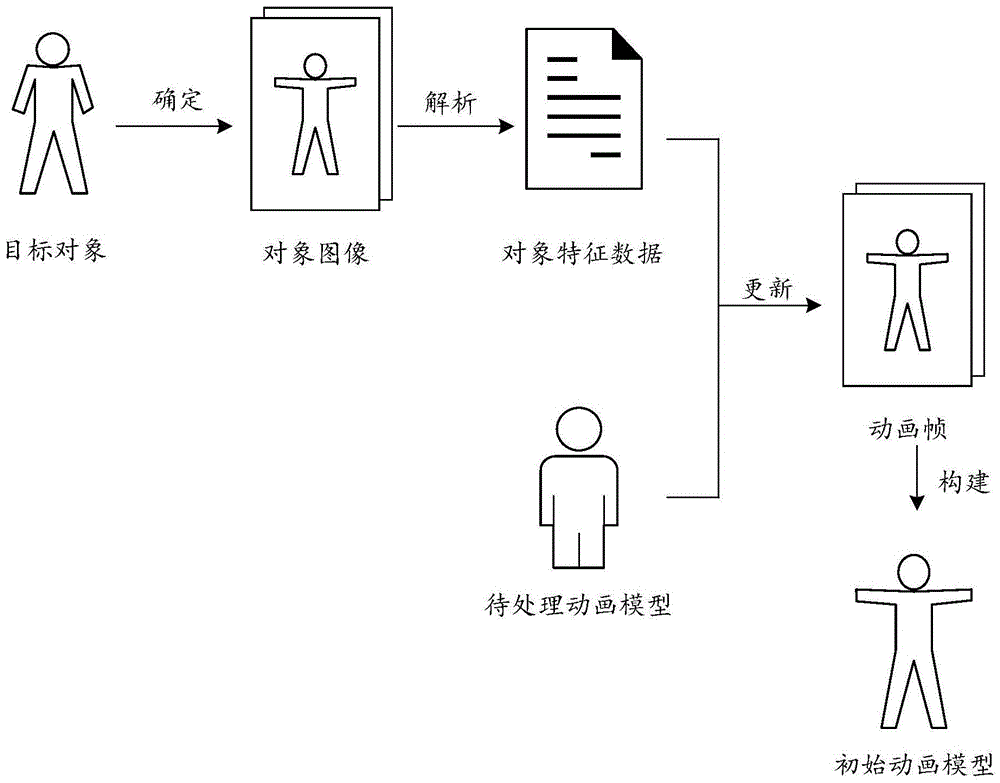
参见图1所示的动画模型生成方法的结构示意图。确定目标对象,以及目标对象的至少两个对象图像。可以采用图像或视频采集设备对目标对象进行图像采集或视频采集,进而获得至少两个对象图像。对至少两个对象图像进行解析,识别对象图像中目标对象的对象特征,进而获得目标对象的至少两组对象特征数据。确定与目标对象对应的待处理动画模型,并基于至少两组对象特征数据对待处理动画模型的模型特征参数进行更新,将对象特征参数应用于待处理动画模型,获得至少两个对象图像分别对应的动画帧。对至少两个对象图像分别对应的动画帧进行连接,构建初始动画模型。
综上所述,基于对对象图像进行解析获得的对象特征数据,对待处理动画模型的模型特征参数进行更新,进而获得初始动画模型,使得初始动画模型能够表现对象图像中目标对象的形态、表情的信息,进而提高初始动画模型的生成效率,简化初始动画模型的制作流程。
图2出了根据本申请一实施例提供的一种动画模型生成方法的流程图,具体包括以下步骤:
步骤S202:确定目标对象的至少两个对象图像,并对至少两个对象图像进行解析,获得所述目标对象的至少两组对象特征数据。
具体的,目标对象可以是包含头部和肢体躯干的人体,也可以是人的头部、腿部等肢体部位;对象图像可以是包含目标对象的图像,可以通过对目标对象进行图像采集获得,也可以通过对目标对象进行视频录制后,对录制的视频进行分帧处理或裁剪、截图获得;对象图像也可以是预先存储的,包含目标对象的图像;对象特征数据是指与对象图像中目标对象的五官、关节、肢体等特征部位对应的特征数据;对象特征数据包括但不限于特征部位的大小、方向、运动幅度、形态等数据。
基于此,确定目标对象,利用图像采集设备对目标对象进行图像采集,获得包含目标对象的至少两个对象图像。确定对象图像中目标对象的特征部位,并对每个特征部位进行解析,分别对至少两个对象图像进行解析,获得目标对象的至少两组对象特征数据。
实际应用中,在对目标对象进行图像采集以及对对象图像进行解析时,可以利用ARkit设备实现对面部表情数据的捕捉,实时追踪用户的面部表情,并将其转化为数据。即,利用ARkit设备实现对象图像的采集,以及表情数据的获取。在获取到表情数据后,由Unity引擎提供的TimeLine工具对表情数据进行转化,转化为自定义的表情姿态数据,表情姿态数据即为对象特征数据。
进一步的,考虑到动画制作,以及目标对象的表情重现、姿态重现的真实性问题,可以在采集对象图像时选用特定的能够记录图像深度、强化图像颜色的图像采集设备,具体实现如下:
利用包括至少两个图像采集维度的图像采集设备,采集目标对象的至少两个深度对象图像。
具体的,图像采集维度包括但不限于图像深度维度、图像颜色维度、图像广度维度,每个图像采集维度可以对应特定的摄像头,例如深度摄像头、颜色摄像头等。图像采集设备可以是相机、摄影机、手机等任意具有图像采集功能的设备;相应的,深度对象图像即为利用具有强化深度、广度、颜色等多个图像维度的图像采集设备采集的图像。
基于此,利用包括至少两个图像采集维度的图像采集设备,采集目标对象的至少两个深度对象图像。图像采集设备中包括颜色摄像头、深度摄像头和广度摄像头,从颜色、深度、广度三个维度进行图像采集,采集目标对象以及场景,同时记录场景中目标对象以及其他对象的深度坐标,进而便于后续对象图像的解析。
举例说明,在动画制作场景下,可以针对人物的头部制作表情动画,也可以针对人体制作包含头部、肢体和躯干的人物动画。可以利用深度摄像机实现图像采集。获得深度摄像头采集的深度信息。使得在图像采集的过程中融入增强现实技术,将虚拟信息和真实世界的人物、场景相融合。
综上所述,利用包括至少两个图像采集维度的图像采集设备,采集目标对象的至少两个深度对象图像,进而在后续制作动画时融入对象图像的深度信息,使得动画更加真实。
进一步的,考虑到图像采集维度在不同的图像采集场景中起到的作用不同,因此,可以针对目标对象选择特定的图像采集维度,以及通过每个图像采集维度对应的特定摄像头进行图像采集,从而提高图像采集效果,具体实现如下:
确定所述图像采集设备的至少两个图像采集维度中,每个图像采集维度对应的摄像头;基于各图像采集维度对应的摄像头采集目标对象的至少两个深度对象图像。
基于此,确定图像采集设备的至少两个图像采集维度中包含的颜色维度、深度维度和广度维度,颜色维度对应颜色摄像头、深度维度对应深度摄像头以及广度维度对应广度摄像头。基于各图像采集维度对应的摄像头采集目标对象的至少两个深度对象图像。通过深度摄像头采集深度对象图像,可以获得目标对象的深度坐标(空间坐标),进而在对深度对象图像进行解析时,结合深度坐标实现。
综上所述,利用各图像采集维度对应的摄像头采集目标对象的至少两个深度对象图像,使得采集到的深度对象图像更加真实,更接近真实的目标对象和场景。提高深度对象图像的采集效果。
进一步的,考虑到对动画的不同需求,可以针对特定的目标对象进行图像采集和特征数据解析,不仅可以针对面部表情制作表情动画,还可以针对人体制作姿态动画,具体实现如下:
在所述目标对象为面部对象的情况下,在对象图像中提取面部器官形态数据,并将所述面部器官形态数据作为对象特征数据;在所述目标对象为人体对象的情况下,在对象图像中提取人体动作数据,并将所述人体动作数据作为对象特征数据。
具体的,面部对象即为人物的头部,将包含面部特征的头部作为目标对象实现图像采集;相应的,人体对象即为包含头部、四肢和躯干的人体,将包含头部、四肢和躯干的人体作为目标对象,或者将包含头部、面部五官、四肢和躯干的人体作为目标对象;面部器官形态数据即为眼睛、鼻子、嘴巴、眉毛、舌头、脸颊、下巴等部位的形态数据,包括面部器官的方向、角度信息;人体动作数据即为手臂、手、腿部、脚、脖子、躯干、头部等部位的动作数据,例如:手臂和腿部的向前抬起、向左抬起等。
基于此,在目标对象为面部对象的情况下,在对象图像中提取眼睛、鼻子、嘴巴、眉毛、舌头、脸颊等器官面部器官形态数据。面部器官形态数据即为对象特征数据,用于后续动画模型的生成。在目标对象为人体对象的情况下,在对象图像中提取手臂、手、腿部、脚、脖子、躯干、头部等部位的人体动作数据,并将人体动作数据作为对象特征数据,用于后续动画模型的生成。
沿用上例,在目标对象为面部对象的情况下,在对象图像中提取眼睛、下巴、嘴巴、眉毛、脸颊、鼻子、舌头等器官或部位的数据。眼睛对应的对象特征数据可以为:EyeBlinkLeft眨左眼、EyeLookDownLeft左眼下看、EyeLookInLeft左眼内看、EyeLookOutLeft左眼外看、EyeLookUpLeft左眼上看、EyeSquintLeft左眼斜视、EyeWideLeft左眼睁大、EyeBlinkRight眨右眼、EyeLookDownRight右眼下看、EyeLookInRight右眼内看、EyeLookOutRight右眼外看、EyeLookUpRight右眼上看、EyeSquintRight右眼斜视、EyeWideRight右眼睁大;下巴对应的对象特征数据可以为:JawForward下巴向前、JawLeft下巴向左、JawRight下巴向右、JawOpen下巴打开。
嘴巴对应的对象特征数据可以为:MouthClose闭嘴、MouthFunnel嘟嘴、MouthPucker噘嘴、MouthLeft左嘴角、MouthRight右嘴角、MouthSmileLeft左嘴角笑、MouthSmileRight右嘴角笑、MouthFrownLeft左嘴角哭、MouthFrownRight右嘴角哭、MouthDimpleLeft左嘴角酒窝、MouthDimpleRight右嘴角酒窝、MouthStretchLeft嘴角左侧拉伸、MouthStretchRight嘴角右侧拉伸、MouthRollLower翻下嘴唇、MouthRollUpper翻上嘴唇、MouthShrugLower耸下嘴唇、MouthShrugUpper耸上嘴唇、MouthPressLeft嘴巴左侧按下、MouthPressRight嘴巴右侧按下、MouthLowerDownLeft左下嘴唇、MouthLowerDownRight右下嘴唇、MouthUpperUpLeft左上嘴唇、MouthUpperUpRight右上嘴唇;眉毛对应的对象特征数据可以为:BrowDownLeft眉毛左下、BrowDownRight眉毛右下、BrowInnerUp眉心向上、BrowOuterUpLeft眉毛左上、BrowOuterUpRight眉毛右上;脸颊对应的对象特征数据可以为:CheekPuff脸颊鼓起、CheekSquintLeft脸颊左眯、CheekSquintRight脸颊右眯;鼻子和舌头对应的对象特征数据可以为:NoseSneerLeft鼻子左嘲讽、NoseSneerRight鼻子右嘲讽、TongueOut舌头伸出。基于上述对象特征数据进行后续的动画模型制作。
在所述目标对象为人体对象的情况下,在对象图像中提取手臂、手、腿部、脚、躯干、头部等部位的动作数据。手臂对应的对象特征数据可以为:手臂向前抬起、手臂向后抬起、手臂垂直举过头顶等;腿部对应对象特征数据可以为腿部向前抬起、腿部向后抬起、腿部向右抬起、腿部向前弯曲抬起等;头部对应的对象特征数据可以为头部向后仰、头部向左转、头部向右转等。基于上述对象特征数据进行后续的动画模型制作。
综上所述,目标对象可以为面部对象,也可以为人体对象,进而针对面部表情制作表情动画,以及针对人体制作姿态动画提高动画制作的丰富性。
步骤S204:确定与所述目标对象对应的待处理动画模型,并基于至少两组对象特征数据对所述待处理动画模型的模型特征参数进行更新,获得至少两个对象图像分别对应的动画帧。
具体的,在上述确定目标对象的至少两个对象图像,并对至少两个对象图像进行解析,获得目标对象的至少两组对象特征数据之后,即可确定与目标对象对应的待处理动画模型,并基于至少两组对象特征数据对待处理动画模型的模型特征参数进行更新,获得至少两个对象图像分别对应的动画帧,其中,待处理动画模型是指预先生成的骨骼模型,待处理动画模型可以是人的头部3D立体模型,也可以是包含躯干的人体3D立体模型,用于后续的动画制作;模型特征参数是指待处理动画模型的初始化参数,待处理动画模型提供多个模型特征参数的参数配置接口,通过进行参数配置即可驱动待处理动画模型的骨骼进行动作;模型特征参数具有初始的参数区间,可以基于对象特征参数在参数区间内对模型特征参数进行调整,改变待处理动画模型的五官形态以及肢体动作。动画帧是指与对象图像对应的包含更新了模型特征参数的待处理动画模型的图像帧,动画帧可以是1秒、3秒等任意时间,因此动画帧可以对应静态的表情或动作,也可以对应3秒内动态的表情或动作。
基于此,在上述确定目标对象的至少两个对象图像,并对至少两个对象图像进行解析,获得目标对象的至少两组对象特征数据后,确定与目标对象对应的待处理动画模型并对待处理动画模型进行初始化,将待处理动画模型的模型特征参数调整至预设的参数区间内。基于至少两组对象特征数据对待处理动画模型的,初始化后的模型特征参数进行更新,获得至少两个对象图像分别对应的动画帧。
进一步的,考虑到待处理动画模型在创建后可能存在模型特征参数不在参数区间内的情况,此时需要对待处理动画模型进行初始化,从而保证后续动画模型生成的准确性,具体实现如下:
确定所述待处理动画模型预置的模型特征参数,将所述模型特征参数调整至预设的参数区间。
具体的,参数区间是指模型特征参数对应的初始化参数区间,模型特征参数在参数区间内表示待处理动画模型已经初始化完成,可以直接用于动画模型的生成;模型特征参数不在参数区间内表示待处理动画模型未初始化完成,需要将模型特征参数调整至参数区间,才可以用于后续的动画模型生成。参数区间可以设置为0-1或者根据需求设置为其他任意数值区间,本实施例对此不作任何限定。
基于此,在确定与目标对象对应的待处理动画模型之后,且基于至少两组对象特征数据对所述待处理动画模型的模型特征参数进行更新之前,确定动画模型预置的至少两个模型特征参数,每个模型特征参数与解析获得的对象特征参数相对应。将模型特征参数调整至预设的参数区间,完成对待处理动画模型的初始化。
沿用上例,在Unity中创建如图3中(a)所示的待处理动画模型。待处理动画模型对应三维坐标,为3D立体动画模型。可以在Unity中确定时间轴,以及对待处理动画模型进行参数调整。将待处理动画模型特征为初始化状态。
综上所述,将待处理动画模型预置的模型特征参数调整至预设的参数区间,实现待处理动画模型的初始化,保证后续动画模型生成的准确性。
进一步的,考虑到动画中包含多帧,在进行动画的制作和测试过程中需要进行调整,为了便于对特定的动画帧进行调整,可以创建动画控制器,实现待处理动画模型的播放与暂停控制,具体实现如下:
针对所述待处理动画模型创建动画控制器,并建立所述动画控制器与所述待处理动画模型之间的控制连接。
具体的,动画控制器是Unity中用于控制角色动画的组件,利用它可以将一系列动画片段组装成一个动画状态机。动画状态机中的状态表示动画的播放方式,每个状态都可以包含不同的动画片段,并且状态可以根据条件自动切换。控制连接是指动画控制器和待处理动画模型之间的连接,用于实现动画的播放和暂停。
基于此,针对待处理动画模型创建动画控制器,并建立动画控制器与待处理动画模型之间的控制连接,利用动画控制器控制待处理动画模型的播放和暂停。
沿用上例,在Unity的动画系统中创建一个面部动画控制器,并将面部动画控制器分配至待处理动画模型。用于实现待处理动画模型的播放控制。
综上所述,针对待处理动画模型创建动画控制器,并建立动画控制器与所述待处理动画模型之间的控制连接,实现待处理动画模型的播放与暂停控制,从而便于对待处理动画模型特定帧的参数调整。
进一步的,考虑到每组对象特征数据包含的对象特征数量较多,相应的,与对象特征对应的对象特征数据的数量也较多,为了便于对单独的对象特征进行细微的调整,可以创建动画状态机,具体实现如下:
针对所述待处理动画模型创建动画状态机,并利用所述动画状态机对各对象图像对应的动画帧中的任意对象特征进行调整和/或测试。
具体的,动画状态机是一种用于控制复杂动画的工具。可以在动画控制器中创建动画状态机,用于控制动画播放逻辑,动画播放逻辑是指针对单独的特征进行动画播放,例如:眼睛从闭合到张开的过程这一动画单独播放,其他面部器官无需播放;对象特征即为目标对象的眼睛、鼻子、眉毛、嘴巴等面部特征,以及躯干特征,手臂、腿部、手、脚等肢体特征;对象特征的调整包括对象特征的状态调整和/变化调整,状态调整包括但不限于对象特征的形状、姿态的调整;变化调整包括但不限于对象特征变化的角度和幅度的调整;对象特征的测试可以是对对象特征在动画维度进行播放测试,还可以是在动画帧维度进行帧间切换测试和/或单帧测试。
基于此,针对待处理动画模型在动画控制器中创建动画状态机,在对象图像对应的动画帧中确定任意对象特征作为待处理对象特征,利用动画状态机对待处理对象特征进行状态调整和/或变化调整,以及进行播放测试、帧间切换测试和/或单帧测试;或者利用动画状态机对待处理对象特征进行状态调整和/或变化调整;再或者利用动画状态机对待处理对象特征进行播放测试、帧间切换测试和/或单帧测试。
沿用上例,在Unity的面部动画控制器中创建动画状态机,用于控制面部骨骼的动画播放逻辑。对眼睛、鼻子、眉毛、嘴巴等面部特征,以及躯干特征,手臂、腿部、手、脚等肢体特征进行一对一调整和播放,实现动画的播放和测试;或者针对面部特征、肢体特征中的任意对象特征进行一对一的状态调整和/变化调整,使得对象特征的状态变化更加流畅自然;再或者针对面部特征、肢体特征中的任意对象特征进行单独播放,实现对象特征的动画效果测试。
综上所述,利用动画状态机对各对象图像对应的动画帧中的任意对象特征进行调整和/或测试,从而实现针对特定的对象特征进行单独调整和/或测试,提高目标对象在动画制作过程中的还原度,使得各个对象特征的动画更加协调自然。
步骤S206:利用至少两个对象图像分别对应的动画帧构建初始动画模型。
具体的,在上述确定与目标对象对应的待处理动画模型,并基于至少两组对象特征数据对待处理动画模型的模型特征参数进行更新,获得至少两个对象图像分别对应的动画帧之后,即可利用至少两个对象图像分别对应的动画帧构建初始动画模型,其中,初始动画模型是将多个动画帧连接后获得的动画模型,初始动画模型能够展示动态的表情变化或肢体变化,例如,眼睛、嘴巴从闭合到张开的变化过程,手臂抬起与摆动的变化过程等。
基于此,在上述确定与目标对象对应的待处理动画模型,并基于至少两组对象特征数据对待处理动画模型的模型特征参数进行更新,获得至少两个对象图像分别对应的动画帧后,对至少两个对象图像分别对应的动画帧按照动画帧对应的对象图像的图像顺序进行连接,构建初始动画模型。
实际应用中,可以通过创建动画状态机的方式实现动画帧的连接。在动画状态机中连接不同的动画帧状态,控制面部表情或肢体动作的切换。通过动画状态机实现面部中五官的联动,例如微小状态,嘴角上扬的同时眼睛张开的幅度变小,呈现眼睛微弯曲的状态。使得面部表情更加生动真实。初始动画模型的生成可以广泛的应用于游戏角色构建、虚拟现实和增强现实的使用场景中。在教育、医疗等领域可以应用于人机交互,用于展示更加真实的人物形态。在游戏、虚拟现实和增强现实等领域的应用中,可以使角色面部表情更加逼真、丰富。在动画制作的应用中,可以在同一制作界面对多个人物进行动画制作,可以通过勾选的方式选中人物进行动画制作。在同一制作界面中包含人物A、B和C的情况下,可以通过勾选人物A的方式选中人物A,进而针对人物A进行动画制作、测试以及播放。
进一步的,考虑到在进行动画制作时,是基于每个对象图像的一组对象特征数据进行单帧动画制作,为了实现连续的动画,需要对多个动画帧进行连接,制作出连续的动画,具体实现如下:
按照所述至少两个对象图像分别对应的图像顺序,对所述至少两个对象图像分别对应的动画帧进行连接,获得初始动画模型。
具体的,图像顺序是指展示两个对象图像的获取顺序,由于目标对象的对象图像是按照时间顺序采集的,对象图像中目标对象的动作具有连续性。
基于此,确定至少两个对象图像中每个对象图像的图像顺序,按照图像顺序对至少两个对象图像分别对应的动画帧进行连接,获得初始动画模型。初始动画模型中可以通过触发转换逻辑实现动画帧的切换。可以通过点击、滑动等触发操作实现动画帧的切换。
实际应用中,在对至少两个对象图像分别对应的动画帧进行连接后,还可以对每个动画帧中对象特征的对象特征参数进行调整,使得动画帧之间对象特征的衔接更加真实自然。
沿用上例,在获得至少两个对象图像分别对应的动画帧之后,按照对象图像的获取顺序对动画帧进行连接,获得能够进行播放的初始动画模型,完成动画制作。
综上所述,按照至少两个对象图像分别对应的图像顺序,对至少两个对象图像分别对应的动画帧进行连接,获得能够播放的初始动画模型,
进一步的,考虑到初始动画模型是通过动画的方式展示人物的表情、肢体动画,为了提高适用性,可以对单帧动画进行保存,从而提高单帧动画的使用率,具体实现如下:
对所述初始动画模型进行播放操作,并获取所述初始动画模型的动画状态图像,且将所述动画状态图像作为动画表情存储。
具体的,动画状态图像是指在初始动画模型播放过程中获取的任意播放时刻的图像;在初始动画模型为从无表情到微小的过程的情况下,可以对无表情的动画模型进行截图或图像帧存储操作,获得单独存储的动画表情。
基于此,对初始动画模型进行播放操作,确定在初始动画模型播放过程中的图像获取时刻,并获取图像获取时刻的动画状态图像,将动画状态图像作为动画表情存储。
沿用上例,在初始动画模型构建完成后,初始动画模型即可实现目标对象的表情动画重现或人体姿态动画重现。在初始动画模型播放过程中,确定一个播放时刻,获取初始动画模型在这一时刻的图像进行存储,从而实现特殊表情的存储或较为精彩有趣的表情存储。
综上所述,获取初始动画模型的动画状态图像,且将动画状态图像作为动画表情存储,从而可以实现动画表情的复用,提高初始动画模型的利用率。
进一步的,考虑到初始动画模型仅具有对象的轮廓特征以及表情、肢体等特征,为了提高动画模型的真实度,可以为初始动画模型添加对象材质参数和/或对象骨骼参数,制作更加生动的动画,具体实现如下:
确定对象材质参数和/或对象骨骼参数;基于所述对象材质参数和/或所述对象骨骼参数对所述初始动画模型进行形态调整,获得目标动画模型。
具体的,材质参数用于对初始动画模型的模型材质进行调整,模型材质包括但不限于面部的光照、阴影、皮肤材质,为头部添加发丝,为面部添加眉毛、睫毛、毛孔;相应的,材质参数包括但不限于皮肤参数、毛发参数、光影参数,其中,皮肤参数包括但不限于皮肤颜色、皮肤纹理、皮肤光泽度;毛发参数包括但不限于头发、眉毛、睫毛、汗毛等参数;光影参数包括但不限于光照、阴影等。骨骼参数用于对初始动画模型的骨骼进行调整,能够通过调整骨骼参数改变面部肌肉的运动方向和面部轮廓;相应的,目标动画模型即为添加的材质特征和骨骼肌肉特征的动画模型。
基于此,确定对象材质参数。基于对象材质参数中包含的皮肤参数、毛发参数、光影参数对初始动画模型进行皮肤、毛发、光影效果的调整,获得具有材质特征的目标动画模型。可以以贴图的方式为初始动画模型添加材质参数对应的材质特征。或者,为初始动画模型添加骨骼状态机,并确定对象骨骼参数。基于对象骨骼参数对初始动画模型进行骨骼、轮廓等形态维度的调整,使用骨骼驱动动画模型中的面部肌肉,获得具有骨骼特征的目标动画模型。可以以贴图的方式为初始动画模型添加骨骼特征。再或者,确定对象材质参数和对象骨骼参数。同时基于对象材质参数和对象骨骼参数对初始动画模型进行调整,获得具有骨骼特征和材质特征的目标动画模型。
沿用上例,在构建了初始动画模型后,使用Unity中的动态材质功能为初始动画模型添加细微的材质变化。根据不同的面部表情、人体结构,调整面部模型以及人体模型的材质属性,使其与目标对象相匹配。通过以贴图的方式添加面部的光影、皮肤、毛发特征,为头部添加发丝,为面部添加眉毛、睫毛、毛孔等材质特征,获得如图3中(b)所示的初始动画模型。可以通过对对象特征数据的调整实现对初始动画模型的灵活调整,包括但不限于对“闭嘴”、“左眼下看”、“左眼斜视”、“右眼下看”、“右眼斜视”等对象特征参数的调整。还可以在初始动画模型的基础上叠加骨骼状态机。通过调整骨骼参数获得不同脸型和体形的动画效果。通过针对初始动画模型添加骨骼状态机,对骨骼进行调整,进而驱动动画模型中的面部肌肉,使得表情变化时面部肌肉和轮廓也会随之改变。
综上所述,基于对象材质参数和/或对象骨骼参数对初始动画模型进行形态调整,获得目标动画模型。从而实现对初始动画模型材质特征和/或骨骼特征进行灵活的调整,使得生成的动画更加生动真实。
本实施例提供的动画模型生成方法,通过确定目标对象的至少两个对象图像,并对至少两个对象图像进行解析,获得目标对象的至少两组对象特征数据;确定与目标对象对应的待处理动画模型,并基于至少两组对象特征数据对待处理动画模型的模型特征参数进行更新,获得至少两个对象图像分别对应的动画帧;利用至少两个对象图像分别对应的动画帧构建初始动画模型。基于对对象图像进行解析获得的对象特征数据,对待处理动画模型的模型特征参数进行更新,进而获得初始动画模型,使得初始动画模型能够表现对象图像中目标对象的形态、表情的信息,进而提高初始动画模型的生成效率,简化初始动画模型的制作流程。
下述结合附图4以本申请提供的动画模型生成方法对表情动画制作的应用为例,对所述动画模型生成方法进行进一步说明。其中,图4示出了本申请一实施例提供的一种应用于表情动画制作的动画模型生成方法的处理流程图,具体包括以下步骤:
步骤S402:利用包括至少两个图像采集维度的图像采集设备,采集目标对象的至少两个深度对象图像。
在表情动画制作场景下,采用深度摄像机录制用户的面部表情,获得图像或视频。图像或视频可以进行本地保存。深度摄像机的摄像头分为颜色摄像头和深度摄像头,颜色摄像头用于记录场景内的图像,而深度摄像头用于记录场景内物体的深度坐标。进而基于图像和深度坐标确定深度对象图像的对象特征数据。
步骤S404:对至少两个深度对象图像进行解析,获得目标对象的至少两组对象特征数据。
实际应用中,可以基于ARkit的面部表情录制APP针对用户的表情进行采集。基于ARkit的面部追踪功能,APP可以在手机或平板设备上运行,用户可以通过摄像头来实时录制面部表情,捕捉面部表情数据并保存。APP中加入本地局域网通讯功能,除保存数据之外,也可以连接到PC端,便于后续实时查看面部模型的表情效果。对象特征数据可以是包括眼睛、下巴、嘴、眉毛、脸颊、鼻子、舌头等器官的形态数据,可以将形态数据转换为Unity帧动画曲线,表示特征的细微变化。
对象特征数据包括52项:眨左眼、左眼下看、左眼内看、左眼外看、左眼上看、左眼斜视、左眼睁大、眨右眼、右眼下看、右眼内看、右眼外看、右眼上看、右眼斜视、右眼睁大、下巴向前、下巴向左、下巴向右、下巴打开、闭嘴、嘟嘴、噘嘴、左嘴角、右嘴角、左嘴角笑、右嘴角笑、左嘴角哭、右嘴角哭、左嘴角酒窝、右嘴角酒窝、嘴角左侧拉伸、嘴角右侧拉伸、翻下嘴唇、上嘴唇、耸下嘴唇、耸上嘴唇、嘴巴左侧按下、嘴巴右侧按下、左下嘴唇、右下嘴唇、左上嘴唇、右上嘴唇、眉毛左下、眉毛右下、眉心向上、眉毛左上、眉毛右上、脸颊鼓起、脸颊左眯、脸颊右眯、鼻子左嘲讽、鼻子右嘲讽、舌头伸出等。
上述52项表情数据是ARkit基础的表情单位,即表情Pose,任何表情都可以通过这52个表情Pose组合而得到。将APP中录制得到的表情图像转化为这52项表情数据,每一帧会获得52个表情数据。表情数据可以转化为Unity帧动画曲线,用于后续的动画制作。表情数据将驱动面部模型的骨骼变化,实现不同的面部表情。
步骤S406:确定与目标对象对应的待处理动画模型。
在Unity中导入面部模型,导入的面部模型即为骨骼结构正确的初始化面部模型,将面部模型作为待处理动画模型进行后续的表情动画制作。
步骤S408:针对待处理动画模型创建动画控制器,并建立动画控制器与待处理动画模型之间的控制连接。
在Unity的动画系统中创建一个面部动画控制器,并将面部动画控制器与待处理动画模型之间进行绑定,建立面部动画控制器与待处理动画模型之间的控制连接。从而可以通过面部动画控制器控制后续待处理动画模型的播放和暂停。便于对待处理动画模型进行播放和测试。
步骤S410:基于至少两组对象特征数据对待处理动画模型的模型特征参数进行更新,获得至少两个深度对象图像分别对应的动画帧。
步骤S412:针对待处理动画模型创建动画状态机,并利用动画状态机对各深度对象图像对应的动画帧中,任意对象特征进行状态调整和播放测试。
设计动画状态机,在面部动画控制器中创建动画状态机,用于控制面部骨骼的动画播放逻辑。将录制的52项表情数据应用于动画状态机中的不同状态,以实现对各项表情数据进行单独调整。还可以在动画状态机中创建不同的动画状态,并为每个状态分配不同的表情数据。动画状态可以单独存储为表情动画中的一帧,实现单帧表情存储,或者通过图像截取的方式保存表情图像。
步骤S414:按照至少两个深度对象图像分别对应的图像顺序,对至少两个深度对象图像分别对应的动画帧进行连接,获得初始动画模型。
通过激活动画状态机来播放面部表情动画。可以通过脚本或用户界面触发动画状态的切换,实现不同的面部表情。还可以在动画状态机中连接不同的动画状态,以控制面部表情的切换。以及为动画状态机绑定动画参数,例如触发器参数(触发表情的时刻为是,其余状态为否)或布尔参数。这些参数可以用来控制面部表情的触发和停止,实现表情动画的播放测试。根据录制的表情数据,使用Unity的动画状态机来控制面部模型的骨骼变化,从而实现不同的面部表情效果,通过播放器来实时显示面部表情。
步骤S416:确定对象材质参数和对象骨骼参数,并基于对象材质参数和对象骨骼参数对初始动画模型进行形态调整,获得目标动画模型。
为了使面部表情更加真实和生动,可以使用Unity中的动态材质功能来为面部模型添加细微的材质变化。根据不同的面部表情,调整面部模型的材质属性,使其与表情相匹配。通过添加材质贴图,改变面部的光照、阴影、皮肤材质,为头部添加发丝,为面部添加眉毛、睫毛、毛孔等,实现对表情风格的调整。
进一步的,为了增加表情动画的自由度和多样性,可以在面部表情的基础上叠加捏脸骨骼状态机。捏脸骨骼状态机可以通过调整面部骨骼的参数来实现不同的脸型。提高表情与面部轮廓的贴合程度,使得表情变化时面部肌肉和轮廓也会随之改变。提高捏脸骨骼与表情骨骼的适配性以及统一性,二者相互配合,相互影响。从而实现真实、生动的面部表达效果。
综上所述,通过确定目标对象的至少两个对象图像,并对至少两个对象图像进行解析,获得目标对象的至少两组对象特征数据;确定与目标对象对应的待处理动画模型,并基于至少两组对象特征数据对待处理动画模型的模型特征参数进行更新,获得至少两个对象图像分别对应的动画帧;利用至少两个对象图像分别对应的动画帧构建初始动画模型。基于对对象图像进行解析获得的对象特征数据,对待处理动画模型的模型特征参数进行更新,进而获得初始动画模型,使得初始动画模型能够表现对象图像中目标对象的形态、表情的信息,进而提高初始动画模型的生成效率,简化初始动画模型的制作流程。
与上述方法实施例相对应,本申请还提供了动画模型生成装置实施例,图5示出了本申请一实施例提供的一种动画模型生成装置的结构示意图。如图5所示,该装置包括:
确定模块502,被配置为确定目标对象的至少两个对象图像,并对至少两个对象图像进行解析,获得所述目标对象的至少两组对象特征数据;
更新模块504,被配置为确定与所述目标对象对应的待处理动画模型,并基于至少两组对象特征数据对所述待处理动画模型的模型特征参数进行更新,获得至少两个对象图像分别对应的动画帧;
构建模块506,被配置为利用至少两个对象图像分别对应的动画帧构建初始动画模型。
一个可选地实施例,所述确定模块502,进一步被配置为:
利用包括至少两个图像采集维度的图像采集设备,采集目标对象的至少两个深度对象图像。
一个可选地实施例,所述确定模块502,进一步被配置为:确定所述图像采集设备的至少两个图像采集维度中,每个图像采集维度对应的摄像头;基于各图像采集维度对应的摄像头采集目标对象的至少两个深度对象图像。
一个可选地实施例,所述确定模块502,进一步被配置为:
在所述目标对象为面部对象的情况下,在对象图像中提取面部器官形态数据,并将所述面部器官形态数据作为对象特征数据;
在所述目标对象为人体对象的情况下,在对象图像中提取人体动作数据,并将所述人体动作数据作为对象特征数据。
一个可选地实施例,所述更新模块504,还被配置为:
确定所述待处理动画模型预置的模型特征参数,将所述模型特征参数调整至预设的参数区间。
一个可选地实施例,所述更新模块504,还被配置为:
针对所述待处理动画模型创建动画控制器,并建立所述动画控制器与所述待处理动画模型之间的控制连接。
一个可选地实施例,所述更新模块504,还被配置为:
针对所述待处理动画模型创建动画状态机,并利用所述动画状态机对各对象图像对应的动画帧中的任意对象特征进行状态调整和/或播放测试。
一个可选地实施例,所述构建模块506,进一步被配置为:
按照所述至少两个对象图像分别对应的图像顺序,对所述至少两个对象图像分别对应的动画帧进行连接,获得初始动画模型。
一个可选地实施例,所述构建模块506,还被配置为:
对所述初始动画模型进行播放操作,并获取所述初始动画模型的动画状态图像,且将所述动画状态图像作为动画表情存储。
一个可选地实施例,所述构建模块506,还被配置为:
确定对象材质参数和/或对象骨骼参数;基于所述对象材质参数和/或所述对象骨骼参数对所述初始动画模型进行形态调整,获得目标动画模型。
综上所述,通过确定目标对象的至少两个对象图像,并对至少两个对象图像进行解析,获得目标对象的至少两组对象特征数据;确定与目标对象对应的待处理动画模型,并基于至少两组对象特征数据对待处理动画模型的模型特征参数进行更新,获得至少两个对象图像分别对应的动画帧;利用至少两个对象图像分别对应的动画帧构建初始动画模型。基于对对象图像进行解析获得的对象特征数据,对待处理动画模型的模型特征参数进行更新,进而获得初始动画模型,使得初始动画模型能够表现对象图像中目标对象的形态、表情的信息,进而提高初始动画模型的生成效率,简化初始动画模型的制作流程。
上述为本实施例的一种动画模型生成装置的示意性方案。需要说明的是,该动画模型生成装置的技术方案与上述的动画模型生成方法的技术方案属于同一构思,动画模型生成装置的技术方案未详细描述的细节内容,均可以参见上述动画模型生成方法的技术方案的描述。此外,装置实施例中的各组成部分应当理解为实现该程序流程各步骤或该方法各步骤所必须建立的功能模块,各个功能模块并非实际的功能分割或者分离限定。由这样一组功能模块限定的装置权利要求应当理解为主要通过说明书记载的计算机程序实现该解决方案的功能模块构架,而不应当理解为主要通过硬件方式实现该解决方案的实体装置。
图6示出了根据本申请一实施例提供的一种计算设备600的结构框图。该计算设备600的部件包括但不限于存储器610和处理器620。处理器620与存储器610通过总线630相连接,数据库650用于保存数据。
计算设备600还包括接入设备640,接入设备640使得计算设备600能够经由一个或多个网络660通信。这些网络的示例包括公用交换电话网(PSTN)、局域网(LAN)、广域网(WAN)、个域网(PAN)或诸如因特网的通信网络的组合。接入设备640可以包括有线或无线的任何类型的网络接口(例如,网络接口卡(NIC))中的一个或多个,诸如IEEE802.11无线局域网(WLAN)无线接口、全球微波互联接入(Wi-MAX)接口、以太网接口、通用串行总线(USB)接口、蜂窝网络接口、蓝牙接口、近场通信(NFC)接口,等等。
在本申请的一个实施例中,计算设备600的上述部件以及图6中未示出的其他部件也可以彼此相连接,例如通过总线。应当理解,图6所示的计算设备结构框图仅仅是出于示例的目的,而不是对本申请范围的限制。本领域技术人员可以根据需要,增添或替换其他部件。
计算设备600可以是任何类型的静止或移动计算设备,包括移动计算机或移动计算设备(例如,平板计算机、个人数字助理、膝上型计算机、笔记本计算机、上网本等)、移动电话(例如,智能手机)、可佩戴的计算设备(例如,智能手表、智能眼镜等)或其他类型的移动设备,或者诸如台式计算机或PC的静止计算设备。计算设备600还可以是移动式或静止式的服务器。
其中,处理器620用于执行所述动画模型生成方法的计算机可执行指令。
上述为本实施例的一种计算设备的示意性方案。需要说明的是,该计算设备的技术方案与上述的动画模型生成方法的技术方案属于同一构思,计算设备的技术方案未详细描述的细节内容,均可以参见上述动画模型生成方法的技术方案的描述。
本申请一实施例还提供一种计算机可读存储介质,其存储有计算机指令,该指令被处理器执行时以用于动画模型生成方法。
上述为本实施例的一种计算机可读存储介质的示意性方案。需要说明的是,该存储介质的技术方案与上述的动画模型生成方法的技术方案属于同一构思,存储介质的技术方案未详细描述的细节内容,均可以参见上述动画模型生成方法的技术方案的描述。
本申请一实施例还提供一种芯片,其存储有计算机程序,该计算机程序被芯片执行时实现所述动画模型生成方法的步骤。
上述对本申请特定实施例进行了描述。其它实施例在所附权利要求书的范围内。在一些情况下,在权利要求书中记载的动作或步骤可以按照不同于实施例中的顺序来执行并且仍然可以实现期望的结果。另外,在附图中描绘的过程不一定要求示出的特定顺序或者连续顺序才能实现期望的结果。在某些实施方式中,多任务处理和并行处理也是可以的或者可能是有利的。
所述计算机指令包括计算机程序代码,所述计算机程序代码可以为源代码形式、对象代码形式、可执行文件或某些中间形式等。所述计算机可读介质可以包括:能够携带所述计算机程序代码的任何实体或装置、记录介质、U盘、移动硬盘、磁碟、光盘、计算机存储器、只读存储器(ROM,Read-Only Memory)、随机存取存储器(RAM,Random Access Memory)、电载波信号、电信信号以及软件分发介质等。需要说明的是,所述计算机可读介质包含的内容可以根据司法管辖区内立法和专利实践的要求进行适当的增减,例如在某些司法管辖区,根据立法和专利实践,计算机可读介质不包括电载波信号和电信信号。
需要说明的是,对于前述的各方法实施例,为了简便描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本申请并不受所描述的动作顺序的限制,因为依据本申请,某些步骤可以采用其它顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于优选实施例,所涉及的动作和模块并不一定都是本申请所必须的。
在上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述的部分,可以参见其它实施例的相关描述。
以上公开的本申请优选实施例只是用于帮助阐述本申请。可选实施例并没有详尽叙述所有的细节,也不限制该发明仅为所述的具体实施方式。显然,根据本申请的内容,可作很多的修改和变化。本申请选取并具体描述这些实施例,是为了更好地解释本申请的原理和实际应用,从而使所属技术领域技术人员能很好地理解和利用本申请。本申请仅受权利要求书及其全部范围和等效物的限制。
- 用于生成动画的方法和装置
- 一种混合流体相变动画生成方法及装置
- 一种口语测评方法、装置及一种生成口语测评模型的装置
- 三维模型的生成方法、装置、硬件装置
- 用于生成在测试装置上可实施的模型的方法和测试装置
- 角色动画的生成方法、动画生成模型的训练方法及装置
- 光纤总线接口的测试方法及相关设备