一种基于关系和风格感知的多模态场景生成方法
文献发布时间:2024-04-18 19:59:31
技术领域
本发明涉及计算机视觉及3D多模态技术领域,更具体的说是涉及一种基于关系和风格感知的多模态场景生成方法。
背景技术
3D场景生成主要是指利用计算机技术以及相应的算法生成真实的3D场景,这项技术在电影、视频、游戏产业、增强和虚拟现实技术和机器人等领域有着巨大应用潜力。其中,可控制的场景合成是指以一种允许控制或操纵场景生成的过程,用户可以指定他们想要在生成的场景中出现的3D物体。现有的可控场景生成方法常用的控制机制主要有文本描述、语义映射和场景图。其中,场景图提供了一个强大的工具来抽象场景内容,包括场景上下文和对象关系,同时场景图可以为用户提供一个更适合的操作界面。
目前的场景图主要分为两种:第一种方法只学习生成场景布局,3D物体则是从给定的数据库中检索,例如Graph-to-Box;第二种方法同时学习生成场景布局和3D物体形状,例如:Graph-to-3D。但是这两种方法都有明显的不足及缺陷:第一种基于检索的方法生成的物体形状受到检索的数据库的大小的限制;第二种方法,形状的生成依赖于预先训练好的形状编码,这些编码来自具有类别感知能力的自动解码器。这种半生成设计减少了生成输出的形状多样性,且生成的3D物体形状不具有细粒度的纹理特征。同时目前的各种方法对场景中所包含的对象之间的局部与全局上下文关系考虑甚少,这使得当前的3D场景生成方法的一致性效果较差。因此,如何提供一种基于关系和风格感知的多模态场景生成方法是本领域技术人员亟需解决的问题。
发明内容
有鉴于此,本发明提供了一种基于关系和风格感知的多模态场景生成方法,使用多模态大模型-CLIP增强场景图数据的上下文关系信息,同时采用基于图卷积神经网络的双流结构,分别预测场景布局和相应的3D形状。
为了实现上述目的,本发明提供如下技术方案:
一种基于关系和风格感知的多模态场景生成方法,包括以下步骤:
S1、获取原始场景图,为原始场景图中每个节点和每条边初始化一个可学习的特征向量,使用CLIP的文本编码器将节点的语义标签和边的关系信息进行编码,同时将场景图中每个节点对应的位置3D框的参数特征化,得到特征增强后的场景图;
S2、将特征增强后的场景图分为两个部分,第一部分由可学习的特征向量和编码后的语义标签组成,第二部分由参数化后的每个物体对应的位置3D框参数组成,两部分场景图的边的特征都是编码后的关系信息,第一部分送入形状编码器,第二部分送入布局编码器;
S3、将形状编码器和布局编码器的输出送入一个基于图卷积神经网络的特征交互模块中,学习得到联合的布局-形状后验分布,最后采样得到特征向量z
S4、将更新后的场景图分别送入布局解码器和形状解码器中,其中布局解码器的输出为场景中对应的物体3D框及布局,形状解码器输出的为含有上下文关系信息的形状嵌入;
S5、将形状嵌入作为隐式扩散模型的条件输入,训练过程中使用VQ-VAE编码3D形状得到初始的形状特征,推理过程中随机的高斯噪声通过隐式扩散模型去噪,生成物体形状;
S6、用户首先输入风格提示文本,利用S5中生成的物体形状作为神经辐射场的初始化,然后使用CLIP指导对其进行优化,得到具有细粒度纹理及风格的物体的3D形状,最后将物体的3D形状和场景布局相融合,得到完整的场景。
可选的,S1中使用嵌入层初始化节点的边的特征,两个相邻的节点的特征分别记为o
p
p
3D框的参数通过3层的MLP进行特征化,得到的特征表示为b
可选的,S2中的形状编码器E
f
f
其中,N为节点的数量。
可选的,S3中的特征交互模块E
特征交互模块E
可选的,S4中形状解码器D
式中,
可选的,S5中使用体素化空间中截断SDF作为3D形状的表示,使用VQ-VAE模型作为3D形状的压缩器,将3D形状编码成一个潜在维度的特征x
在推理过程中,给定隐式扩散模型一个随机的高斯噪声,形状嵌入R作为条件,即得到相应的3D形状。
可选的,S6中用户输入带有风格信息的文本提示y,利用多模态大模型CLIP的文本编码器E
式中,
经由上述的技术方案可知,与现有技术相比,本发明提供了一种基于关系和风格感知的多模态场景生成方法,具有以下有益效果:本发明利用多模态大模型-CLIP处理分析上下文信息的能力,增强了场景图中的各节点之前的关系信息;使用生成模型-隐式扩散模型及神经辐射场,同时引入多模态大模型—CLIP进行优化指导,从而实现了生成物体形状的多样性及真实性;可以通过场景图及用户输入的风格文本,实现可控的场景生成及风格感知,解决了目前现有的场景生成方法的不足。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
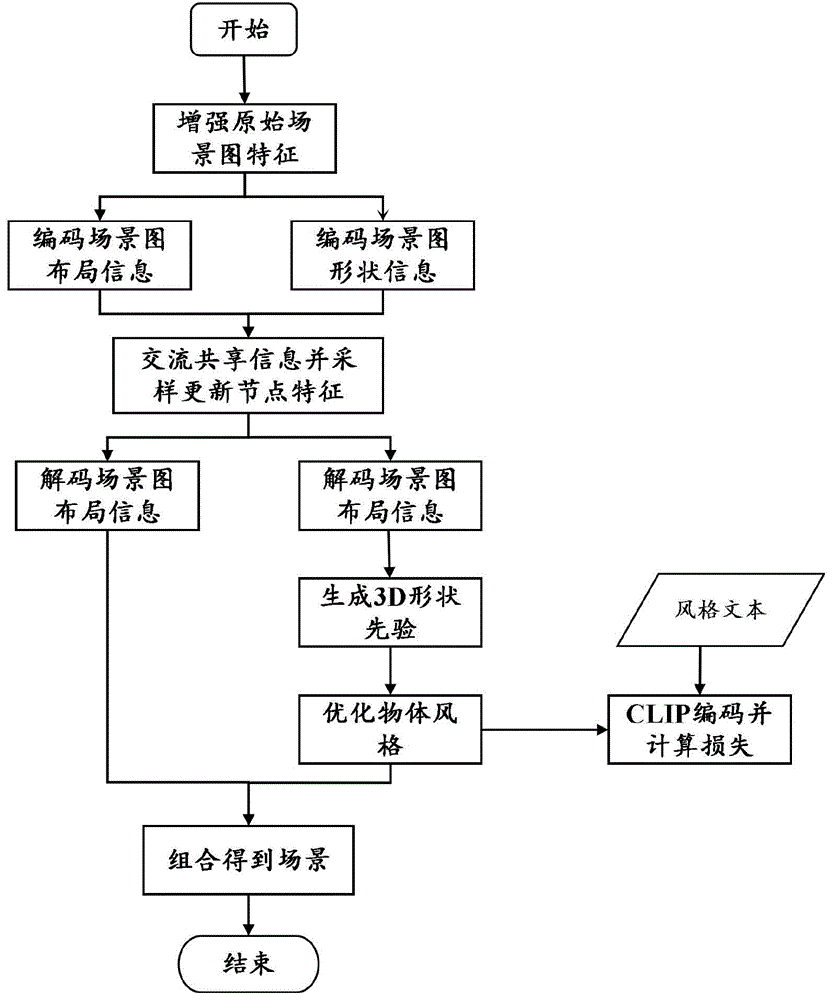
图1为本发明的多模态场景生成方法流程图;
图2为本发明一个实施例中的多模态场景生成方法流程图;
图3为本发明一个实施例中的多模态场景生成方法原理图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明实施例公开了一种基于关系和风格感知的多模态场景生成方法,如图1所示,包括以下步骤:
S1、获取原始场景图,为原始场景图中每个节点和每条边初始化一个可学习的特征向量,使用CLIP的文本编码器将节点的语义标签和边的关系信息进行编码,同时将场景图中每个节点对应的位置3D框的参数特征化,得到特征增强后的场景图;
S2、将特征增强后的场景图分为两个部分,第一部分由可学习的特征向量和编码后的语义标签组成,第二部分由参数化后的每个物体对应的位置3D框参数组成,两部分场景图的边的特征都是编码后的关系信息,第一部分送入形状编码器,第二部分送入布局编码器;
S3、将形状编码器和布局编码器的输出送入一个基于图卷积神经网络的特征交互模块中,学习得到联合的布局-形状后验分布,最后采样得到特征向量z
S4、将更新后的场景图分别送入布局解码器和形状解码器中,其中布局解码器的输出为场景中对应的物体3D框及布局,形状解码器输出的为含有上下文关系信息的形状嵌入;
S5、将形状嵌入作为隐式扩散模型的条件输入,训练过程中使用VQ-VAE编码3D形状得到初始的形状特征,推理过程中随机的高斯噪声通过隐式扩散模型去噪,生成物体形状;
S6、用户首先输入风格提示文本,利用S5中生成的物体形状作为神经辐射场的初始化,然后使用CLIP指导对其进行优化,得到具有细粒度纹理及风格的物体的3D形状,最后将物体的3D形状和场景布局相融合,得到完整的场景。
原始场景图数据主要由节点和连接节点的边组成,每个节点代表场景中的一个物体形状,节点带有语义标签;每条边代表场景中每个物体之间的关系,每条边带有相应的关系信息。在本发明的一个实施例中,以场景中的床和灯为例,其生成流程如图2所示,生成原理如图3所示,。
进一步的,S1中使用嵌入层初始化节点的边的特征,两个相邻的节点的特征分别记为o
p
p
3D框的参数通过3层的MLP进行特征化,得到的特征表示为b
进一步的,S2中的形状编码器E
f
f
其中,N为节点的数量。
在本发明的一个实施例中,形状编码器E
进一步的,S3中的特征交互模块E
特征交互模块E
在本发明的一个实施例中,由于布局和形状预测是相关的任务,因此使用基于图卷积神经网络的特征交互模块鼓励两条支路之间的交互。
进一步的,S4中形状解码器D
式中,
在本发明的一个实施例中,形状解码器D
进一步的,S5中使用体素化空间中截断SDF作为3D形状的表示,使用VQ-VAE模型作为3D形状的压缩器,将3D形状编码成一个潜在维度的特征x
在推理过程中,给定隐式扩散模型一个随机的高斯噪声,形状嵌入R作为条件,即得到相应的3D形状。
进一步的,S6中用户输入带有风格信息的文本提示y,利用多模态大模型CLIP的文本编码器E
式中,
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 基于深度神经网络声发射信号分离的变压器局放检测方法
- 基于电流和超声信号的变压器局放检测系统、方法及设备