一种基于数据挖掘的异常光谱识别分析方法
文献发布时间:2024-04-18 20:00:50
技术领域
本发明涉及光谱数据处理技术领域,尤其涉及一种基于数据挖掘的异常光谱识别分析方法。
背景技术
在线近红外广泛应用在烟叶生产过程中的各个环节,每个环节都会产生庞大的光谱数据,烟叶生产是一个复杂的过程包含有正常生产和非正常生产(外界环境的干扰、生产的故障、仪器的维修等),而近红外在这些过程中在连续不间断的采集光谱数据,导致产生的大量的没有任何价值或意义的数据,这些数据不仅没有提供任何有用的信息,用于做出任何结论或决策,并且这些数据的存在会对数据分析造成负面影响,影响数据分析结果的可信度和准确性,甚至导致作出错误的决策。
目前,在线近红外大多数采用人工手动删除数据或者数据收集到一定的程度,自动清除之前的数据,只保存一定时间内的数据,这样导致数据保存的时间过短,没有延续性,而且删除了有效光谱数据,造成很多有价值的数据信息丢失,严重的经济损失。大量无用的数据,不仅占据内存大,而且对实际数据分析没有任何贡献的同时造成数据污染,影响数据反映的真实性,不仅对仪器设备存储造成干扰,而且影响仪器的寿命和使用。
因此,亟需一种基于数据挖掘的异常光谱识别分析方法。
发明内容
本发明的目的是提供一种基于数据挖掘的异常光谱识别分析方法,以解决上述现有技术中的问题,能够在在线生产过程中建立一套异常识别机制,在剔除这些无效数据的同时,可以提高数据的准确性、可信度和实用性,从而促进有效数据的使用和价值的发挥,保障分析结果的可靠性和决策。
本发明提供了一种基于数据挖掘的异常光谱识别分析方法,其中,包括:
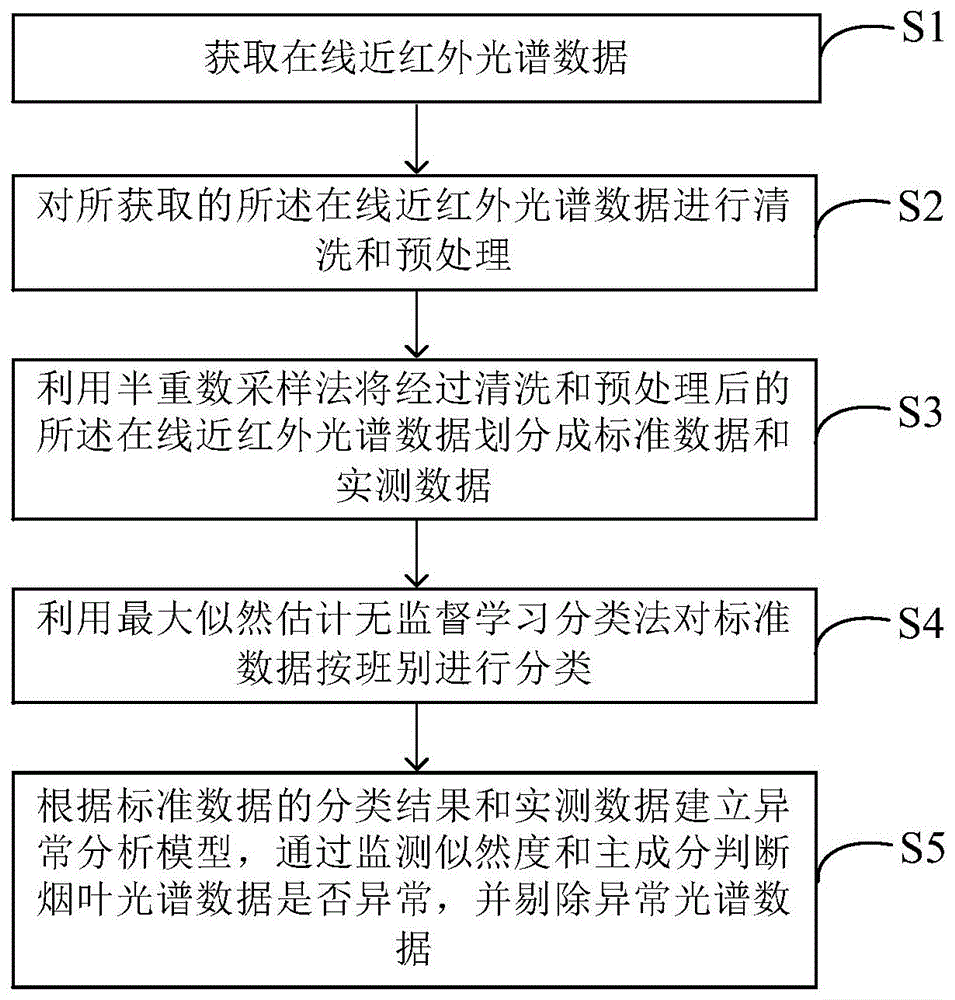
获取在线近红外光谱数据;
对所获取的所述在线近红外光谱数据进行清洗和预处理;
利用半重数采样法将经过清洗和预处理后的所述在线近红外光谱数据划分成标准数据和实测数据;
利用最大似然估计无监督学习分类法对标准数据按班别进行分类;
根据标准数据的分类结果和实测数据建立异常分析模型,通过监测似然度和主成分判断烟叶光谱数据是否异常,并剔除异常光谱数据。
如上所述的基于数据挖掘的异常光谱识别分析方法,其中,优选的是,所述在线近红外光谱数据包括一年四季不同外部环境生产下所收集的烟叶光谱、皮带光谱或半烟叶半皮带光谱。
如上所述的基于数据挖掘的异常光谱识别分析方法,其中,优选的是,所述对所获取的所述在线近红外光谱数据进行清洗和预处理,具体包括:
在所获取的所述在线近红外光谱数据中,剔除光谱吸光度大于0且小于0.5的数据,以剔除明显异常数据;
对剔除明显异常后的所有数据进行标准正态变量变换;
对标准正态变量变换后的光谱数据进行指数平滑化。
如上所述的基于数据挖掘的异常光谱识别分析方法,其中,优选的是,所述对剔除明显异常后的所有数据进行标准正态变量变换,具体包括:
通过以下公式进行标准正态变量变换:
其中,x
所述对标准正态变量变换后的光谱数据进行指数平滑化,具体包括:
通过以下公式进行指数平滑化:
b
b
其中,向量序列{x
如上所述的基于数据挖掘的异常光谱识别分析方法,其中,优选的是,所述利用半重数采样法将经过清洗和预处理后的所述在线近红外光谱数据划分成标准数据和实测数据,具体包括:
从经过清洗和预处理后的所述在线近红外光谱数据中多次随机选择总样本数的一半样本作为采样子集;
计算每个采样子集中每个样本距离该采样子集中的采样中心点的马氏距离;
计算各采样子集所对应的马氏距离的平均值;
取马氏距离的平均值最小的预设百分数所对应的在线近红外光谱数据作为标准数据;
将标准数据之外的经过清洗和预处理后的所述在线近红外光谱数据作为实测数据。
如上所述的基于数据挖掘的异常光谱识别分析方法,其中,优选的是,所述计算每个采样子集中每个样本距离该采样子集中的采样中心点的马氏距离,具体包括:
通过以下公式计算每个采样子集中每个样本距离该采样子集中的采样中心点的马氏距离:
其中,x
并且,R
其中,X表示经过清洗和预处理后的所有近红外光谱数据,
如上所述的基于数据挖掘的异常光谱识别分析方法,其中,优选的是,所述计算各采样子集所对应的马氏距离的平均值,具体包括:
通过以下公式计算样本x
用主成分分析的得分T代替光谱数据X,这时公式(5)可以表示为:
也可以写成:
其中,t
其中,
如上所述的基于数据挖掘的异常光谱识别分析方法,其中,优选的是,所述预设百分数为5%,
所述取马氏距离的平均值最小的预设百分数所对应的在线近红外光谱数据作为标准数据,具体包括:
通过以下公式确定实测数据:
F(X
其中,f(XD
如上所述的基于数据挖掘的异常光谱识别分析方法,其中,优选的是,所述利用最大似然估计无监督学习分类法对标准数据按班别进行分类,具体包括:
通过以下公式确定标准数据的分布律:
q{X
其中,X
根据标准函数的分布律,确定似然函数为:
其中,H(q|x)为概率,表示通过已知的分布函数与参数,随机生成出x的概率,S表示标准数据X
对公式(11)化简,得到:
对公式(12)中参数求导,根据导数等于0,得到最大似然估计:
其中,d表示标准数据X
对公式(13)进行求解,得到分成的类别为:
F(α)=∫∫H(qx) (13)
其中,F(α)表示分类函数。
如上所述的基于数据挖掘的异常光谱识别分析方法,其中,优选的是,所述根据标准数据的分类结果和实测数据建立异常分析模型,通过监测似然度和主成分判断烟叶光谱数据是否异常,并剔除异常光谱数据,具体包括:
计算以标准数据为基准的似然度分类后每个类别的平均值;
将实测数据在似然度分类主成分空间进行投影,计算每一条实测数据离标准数据平均值的马氏距离;
利用标准数据的95%分位数判断马氏距离是否构成异常,同时监测实测数据在标准数据的不同主成分上的投影,如果大于标准数据在同一主成分上投影的3倍标准差则实测数据异常,剔除异常光谱数据,同时计算每类超过2倍标准偏差的异常率以及超过3倍的平滑异常率,以确定造成异常的班别。
本发明提供一种基于数据挖掘的异常光谱识别分析方法,通过数据挖掘技术从前期收集的在线近红外海量数据中寻找有用的信息,建立一套异常光谱识别分析策略,可以对在线生产过程中的烟叶光谱数据进行异常识别并剔除,保存大量有效数据的同时排除无效数据,不仅减少内存的消耗,延长仪器使用寿命,而且可以提高数据的准确性、可信度和实用性,从而促进有效数据的使用和价值的发挥,保障数据分析结果的可靠性和有效决策。
附图说明
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步描述,其中:
图1为本发明提供的基于数据挖掘的异常光谱识别分析方法实施例的流程图;
图2为本发明提供的基于数据挖掘的异常光谱识别分析方法实施例的逻辑图;
图3为本发明提供的基于数据挖掘的异常光谱识别分析方法实施例的光谱图;
图4为本发明提供的基于数据挖掘的异常光谱识别分析方法实施例的光谱图中的异常位置示意图;
图5为本发明提供的基于数据挖掘的异常光谱识别分析方法实施例的标准数据与实测数据的示意图;
图6为本发明提供的基于数据挖掘的异常光谱识别分析方法实施例的似然度分类示意图;
图7为本发明提供的基于数据挖掘的异常光谱识别分析方法实施例的异常剔除示意图。
具体实施方式
现在将参照附图来详细描述本公开的各种示例性实施例。对示例性实施例的描述仅仅是说明性的,决不作为对本公开及其应用或使用的任何限制。本公开可以以许多不同的形式实现,不限于这里所述的实施例。提供这些实施例是为了使本公开透彻且完整,并且向本领域技术人员充分表达本公开的范围。应注意到:除非另外具体说明,否则在这些实施例中阐述的部件和步骤的相对布置、材料的组分、数字表达式和数值应被解释为仅仅是示例性的,而不是作为限制。
本公开中使用的“第一”、“第二”:以及类似的词语并不表示任何顺序、数量或者重要性,而只是用来区分不同的部分。“包括”或者“包含”等类似的词语意指在该词前的要素涵盖在该词后列举的要素,并不排除也涵盖其他要素的可能。“上”、“下”等仅用于表示相对位置关系,当被描述对象的绝对位置改变后,则该相对位置关系也可能相应地改变。
在本公开中,当描述到特定部件位于第一部件和第二部件之间时,在该特定部件与第一部件或第二部件之间可以存在居间部件,也可以不存在居间部件。当描述到特定部件连接其它部件时,该特定部件可以与所述其它部件直接连接而不具有居间部件,也可以不与所述其它部件直接连接而具有居间部件。
本公开使用的所有术语(包括技术术语或者科学术语)与本公开所属领域的普通技术人员理解的含义相同,除非另外特别定义。还应当理解,在诸如通用字典中定义的术语应当被解释为具有与它们在相关技术的上下文中的含义相一致的含义,而不应用理想化或极度形式化的意义来解释,除非这里明确地这样定义。
对于相关领域普通技术人员已知的技术、方法和设备可能不作详细讨论,但在适当情况下,技术、方法和设备应当被视为说明书的一部分。
如图1和图2所示,本实施例提供的基于数据挖掘的异常光谱识别分析方法在实际执行过程中,具体包括如下步骤:
步骤S1、获取在线近红外光谱数据。
其中,所述在线近红外光谱数据包括一年四季不同外部环境生产下所收集的烟叶光谱、皮带光谱或半烟叶半皮带光谱。图3所示为获取的一线润叶在线近红外光谱采集的从2022年6月1号到12月22号的半年不同温湿度、光照的烟叶光谱、皮带光谱、半烟叶半皮带光谱等,采集的光谱平均每15秒采集一条,总共70多万条。
步骤S2、对所获取的所述在线近红外光谱数据进行清洗和预处理。
对图3中的70多万条数据进行清洗和预处理。在本发明的基于数据挖掘的异常光谱识别分析方法的一种实施方式中,所述步骤S2具体可以包括:
步骤S21、在所获取的所述在线近红外光谱数据中,剔除光谱吸光度大于0且小于0.5的数据,以剔除明显异常数据。
如图4所示,结合实际情况,在光谱吸光度第18和58的位置有明显异常情况,所以剔除第18个吸光度值>0.39和光谱吸光度的第58个吸光度值<0.22的光谱数据,剩下62万多条数据。
步骤S22、对剔除明显异常后的所有数据进行标准正态变量变换(SNV)。
具体可地,通过以下公式进行标准正态变量变换:
其中,x
如公式(1)所示,准正态变量变换的变换规则为将每一条光谱数据减去其均值,除以其标准差。通过对剔除明显异常后所有数据进行标准正态变量变换,能够纠正基线漂移。
步骤S23、对标准正态变量变换后的光谱数据进行指数平滑化。
具体地,通过以下公式进行指数平滑化:
其中,向量序列{x
其中,示例性地,取参数为t=0.01的指数平滑化类似于窗口大小为199的移动平均。对标准正态变量变换后的光谱数据进行指数平滑化,能够减少随机误差,保留系统误差。
步骤S3、利用半重数采样法将经过清洗和预处理后的所述在线近红外光谱数据划分成标准数据和实测数据。
生成标准数据,需要将清洗和预处理后的近红外光谱数据利用半数重采样法划分成一部分为实测数据,一部分为测试集即标准数据。标准数据用于建立基准,以对实测数据进行判定。在本发明的基于数据挖掘的异常光谱识别分析方法的一种实施方式中,所述步骤S3具体可以包括:
步骤S31、从经过清洗和预处理后的所述在线近红外光谱数据中多次随机选择总样本数的一半样本作为采样子集。
步骤S32、计算每个采样子集中每个样本距离该采样子集中的采样中心点的马氏距离。
具体地,通过以下公式计算每个采样子集中每个样本距离该采样子集中的采样中心点的马氏距离:
其中,x
并且,R
其中,X表示经过清洗和预处理后的所有近红外光谱数据,
步骤S33、计算各采样子集所对应的马氏距离的平均值。
具体地,通过以下公式计算样本x
用主成分分析的得分T代替光谱数据X,这时公式(5)可以表示为:
也可以写成:
其中,t
其中,
步骤S34、取马氏距离的平均值最小的预设百分数所对应的在线近红外光谱数据作为标准数据。
其中,所述预设百分数为5%,具体地,通过以下公式确定实测数据:
F(X
其中,f(XD
步骤S35、将标准数据之外的经过清洗和预处理后的所述在线近红外光谱数据作为实测数据。
综上所述,半数重采样法的过程如下:从预处理后的光谱中随机选择总样本数的一半样本作为采样子集,计算每个采样子集中每个样本距离这个采样中心点的马氏距离。对光谱数据进行多次随机采样,并记录采样后计算的马氏距离,从而算出每条向量的马氏距离的平均值,取平均值最小的5%作为实测数据即3.1万多条数据。如图5所示为样本马氏距离的平均值。黑色横线为5%分位数。
步骤S4、利用最大似然估计无监督学习分类法对标准数据按班别进行分类。
在本发明的基于数据挖掘的异常光谱识别分析方法的一种实施方式中,所述步骤S4具体可以包括:
步骤S41、通过以下公式确定标准数据的分布律:
q{X
其中,X
步骤S42、根据标准函数的分布律,确定似然函数为:
其中,H(q|x)为概率,表示通过已知的分布函数与参数,随机生成出x的概率,S表示标准数据X
步骤S43、对公式(11)化简,得到:
步骤S44、对公式(12)中参数求导,根据导数等于0,得到最大似然估计:
其中,d表示标准数据X
步骤S45、对公式(13)进行求解,得到分成的类别为:
其中,F(α)表示分类函数。
图6所示为一线润叶工艺点处的标准数据经过似然度分成6类后,整体的平均水平以及每类的光谱数据分布情况,从图中可以看出前四类分布基本均匀,后面两个类平均水平偏上。
步骤S5、根据标准数据的分类结果和实测数据建立异常分析模型,通过监测似然度和主成分判断烟叶光谱数据是否异常,并剔除异常光谱数据。
在本发明的基于数据挖掘的异常光谱识别分析方法的一种实施方式中,所述步骤S5具体可以包括:
步骤S51、计算以标准数据为基准的似然度分类后每个类别的平均值。
步骤S52、将实测数据在似然度分类主成分空间进行投影,计算每一条实测数据离标准数据平均值的马氏距离。
步骤S53、利用标准数据的95%分位数判断马氏距离是否构成异常,同时监测实测数据在标准数据的不同主成分上的投影,如果大于标准数据在同一主成分上投影的3倍标准差则实测数据异常,剔除异常光谱数据,同时计算每类超过2倍标准偏差的异常率以及超过3倍的平滑异常率,以确定造成异常的班别。
如图7所示是一线润叶工艺点处的主成分监测(这里选择第三主成分)。浅蓝色点表示原数据点的第三主成分,深蓝色线表示平滑后数据点的第三主成分,浅色线表示参考数据的两倍标准差,深色线表示参考数据的三倍标准差,异常率表示超出三倍标准差的数据占比,平滑异常率表示平滑后超出两倍标准差的数据占比。前第一、二、三、四类都没有出现超过3倍标准偏差光谱数据,第五类开始出现平滑异常率42.17%,第六类开始恢复正常,经过排查,在第六班的时候,由于仪器出现故障,导致物料流量不稳定,出现半烟叶半皮带情况。通过监测似然度和主成分可以判断烟叶光谱是否异常并剔除异常,保留正常的光谱数据,从原始的70多万到最后剩下的正常数据55多万条,异常数据基本占据21%。
通过步骤S5,剔除了异常光谱数据,只保留正常的光谱数据。
本发明实施例提供的基于数据挖掘的异常光谱识别分析方法,通过数据挖掘技术从前期收集的在线近红外海量数据中寻找有用的信息,建立一套异常光谱识别分析策略,可以对在线生产过程中的烟叶光谱数据进行异常识别并剔除,保存大量有效数据的同时排除无效数据,不仅减少内存的消耗,延长仪器使用寿命,而且可以提高数据的准确性、可信度和实用性,从而促进有效数据的使用和价值的发挥,保障数据分析结果的可靠性和有效决策。
至此,已经详细描述了本公开的各实施例。为了避免遮蔽本公开的构思,没有描述本领域所公知的一些细节。本领域技术人员根据上面的描述,完全可以明白如何实施这里公开的技术方案。
虽然已经通过示例对本公开的一些特定实施例进行了详细说明,但是本领域的技术人员应该理解,以上示例仅是为了进行说明,而不是为了限制本公开的范围。本领域的技术人员应该理解,可在不脱离本公开的范围和精神的情况下,对以上实施例进行修改或者对部分技术特征进行等同替换。本公开的范围由所附权利要求来限定。
- 一种增强增韧竹纤维/聚乳酸复合材料及其制备方法
- 增韧改性聚乳酸、聚己二酸对苯二甲酸丁二酯复合材料及其制备方法
- 一种阻燃增韧可生物降解的聚乳酸材料及其制备方法
- 一种体型聚氨酯增塑聚乳酸复合材料及其制备方法
- 一种增塑聚乳酸复合材料及其制备方法