一种基于yolov5的目标检测模型、检测方法以及训练方法
文献发布时间:2024-04-18 20:02:18
技术领域
本发明涉及一种基于yolov5的目标检测模型、检测方法以及训练方法。
背景技术
体育运动是青少年健康成长不可或缺的一部分,因此,体育运动分析是当前时代背景下的重要技术,但当前不平衡不充分的教师资源分布和学生亟需专业的运动指导之间的矛盾愈发显著,通过人工智能教师对体育运动监考、分析成为最优解决方案,而运动监考与分析的核心在于对运动中人体关键点时序状态获取与表征。
现有技术中运动过程被视为时间序列,传统的技术如隐马尔可夫模型、运动能量图像、(Motion Energy Image,MEI)、运动历史图像(Motion History Image,MHI)、光流算法、时空兴趣点预测、2D关键点预测、RGB-D图像3D关键点预测、二阶段结构的3D关键点预测等算法。
现有技术不足:隐马尔科夫模型虽能大致预测,但这种传统的序列模型不适合时序图像数据的高维特征;MEI和MHI将动态人体运动编码为单个图像,虽在动作识别方面取得良好效果,但对视点变化很敏感;光流计算通过在连续的帧中捕捉水平和垂直运动描述人体和身体部位的特征,但存在模糊、噪音敏感、速度非一致性和积累误差等问题;STIPs对帧进行特征提取后进行帧间匹配从而实现运动分析,但在密集纹理的区域、遮挡等情况下缺乏鲁棒性;2D关键点预测虽能较好预测静止姿态,但难以表征运动过程中的深度信息;基于RGB-D图像的3D关键点预测存在硬件要求高、适配环境严格的问题;二阶段结构的3D关键点预测方法虽能较好地表征运动姿态,但需要目标检测模型辅助进行二阶段检测,导致模型推理较慢。
发明内容
本发明要解决的技术问题,在于提供一种基于yolov5的目标检测模型、检测方法以及训练方法,提高目标检测的速度,提高了检测的效果。
第一方面,本发明提供了一种基于yolov5的目标检测模型,包括:
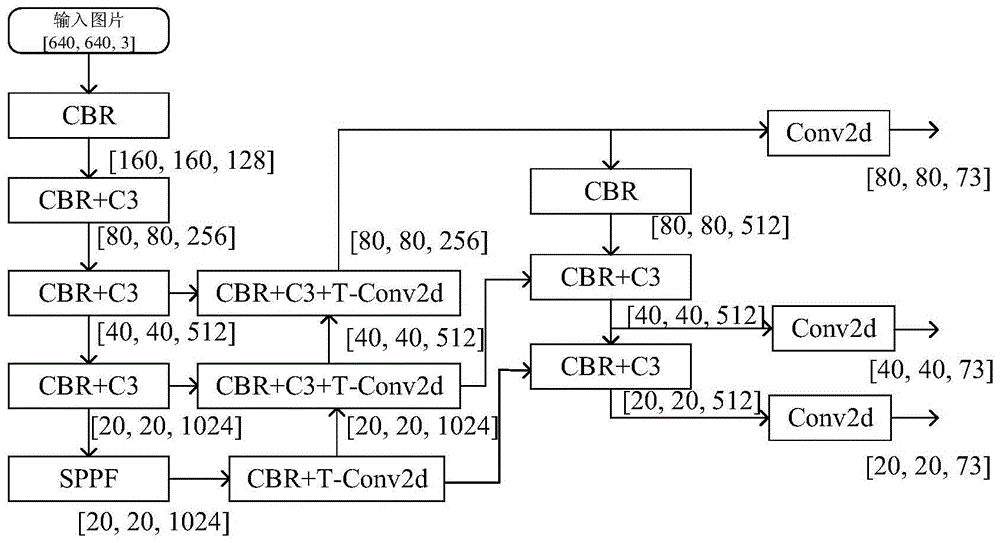
Backbone单元,用于特征提取,对图像进行设定次数的下采样和特征提取,获取到图像内容的特征,并降低参数量,输出不同采样率的第一特征图;
Head单元,用于采用特征金字塔网络结构对Backbone单元中的不同采样率的第一特征图进行信息融合,获取到Backbone单元中浅层的空间信息和深沉的语义信息,并将Backbone单元中浅层的空间信息和深沉的语义信息进行融合,输出不同采样率的第二特征图;
Detect单元,将Head单元中提取到的不同采样率的第二特征图进行特征提取,提取不同采样率的目标类别信息、目标位置信息和目标框大小信息;输出第三特征图;
卷积单元,用于将第三特征图进行卷积处理,输出最终特征图。
进一步地,所述Backbone单元包括CBR模块、三个CBR+C3模块以及SPPF模块,所述CBR模块包括卷积层、批归一化层以及ReLU激活函数层;
每个所述CBR+C3模块为CBR模块与C3模块顺序堆叠;
将图片进入CBR模块处理采样,即分别进行卷积层、BN层以及ReLU激活函数层的处理,得到采样信息,之后再经过两次CBR+C3模块处理采样,得到第一特征图一;将第一特征图一再次经过CBR+C3模块处理采样,得到第一特征图二,将第一特征图二经过SPPF模块处理,得到第一特征图三。
进一步地,所述Head单元包括两个CBR+C3+T-Conv2d模块以及一个CBR+T-Conv2d模块,所述CBR+T-Conv2d模块为CBR模块与转置卷积模块顺序堆叠,所述CBR+C3+T-Conv2d模块为CBR模块先与C3模块顺序堆叠,再与转置卷积模块堆叠;将第一特征图一进行CBR+C3+T-Conv2d模块处理,得到第二特征图一;
将第一特征图二进行CBR+C3+T-Conv2d模块处理,得到第二特征图二;
将第一特征图三进行CBR+T-Conv2d模块处理,得到第二特征图三。
进一步地,所述Detect单元包括CBR模块以及两个CBR+C3模块;
将第二特征图一进行CBR模块处理,得到第三特征图一;
将第二特征图二进行CBR+C3模块处理,得到第三特征图二;
将第二特征图三进行CBR+C3模块处理,得到第三特征图三。
进一步地,将第三特征图一、第三特征图二以及第三特征图三分别进行卷积单元的处理,分别输出最终特征图一、最终特征图二以及最终特征图三。
第二方面,本发明提供了一种目标检测方法,应用于配置有第一方面任一项所述的目标检测模型的终端,所述目标检测方法包括:
获取待检测图片,经过resize、归一化后,送入所述目标检测模型,目标检测模型输出三个特征图,经过NMS后得到对应的3D关键点。
第三方面,本发明提供了一种基于yolov5的目标检测模型的训练方法,用于训练第一方面任一项所述的目标检测模型;具体包括:
将设定格式的训练图片输入至目标检测模型中,进行检测模型的训练;
在模型训练过程中的损失函数如式(2)至式(6)所示;式(2)中的μ
目标模型评估指标采用每个关节的平均位置误差,如式(7)所示;
该公式(7)为模型评估指标,用于评估检测模型效果,当达到设定阈值时,停止目标检测模型的训练,输出训练后的目标检测模块。
进一步地,采用重投影,将3D关键点映射至2D平面,其中2D关键点损失如式(8)所示;
公式(8)的作用是计算2D关键点损失;
将3D预测结果投影至2D,通过计算2D损失进行优化;
记目标检测模型为model,模型推理过程如式(9)所示;式中的
采用式(2)或式(8)计算预测的3D关键点
使用梯度下降的反向传播优化算法,更新目标检测模型权重,如式(12)所示;式中(w
经过不断训练后,所述
进一步地,式(2)中μ
本发明实施例中提供的一个或多个技术方案,至少具有如下技术效果或优点:
本申请实施例提供的基于yolov5的目标检测模型、检测方法以及训练方法,使用端到端神经网络结构,由图像信息直接推理3D关键点,从而降低模型推理算力消耗、提高推理速度;使用重投影方法对训练过程弱监督,利用2D关键点实现辅助监督降低3D关键点数据需求量,从而降低3D数据采集工作量;使用3D Mesh表征方法,将基于3D关键点的人体模型重构,获取Mesh表征。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
附图说明
下面参照附图结合实施例对本发明作进一步的说明。
图1为本发明目标检测模型的结构图;
图2a为本发明CBR模块的结构图;
图2b为本发明C3模块的结构图;
图2c为本发明BottleNeck模块的结构图;
图3为本发明目标检测方法在多种运动的3D关键点及Mesh展示的示意图。
具体实施方式
本申请实施例中的技术方案,总体思路如下:
图1、图2a、图2b以及图2c所示,CBR+C3模块为CBR模块与C3模块顺序堆叠,CBR+T-Conv2d为CBR模块与转置卷积模块顺序堆叠,CBR+C3+T-Conv2d为CBR模块先与C3模块顺序堆叠,再与转置卷积模块堆叠。三个输出为含有关键点检测信息的特征图;[20,20,73]代表的是该特征图的形状,其中20、40、80代表模型输入640尺寸图像分别下采样3次、4次、5次,即缩小23、24和25倍后的平面尺寸,可理解为每个feature_map
其中还有SPPF模块是yolov5中原有的模块,是对SPP的一种改进,用于自适应尺寸输出。
图中的[i,j,k]代表对应模块神经网络输出特征图的形状,如果第一、第二个维度经过该模块缩小二倍,说明该模块中的Conv2d层的kernel size值为2,out channel为inchannel的2倍。
CBR模块由卷积层、BN层以及ReLU激活函数层组成;BottleNeck模块为现有的,用于降低模型参数量,提高模型效率;图2b中提到C3模块存在包括9个BottleNeck;也可以为其他数量的BottleNeck;其中Concat为现有的,经过Concat操作后,特征图的尺寸不变,深度会增加。
本发明目标检测模型输出的三个特征图表征的是不同采样率下各区域关键点分布,特征图的73通道表征信息为[x,y,w,h,confidence,noise,l-eye,r-eye,l-ear,r-ear,l-shoulder,r-shoulder,l-elbow,r-elbow,l-wrist,r-wrist,l-hip,r-hip,l-knee,r-knee,l-ankle,r-ankle],该特征前5位为2D图像上目标人物框的中心点位置、框的大小和置信度,后17*4位分别为17个点位:左眼、右眼、左耳、右耳、左肩、右肩、左肘、右肘、左手腕、右手腕、左髋部、右髋部、左膝盖、右膝盖、左脚踝、右脚踝的3D关键点表征,表征为四个向量:三个3D位置表征和一个可见置信度值δ,即[x,y,z,δ]。
实施例一
图1、图2a、图2b以及图2c所示,本实施例提供本发明提供了一种基于yolov5的目标检测模型,包括:
Backbone单元,用于特征提取,对图像进行设定次数的下采样和特征提取,获取到图像内容的特征,并降低参数量,输出不同采样率的第一特征图;
Head单元,用于采用特征金字塔网络结构对Backbone单元中的不同采样率的第一特征图进行信息融合,获取到Backbone单元中浅层的空间信息和深沉的语义信息,并将Backbone单元中浅层的空间信息和深沉的语义信息进行融合,输出不同采样率的第二特征图;
Detect单元,将Head单元中提取到的不同采样率的第二特征图进行特征提取,提取不同采样率的目标类别信息、目标位置信息和目标框大小信息;输出第三特征图;
卷积单元,用于将第三特征图进行卷积处理,输出最终特征图。
所述Backbone单元包括CBR模块、三个CBR+C3模块以及SPPF模块,所述CBR模块包括卷积层(Convolution layer)、批归一化(Batch Normalization)层以及ReLU激活函数层;
每个所述CBR+C3模块为CBR模块与C3模块顺序堆叠;
将图片进入CBR模块处理采样,即分别进行卷积层、BN层以及ReLU激活函数层的处理,得到采样信息,之后再经过两次CBR+C3模块处理采样,得到第一特征图一;将第一特征图一再次经过CBR+C3模块处理采样,得到第一特征图二,将第一特征图二经过SPPF模块处理,得到第一特征图三,这里的第一特征图一、第一特征图二和第一特征图三为Backbone部分对输入图像提取到的不同采样率特征图;
所述Head单元包括两个CBR+C3+T-Conv2d模块以及一个CBR+T-Conv2d模块,所述CBR+T-Conv2d模块为CBR模块与转置卷积模块顺序堆叠,所述CBR+C3+T-Conv2d模块为CBR模块先与C3模块顺序堆叠,再与转置卷积模块堆叠;将第一特征图一进行CBR+C3+T-Conv2d模块处理,得到第二特征图一;
将第一特征图二进行CBR+C3+T-Conv2d模块处理,得到第二特征图二;
将第一特征图三进行CBR+T-Conv2d模块处理,得到第二特征图三。
所述Detect单元包括CBR模块以及两个CBR+C3模块;
将第二特征图一进行CBR模块处理,得到第三特征图一;
将第二特征图二进行CBR+C3模块处理,得到第三特征图二;
将第二特征图三进行CBR+C3模块处理,得到第三特征图三;
这里的第二特征图一、第二特征图二和第二特征图三为Backbone提取到的不同采样率特征进行信息融合和再提取后的特征图;
将第三特征图一、第三特征图二以及第三特征图三分别进行卷积单元的处理,分别输出最终特征图一、最终特征图二以及最终特征图三,这里的最终特征图一、最终特征图二和最终特征图三为具体包含了目标所在位置、目标框大小和目标类别的特征,三个特征图为不同采样率下的特征提取,能确保模型能够精准识别近距离、中距离和远距离的人物目标。
基于同一发明构思,本申请还提供了与实施例一中的方法对应的装置,详见实施例二。
实施例二
在本实施例中提供了一种基于yolov5的目标检测模型的训练方法,用于训练实施例一所述的目标检测模型;具体包括:
将设定格式的训练图片输入至目标检测模型中,进行检测模型的训练;
在模型训练过程中的损失函数如式(2)至式(6)所示;式(2)中的μ
目标模型评估指标采用每个关节的平均位置误差,如式(7)所示;
该公式(7)为模型评估指标,用于评估检测模型效果,当达到设定阈值时,停止目标检测模型的训练,输出训练后的目标检测模块。
针对优质开源3D关键点数据量少,标注困难等问题,本发明采用重投影,将3D关键点映射至2D平面,其中2D关键点损失如式(8)所示;
公式(8)的作用是计算2D关键点损失;
将3D预测结果投影至2D,通过计算2D损失进行优化,该损失函数在模型训练过程中使用;
记目标检测模型为model,模型推理过程如式(9)所示;式中的
采用式(2)或式(8)计算预测的3D关键点
使用梯度下降的反向传播优化算法,更新目标检测模型权重,如式(12)所示;式中(w
经过不断训练后,所述
由于实际体育监考、教学的可视化设备多数为平面显示屏,为提供清晰三维特征表述,使用SMPL模型对YOLO-Human3D结果进行3D Mesh重构。
基于同一发明构思,本申请提供了实施例一对应的检测方法,详见实施例三。
实施例三
本实施例提供了一种目标检测方法,应用于配置有实施例一种所述目标检测模型的终端,所述目标检测方法包括:
获取待检测图片,经过resize、归一化后,送入所述目标检测模型,目标检测模型输出三个特征图,经过NMS后得到对应的3D关键点。
目标检测模型在RTX 3080Ti(12GB)上对human3.6M数据集进行的消融实验如表1所示。其中模型N的C3模块中BottleNeck个数为2,模型S的C3模块中BottleNeck个数为4,MAP@.5为阈值0.5下的平均精确度均值(MeanAverage Precision,MAP),SPF为每帧的耗时(Seconds PerFrame,SPF);BottleNeck个数可以动态调整,个数越大理论模型精度会高一些,但代价是模型训练和推理的速度会慢,因此合适的值是关键,经过实验证明使用S模型(number ofBottleNecks=4)效果最好,且模型推理速度能被接受。
表1YOLO-Human3D消融实验
由表1消融实验可知,模型在扩大尺寸后能获得更高的表现;当激活函数由SiLU替换为ReLU后会略微损失精度,对速度有一定提升;使用转置卷积代替最近邻二倍上采样后对速度略微损失,对精度提高更多。
相较于传统的Two-Stage结构模型,本模型以One-Stage的End to End形式训练和推理,能够在保证精度的同时大幅提升推理速度,使模型能在更多边缘设备部署,模型参数性能对比如表2所示。
表2模型性能比较
由表2可知传统的3D关键点检测方法需要额外的目标检测模型,或利用多头自注意力机制(Multi Head SelfAttention,MHSA)庞大模型学习长文本间匹配信息。但表2结果表明,传统的Two-Stage结构模型中目标检测的冗余部分会对模型推理时间造成极大影响,MHSA机制虽然能带来强大的数据学习能力,但所需数据量极大,在体育运动繁多、运动场景多样的前提下采集丰富的3D关键点标注数据成本极高,且MHSA模型在部署时对硬件要求高,推理速度较慢。本发明提出的基于重投影的YOLO-Human3D方法能够解决传统模型推理速度慢、数据量要求高的问题,为End to End的3D关键点检测实现体育运动姿态估计提供可行方案。
该目标检测模型在复杂环境中不同运动项目中的实际表现如图3所示。
如图3所示,展示图像为训练集分布外图像(Out OfDistribution,OOD),该结果证明本上游模型在处理OOD任务时仍具有较优表现,且3D Mesh的展示方式能够更加直观展示3D估计的表示,为体育运动的监考、分析等工作提供重要支撑。
虽然以上描述了本发明的具体实施方式,但是熟悉本技术领域的技术人员应当理解,我们所描述的具体的实施例只是说明性的,而不是用于对本发明的范围的限定,熟悉本领域的技术人员在依照本发明的精神所作的等效的修饰以及变化,都应当涵盖在本发明的权利要求所保护的范围内。
- 基于Yolov5目标检测模型改进的目标检测方法、装置和存储介质
- 基于YOLOv5改进的目标检测方法及装置、训练方法