人脸识别优化方法、装置、设备和介质
文献发布时间:2023-06-19 13:45:04
技术领域
本发明涉及视频监控技术领域,具体提供一种人脸识别优化方法、装置、设备和介质。
背景技术
在人脸识别,车辆识别等图像识别场合中,主要使用到的引擎为1:N比对引擎。在具体场景中,直接使用比对引擎,往往不能带来最优的识别效果。具体原因有如下几点:
1、实验室训练环境有限,极限光照的训练数据少,导致引擎部署上线后受到环境影响较大。光线太强导致曝光过度,光照不足导致面部曝光过低,细节丢失。
2、监控场景和比对场景不同,一般相机抓拍点位无法抓拍到正面人脸图,而人脸底库中保存的照片多为正面照片,由此导致在监控场景下,抓拍的侧脸照片和底库中的正面照片进行比对,造成比对结果的数据分布和正面比对结果的数据分布不同,使得使用固定的静态阈值容易产生误识别。
3、为保证比对结果的准确性,静态阈值一般取值偏高,导致牺牲召回率,综合准确率偏低。例如,在大量人员带口罩的情况下抓拍到的照片为戴口罩的照片,而人脸底库中保存的为不戴口罩的注册照,两者之间比对的话,相似度偏低。
由此可见,使用静态阈值无法应对复杂的比对情况。相应地,本领域需要一种新的识别方案来解决上述问题。
发明内容
本发明旨在解决上述技术问题,即,解决现有在人脸识别时使用静态阈值容易造成误识别的问题。
在第一方面,本发明提供一种人脸识别优化方法,主要包括以下步骤:
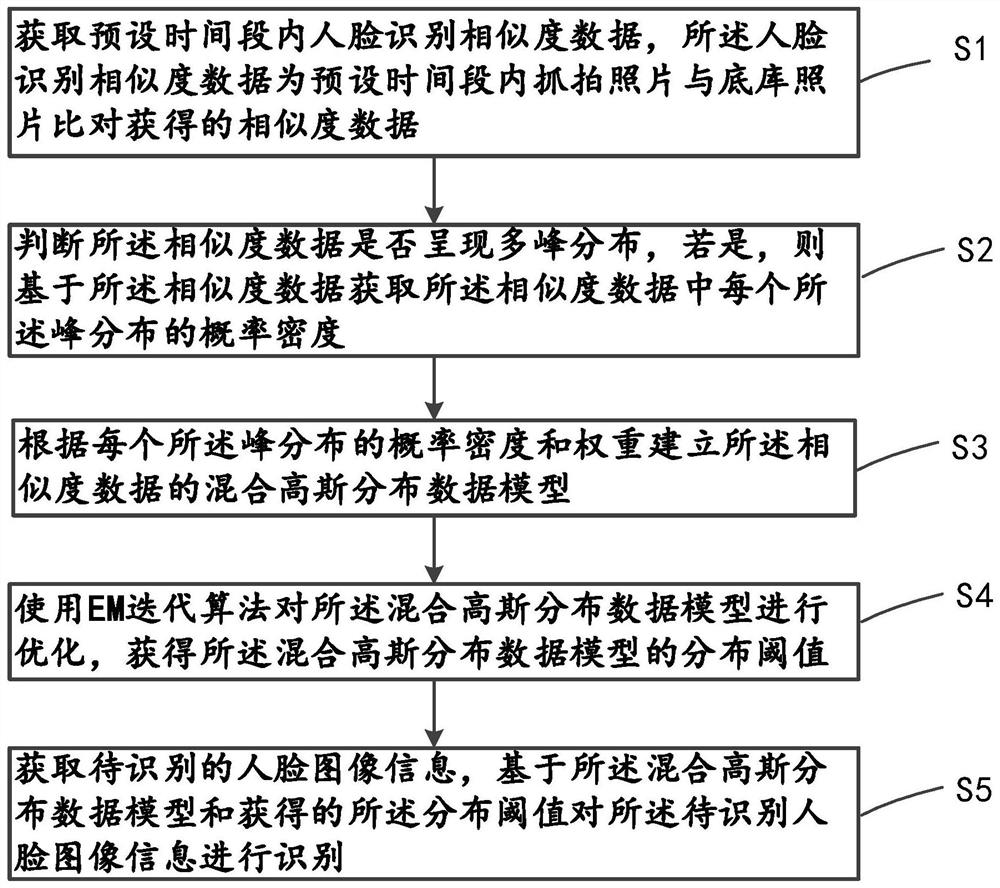
S1、获取预设时间段内人脸识别相似度数据,所述人脸识别相似度数据为预设时间段内抓拍照片与底库照片比对获得的相似度数据;
S2、判断所述相似度数据是否呈现多峰分布,若是,则基于所述相似度数据获取所述相似度数据中每个所述峰分布的概率密度;
S3、根据每个所述峰分布的概率密度和权重建立所述相似度数据的混合高斯分布数据模型;
S4、使用EM迭代算法对所述混合高斯分布数据模型进行优化,获得所述混合高斯分布数据模型的分布阈值;
S5、获取待识别的人脸图像信息,基于所述混合高斯分布数据模型和获得的所述分布阈值对所述待识别人脸图像信息进行识别。
可选地,在步骤S2中,所述多峰分布包括双峰分布。
可选地,在步骤S2中,基于所述相似度数据分别获取所述相似度数据中每个所述峰分布的概率密度包括依据以下公式,获取:
其中,x为人脸识别相似度数值,μ为所述相似度数据的众数,σ为所述相似度数据的标准差,P(x|θ)为所述相似度数据的概率密度。
可选地,在步骤S2中,在基于所述相似度数据获取所述相似度数据中每个所述峰分布的概率密度之前,根据事先设定的相似度静态阈值将所述相似度数据划分为多个数据区域,每个所述数据区域对应不同的所述峰分布。
可选地,在步骤S3之前,分别计算所述多个数据区域中各数据区域内所包含的相似度数据的数量占全部相似度数据总量的比例,并将该比例作为相应数据区域在混合高斯分布数据模型中的权重。
可选地,在步骤S4中,根据各数据区域内相似度数据的概率密度和权重得到每个用户的相似度数据的混合高斯分布数据模型,其中,混合高斯分布数据模型具体为:
其中,N(x|μ
在第二方面,本发明提供一种人脸识别优化装置,主要包括:
数据获取模块,其用于获取预设时间段内人脸识别相似度数据,所述人脸识别相似度数据为预设时间段内抓拍照片与底库照片比对获得的相似度数据;
数据处理模块,其用于判断所述相似度数据是否呈现多峰分布,若是,则基于所述相似度数据获取所述相似度数据中每个所述峰分布的概率密度;
模型生成模块,其用于根据每个所述峰分布的概率密度和权重建立所述相似度数据的混合高斯分布数据模型;
分布阈值获取模块,其用于使用EM迭代算法对所述混合高斯分布数据模型进行优化,获得所述混合高斯分布数据模型的分布阈值;
识别模块,其用于获取待识别的人脸图像信息,基于所述混合高斯分布数据模型和获得的所述分布阈值对所述待识别人脸图像信息进行识别。
可选地,所述数据处理模块,其用于判断所述相似度数据是否呈现双峰分布。
可选地,所述数据处理模块,基于所述相似度数据分别获取所述相似度数据中每个所述峰分布的概率密度包括依据以下公式,获取:
其中,x为人脸识别相似度数值,μ为所述相似度数据的众数,σ为所述相似度数据的标准差,P(x|θ)为所述相似度数据的概率密度。
可选地,所述数据处理模块,在基于所述相似度数据获取所述相似度数据中每个所述峰分布的概率密度之前,根据事先设定的相似度静态阈值将所述相似度数据划分为多个数据区域,每个所述数据区域对应不同的所述峰分布。
可选地,所述模型生成模块,分别计算所述多个数据区域中各数据区域内所包含的相似度数据的数量占全部相似度数据总量的比例,并将该比例作为相应数据区域在混合高斯分布数据模型中的权重。
可选地,所述模型生成模块,根据各数据区域内相似度数据的概率密度和权重得到每个用户的相似度数据的混合高斯分布数据模型,其中,混合高斯分布数据模型具体为:
其中,N(x|μ
在第三方面,本发明提供一种人脸识别优化设备,该设备包括一个或多个处理器,当所述一个或多个处理器执行时,使得所述设备执行本发明第一方面中任一项所述的人脸识别优化方法。
在第四方面,本发明提供一种计算机存储介质,所述存储介质存储有计算机程序,所述计算机程序被执行后能实现本发明第一方面中任一项所述的人脸识别优化方法。
有益技术效果:
在采用上述技术方案的情况下,本发明通过使用混合高斯分布数据模型获取的分布阈值作为人脸识别的动态阈值,相比于单纯使用静态阈值进行人脸识别来说,提升了人脸识别的准确率,相应地降低了误判情况的出现。
附图说明
下面结合附图来描述本发明的优选实施方式,附图中:
图1是本发明人脸识别优化方法实施例的主要步骤流程图;
图2是本发明人脸识别优化方法实施例的比对相似度数据双峰分布示意图;
图3是本发明人脸识别优化方法实施例的动态阈值优化流程示意图;
图4是本发明人脸识别优化装置实施例的结构示意图。
图5是本发明人脸识别优化设备实施例的结构示意图。
具体实施方式
本发明提供一种人脸识别优化方法,如图1所示,主要包括以下步骤:
S1、获取预设时间段内人脸识别相似度数据,所述人脸识别相似度数据为预设时间段内抓拍照片与底库照片比对获得的相似度数据;
S2、判断所述相似度数据是否呈现多峰分布,若是,则基于所述相似度数据获取所述相似度数据中每个所述峰分布的概率密度;
S3、根据每个所述峰分布的概率密度和权重建立所述相似度数据的混合高斯分布数据模型;
S4、使用EM迭代算法对所述混合高斯分布数据模型进行优化,获得所述混合高斯分布数据模型的分布阈值;
S5、获取待识别的人脸图像信息,基于所述混合高斯分布数据模型和获得的所述分布阈值对所述待识别人脸图像信息进行识别。
在本发明的人脸识别优化方法的一个实施例中,所述步骤S1具体为,获取人脸识别相似度数据,所述人脸识别相似度数据为抓拍照片与底库照片比对获得的相似度数据。其中获取的人脸识别相似度数据可以依据实际场景日常产生的人脸识别数据量多少获取某一预设时间段内的人脸识别相似度数据。例如,在某智慧社区场景,收集一个月的视频监控人脸识别比对照片共30万组数据,每组获取的数据中除了包括抓拍照片和与其相似度最高的底库照片外,还包括抓拍照片与底库照片比对获得的相似度数据。从中随机挑选部分数据作为测试集,剩余数据作为训练集。
所述步骤S2具体为,判断所述相似度数据是否呈现多峰分布形态。一般情况下,人脸识别结果中包含识别成功和识别失败两种类别,当采集的人脸识别相似度数据量增大时,在识别相似度数据的分布图上呈现出较为明显的双峰分布。对于更加精细分类的场合,可以根据人脸识别相似度的大小,将其分为多类,比如根据识别结果相似度高、中、低分为三类,按照这样分类的方式,相似度数据可能呈现较为复杂的三峰或多峰结构。实际操作中也可以根据实际需求预设不同的分类标准,从而将识别相似度数据分为多个数据类别,相应地识别相似度的分布呈现多峰分布形态。
对于双峰分布的场景,将组成双峰分布的两个单峰形状的识别相似度数据密度曲线的交点作为两数据密度曲线的最佳分割点,该最佳分割点所对应的相似度数值即为两数据概率密度的分布阈值。根据该最佳分割点对应的分布阈值相比于单纯使用静态阈值进行人脸识别来说,提升了人脸识别的准确率,相应地降低了误判情况的出现。
对于三峰及以上的场景,采取与双峰分布相类似的方法,将多峰中的相邻数据分布转换为多个相邻单峰数据组成的双峰形态的数据分布,采用与双峰分布相同的方法,分别找出多个相邻数据分布间的分割阈值。
下面以双峰分布形态为例进行说明,如图2所示为本发明人脸识别优化方法实施例的比对相似度数据双峰分布示意图。从图2中可以看到,以0.9为分割点,其左侧低分段为人脸识别匹配失败的样本统计结果,其呈现偏态分布,右侧高分段为匹配成功的样本统计结果,其呈现仅为偏态分布的左半部分,两侧数据分布结合形成高斯混合分布的形式。高分段的概率分布与低分段的概率分布的交点处被认为是分割左右两侧数据分布的最佳分割点,该分割点所对应的数值作为人脸识别动态阈值将能更好地保证相应场景中人员的识别结果。需要说明的是,每一个人的人脸识别动态阈值,即每个人的人脸识别相似度高分段与低分段概率分布的交点,不尽相同。部分人的高分段数据较多,说明该用户经常正面被抓拍到,抓拍图像较清晰,和静态阈值相比,需要提高识别相似度的判断阈值,由此可以提高准确率,降低召回率,保证综合F1分数最高。而另一部分人的低分段数据偏多,说明该用户的抓拍照片整体质量较差,需要降低阈值,提升召回率,由此产生了动态的阈值。
一般情况下,可以对获取的相似度数据分布情况采用图像识别的方式判断是否所述人脸识别相似度数据分布呈现为双峰分布。或者通过测试人员人工判断的方式判断是否所述人脸识别相似度数据分布呈现为双峰分布。根据相关的测试经验,当所述人脸识别相似度数据积累达到一定数量后,相似度数据均会呈现为双峰分布的形态。
当人脸识别相似度数据呈现为双峰分布时,根据事先设定的人脸识别相似度静态阈值将所述相似度数据划分为2个数据区域,分别对应于识别成功和识别不成功这两类数据分类。其中,人脸识别相似度大于静态阈值的数据为识别成功的数据,人脸识别相似度小于静态阈值的数据为识别不成功的数据。
在上述两种数据分类中,分别基于所述相似度数据获取所述相似度数据的概率密度。其概率密度具体为,
其中,x为人脸识别相似度数值,μ为人脸识别相似度数据的众数,σ为人脸识别相似度数据的标准差,P(x|θ)为所述人脸识别相似度数据的概率密度。
具体来说,人脸识别相似度小于静态阈值的数据部分,即识别不成功数据的概率密度可设定为:
人脸识别相似度大于静态阈值的数据部分,即识别成功数据的概率密度可设定为:
所述步骤S3具体为,根据上述各数据区域内相似度数据的概率密度和权重建立相似度数据的混合高斯分布数据模型。混合高斯分布数据模型指的是多个高斯分布函数的线性组合,理论上该模型可以拟合出任意类型的分布,通常用于解决同一集合下的数据包含多个不同的分布的情况。
具体来说,本发明采用的混合高斯分布数据模型如下所示:
其中,N(x|μ
具体来说,在本发明中,π
另外,该公式中的N(x|μ
所述步骤S4具体为,使用EM迭代算法对所述混合高斯分布数据模型进行优化,获得所述混合高斯分布数据模型的分界点。
首先,使用EM算法对所述混合高斯模型进行迭代求解。EM算法可以用于解决数据缺失的参数估计问题,隐参数的存在实际上就是数据缺失问题。缺失了各个样本来源于哪一类的记录。通过使用迭代逼近的方法,来对高斯混合模型进行迭代处理。EM算法中包含了隐参数,每次迭代,先使用上一次的参数计算隐参数的大小,通过迭代的过程来找到一组最优的参数。对于本发明来说,所述使用EM算法对所述混合高斯模型迭代后得到的一组最优隐参数,具体为人脸识别相似度的众数、标准差以及左右分布的概率。使用最优隐参数表示的混合高斯分布数据模型最有可能产生现有的采样数据。每次迭代的过程也是参数优化修正的过程。
其中,判断EM算法迭代时可以通过设定相应的迭代参数作为迭代结束的条件。例如,可以设置最大迭代次数,当迭代次数大于最大迭代次数时,则结束迭代。也可以通过设定一个最小差值,判断本次迭代后获得的参数值(众数、标准差、概率密度)与上一次迭代结果得到的参数值之间是否小于预设的最小差值,当前后两次迭代结果得到的参数值之间小于预设的最小差值时,则结束迭代。
其次,通过多次迭代后得到最优的众数和标准差后,将其分别带入左右分布的概率密度公式中,得到EM算法迭代优化后的低分段相似度数据分布的概率密度公式和高分段相似度数据分布的概率密度公式。
最后,通过获得的低分段相似度数据分布的概率密度公式和高分段相似度数据分布的概率密度公式,计算得出两个概率密度公式相同的x值,即通过计算下述公式中的人脸识别相似度数值,
P(x
由以上公式求解得到两个概率密度公式中相同的人脸识别相似度数值,即x1=x2时的相似度数值,将该相似度数值作为该用户人脸识别的动态阈值。该相似度数值也是左右两个概率密度分布的交点,也称为两概率密度分布的最佳分割点。
所述步骤S5具体为,基于所述混合高斯分布数据模型和获得的所述分界点对待识别人脸图像进行识别。也就是将混合高斯分布数据模型中某用户人脸识别相似度高分段与低分段两部分概率分布的分界点作为该用户人脸识别相似度的阈值对待识别人脸图像进行识别。如果识别后的相似度数值高于阈值,则表示识别成功,反之,则表示识别失败。
在步骤S5中,还包括,服务器周期性地获取每个用户新增的人脸识别相似度数据,并基于新获取的相似度数据和混合高斯分布数据模型对每个用户的人脸识别动态阈值进行修正优化,获取修正优化后的人脸识别动态阈值。如图3所示,保存通过1:N引擎得到的人脸识别比对结果到服务器的数据库中。服务器分析每个人的人脸识别相似度数据的数据分布是否符合双峰分布的形式,对于相似度数据符合双峰分布的用户,使用EM算法求解静态阈值两侧相似度数据分布的交点,将交点作为该用户人脸识别的动态阈值。保存每个人的人脸识别动态阈值到数据库中。服务器根据获取的人脸识别动态阈值,周期性地将设置中保存的用于人脸识别阈值更新为最新获取的人脸识别动态阈值。
对于所述混合高斯分布数据模型的性能可以使用混淆矩阵来评估。具体来说,混淆矩阵是一个误差矩阵。混淆矩阵一般为(n_classes,n_classes)的方阵,其中n_classes表示类的数量。
混淆矩阵的每一行表示真实类中的实例,也可以是,每一行表示预测类中的实例。
而每一列表示真实类中的实例。
通过混淆矩阵,可以很容易看出系统是否会弄混两个类。
用到的指标包括准确率(precision)、召回率(recall)和F1值(F1score),并通过混淆矩阵来辅助计算这些值。其中,
精确率:为被分类器判定正例中的正样本的比重;
召回率:为被预测为正例的占总的正例的比重;
F1score:为2·精确率·召回率/(精确率+召回率)。
对于一个分类器的预测结果,可以画出这样一个混淆矩阵:表格每一行表示预测的类别,每一列表示真实的类别。在二分类任务中,混淆矩阵如下所示:
其中label是数据的标注标签,predict是模型的预测结果。为了计算precision、recall和F1,这里引入了4个概念:
TP:True Positive,表示label=1且predict=1
FP:False Positive,表示label=0且predict=1
FN:False Negative,表示label=1且predict=0
TN:True Negative,表示label=0且predict=0
True/False表示预测结果和标注标签是否一致,
Positive/Negative表示预测结果是1还是0。
得到混淆矩阵后,计算precision、recall和F1值只需要代入公式:
precision=TP/(TP+FP)
recall=TP/(TP+FN)
在得到准确率和召回率后,根据下述公式求解可以得到F1score:
其中,F1score是精确率和召回率的调和平均数,该调和平均数最大为1,最小为0。越靠近1,表示精确率和召回率的综合表现更优。
例如,通过对10人,1000次人脸识别比对照片进行人工打标,其中正样本500个,负样本500个,经过模型训练后,产生所述10人的比对阈值。
根据比对阈值把比对样本分为预测正样本和预测负样本,其中
真实值为1,预测值为1的TP类型数量为489个,
真实值为0,预测值为1的FP类型数量为24个,
真实值为1,预测值为0的FN类型数量为11个,
真实值为0,预测值为0的TN类型数量为476。
由此,可以得到,
precision=489/(489+24)=0.9532
recall=489/(489+11)=0.978
F1score=2*0.9532*0.978/(0.9532+0.978)=0.9654
在第二方面,本发明提供一种人脸识别优化装置,如图4所示,本实施例的人脸识别优化装置主要包括:
数据获取模块,其用于获取预设时间段内人脸识别相似度数据,所述人脸识别相似度数据为预设时间段内抓拍照片与底库照片比对获得的相似度数据;
数据处理模块,其用于判断所述相似度数据是否呈现多峰分布,若是,则基于所述相似度数据获取所述相似度数据中每个所述峰分布的概率密度;
模型生成模块,其用于根据每个所述峰分布的概率密度和权重建立所述相似度数据的混合高斯分布数据模型;
分布阈值获取模块,其用于使用EM迭代算法对所述混合高斯分布数据模型进行优化,获得所述混合高斯分布数据模型的分布阈值;
识别模块,其用于获取待识别的人脸图像信息,基于所述混合高斯分布数据模型和获得的所述分布阈值对所述待识别人脸图像信息进行识别。
本实施例提供的人脸识别优化装置,可用于执行上述第一方面所提供的人脸识别优化方法。具体实现方法和技术效果与第一方面所述类似,这里不再赘述。
在第三方面,本发明提供一种人脸识别优化设备,如图5所示,本实施例的人脸识别优化设备400主要包括:处理器41、存储器42、接收器43。
其中,处理器41、存储器42、接收器43通过总线实现彼此连接,相互通信。具体来说,
处理器41,其用于执行本发明提供的人脸识别优化方法;
存储器42,其用于储存执行指令,当人脸识别优化设备400运行时,处理器41与存储器42之间通信,处理器41执行存储器42中储存的执行指令,使得人脸识别优化设备400执行本发明第一方面中任一项所述的人脸识别优化方法;
接收器43,其用于接收人脸识别相似度数据。
在第四方面,本发明提供一种计算机存储介质,所述存储介质存储有计算机程序,所述计算机程序被执行后能实现本发明的第一方面中任一项所述的人脸识别优化方法。
至此,已经结合附图所示的优选实施方式描述了本发明的技术方案,但是,本领域技术人员容易理解的是,本发明的保护范围显然不局限于这些具体实施方式。在不偏离本发明的原理的前提下,本领域技术人员可以对相关技术特征作出等同的更改或替换,这些更改或替换之后的技术方案都将落入本发明的保护范围之内。