一种基于分析Http请求的网络爬虫快速识别装置
文献发布时间:2023-06-19 13:45:04
技术领域
本发明涉及信息技术领域。
背景技术
很多在线交易网站在互联网提供查询、预订、下单等服务,例如:携程、12306、淘宝、京东等官网有大量正常用户访问的同时,也存在大量爬虫。爬虫消耗了系统资源,但是却没有转化成销量,导致系统资源虚耗,严重时会造成系统波动,影响正常用户访问。通过系统日志分析等,发现官网访问中存在大量爬虫,且通过大量的 IP 进行伪装。
大量热门、特价商品吸引正常用户访问官网的同时,也存在大量恶意占座的非法代理。通过不断的下单但不支付,利用这些虚占的进行非法盈利,通过系统日志分析等,发现官网存在大量的非法占座会员及非会员手机号用户。
为了限制伪装技术越来越强的爬虫访问和恶意占座行为,需要开发大数据防爬工具,反爬虫的工具必须具有时效性,所以选择的开发底层框架必须要支持流式计算。
传统的网络爬虫识别技术是通过对系统日志的分析达成,属于事后发现,本发明的优势是利用流计算技术实时发现网络爬虫进行封堵。
现有技术
Spark是一种基于内存技术,具有快速、通用、可扩展特性,支持流式计算的大数据计算引擎。Spark Streaming是Spark平台上针对实时数据进行流式计算的组件,提供丰富的,易操作的流式处理API。由于单台计算处理速度有限,通过搭建Spark集群,并且配置Zookeeper集群,使Master节点高可用,当Master节点出现故障,由备用Master节点提供服务,保证作业可用继续执行。
页面埋点
用户行为分析是一个大系统,一个典型的数据平台。由用户数据采集,用户行为建模分析,可视化报表展示几个模块构成。现有的埋点采集方案可以大致被分为三种,手动埋点,可视化埋点,无埋点。
手动代码埋点比较常见,需要调用埋点的业务方在需要采集数据的地方调用埋点的方法。优点是流量可控,业务方可以根据需要在任意地点任意场景进行数据采集,采集信息也完全由业务方来控制。这样的有点也带来了一些弊端,需要业务方来写死方法,如果采集方案变了,业务方也需要重新修改代码,重新发布。
可是化埋点是近今年的埋点趋势,很多大厂自己的数据埋点部门也都开始做这块。优点是业务方工作量少,缺点则是技术上推广和实现起来有点难。阿里的活动页很多都是运营通过可视化的界面拖拽配置实现,这些活动控件元素都带有唯一标识。通过埋点配置后台,将元素与要采集事件关联起来,可以自动生成埋点代码嵌入到页面中。
无埋点则是前端自动采集全部事件,上报埋点数据,由后端来过滤和计算出有用的数据,优点是前端只要加载埋点脚本。缺点是流量和采集的数据过于庞大,服务器性能压力山大,主流的 GrowingIO 就是这种实现方案。
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。
发明内容
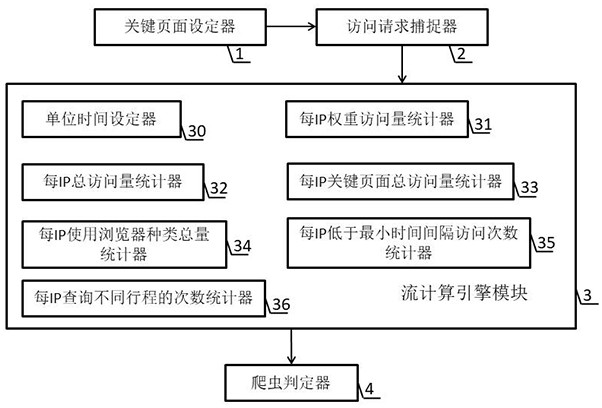
鉴于现有技术的不足,本发明提供的一种基于分析Http请求的网络爬虫快速识别装置由关键页面设定器、访问请求捕捉器、流计算引擎模块和爬虫判定器组成;流计算引擎模块由单位时间设定器、每IP权重访问量统计器、每IP总访问量统计器、每IP关键页面总访问量统计器、每IP使用浏览器种类总量统计器、每IP低于最小时间间隔访问次数统计器和每IP查询不同行程的次数统计器组成;
关键页面设定器负责标记网站的关键页面,并在关键页面根据活动控件元素带有唯一标识的特点进行自动埋点,埋点的过程是在关键页面的活动控件元素处添加引用采集脚本的script 脚本来实现;
访问请求捕捉器用来生成采集脚本,采集脚本用来采集http请求,并且将http请求数据传送目标设定为访问请求捕捉器;访问请求捕捉器解析http请求,得到该http请求的请求时间,URL地址,请求参数,源IP,访问用的浏览器种类;访问请求捕捉器把解析http请求得到的数据封装成一个字符串,通过Kafka发送给流计算引擎模块;
流计算引擎模块由Spark对数据进行流式处理;由流式处理API编辑构成单位时间设定器、每IP权重访问量统计器、每IP总访问量统计器、每IP关键页面总访问量统计器、每IP使用浏览器种类总量统计器、每IP低于最小时间间隔访问次数统计器和每IP查询不同行程的次数统计器;
单位时间设定器设定进行网络爬虫快速识别时所采用的时间段的长度,命名为单位时间,默认的单位时间为1分钟;
每IP权重访问量统计器用来列举单位时间一个源IP访问不同目的的访问量,并将一个源IP访问不同目的的访问量中的前两位访问量相加,得到每IP权重访问量;每IP权重访问量统计器设定每IP权重访问量的阈值为100,权重为0.2;当每IP权重访问量大于阈值时,每IP权重访问量统计器将每IP权重访问量乘以0.2发送给爬虫判定器;
每IP总访问量统计器用来统计单位时间一个源IP所有的访问量之和,得到每IP总访问量;每IP总访问量统计器设定每IP总访问量的阈值为80,权重为0.2;当每IP总访问量大于阈值时,每IP总访问量统计器将每IP总访问量乘以0.2发送给爬虫判定器;
每IP关键页面总访问量统计器用来统计单位时间一个源IP访问所有关键页面的访问量之和,得到每IP关键页面总访问量;每IP关键页面总访问量统计器设定每IP关键页面总访问量的阈值为50,权重为0.2;当每IP关键页面总访问量大于阈值时,每IP关键页面总访问量统计器将每IP关键页面总访问量乘以0.2发送给爬虫判定器;
每IP使用浏览器种类总量统计器用来统计单位时间一个源IP使用的浏览器种类,得到每IP使用浏览器种类总量;每IP使用浏览器种类总量统计器设定每IP使用浏览器种类总量的阈值为3,权重为0.1;当每IP使用浏览器种类总量大于阈值时,每IP使用浏览器种类总量统计器将每IP使用浏览器种类总量乘以0.1发送给爬虫判定器;
每IP低于最小时间间隔访问次数统计器设定最小时间间隔为3秒,每IP低于最小时间间隔访问次数统计器用来统计单位时间同一源IP对外发起http请求的间隔时间小于最小时间间隔的所有http请求,得到每IP低于最小时间间隔访问次数;每IP低于最小时间间隔访问次数统计器设定每IP低于最小时间间隔访问次数的阈值为25,权重为0.2;当每IP低于最小时间间隔访问次数大于阈值时,每IP低于最小时间间隔访问次数统计器将每IP低于最小时间间隔访问次数乘以0.2发送给爬虫判定器;
每IP查询不同行程的次数统计器用来统计单位时间一个源IP 进行不同行程查询的总次数,得到每IP查询不同行程的次数;每IP查询不同行程的次数对于没有行程规划的网站没有意义;每IP查询不同行程的次数统计器设定每IP查询不同行程的次数的阈值为12,权重为0.1;当每IP查询不同行程的次数大于阈值时,每IP查询不同行程的次数统计器将每IP查询不同行程的次数乘以0.1发送给爬虫判定器;
爬虫判定器根据综合评分决定源IP是否为爬虫所在IP,当综合评分大于0.6则判定源IP为爬虫所在IP;综合评分=将每IP权重访问量乘以0.2+每IP总访问量乘以0.2+每IP关键页面总访问量乘以0.2+每IP使用浏览器种类总量乘以0.1+每IP低于最小时间间隔访问次数乘以0.2+每IP查询不同行程的次数乘以0.1。
有益效果
本发明可以实时判断网络爬虫,有助于实时采取阻断措施。
附图说明
图1是本发明的系统结构图。
具体实施方式
实施例一
参看图1,本发明提供的一种基于分析Http请求的网络爬虫快速识别装置由关键页面设定器1、访问请求捕捉器2、流计算引擎模块3和爬虫判定器4组成;流计算引擎模块3由单位时间设定器30、每IP权重访问量统计器31、每IP总访问量统计器32、每IP关键页面总访问量统计器33、每IP使用浏览器种类总量统计器34、每IP低于最小时间间隔访问次数统计器35和每IP查询不同行程的次数统计器36组成;
关键页面设定器1负责标记网站的关键页面,并在关键页面根据活动控件元素带有唯一标识的特点进行自动埋点,埋点的过程是在关键页面的活动控件元素处添加引用采集脚本的script 脚本来实现;
访问请求捕捉器2用来生成采集脚本,采集脚本用来采集http请求,并且将http请求数据传送目标设定为访问请求捕捉器2;访问请求捕捉器2解析http请求,得到该http请求的请求时间,URL地址,请求参数,源IP,访问用的浏览器种类;访问请求捕捉器把解析http请求得到的数据封装成一个字符串,通过Kafka发送给流计算引擎模块3;
流计算引擎模块3由Spark对数据进行流式处理;由流式处理API编辑构成单位时间设定器30、每IP权重访问量统计器31、每IP总访问量统计器32、每IP关键页面总访问量统计器33、每IP使用浏览器种类总量统计器34、每IP低于最小时间间隔访问次数统计器35和每IP查询不同行程的次数统计器36;
单位时间设定器30设定进行网络爬虫快速识别时所采用的时间段的长度,命名为单位时间,默认的单位时间为1分钟;
每IP权重访问量统计器31用来列举单位时间一个源IP访问不同目的的访问量,并将一个源IP访问不同目的的访问量中的前两位访问量相加,得到每IP权重访问量;每IP权重访问量统计器31设定每IP权重访问量的阈值为100,权重为0.2;当每IP权重访问量大于阈值时,每IP权重访问量统计器31将每IP权重访问量乘以0.2发送给爬虫判定器;
每IP总访问量统计器32用来统计单位时间一个源IP所有的访问量之和,得到每IP总访问量;每IP总访问量统计器32设定每IP总访问量的阈值为80,权重为0.2;当每IP总访问量大于阈值时,每IP总访问量统计器32将每IP总访问量乘以0.2发送给爬虫判定器;
每IP关键页面总访问量统计器33用来统计单位时间一个源IP访问所有关键页面的访问量之和,得到每IP关键页面总访问量;每IP关键页面总访问量统计器33设定每IP关键页面总访问量的阈值为50,权重为0.2;当每IP关键页面总访问量大于阈值时,每IP关键页面总访问量统计器33将每IP关键页面总访问量乘以0.2发送给爬虫判定器;
每IP使用浏览器种类总量统计器34用来统计单位时间一个源IP使用的浏览器种类,得到每IP使用浏览器种类总量;每IP使用浏览器种类总量统计器34设定每IP使用浏览器种类总量的阈值为3,权重为0.1;当每IP使用浏览器种类总量大于阈值时,每IP使用浏览器种类总量统计器34将每IP使用浏览器种类总量乘以0.1发送给爬虫判定器;
每IP低于最小时间间隔访问次数统计器35设定最小时间间隔为3秒,每IP低于最小时间间隔访问次数统计器35用来统计单位时间同一源IP对外发起http请求的间隔时间小于最小时间间隔的所有http请求,得到每IP低于最小时间间隔访问次数;每IP低于最小时间间隔访问次数统计器35设定每IP低于最小时间间隔访问次数的阈值为25,权重为0.2;当每IP低于最小时间间隔访问次数大于阈值时,每IP低于最小时间间隔访问次数统计器将每IP低于最小时间间隔访问次数乘以0.2发送给爬虫判定器;
每IP查询不同行程的次数统计器36用来统计单位时间一个源IP 进行不同行程查询的总次数,得到每IP查询不同行程的次数;每IP查询不同行程的次数对于没有行程规划的网站没有意义;每IP查询不同行程的次数统计器36设定每IP查询不同行程的次数的阈值为12,权重为0.1;当每IP查询不同行程的次数大于阈值时,每IP查询不同行程的次数统计器36将每IP查询不同行程的次数乘以0.1发送给爬虫判定器;
爬虫判定器4根据综合评分决定源IP是否为爬虫所在IP,当综合评分大于0.6则判定源IP为爬虫所在IP;综合评分=将每IP权重访问量乘以0.2+每IP总访问量乘以0.2+每IP关键页面总访问量乘以0.2+每IP使用浏览器种类总量乘以0.1+每IP低于最小时间间隔访问次数乘以0.2+每IP查询不同行程的次数乘以0.1。