一种基于租车网站评论的情感分析可视化的方法及设备
文献发布时间:2023-06-19 18:37:28
技术领域
本发明涉及计算机技术领域,具体涉及一种基于租车网站评论的情感分析可视化的方法及设备。
背景技术
随着人工智能和5G时代的快速发展,运用人工智能技术进行数据分析成为了一个重要的应用方向。在这个快节奏的社会里,人们更喜欢看图片,图表等快速准确地获取有用的信息而不再喜欢看大篇幅的文字。因此,本发明提出一种方法和运用,从租车网站中大量用户的评论中提取有用评论并将它们以图表形式展示给用户。
在目前主流的租车网站中,并没有找到可以对租车点和汽车进行评论的模块。这种情况会让用户在选择汽车时产生过多的纠结和犹豫,也会担心租的汽车是否适合该用户驾驶。因此,提供用户进行评论的功能以及将评论以图表形式可视化将会让用户更安心地去租用自己心仪的汽车。
发明内容
本发明的目的在于提供一种基于租车网站评论的情感分析可视化的方法及设备,以期解决背景技术中存在的问题。
为了实现上述目的,本发明采用以下技术方案:
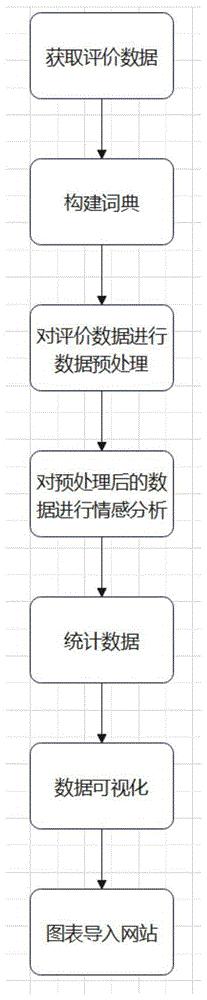
一种基于租车网站评论的情感分析可视化的方法,包括以下步骤:
获取评价数据;
构建词典;
对评价数据进行数据预处理;
对预处理后的文本数据进行情感分析;
统计维度词和有情感的评价词的数量;
将统计完毕后的数据导入可视化软件进行数据可视化;
将可视化数据通过接口导入网站。
在一些实施例中,所述获取评价数据,包括:获取初始汽车评论信息以及系统采集用户租车完成后对租车点和租用车型的评论。
随着网站的运行,用户的评论增多,不断扩充数据集。
数据集数据来源包括但不限于懂车帝,汽车之家等与汽车有关的网站。
在一些实施例中,所述构建词典包括,基于获取评价数据构建情感词词典和维度词词典。
在一些实施例中,所述对评价数据进行数据预处理包括,去除重复评论,使用结巴分词,以及去除停用词。
在一些实施例中,所述对预处理后的文本数据进行情感分析包括,对文本数据使用Bert预训练和深度学习模型进行情感分析。
在一些实施例中,进行情感分析的方法为:
将数据集分为训练集和测试集,并进行Bert预训练获得相应的词向量,再与维度词词典的词ID构建矩阵;
使用深度神经网络Bi-LSTM模型对数据进行训练和测试。
情感分析可视化的方法包括但不限于Bert预训练+深度学习模型。
在一些实施例中,使用深度神经网络Bi-LSTM模型对数据进行训练和测试,包括:设定Bert词向量维度768,LSTM维度为384,LSTM-layers为3,dropout为0.5,选择双向循环;模型后面用SoftMax函数和交叉熵损失函数得出评论数据的极性;数据的极性分为-1,0,1,分别代表差评,中评,好评三种类型的评论数据。
在一些实施例中,所述统计维度词和有情感的评价词的数量包括,统计每个维度词相对应的好评,中评以及差评。
在一些实施例中,所述将统计完毕后的数据导入可视化软件进行数据可视化包括,将统计后的数据进行整理,按照维度词进行切片,最终通过可视化软件进行数据可视化。
可视化软件包括但不限于Tableau。
本申请还提供了一种基于租车网站评论的情感分析可视化的设备,包括:
信息交互模块,用于与网站进行交互,接收网站的用户评论数据,输入到数据采集模块,然后获取从数据可视化模块返回的结果,并将结果作为答案输出到网站页面上;
数据采集模块,用于采集任务相关的数据;
检索库模块,用于构建情感词词典和维度词词典;
数据预处理模块,用于对评论数据进行数据清洗;
情感分析模块,用于对评论数据进行情感分析,得出评论是否为好评,中评或者差评;
数据统计模块,用于统计各维度词的好评,中评,差评的数量;
数据可视化模块,用于将数据统计模块的数据以图表形式展现。
本申请所提供的一种基于租车网站评论的情感分析可视化的方法具有的有益效果包括但不限于:
经过评论数量的积累后,用户可以通过查看数据图表方便,快捷地了解每辆车和租车点的评论,然后选择自己心仪的汽车租用。这个自然语言处理运用可以增加用户对租车体验的满意度,同时也能让租车点对自己的服务进行优化。
附图说明
图1为本基于租车网站评论的情感分析可视化的方法的流程图;
图2为基于租车网站评论的情感分析可视化的装置结构框图。
具体实施方式
为了使本申请的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本申请进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本申请,并不用于限定本申请。
相反,本申请涵盖任何由权利要求定义的在本申请的精髓和范围上做的替代、修改、等效方法以及方案。进一步,为了使公众对本申请有更好的了解,在下文对本申请的细节描述中,详尽描述了一些特定的细节部分。对本领域技术人员来说没有这些细节部分的描述也可以完全理解本申请。
以下将结合图1-2对本申请实施例所涉及的一种基于租车网站评论的情感分析可视化的方法进行详细说明。值得注意的是,以下实施例仅仅用于解释本申请,并不构成对本申请的限定。
本发明的目的在于在租车网站上收集用户评论并可视化展示出来,这种基于租车网站评论的情感分析可视化的方法的主要难点在于目前还没有用户对租用的汽车和该租车点的评论,在使用初期能利用的数据较少,以及初期做出的评论会有一定的误差。
本发明将在其他汽车网站上获取对每个车型相应的评论,尽可能在本发明使用初期能用显示较为准确的评论。之后随着用户租用汽车的数量增多,网站收集的评论随之增加,会逐渐地对评论的图表进行优化。用户也会对网站显示的图表更加信赖。主要包括以下步骤:
如图1-2所示,一种基于租车网站评论的情感分析可视化的方法,具体包括以下几个步骤:
步骤s1:在汽车网站获取初始汽车评论信息以及系统采集用户租车完成后对租车点和租用车型的评论;
步骤s2:建立情感词词典以及维度词词典;
步骤s3:对初始数据进行数据预处理;
步骤s4:对预处理后的文本数据进行情感分析;
步骤s5:统计维度词和有情感的评价词的数量;
步骤s6:将统计完毕后的数据导入可视化软件进行数据可视化;
步骤s7:将可视化数据通过接口导入网站;
进一步的所述步骤s1的步骤包括:
步骤s11:通过网络爬虫,协商,购买等方式从汽车信息网站(例如懂车帝等主流网站)获取该网站用户对各种车型的评论作为本发明的初始数据;
步骤s12:将各网站的初始数据合并,并且人工标注,将好评标注为1,中评标注为0,差评标注为-1,然后存放为txt文件形式,并将数据保存为UTF-8格式;
进一步的所述步骤s2的步骤包括:
步骤s21:所述建立的维度词词典,包括汽车名称以及租车点名称,具体如“大众朗逸”,“世纪城蜀都中心服务点”,并为汽车和租车点创建ID;
进一步的所述步骤s3的步骤包括:
步骤s31:去除重复评论信息。利用pandas库的dataframe方法统计重复评论内容并删除;
步骤s32:采用的结巴分词方法为python的结巴分词方法。对去除重复数据后的评论进行分词;
步骤s33:基于结巴分词方法,可根据情感词词典,新增自定义结巴分词表,具体如,“省油”,“省心”,“开着很飘”等词汇或短语;
步骤s34:去除停用词。读取所有停用词,存到stop_words列表中,并以换行符切分。通过双重循环去除评论中的停用词;
进一步的所述步骤s4的步骤包括:
步骤s41:将预处理完成后的数据打乱顺序,并按数量比7:3的比例分为训练集和测试集。根据训练样本训练一个情感分类模型。以下述模型为例,首先将分词后的句子转换为输入向量,然后将输入向量输入到模型中,模型第一层为嵌入层(Embedding),采用Bert预训练模型对每个数据预处理后的长文本评论数据的单个词转换为词向量(Wordembedding);
步骤s42:通过Bert预训练模型后,借助TorchText建立vocabulary,把每个词语映射到数字ID。首先创建两个Field对象,这两个对象包含预处理的文本数据的信息,分别为TEXT和LABEL。接着,使用TabularDataset方法生成数据集,存放为CSV形式的文件。
步骤s43:构建词嵌入矩阵。根据维度词词典的ID和实体名称,将Bert预训练模型的词向量和维度词词典的词id进行一一对应并构建矩阵,比如“大众朗逸”的词id为10,在构建的矩阵中,第十行对应的就是“大众朗逸”的词向量。整个矩阵的大小为2000*768,代表通过建立此表一共存在2000个词id,每个词向量的维度为768。
步骤s44:创建iterator,每个iteration返回一个batch的样本,设置训练集和测试集的batch size为64。
步骤s45:搭建深度神经网络,采用Bi-LSTM模型,并设定LSTM维度为384,LSTM-layers为3,dropout为0.5,选择双向循环。利用Bi-LSTM对训练集进行训练,对测试集进行测试。
步骤s46:并用SoftMax函数和交叉熵损失函数得出较精确的极性;
步骤s47:所述数据极性分为-1,0,1,分别代表差评,中评,好评三种类型的评论数据;
进一步的所述步骤s5的步骤包括:
步骤s51:对差评,中性,好评三种类型对维度词的评论数据数量进行统计;具体如,大众朗逸:好评2000条;中评:200条;差评:10条;
步骤s52:对差评,中性,好评的评论中维度词及情感词进行统计;具体如,世纪城蜀都中心服务点:服务态度极好(50次),非常满意(26次);
进一步的所述步骤s6的步骤包括:
步骤s61:将统计好的数据存放为Excel文件形式;
步骤s62:将Excel数据导入Tableau软件进行可视化;
实施例二:
本发明实施例提供的另一种基于租车网站评论的情感分析可视化的设备,包括:
信息交互模块,用于与网站进行交互,接收网站的用户评论数据,输入到数据采集模块,然后获取从数据可视化模块返回的结果,并将结果作为答案输出到网站页面上;
数据采集模块,用于采集任务相关的数据;
检索库模块,用于构建情感词词典和维度词词典;
数据预处理模块,用于对评论数据进行数据清洗;
情感分析模块,用于对评论数据进行情感分析,得出评论是否为好评,中评或者差评;
数据统计模块,用于统计各维度词的好评,中评,差评的数量;
数据可视化模块,用于将数据统计模块的数据以图表形式展现;
通过本发明实施例二提供的基于租车网站评论的情感分析可视化的设备,采用Bert预训练模型能够最大程度的精确获得词向量,再通过Bi-LSTM模型高效快速的分析评论数据的极性。
本领域普通技术人员可以理解,实现上述实施例方法中的全部或部分流程是可以通过程序来指令相关的硬件来完成,所述的程序可以存储于计算机可读取存储介质中,该程序在执行时,可包括如上各方法的实施例的流程。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。