定点医药机构ERP药品与国家医保目录智能全量对码的方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及定点医药机构ERP药品与国家医保目录对码技术领域,具体为定点医药机构ERP药品与国家医保目录智能全量对码的方法。
背景技术
当前定点医药机构使用的ERP软件和国家医保目录对码中存在以下几点不足和缺陷:
1:医药行业有上百个ERP软件,都未引入药品的智能全量对码方法。
2:部分ERP软件基于药品的通用名称、批准文号、条形码、规格相等的办法进行对码,对码的成功率依赖于药品资料建立的规范性,不符合大部分定点医药机构药品资料建立不规范的实际情况,对码的成功率不高。
3:判断药品属性相等进行对码的方法无法完全判定就是同一种药品,因为还存在规格,剂型,生产厂家等差异。
4:规格存在书写顺序及计算方式的差异。
5:全量对码工作需要定点医药机构投入较多人力。
6:人工对码存在一定的错误,影响国家医保结算数据准确性,也给国家医保造成资金损失。
为解决以上问题,本发明提出了一种定点医药机构ERP药品与国家医保目录智能全量对码的方法。
发明内容
为实现上述目的,本发明提供如下技术方案:定点医药机构ERP药品与国家医保目录智能全量对码的方法,包括用户端和服务端,所述用户端和服务端之间通过网络进行信息交换;
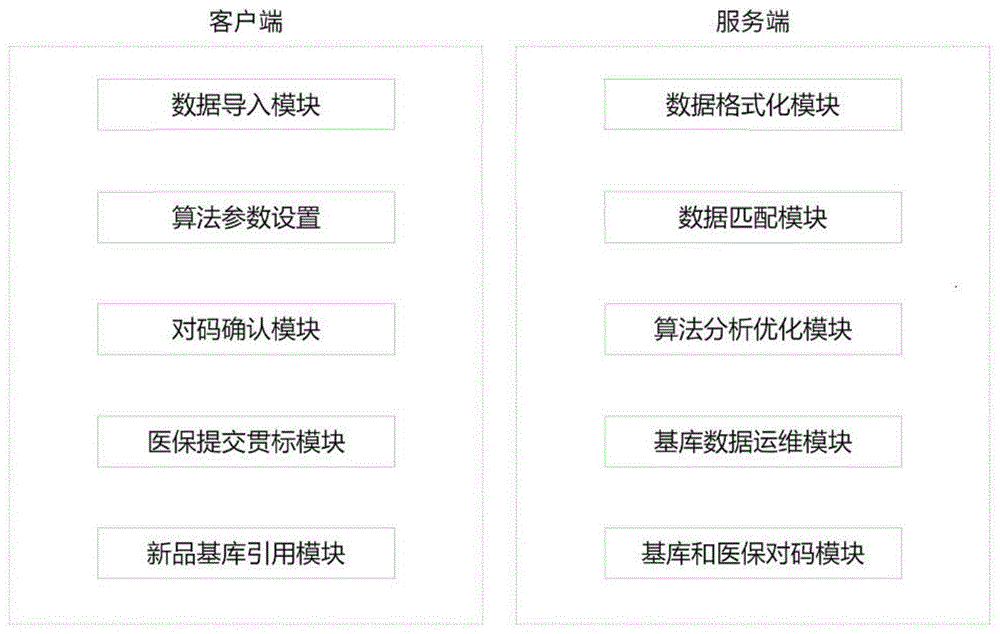
所述用户端包括数据导入模块、算法参数设置模块、对码确认模块、医保提交贯标模块、新品基库引用模块;
其中,所述数据导入模块用于药品资料的导入,所述药品资料包括:药品名称、含量、包装、重量、尺寸、单位不中的任意一种或多种,所述算法参数设置模块用于手动调整药品分值参数,所述对码确认模块用于接收药品数据处理后的结果,并在用户端进行验证确认,医保提交贯标模块用于将验证后的数据提交至国家医保局,新品基库引用模块用于调取引用基库内的新药品资料;
所述服务端包括数据格式化模块、数据匹配模块、算法分析优化模块、基库数据运维模块、基库和医保对码模块;
其中,所述数据格式化模块用于将导入的数据分解格式化,便于数据代入算法进行分析,所述数据匹配模块用于将用户端发送的药品资料与国家医保目录进行匹配,算法分析优化模块用于将药品的资料数据进行算法分析,基库数据运维模块用于基库内的数据的运行和维护,所述基库和医保对码模块用于基库内药品资料与医保目录对码。
优选的,所述药品资料记录形式为条形码,所述读取药品资料所用设备为扫描器。
优选的,主要包括以下步骤:
S1:首先,定点医药机构使用读取设备采集药品资料,并在用户端将药品资料导入,并按药品设定分值;
S2:接着,用户端收录导入的药品资料,将药品资料发送至服务端以进行对码确认申请;
S3:然后,服务端接收药品资料,并针对不同的商品属性,进行语义分析后拆解数据,分解为含量、包装、重量、尺寸、单位的不同维度;
S4:然后,对拆解后的数据进行单位换算,统一计量,并根据批准文号、条形码的属性规范,剔除无效的属性;
S5:然后,用文本相似度给商品名称、生产厂家打分,对不同要素授予不同的分值权重;
S6:然后,根据正则算法对数据进行清洗分析,对核心关键字做排除处理,进而将用户端的药品数据与服务端的数据进行匹配;
S7:最后,服务端将匹配结果进行分类,并反馈给定点医药机构进行验证和确认。
S8:定点医疗机构对数据验证后,医保提交贯标模块将医保数据全量给国家医保局上报,完成贯标对码工作。
与现有技术相比,本发明的有益效果是:
1、本发明采用一整套正则算法进行数据清洗,并对药品数据进行拆解再换算统一后进行匹配,避免了药品资料中干扰项对匹配过程的干扰,提高了对码成功率;
2、对定点医药机构在新建药品资料时,输入批准文号或条形码调取服务端基库数据,调取后的数据用户无法自行修改,保证了新增数据的规范性;
3、适用于所有的定点医药机构,可快速,智能,全量解决定点医药机构和国家医保目录的对码工作。
附图说明
图1为本发明模块结构图;
图2为本发明全量算法流程图;
图3为本发明用户端分值参数设置界面;
图4为本发明步骤S6具体案例流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1-3,本发明提供一种技术方案:定点医药机构ERP药品与国家医保目录智能全量对码的方法,包括用户端和服务端,所述用户端和服务端之间通过网络进行信息交换;
所述用户端包括数据导入模块、算法参数设置模块、对码确认模块、医保提交贯标模块、新品基库引用模块;
其中,所述数据导入模块用于药品资料的导入,所述药品资料包括:药品名称、含量、包装、重量、尺寸、单位不中的任意一种或多种,所述算法参数设置模块用于手动调整药品分值参数,所述对码确认模块用于接收药品数据处理后的结果,并在用户端进行验证确认,医保提交贯标模块用于将验证后的数据提交至国家医保局,新品基库引用模块用于调取引用基库内的新药品资料,且用户端无法对引用的新品药品资料进行修改,保证新增药品数据的规范性;
所述服务端包括数据格式化模块、数据匹配模块、算法分析优化模块、基库数据运维模块、基库和医保对码模块;
其中,所述数据格式化模块用于将导入的数据分解格式化,便于数据代入算法进行分析,所述数据匹配模块用于将用户端发送的药品资料与国家医保目录进行匹配,算法分析优化模块用于将药品的资料数据进行算法分析,基库数据运维模块用于基库内的数据的运行和维护,所述基库和医保对码模块用于基库内药品资料与医保目录对码。
所述药品资料记录形式为条形码,所述读取药品资料所用设备为扫描器。
主要包括以下步骤:
S1:首先,定点医药机构使用读取设备采集药品资料,并在用户端将药品资料导入,并按药品设定分值:步骤是1、设定总分值,2、设定单项分值,3、设定规格分值,4、对本地数据做预处理,引入自定义正则;
S2:接着,用户端收录导入的药品资料,将药品资料发送至服务端以进行对码确认申请,步骤是:1、导出药品资料模板,2、完善本地药品资料数据,3、执行药品资料导入,4、提交对码申请;
S3:然后,服务端接收药品资料,并针对不同的商品属性,进行语义分析后拆解数据,分解为含量、包装、重量、尺寸、单位的不同维度,其中,数据格式化分解步骤为:
1、商品名称去除停用词,使用的正则算法是:
2、从商品名称数据清洗,使用的正则算法是:
3、生厂厂家去除干扰词,使用的正则算法是:
4、生厂厂家格式化,使用的正则算法是:
5、商品规格格式化,将单位进行统一,拆分为含量、包装、重量、尺寸等多维度,使用的正则及处理是:
/>
/>
/>
/>
/>
6、其他商品属性数据,使用的正则算法是:
/>
S4:然后,对拆解后的数据进行单位换算,统一计量,并根据批准文号、条形码的属性规范,剔除无效的属性;
S5:然后,用文本相似度给商品名称、生产厂家打分,对不同要素授予不同的分值权重;
S6:然后,根据正则算法对数据进行清洗分析,对核心关键字做排除处理,进而将用户端的药品数据与服务端的数据进行匹配,其中,匹配步骤是:
1、对批准文号进行比较,分为完全相等,数字字母部分包含和其他情况,使用的算法是:
/>
2、对条形码进行比较,处理掉无效条码,进行相等比较3、对通用名称及商品名进行比较,并引入文本相似度方法
/>
4、对厂家的原厂和第二厂名进行比较
/>
/>
5、对规格进行多维度比较
/>
/>
/>
/>
/>
/>
/>
/>
6、对核心关键字进行否决方法
/>
S7:最后,服务端将匹配结果进行分类,并反馈给定点医药机构进行验证和确认,步骤是:1、忽略高匹配度药品资料,2、对中匹配度做抽查,3、对低匹配度做全量检查;
S8:定点医疗机构对数据验证后,医保提交贯标模块将医保数据全量给国家医保局上报,完成贯标对码工作,步骤是:1、在用户端对应界面,点击全量上报,2、医保平台返回上报结果,如成功则完成医保贯标工作。
其中,参考图4,S6步骤的具体案例如下:
对“批准文号:国药准字B2002050
通用名称:复方黄柏祛藓搽剂1
规格:1.2升每瓶
条形码:123445A
生产厂家:哈药三场委托江西丰达制药厂生产”的药品进行处理,
首先,基于批准文号规则和条形码规则,保留批准文号而去除条形码;
接着,基于大数据将错别字“藓”处理为“癣”,并去除无效字符1;
然后,将单位转为ml,将每瓶做标准化写法处理为ml/瓶;
最后,在具有的委托关系中,取生实际生产厂家,并消除生产等描述词;
最终,获得处理结果为
批准文号:国药标准B2002050
通用名称:复方复方黄柏祛癣搽剂
规格:1200ml/瓶
条形码:
生产厂家:江西丰达制药厂。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。