一种促进多智能体协作性的通讯强化学习算法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明属于多智能体协作与竞争领域,涉及一种基于深度学习的多智能体通讯强化学习算法。
背景技术
合作多智能体强化学习(MARL)正变得越来越流行,并已应用于许多领域,例如自动驾驶汽车团队、机器人群控制和无人驾驶飞行器等。人类社会可以实现高效协作,因为当一个团队处理一个复杂的问题时,他们会通过交流通信将不同的任务分配给不同的人实现分工协作,这也是通用人工智能的基础。实际上,人类社会可以被视为一个大规模的只能观测到部分信息的多智能体系统,其中许多自动化的协作任务将会使处理合作任务的效率提高。因此在大规模多智能体合作任务的系统中提高算法性能的关键是如何通过提高智能体之间的通信效率促进智能体间的合作。
在现实世界中,多智能体系统中通常包含不同类型和大量的智能体。这些复杂交互的智能体给策略学习带来了极大的困难,尤其是当智能体只能获得部分观测并且面临需要协作和同步的任务时。通信组件是多智能体系统学习协调行为的核心组成部分之一,它在多智能体系统中引起了越来越多的关注。多智能体之间出现的通信通道被认为可以提高多智能体任务分散执行阶段的性能。目前现有的所有多智能体通讯算法都直接将代理之间交换的信息作为环境的一部分来预测当前时间步的动作,这种做法会使智能体之间进行大量的通信,增加的智能体的观测空间而且对智能体之间的通信通道有极高的要求,然而在大量的通信消息中智能体难以辨别那些信息是重要的,这极大的增加学习的难度。
尽管一些多智能体通信强化学习算法已经取得了一些成就,但智能体如何高效的使用其他智能体发送的通信的消息仍然是一个重大挑战。
为了解决上述问题,本发明提出了一种多智能体分层通讯强化学习算法。与其他多智能体强化学习通信方法不同,本发明将智能体之间的通信模块分解为层次结构,这不仅大大降低了通信频率,而且使模型能够学习更有效的策略来使用智能体间传递的消息。
发明内容
本发明提出了一种基于深度学习的多智能体分层通信算法,该算法智能体首先根据当前观测到的环境状态和其他智能体发送过来的消息计算得出智能体之间的交互关系,然后基于智能体之间的交互关系为其他智能体分配注意力权重选择顶层策略。选择不同的顶层策略意味着智能体之间存在分工。然后在底层策略中,智能体根据选择的高级策略据与局部观测选择适当的动作。通过形成分层通信网络结构,简化了学习过程,降低了学习合作的难度。
该算法通过神经网络反向传播进行端到端训练。本发明的模型与人类解决复杂问题的方式非常相似,通过沟通选择顶层策略,而不是直接选择当前时间步的动作。模型通过在部分可观察的分布式环境中进行分层通信来学习智能体之间的交互关系,从而可以有效地使用智能体之间的消息。模型采用了分层结构,这更像是人类社会中解决复杂问题的方式。只需间隔特定个时间步进行一次通信,即可调整顶级策略。这不仅减少了智能体之间通信的消息数量,而且由于没有增加用于预测行动的观察空间,并且提高了通信的有效性,从而促进了智能体之间的协作。
为了达到上述目的,本发明的技术方案如下:
一种基于深度学习的多智能体通讯强化学习算法,包括如下步骤:
步骤(1)模型与环境进行交互获得每一时刻的全局状态和每个智能体的局部观测信息。
步骤(2):训练动作语义表征编码模型,使用动作表征编码来分解智能体的动作空间。
步骤(3):智能体选择顶层策略,智能体通过沟通提取智能体之间的关系选择角色,从而达到分工合作的目的。
步骤(4):智能体根据顶层策略在子动作空间中选择适当的行动。
步骤(5):将上述所有组件综合成一个协同学习框架,并采用端到端的训练方式优化损失函数。
进一步地,所述步骤(2)包括以下步骤:
(2.1)训练参数为θ
(2.2)给定智能体i的当前时间步本地局部观测o
(2.3)将θ
其中D是经验重放缓冲区,
(2.4)训练的f
(2.5)将智能体的所有可执行的动作输入至动作编码器获得每个不同的动作表征,使用k均值聚类方法通过测量动作表征的欧氏距离将智能体的整个动作空间划分为k组,不同的组具有不同的子动作空间,数字k是一个超参数。动作分组后,训练开始。智能体根据局部观测和其他智能体的消息选择高层策略,即选择k组子动作空间中的一个。在训练过程中,每组子动作空间的动作表征保持固定。
进一步地,所述步骤(3)包括以下步骤:
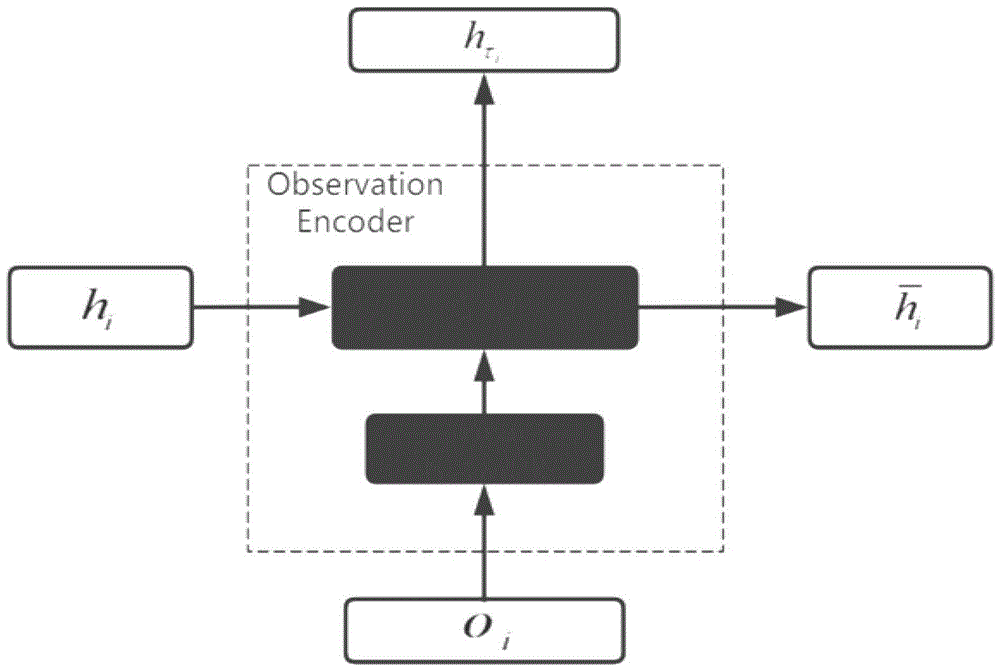
(3.1)构建一个包含一层线性层和一层记忆单元网络的顶层策略观测编码器,将智能体的局部观测O和循环网络记忆单元中隐藏状态h同时输入进循环网络单元中编码输出为向量hτ。
(3.2)在顶层策略网络中设置由χ参数化的多轮通信器。通信轮数被视为超参数。在通信结构中使用基于键值的自注意力机制,每个通信器由两个组件组成:发送器和接收器。
(3.3)每个智能体通过发送器生成消息,通过接收器接收和处理其他智能体的消息。智能体的通信器将观测编码hτ和消息作为输入发送给其他智能体,并通过注意力模块抽象智能体之间的关系,最后将其他智能体的消息将它们集成到向量h
(3.4)在接收端,每个智能体首先从作为通信器输入的
智能体i接收所有其他智能体发送过来的消息,使用查询q
其中
对于多轮通信,再次使用更新的隐藏状态
(3.5)顶层策略输出角色Q值,角色选择器基于可执行动作的的平均表示计算
(3.6)智能体选择最大的角色Q值
进一步地,所述步骤(4)包括以下步骤:
(4.1)构建每个不同角色策略网络,每个角色策略
(4.2)通过
(4.3)使用动作表示
进一步地,所述步骤(5)包括以下步骤:
(5.1)使用每个智能体
(5.2)将Q值
(5.3)将以下TD损失降至最低,以更新高层策略:
其中
其中
(5.4)通过反向梯度传播使总损失L=L
本发明基于分层深度强化学习模型,可以在大规模多智能体系统中实现良好的协作,本发明与人类群体解决复杂问题的方式非常相似,通过沟通选择顶级策略,而不是直接决定行动。模型不仅具有较低的通信频率,而且具有较好好的可扩展性。
附图说明
图1总体模型框架流程图;
图2动作编码表征的前馈模型图;
图3局部观测编码器结构图;
图4通讯模块的总体结构模型图;
图5信息发送模块结构图;
图6信息接收模型结构图;
图7高层策略模型结构图;
图8底层策略模型结构图。
具体实施方式
以下结合附图和技术方案,对本发明实施例进行详细的描述。
本发明的包括以下步骤:
(1)每个时间步与环境交互进行数据采集并储存到经验重放缓冲器中。
(2)动作表征编码模型训练过程:构建编码器模型与解码器模型,其中编码器模型都包含当前智能体执行动作输入过程、其他智能体所选动作和当前状态输入过程以及编码输出过程,解码器模型需要将动作特征和状态特征进行拼接,且包含解码过程和解码输出过程。初始化编码器模型与解码器模型的参数。
(3)划分子动作空间,在获得动作表示之后,通过测量动作表示的欧氏距离,使用k均值聚类将智能体的完整动作空间划分为5组,不同的组具有不同的子动作空间。根据属于同一组的动作在其动作表示之间具有较小的欧氏距离,这意味着它们对环境和其他智能体具有相似的影响。例如,移动动作和攻击动作通常被划分为不同的组。动作分组后,训练开始,在训练过程中,每组的动作表示和动作空间保持固定。
(4)模型训练过程:本发明模型包括顶层观测编码器和底层观测编码器,它们具有相同网络的结构,分别由δ
(5)模型预测过程:在两个模型的损失函数收敛至最低或迭代达到预先设定好的次数后,保存观测编码模型,顶层策略网络模型和底层策略网络模型。每隔5个时间步将智能体的局部观测输入该模型进行顶层策略预测,根据选择的高层策略执行底层策略动作预测,最终将获得每个智能体在此时间步的执行动作与环境进行交互。