一种基于视频AI剪辑的智能归类系统
文献发布时间:2024-01-17 01:27:33
技术领域
本发明涉及视频剪辑技术领域,更具体地说,本发明涉及一种基于视频AI剪辑的智能归类系统。
背景技术
在这个资讯传播速度极快的时代,人们对视频内容的要求也越来越高。在新的媒体环境下,视频的输出需要满足准确性和实时性的要求。目前,仅靠手工视频剪辑已经无法满足人们对图像产品的需求。近年来,随着人工智能技术的飞速发展,视频剪辑的自动化程度和智能化程度不断提高。在短视频领域为了方便自媒体运营者自己制作短视频,推出许多手机端剪辑软件。当剪辑软件利用自动语音识别智能生成相应的字幕时,常会存在语音模糊的片段,导致观众产生较差的观感。传统的语音识别功能多用特征提取、声学模型以及语言模型的理论进行识别,但是对于自媒体运营者存在口音、说话速度过快的情况,自动语音识别通常难以准确进行识别,并且对于无法识别的语句通常显示无法识别而非阐述相同含义的语句,对自媒体运营者造成了一定的烦恼。
为了解决上述问题,现提供一种技术方案。
发明内容
为了克服现有技术的上述缺陷,本发明的实施例提供一种基于视频AI剪辑的智能归类系统,通过模糊音频提取模块提取音频特征,利用音频特征获取音频帧数据集,通过音频帧数据集生成五条候选语句并建立候选语句概率分析模型,选择音频帧指标的综合概率最高的候选语句输入至模糊音频修正模块,通过模糊音频修正模块综合完善最佳候选语句,并将不合格的语句返回至模糊音频识别模块重新生成,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:
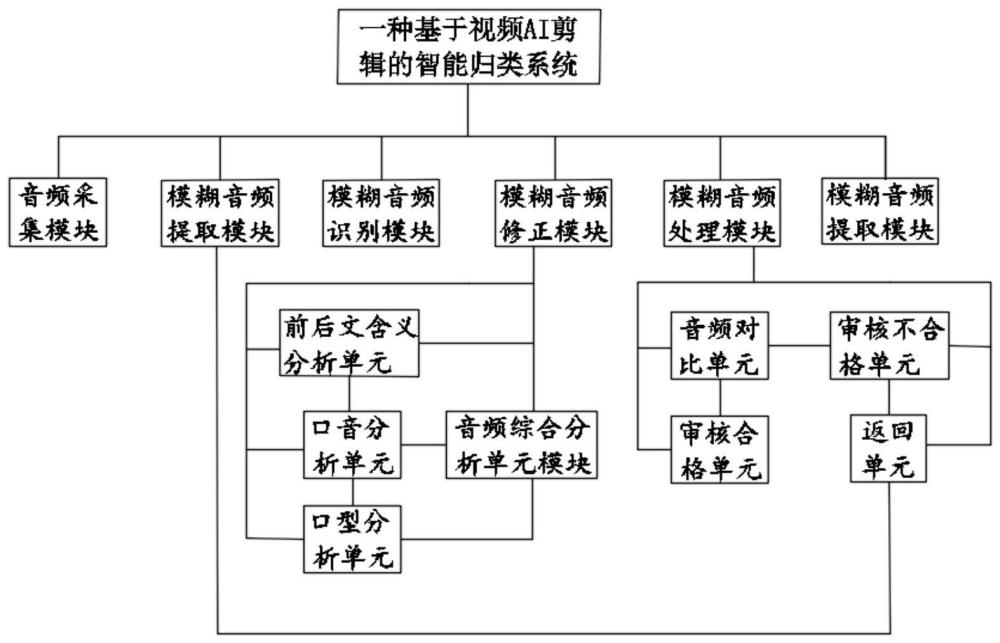
一种基于视频AI剪辑的智能归类系统,包括音频采集模块、模糊音频提取模块、模糊音频识别模块、模糊音频修正模块、模糊音频处理模块以及音频数据存储模块,音频采集模块与模糊音频提取模块相连接,模糊音频提取模块与模糊音频识别模块与相连接,模糊音频识别模块与模糊音频修正模块相连接,模糊音频修正模块与模糊音频处理模块相连接,模糊音频处理模块与音频数据存储模块相连接,其中,模糊音频识别模块依据模糊音频提取模块提取的音频特征生成五条候选语句,并建立候选语句概率分析模型分析音频帧指标的综合概率最高的候选语句。
音频文件时长较长,想要能够更好地对音频进行特征分析,需要将连续的音频划分为多个较短的音频帧,这样做能够捕捉到音频中的快速变化和细微的音频特征,而傅里叶变换能够将这些音频帧转换为频谱表示,进而根据音频帧的特点转换为音频特征在傅里叶变换后的频率和振幅信息。
作为本发明进一步的方案,模糊音频提取模块通过将音频采集模块采集的连续音频转换为音频帧,对音频帧进行傅里叶变换获得音频特征,对音频帧进行傅里叶变换的公式为:
式中,S{x(t)}为音频特征,x(t)为输入的音频帧信号,t为音频帧的时间,τ为帧移,e
傅里叶变将音频信号从时域转换到频域,这种转换能够同时分析音频信号在时间和频率上的特征,通过观察不同音频帧的频谱,能够获取音频信号的时域和频域特征,如频率分布、音调、共振峰等,给语音识别、语音合成带来了便利。音频特征是音频信号的抽象表示,包含了对音频有用的信息,而傅里叶变换将音频帧转化为频谱表示,能够帮助提取出频率和振幅的信息特征,从而有助于进行语音识中的声学模型训练、音频识别和音频分类,同时音频帧的傅里叶变换也能够降低数据的维度,将连续音频数据中大量采样点的数据量缩减和降维,进而有助于提高语音识别的效率和准确度。
作为本发明进一步的方案,模糊音频识别模块通过模糊音频提取模块提取的音频特征获取音频帧的清晰程度、沙哑程度、语速、语调指标以及音色指标,并生成音频帧数据集,通过音频帧数据集生成五条候选语句,并建立候选语句概率分析模型。
通过清晰程度、沙哑程度、语速、语调指标和音色指标的提取,能够利用这些特征对音频的质量和语音特征进行描述和限定,有助于判断一品的可理解度和表达效果,基于音频帧数据集,建立语音识别候选语句,这些候选语句能够根据音频帧的特征进行自动推测,用作后续的语义理解、文本处理和自然语言处理任务的输入。
作为本发明进一步的方案,候选语句概率分析模型通过综合音频帧的清晰程度、沙哑程度、语速、语调指标以及音色指标与各指标正常值的占比建立候选语句概率分析模型,其中,候选语句概率分析模型的计算公式为:
p(Q)=p(Q
式中:p(Q)为音频帧指标的综合概率,p(Q
综合考虑音频帧的多个指标与各指标正常值的占比,能够客观评估语音质量的好坏,不同指标的正常值范围是通过对大量的正常语音样本进行统计和分析得出的,通过与这些正常值进行比较,能够判断音频的清晰程度、沙哑程度、语速、语调以及音色是否正常,从而对语音质量进行评估,候选语句概率分析模型利用音频帧的多个指标与各指标正常值的占比,为生成的候选语句进行评分和排序,通过考虑语音质量指标,能够更准确地判断哪些候选语句与音频内容相符合,提高候选语句的质量和准确性,避免了选择那些与音频特征不匹配或语音质量较差的候选语句,候选语句概率分析模型的建立进一步提高了语音识别系统的准确性,通过综合音频帧的多个指标与各指标正常值的占比,能够根据音频的质量和语音特征,对每个候选语句进行概率评估,这样,识别系统根据候选语句的概率信息,能够更准确地选择正确语句,提高识别结果的准确性和可靠性,基于音频帧指标与各指标正常值的占比建立的概率分析模型具有一定的自适应性和鲁棒性,因为它能够根据不同的音频特征和语音质量,动态地调整候选语句的评分,这使得模型能够适应不同语音环境和不同说话人的特征,提高系统在各种条件下的稳定性和可用性。
作为本发明进一步的方案,模糊音频修正模块包括前后文含义分析单元、口音分析单元、口型分析单元以及音频综合分析单元,前后文含义分析单元与口音分析单元相连接,口音分析单元与口型分析单元相连接,音频综合分析单元与前后文含义分析单元、口音分析单元以及口型分析单元均相连接。
作为本发明进一步的方案,模糊音频修正模块通过将音频帧指标的综合概率最高的候选语句依次输入至前后文含义分析单元、口音分析单元以及口型分析单元,将输出结果分别输入至音频综合分析单元,通过音频综合分析单元综合完善最佳候选语句。
作为本发明进一步的方案,模糊音频处理模块包括音频对比单元、审核合格单元、审核不合格单元以及返回单元,音频对比单元与审核合格单元相连接,音频对比单元与审核不合格单元相连接,审核不合格单元与返回单元相连接。
作为本发明进一步的方案,模糊音频修正模块将最佳候选语句输入至模糊音频处理模块,音频对比单元通过对音频前后语境以及最佳候选语句句意进行对比分析,对比结果合格输入至审核合格单元,对比结果不合格输入至审核不合格单元。
作为本发明进一步的方案,对比结果不合格的最佳候选语句输入至审核不合格单元,再输入至返回单元返回至模糊音频识别模块重新生成。
作为本发明进一步的方案,模糊音频处理模块中的音频对比单元通过音频语句的适配度判断模糊音频修正模块输入的最佳候选语句合格或不合格,其中,音频语句的适配度及计算公式为:
式中:P为音频语句的适配度,n为模型的阶数,L为音频语句中词序列的长度,ω
本发明一种基于视频AI剪辑的智能归类系统的技术效果和优点:
1.本发明通过自动化视频剪辑过程,减少了剪辑师的时间和精力消耗,让他们能够更专注于创意内容的创造。
2.本发明智能归类系统避免了人类剪辑师可能出现的错误,如漏掉关键帧、误删除素材等,降低了剪辑过程中的失误率;
3.本发明通过智能归类系统的使用,剪辑师能够将更多的精力放在创意思考和内容设计上,从而提高工作满意度。
附图说明
图1为本发明一种基于视频AI剪辑的智能归类系统的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
一种基于视频AI剪辑的智能归类系统,包括音频采集模块、模糊音频提取模块、模糊音频识别模块、模糊音频修正模块、模糊音频处理模块以及音频数据存储模块,音频采集模块与模糊音频提取模块相连接,模糊音频提取模块与模糊音频识别模块与相连接,模糊音频识别模块与模糊音频修正模块相连接,模糊音频修正模块与模糊音频处理模块相连接,模糊音频处理模块与音频数据存储模块相连接,其中,模糊音频识别模块依据模糊音频提取模块提取的音频特征生成五条候选语句,并建立候选语句概率分析模型分析音频帧指标的综合概率最高的候选语句。
音频文件时长较长,想要能够更好地对音频进行特征分析,需要将连续的音频划分为多个较短的音频帧,这样做能够捕捉到音频中的快速变化和细微的音频特征,而傅里叶变换能够将这些音频帧转换为频谱表示,进而根据音频帧的特点转换为音频特征在傅里叶变换后的频率和振幅信息。
本实施例中模糊音频提取模块通过将音频采集模块采集的连续音频转换为音频帧,对音频帧进行傅里叶变换获得音频特征,对音频帧进行傅里叶变换的公式为:
式中,S{x(t)}为音频特征,x(t)为输入的音频帧信号,t为音频帧的时间,τ为帧移,e
通过傅里叶变换能够将时域信号转换为频域信号,从而让我们能够从不同的频率分量来理解信号。
具体地,傅里叶变将音频信号从时域转换到频域,这种转换能够同时分析音频信号在时间和频率上的特征,通过观察不同音频帧的频谱,能够获取音频信号的时域和频域特征,如频率分布、音调、共振峰等,给语音识别、语音合成带来了便利。音频特征是音频信号的抽象表示,包含了对音频有用的信息,而傅里叶变换将音频帧转化为频谱表示,能够帮助提取出频率和振幅的信息特征,从而有助于进行语音识中的声学模型训练、音频识别和音频分类,同时音频帧的傅里叶变换也能够降低数据的维度,将连续音频数据中大量采样点的数据量缩减和降维,进而有助于提高语音识别的效率和准确度。
本实施例中模糊音频识别模块通过模糊音频提取模块提取的音频特征获取音频帧的清晰程度、沙哑程度、语速、语调指标以及音色指标,并生成音频帧数据集,通过音频帧数据集生成五条候选语句,并建立候选语句概率分析模型。
需要说明的是,通过清晰程度、沙哑程度、语速、语调指标和音色指标的提取,能够利用这些特征对音频的质量和语音特征进行描述和限定,有助于判断一品的可理解度和表达效果,基于音频帧数据集,建立语音识别候选语句,这些候选语句能够根据音频帧的特征进行自动推测,用作后续的语义理解、文本处理和自然语言处理任务的输入。
本实施例中候选语句概率分析模型通过综合音频帧的清晰程度、沙哑程度、语速、语调指标以及音色指标与各指标正常值的占比建立候选语句概率分析模型,其中,候选语句概率分析模型的计算公式为:
p(Q)=p(Q
式中:p(Q)为音频帧指标的综合概率,p(Q
需要进一步阐述的是,综合考虑音频帧的多个指标与各指标正常值的占比,能够客观评估语音质量的好坏,不同指标的正常值范围是通过对大量的正常语音样本进行统计和分析得出的,通过与这些正常值进行比较,能够判断音频的清晰程度、沙哑程度、语速、语调以及音色是否正常,从而对语音质量进行评估,候选语句概率分析模型利用音频帧的多个指标与各指标正常值的占比,为生成的候选语句进行评分和排序,通过考虑语音质量指标,能够更准确地判断哪些候选语句与音频内容相符合,提高候选语句的质量和准确性,避免了选择那些与音频特征不匹配或语音质量较差的候选语句,候选语句概率分析模型的建立进一步提高了语音识别系统的准确性,通过综合音频帧的多个指标与各指标正常值的占比,能够根据音频的质量和语音特征,对每个候选语句进行概率评估,这样,识别系统根据候选语句的概率信息,能够更准确地选择正确语句,提高识别结果的准确性和可靠性,基于音频帧指标与各指标正常值的占比建立的概率分析模型具有一定的自适应性和鲁棒性,因为它能够根据不同的音频特征和语音质量,动态地调整候选语句的评分,这使得模型能够适应不同语音环境和不同说话人的特征,提高系统在各种条件下的稳定性和可用性。
实施例1
如图1所示,当自媒体运营者在剪辑唱歌视频或者其他音调较为奇怪的视频时,现将视频通过音频采集模块提取出音频信息,将提取出的音频信息输入至模糊音频提取模块,将连续音频转换为音频帧,再对音频帧进行傅里叶变换获得音频特征,模糊音频识别模块通过模糊音频提取模块提取的音频特征获取音频帧的清晰程度、沙哑程度、语速、语调指标以及音色指标,并生成音频帧数据集,通过音频帧数据集生成五条候选语句,并建立候选语句概率分析模型。候选语句概率分析模型通过综合音频帧的清晰程度、沙哑程度、语速、语调指标以及音色指标与各指标正常值的占比建立候选语句概率分析模型,从而确定模糊音频中的五条候选语句概率最大的一条为最佳候选语句。
本实施例中模糊音频修正模块包括前后文含义分析单元、口音分析单元、口型分析单元以及音频综合分析单元,前后文含义分析单元与口音分析单元相连接,口音分析单元与口型分析单元相连接,音频综合分析单元与前后文含义分析单元、口音分析单元以及口型分析单元均相连接。
其中,前后文含义分析单元用于分析模糊语音中的前后文信息,并进行语义理解,根据上下文的语境和语义信息,对模糊语音的意图和含义进行推测和解析,使用语义分析算法来理解模糊语音所传达的信息,利用语义配准程度对模糊音的识别语义进行修正;口音分析单元用于对模糊语音中的口音进行分析,识别说话者的口音特征,以及口音对语音的清晰度、发音和语调产生的影响,通过口音分析,更好地了解模糊语音中的语音特征,并结合其他分析单元进行修正;口型分析单元用于对模糊语音中的口型特征进行分析,根据声音的共振、声带的振动以及嘴唇、舌头和颚部等口腔器官的运动,推测说话者的口型状态,识别模糊语音中存在的发音问题或发音不清晰的情况,为修正提供参考;音频综合分析单元用于综合前后文含义分析单元、口音分析单元和口型分析单元的结果,并进行音频综合分析,结合各种分析单元的输出,综合考虑模糊语音中的语义、口音和口型等特征,确定修正策略和生成最佳的修正语音,使用机器学习算法来生成修正后的语音输出。
本实施例中模糊音频修正模块通过将音频帧指标的综合概率最高的候选语句依次输入至前后文含义分析单元、口音分析单元以及口型分析单元,将输出结果分别输入至音频综合分析单元,通过音频综合分析单元综合完善最佳候选语句。
本实施例中模糊音频处理模块中的音频对比单元通过音频语句的适配度判断模糊音频修正模块输入的最佳候选语句合格或不合格,其中,音频语句的适配度及计算公式为:
式中:P为音频语句的适配度,n为模型的阶数,L为音频语句中词序列的长度,ω
音频语句的适配度及计算公式设置的目的在于:(1)选择最佳候选语句,音频对比单元的目的是对比输入的最佳候选语句与原始模糊音频之间的适配度,如果最佳候选语句与模糊音频适配度较高,即两者在内容和语义上相符合,判断该候选语句是合格的,能够用作模糊音频的修正,能够确保修正后的音频更准确地表达了原始音频所要传达的信息;(2)提高修正效果,通过判断最佳候选语句的适配度,避免选择与模糊音频不相符合的候选语句,如果最佳候选语句与模糊音频适配度较低,会导致修正后的音频与原始音频内容不一致,甚至引入更多的错误,判断候选语句的合格性提高了修正效果,确保修正后的音频更符合原始音频的意图和语义;(3)保留原始信息,在模糊音频修正的过程中,选择合格的候选语句能够更好地保留原始音频中的重要信息,合格的候选语句通常与模糊音频在语义和内容上相符合,能够更准确地表达原始音频中的信息,通过保留原始信息,修正后的音频能够更好地还原原始音频的含义和目的。
实施例2
本实施例与实施例1不同的是,本实施例结合给定的音频语句适配度,具体分析音频语句适配度的判断过程。
通过音频语句的适配度公式判断出,音频语句的适配度越小,选取的最佳候选语句越成功。当音频语句的适配度为x时,其中的每个词序列之后都有x各候选分支,也就是每个词序列之后都有可能会出现x个相同意义的词,并且,这x个词与该词序列一同搭配出现的概率是相同的。因此,当音频语句的适配度x越大时,系统所需要考虑的候选分支也就相应增多,也就是,音频语句的适配度越高,词的混淆概率也就越高。相应的,当音频语句的适配度越低时,词的混淆概率也同样就越低,此时,系统对语言的前后文的约束能力同样越强,故而,系统的对模糊的音频处理效果也就越好。由此能够得出,音频语句的适配度是判断最佳候选语句合格或不合格的关键因素。
本实施例中模糊音频处理模块包括音频对比单元、审核合格单元、审核不合格单元以及返回单元,音频对比单元与审核合格单元相连接,音频对比单元与审核不合格单元相连接,审核不合格单元与返回单元相连接。
本实施例中模糊音频修正模块将最佳候选语句输入至模糊音频处理模块,音频对比单元通过对音频前后语境以及最佳候选语句句意进行对比分析,对比结果合格输入至审核合格单元,对比结果不合格输入至审核不合格单元。
本实施例中对比结果不合格的最佳候选语句输入至审核不合格单元,再输入至返回单元返回至模糊音频识别模块重新生成。
本实施例将模糊音频识别模块确定的最佳候选语句依次输入至前后文含义分析单元、口音分析单元以及口型分析单元,将输出结果分别输入至音频综合分析单元,通过音频综合分析单元综合完善最佳候选语句。随后,再将最佳候选语句输入至模糊音频处理模块,模糊音频处理模块的音频对比单元通过对音频前后语境以及最佳候选语句句意进行对比分析,当对比结果合格时,将最佳候选语句输入至审核合格单元;当对比结果不合格时,将最佳候选语句输入至审核不合格单元,再输入至返回单元返回至模糊音频识别模块重新生成。
本实施例通过模糊音频提取模块提取音频特征,利用音频特征获取音频帧数据集,通过音频帧数据集生成五条候选语句并建立候选语句概率分析模型,选择音频帧指标的综合概率最高的候选语句输入至模糊音频修正模块,通过模糊音频修正模块综合完善最佳候选语句,并将不合格的语句返回至模糊音频识别模块重新生成。有助于减少剪辑师的时间和精力消耗,让他们能够更专注于创意内容的创造,同时避免了人类剪辑师可能出现的错误,如漏掉关键帧、误删除素材等,降低了剪辑过程中的失误率,使剪辑师能够将更多的精力放在创意思考和内容设计上,从而提高工作满意度。
以上所述,仅为本申请的具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应以所述权利要求的保护范围为准。
最后:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。