一种基于数字孪生技术的智慧园区能源管理方法及系统
文献发布时间:2024-04-18 19:58:53
技术领域
本发明涉及数字孪生技术领域,具体是指一种基于数字孪生技术的智慧园区能源管理方法及系统。
背景技术
智慧园区能源管理是利用信息技术和智能化手段对园区内的能源系统进行监控、控制和优化管理的方法,用以提高能源利用效率,实现可持续发展。现有的基于数字孪生技术的智慧园区能源管理方法及系统存在着采集数据中包含异常值,致使后续数据处理失真的问题;存在着采集的数据特征冗余、复杂性高且不利于模型构建的问题;存在着单一模型结构复杂,训练容易陷入局部最优解,导致预测模型的准确性和可扩展性较差的问题;反向传播神经网络预测模型存在着模型权重过高,导致模型过拟合的问题。
发明内容
针对上述情况,为克服现有技术的缺陷,本发明提供一种基于数字孪生技术的智慧园区能源管理方法及系统,针对采集数据中包含异常值,致使后续数据处理失真的问题,本发明采用异常值检测算法,准确识别园区管理原始数据中与其他数据相距较远的异常值,去除异常值,提高分析效率;针对采集的数据特征冗余、复杂性高且不利于模型构建的问题,本发明采用主成分分析算法计算协方差矩阵的特征值和特征向量,找到数据集中最重要的特征,将高维数据集映射到低维空间,减少冗余并保留关键性和有区分度的特征,方便构建模型;针对单一模型结构复杂,训练容易陷入局部最优解,导致预测模型的准确性和可扩展性较差的问题,本发明采用随机森林预测模型和反向传播神经网络预测模型组合的方法,全面处理特征信息,提高特征信息的表达能力和模型的准确率;针对反向传播神经网络预测模型的模型权重过高,导致模型过拟合的问题,本发明采用正则化来惩罚过大的权重,限制模型的复杂度,避免过拟合,提高模型的泛化能力。
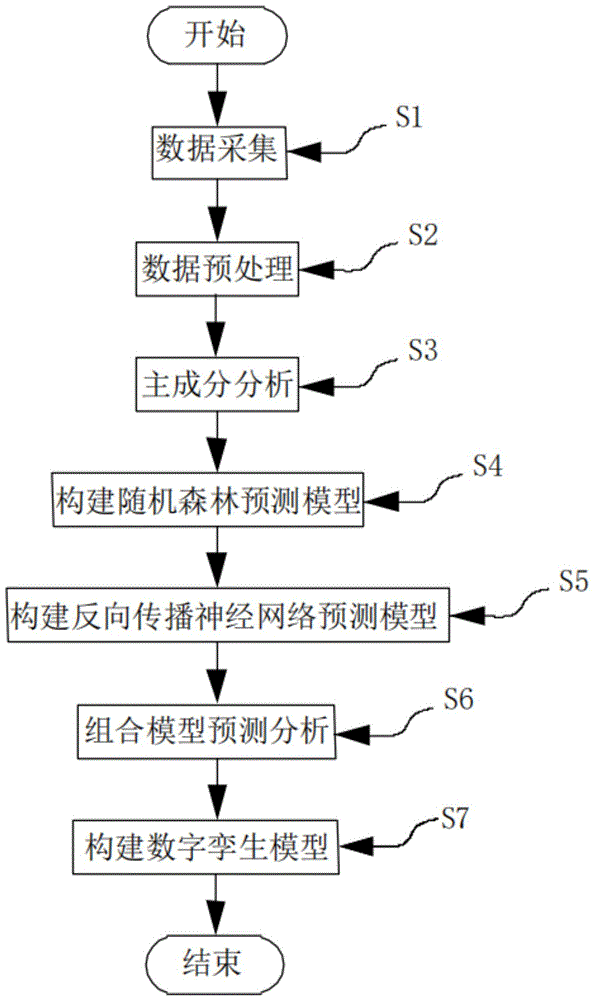
本发明采用的技术方法如下:本发明提供的一种基于数字孪生技术的智慧园区能源管理方法,该方法包括以下步骤:
步骤S1:数据采集;
步骤S2:数据预处理;
步骤S3:主成分分析;
步骤S4:构建随机森林预测模型;
步骤S5:构建反向传播神经网络预测模型;
步骤S6:组合模型预测分析;
步骤S7:构建数字孪生模型。
进一步地,在步骤S1中,所述数据采集,具体为通过实时采集智慧园区内传感器、智能电表、周围环境以及设备状态的数据,得到园区管理原始数据集T
进一步地,在步骤S2中,所述数据预处理,具体为通过对所述园区管理原始数据集T
步骤S21:构建样本数据集,具体为从所述园区管理原始数据集T
;
式中,X表示样本数据集,x
步骤S22:构造观测值向量,其中包含m个元素,所用公式如下:
;
式中,X
步骤S23:计算样本均值向量,具体为通过对观测值向量进行均值运算,得到样本均值向量
;
式中,
步骤S24:计算样本协方差矩阵,具体为通过计算样本中每个维度的协方差,得到样本协方差矩阵Q,所用公式如下:
;
式中,Q表示样本协方差矩阵,
步骤S25:通过对观测值向量和样本均值向量进行距离运算,得到样本间马氏距离Z,所用公式如下:
;
式中,Z表示样本间马氏距离,Q表示样本协方差矩阵,
步骤S26:去除异常值,具体为通过设置阈值T,对比样本间马氏距离Z和阈值T的大小,删除大于阈值T的样本数据,得到高维数据集T
进一步地,在步骤S3中,所述主成分分析,具体为通过对所述高维数据集T
步骤S31:通过构造高维数据集T
;
式中,R表示协方差矩阵,n表示样本数量,
步骤S32:计算特征值和特征向量,具体为通过对协方差矩阵R进行奇异值矩阵分解操作,得到特征值λ
步骤S321:对协方差矩阵进行奇异值矩阵分解,所用公式如下:
;
式中,U表示R的左奇异向量矩阵,S表示对角矩阵,V
步骤S322:计算协方差矩阵的特征值,所用公式如下:
;
式中,λ
步骤S323:计算协方差矩阵的特征向量,所用公式如下:
;
式中,w
步骤S33:根据特征值大小进行排序,通过选择前z个最大特征值,进行对角矩阵截断,使其余特征值置0,得到截断对角矩阵
步骤S34:通过将高维数据集中的特征值和特征向量映射到低维数据集,得到低维数据集T
进一步地,在步骤S4中,所述构建随机森林预测模型,具体为通过对所述低维数据集T
步骤S41:将低维数据集T
步骤S42:随机抽样,具体为通过对训练数据集进行随机抽样操作,每个训练子集抽取t个样本数据,抽取k次,得到k个训练子集,具体步骤如下:
步骤S421:从训练数据集中有放回的随机抽取t个样本数据,构建一个训练子集;
步骤S422:重复步骤S521,抽取k次,得到k个训练子集,保证每个子集都包含t个样本数据;
步骤S43:构建决策树,具体为基于k个不同的训练子集构建k棵决策树,生成一棵决策树的步骤如下:
步骤S431:以训练子集W被特征C划分为例,所述特征C包括特征向量和各种特征值;
步骤S432:计算训练子集W的信息熵,所用公式如下:
;
式中,H(W)表示训练子集W的信息熵,i表示分类标签数目,p
步骤S433:计算特征C对训练子集W的条件熵,具体为通过特征C对训练子集W进行划分操作,划分成m份,得到特征C对训练子集W的条件熵,所用公式如下:
;
式中,H(W|C)表示特征C对训练子集W的条件熵,p
步骤S434:计算信息增益,具体为通过选择具有最大信息增益的特征变量及阈值进行划分操作,并不断对训练子集进行拆分,直至所有训练子集数据属于同一类别或无法再进行划分,得到决策树的分类结果,所用公式如下:
;
式中,G(W,C)表示特征值C对训练子集W的信息增益,H(W)表示训练子集W的信息熵,H(W|C)表示特征C对训练子集W的条件熵;
步骤S44:计算决策树的分类权重,所用公式如下:
;
式中,
步骤S45:重新生成,具体为设置权重阈值,对分类权重低于权重阈值的决策树随机选取m个样本数据重新生成,直到拥有k个分类权重不低于权重阈值的决策树;
步骤S46:构建随机森林预测模型,具体为通过对测试数据集进行分类操作使测试集遍历k棵不同的决策树,得到随机森林预测模型的能耗预测结果p
进一步地,在步骤S5中,所述构建反向传播神经网络预测模型,具体为通过对所述低维数据集T
步骤S51:将低维数据集T
步骤S52:构建训练数据集T={x
;
式中,x
步骤S53:采用sigmoid激活函数进行激活,所用公式如下:
;
式中,f(x)表示激活函数,e表示指数运算;
步骤S54:计算隐藏层神经元n的输出,所用公式如下:
;
式中,O
步骤S55:计算隐藏层的残余误差,所用公式如下:
;
式中,E表示隐藏层的残余误差,O
步骤S56:通过反向传播算法的梯度法来实现权重和阈值的更新,得到最优权重和阈值,具体包括以下步骤:
步骤S561:计算输入层到隐藏层的连接权重,所用公式如下:
;
式中,ω
步骤S562:计算L1正则化后的权重,具体为向目标函数添加权重的绝对值来惩罚较大权重,所用公式如下:
;
式中,
步骤S563:计算L2正则化后的权重,具体为向目标函数添加权重的平方来惩罚较大权重,所用公式如下:
;
式中,
步骤S564:更新隐藏层的神经元阈值,所用公式如下:
;
式中,t表示迭代更新的时间,b
步骤S565:计算隐藏层到输出层的连接权重,所用公式如下:
;
式中,c
步骤S566:更新输出层的神经元阈值,所用公式如下:
;
式中,b
步骤S57:构建反向传播神经网络预测模型,具体为通过训练数据集输出最优权重和阈值,测试数据集遍历反向传播神经网络预测模型,得到反向传播神经网络预测模型的能耗预测结果p
进一步地,在步骤S6中,所述组合模型预测分析,具体为通过计算随机森林预测模型和反向传播神经网络预测模型的权重,进行组合操作,得到组合能耗预测结果,具体包括以下步骤:
步骤S61:计算随机森林预测模型和反向传播神经网络预测模型的方差,所用公式如下:
;
式中,θ
步骤S62:计算随机森林预测模型的动态权重,所用公式如下:
;
式中,ω
步骤S63:计算反向传播神经网络预测模型的动态权重,所用公式如下:
;
式中,ω
步骤S64:组合随机森林预测模型和反向传播神经网络预测模型的能耗预测结果,所用公式如下:
;
式中,p表示组合随机森林预测模型和反向传播神经网络预测模型的能耗预测结果,p
步骤S65:组合模型预测分析,具体为通过组合模型的预测结果,对智慧园区内的各类能源使用情况进行智能调节,使能源得到充分利用。
进一步地,在步骤S7中,所述构建数字孪生模型是通过所述数据采集构建物理层,通过所述数据预处理和主成分分析构建孪生层,通过所述构建随机森林预测模型和构建反向传播神经网络预测模型构建应用层,通过所述组合模型预测分析构建连接层,并通过构建所述物理层、孪生层、应用层和连接层,得到数字孪生模型。
本发明提供的一种基于数字孪生技术的智慧园区能源管理系统,包含数据采集模块、数据预处理模块、主成分分析模块、构建随机森林预测模型模块、构建反向传播神经网络预测模型模块、组合模型预测分析模块和构建数字孪生模型模块;
所述数据采集模块实时采集智慧园区内传感器、智能电表、周围环境以及设备状态的数据,得到园区管理原始数据集,并将园区管理原始数据集发送至数据预处理模块;
所述数据预处理模块接收来自数据采集模块的园区管理原始数据集,对园区管理原始数据集进行异常值处理操作,得到高维数据集,并将高维数据集发送至主成分分析模块;
所述主成分分析模块接收来自数据预处理模块的高维数据集,通过对高维数据集进行主成分分析操作,得到低维数据集,并将低维数据集发送至构建随机森林预测模型模块和构建反向传播神经网络预测模型模块;
所述构建随机森林预测模型模块接收来自主成分分析模块的低维数据集,对低维数据集进行数据集划分,划分的训练数据集进行分类,测试数据集进行能耗预测,得到随机森林预测模型的能耗预测结果,并将随机森林预测模型的能耗预测结果发送至组合模型预测分析模块;
所述构建反向传播神经网络预测模型模块接收来自主成分分析模块的低维数据集,对低维数据集进行数据集划分操作,划分训练数据集进行模型训练,测试数据集进行模型能耗预测,得到反向传播神经网络预测模型的能耗预测结果,并将反向传播神经网络预测模型的能耗预测结果发送至组合模型预测分析模块;
所述组合模型预测分析模块接收来自构建随机森林预测模型模块的能耗预测结果和构建反向传播神经网络预测模型模块的能耗预测结果,计算随机森林预测模型和反向传播神经网络预测模型的权重,进行组合操作,得到组合能耗预测结果,输出组合能耗预测结果;
所述构建数字孪生模型模块通过数据采集模块构建物理层,通过数据预处理模块和主成分分析模块构建孪生层,通过构建随机森林预测模型模块和构建反向传播神经网络预测模型模块构建应用层,通过组合模型预测分析构建连接层,并通过构建物理层、孪生层、应用层和连接层,得到数字孪生模型模块。
采用上述方案本发明取得的有益效果如下:
(1)针对采集数据中包含异常值,致使后续数据处理失真的问题,本发明采用异常值检测算法,准确识别园区管理原始数据中与其他数据相距较远的异常值,去除异常值,提高分析效率。
(2)针对采集的数据特征冗余、复杂性高且不利于模型构建的问题,本发明采用主成分分析算法计算协方差矩阵的特征值和特征向量,找到数据集中最重要的特征,将高维数据集映射到低维空间,减少冗余并保留关键性和有区分度的特征,方便构建模型。
(3)针对单一模型结构复杂,训练容易陷入局部最优解,导致预测模型的准确性和可扩展性较差的问题,本发明采用随机森林预测模型和反向传播神经网络预测模型组合的方法,全面处理特征信息,提高特征信息的表达能力和模型的准确率。
(4)针对反向传播神经网络预测模型的模型权重过高,导致模型过拟合的问题,本发明采用正则化来惩罚过大的权重,限制模型的复杂度,避免过拟合,提高模型的泛化能力。
附图说明
图1为本发明提供的一种基于数字孪生技术的智慧园区能源管理方法的流程示意图;
图2为本发明提供的一种基于数字孪生技术的智慧园区能源管理方系统的结构框图;
图3为步骤S2的流程示意图;
图4为步骤S3的流程示意图;
图5为步骤S4的流程示意图;
图6为步骤S5的流程示意图;
图7为步骤S6的流程示意图。
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例;基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
在本发明的描述中,需要理解的是,术语“上”、“下”、“前”、“后”、“左”、“右”、“顶”、“底”、“内”、“外”等指示方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
实施例一,参阅图1,本发明提供的一种基于数字孪生技术的智慧园区能源管理方法,该方法包括以下步骤:
步骤S1:数据采集;
步骤S2:数据预处理;
步骤S3:主成分分析;
步骤S4:构建随机森林预测模型;
步骤S5:构建反向传播神经网络预测模型;
步骤S6:组合模型预测分析;
步骤S7:构建数字孪生模型。
实施例二,参阅图1,该实施例基于上述实施例,在步骤S1中,所述数据采集,具体为通过实时采集智慧园区内传感器、智能电表、周围环境以及设备状态的数据,得到园区管理原始数据集T
实施例三,参阅图1和图3,该实施例基于上述实施例,在步骤S2中,所述数据预处理,具体为通过对所述园区管理原始数据集T
步骤S21:构建样本数据集,具体为从所述园区管理原始数据集T
;
式中,X表示样本数据集,x
步骤S22:构造观测值向量,其中包含m个元素,所用公式如下:
;
式中,X
步骤S23:计算样本均值向量,具体为通过对观测值向量进行均值运算,得到样本均值向量
;
式中,
步骤S24:计算样本协方差矩阵,具体为通过计算样本中每个维度的协方差,得到样本协方差矩阵Q,所用公式如下:
;
式中,Q表示样本协方差矩阵,
步骤S25:通过对观测值向量和样本均值向量进行距离运算,得到样本间马氏距离Z,所用公式如下:
;
式中,Z表示样本间马氏距离,Q表示样本协方差矩阵,
步骤S26:去除异常值,具体为通过设置阈值T,对比样本间马氏距离Z和阈值T的大小,删除大于阈值T的样本数据,得到高维数据集T
通过执行上述操作,针对采集数据中包含异常值,致使后续数据处理失真的问题,本发明采用异常值检测算法,准确识别园区管理原始数据中与其他数据相距较远的异常值,去除异常值,提高分析效率。
实施例四,参阅图1和图4,该实施例基于上述实施例,在步骤S3中,所述主成分分析,具体为通过对所述高维数据集T
步骤S31:通过构造高维数据集T
;
式中,R表示协方差矩阵,n表示样本数量,
步骤S32:计算特征值和特征向量,具体为通过对协方差矩阵R进行奇异值矩阵分解操作,得到特征值λ
步骤S321:对协方差矩阵进行奇异值矩阵分解,所用公式如下:
;
式中,U表示R的左奇异向量矩阵,S表示对角矩阵,V
步骤S322:计算协方差矩阵的特征值,所用公式如下:
;
式中,λ
步骤S323:计算协方差矩阵的特征向量,所用公式如下:
;
式中,w
步骤S33:根据特征值大小进行排序,通过选择前z个最大特征值,进行对角矩阵截断,使其余特征值置0,得到截断对角矩阵
步骤S34:通过将高维数据集中的特征值和特征向量映射到低维数据集,得到低维数据集T
通过执行上述操作,针对采集的数据特征冗余、复杂性高且不利于模型构建的问题,本发明采用主成分分析算法计算协方差矩阵的特征值和特征向量,找到数据集中最重要的特征,将高维数据集映射到低维空间,减少冗余并保留关键性和有区分度的特征,方便构建模型。
实施例五,参阅图1和图5,该实施例基于上述实施例,在步骤S4中,所述构建随机森林预测模型,具体为通过对所述低维数据集T
步骤S41:将低维数据集T
步骤S42:随机抽样,具体为通过对训练数据集进行随机抽样操作,每个训练子集抽取t个样本数据,抽取k次,得到k个训练子集,具体步骤如下:
步骤S421:从训练数据集中有放回的随机抽取t个样本数据,构建一个训练子集;
步骤S422:重复步骤S521,抽取k次,得到k个训练子集,保证每个子集都包含t个样本数据;
步骤S43:构建决策树,具体为基于k个不同的训练子集构建k棵决策树,生成一棵决策树的步骤如下:
步骤S431:以训练子集W被特征C划分为例,所述特征C包括特征向量和各种特征值;
步骤S432:计算训练子集W的信息熵,所用公式如下:
;/>
式中,H(W)表示训练子集W的信息熵,i表示分类标签数目,p
步骤S433:计算特征C对训练子集W的条件熵,具体为通过特征C对训练子集W进行划分操作,划分成m份,得到特征C对训练子集W的条件熵,所用公式如下:
;
式中,H(W|C)表示特征C对训练子集W的条件熵,p
步骤S434:计算信息增益,具体为通过选择具有最大信息增益的特征变量及阈值进行划分操作,并不断对训练子集进行拆分,直至所有训练子集数据属于同一类别或无法再进行划分,得到决策树的分类结果,所用公式如下:
;
式中,G(W,C)表示特征值C对训练子集W的信息增益,H(W)表示训练子集W的信息熵,H(W|C)表示特征C对训练子集W的条件熵;
步骤S44:计算决策树的分类权重,所用公式如下:
;
式中,
步骤S45:重新生成,具体为设置权重阈值,对分类权重低于权重阈值的决策树随机选取m个样本数据重新生成,直到拥有k个分类权重不低于权重阈值的决策树;
步骤S46:构建随机森林预测模型,具体为通过对测试数据集进行分类操作使测试集遍历k棵不同的决策树,得到随机森林预测模型的能耗预测结果p
实施例六,参阅图1和图6,该实施例基于上述实施例,在步骤S5中,所述构建反向传播神经网络预测模型,具体为通过对所述低维数据集T
步骤S51:将低维数据集T
步骤S52:构建训练数据集T={x
;
式中,x
步骤S53:采用sigmoid激活函数进行激活,所用公式如下:
;
式中,f(x)表示激活函数,e表示指数运算;
步骤S54:计算隐藏层神经元n的输出,所用公式如下:
;
式中,O
步骤S55:计算隐藏层的残余误差,所用公式如下:
;
式中,E表示隐藏层的残余误差,O
步骤S56:通过反向传播算法的梯度法来实现权重和阈值的更新,得到最优权重和阈值,具体包括以下步骤:
步骤S561:计算输入层到隐藏层的连接权重,所用公式如下:
;
式中,ω
步骤S562:计算L1正则化后的权重,具体为向目标函数添加权重的绝对值来惩罚较大权重,所用公式如下:
;
式中,
步骤S563:计算L2正则化后的权重,具体为向目标函数添加权重的平方来惩罚较大权重,所用公式如下:
;
式中,
步骤S564:更新隐藏层的神经元阈值,所用公式如下:
;
式中,t表示迭代更新的时间,b
步骤S565:计算隐藏层到输出层的连接权重,所用公式如下:
;
式中,c
步骤S566:更新输出层的神经元阈值,所用公式如下:
;
式中,b
步骤S57:构建反向传播神经网络预测模型,具体为通过训练数据集输出最优权重和阈值,测试数据集遍历反向传播神经网络预测模型,得到反向传播神经网络预测模型的能耗预测结果p
通过执行上述操作,针对反向传播神经网络预测模型的模型权重过高,导致模型过拟合的问题,本发明采用正则化来惩罚过大的权重,限制模型的复杂度,避免过拟合,提高模型的泛化能力。
实施例七,参阅图1和图7,该实施例基于上述实施例,在步骤S6中,所述组合模型预测分析,具体为通过计算随机森林预测模型和反向传播神经网络预测模型的权重,进行组合操作,得到组合能耗预测结果,具体包括以下步骤:
步骤S61:计算随机森林预测模型和反向传播神经网络预测模型的方差,所用公式如下:
;
式中,θ
步骤S62:计算随机森林预测模型的动态权重,所用公式如下:
;
式中,ω
步骤S63:计算反向传播神经网络预测模型的动态权重,所用公式如下:
;
式中,ω
步骤S64:组合随机森林预测模型和反向传播神经网络预测模型的能耗预测结果,所用公式如下:
;
式中,p表示组合随机森林预测模型和反向传播神经网络预测模型的能耗预测结果,p
步骤S65:组合模型预测分析,具体为通过组合模型的预测结果,对智慧园区内的各类能源使用情况进行智能调节,使能源得到充分利用。
通过执行上述操作,针对单一模型结构复杂,训练容易陷入局部最优解,导致预测模型的准确性和可扩展性较差的问题,本发明采用随机森林预测模型和反向传播神经网络预测模型组合的方法,全面处理特征信息,提高特征信息的表达能力和模型的准确率。
实施例八,参阅图1,该实施例基于上述实施例,在步骤S7中,所述构建数字孪生模型是通过所述数据采集构建物理层,通过所述数据预处理和主成分分析构建孪生层,通过所述构建随机森林预测模型和构建反向传播神经网络预测模型构建应用层,通过所述组合模型预测分析构建连接层,并通过构建所述物理层、孪生层、应用层和连接层,得到数字孪生模型。
实施例九,参阅图2,该实施例基于上述实施例,本发明提供的一种基于数字孪生技术的智慧园区能源管理系统,包含数据采集模块、数据预处理模块、主成分分析模块、构建随机森林预测模型模块、构建反向传播神经网络预测模型模块、组合模型预测分析模块和构建数字孪生模型模块;
所述数据采集模块实时采集智慧园区内传感器、智能电表、周围环境以及设备状态的数据,得到园区管理原始数据集,并将园区管理原始数据集发送至数据预处理模块;
所述数据预处理模块接收来自数据采集模块的园区管理原始数据集,对园区管理原始数据集进行异常值处理操作,得到高维数据集,并将高维数据集发送至主成分分析模块;
所述主成分分析模块接收来自数据预处理模块的高维数据集,通过对高维数据集进行主成分分析操作,得到低维数据集,并将低维数据集发送至构建随机森林预测模型模块和构建反向传播神经网络预测模型模块;
所述构建随机森林预测模型模块接收来自主成分分析模块的低维数据集,对低维数据集进行数据集划分,划分的训练数据集进行分类,测试数据集进行能耗预测,得到随机森林预测模型的能耗预测结果,并将随机森林预测模型的能耗预测结果发送至组合模型预测分析模块;
所述构建反向传播神经网络预测模型模块接收来自主成分分析模块的低维数据集,对低维数据集进行数据集划分操作,划分训练数据集进行模型训练,测试数据集进行模型能耗预测,得到反向传播神经网络预测模型的能耗预测结果,并将反向传播神经网络预测模型的能耗预测结果发送至组合模型预测分析模块;
所述组合模型预测分析模块接收来自构建随机森林预测模型模块的能耗预测结果和构建反向传播神经网络预测模型模块的能耗预测结果,计算随机森林预测模型和反向传播神经网络预测模型的权重,进行组合操作,得到组合能耗预测结果,输出组合能耗预测结果;
所述构建数字孪生模型模块通过数据采集模块构建物理层,通过数据预处理模块和主成分分析模块构建孪生层,通过构建随机森林预测模型模块和构建反向传播神经网络预测模型模块构建应用层,通过组合模型预测分析构建连接层,并通过构建物理层、孪生层、应用层和连接层,得到数字孪生模型模块。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
以上对本发明及其实施方式进行了描述,这种描述没有限制性,附图中所示的也只是本发明的实施方式之一,实际的结构并不局限于此。总而言之如果本领域的普通技术人员受其启示,在不脱离本发明创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结构方式及实施例,均应属于本发明的保护范围。