基于布尔满足的考虑资源共享高层次综合调度方法
文献发布时间:2024-04-18 20:01:23
技术领域
本发明属于集成电路设计高层次综合技术领域,具体涉及一种基于布尔满足的考虑资源共享高层次综合调度方法。
背景技术
现有技术公开了随着集成电路的诞生与不断演进,到目前为止,现场可编程门阵列(FPGA)已经可以在满足提供足够数量可编程逻辑门电路数量基础上,解决专用集成电路(ASIC)中的半定制电路问题。尽管如此,FPGA所能够支持的可编程电路抽象级别也同样具有局限性。随着工艺技术水平的不断提高和应用程序复杂性的不断增加,设计方法和自动化工具亟需转向更高的抽象级别。因此,提高抽象层次和加速综合过程和验证过程的自动化将成为设计过程演进的关键因素。
据报道,高层次综合(High Level Synthesis,HLS)的历史比FPGA要长得多[1],所以早期的HLS工具[2][3][4]大多是针对ASIC设计的,但是在这样的应用背景下,HLS作为更高抽象层级的电路设计辅助工具开始在可编程电路领域得到应用。高层次综合主要分为配置、调度、绑定和电路生成环节,其中研究最为广泛、算法最多的应当属于调度(Scheduling)环节,该环节将直接决定着硬件电路的结构、资源分配、电路延时、松弛分布情况等,是高层次综合中一个至关重要的步骤。
传统的HLS调度算法通过限定特定类型资源数量的方式将资源共享约束引入调度之中,列表调度[5]和力度定向调度[6]是较早的启发式调度方法;基于差分约束系统的调度算法[7]将调度问题转化为了差分约束系统表示下的整数线性规划问题,该方法在多项式时间内可以解调度问题,然而由于使用启发式方法解决资源约束问题,因此仍然获得的是次优解;BULB算法[8]是一种基于分支界定调度算法,通过利用上下边界信息剪枝设计探索空间有效提高资源约束问题下调度问题的搜索速度,但是可能会收敛至次优解。
高层次综合调度过程中并没有显示地考虑功能单元的共享问题。传统算法将资源共享作为先验信息来进行求解,可能会导致次优性的传播。结合基于差分约束系统和布尔满足调度算法[9]有效编码了资源约束问题,并通过冲突学习的方式迭代寻找资源约束问题最优解,然而该方法将资源共享作为了先决条件来进行求解,在一定程度上限制了设计空间的大小,仍然存在未探索的设计空间。
基于现有技术的现状,本申请的发明人拟提供一种基于布尔满足的考虑资源共享高层次综合调度方法。
与本申请相关的参考文献有:
[1].J.Cong,B.Liu,S.Neuendorffer,J.Noguera,K.Vissers,and Z.Zhang,“High-level synthesis for fpgas:From prototyping to deployment,”IEEETransactions on Computer-Aided Design of Integrated Circuits and Systems,vol.30,no.4,pp.473–491,2011.
[2].H.Ren,“A brief introduction on contemporary high-levelsynthesis,”in 2014IEEE International Conference on IC Design Technology,2014,pp.1–4.
[3].C.Pilato and F.Ferrandi,“Bambu:A modular framework for the highlevel synthesis of memory-intensive applications,”in 2013 23rd InternationalConference on Field programmable Logic and Applications,2013,pp.1–4.
[4].A.Canis,J.Choi,M.Aldham,V.Zhang,A.Kammoona,T.Czajkowski,S.D.Brown,and J.H.Anderson,“Legup:An open-source high-level synthesis toolfor fpga-based processor/accelerator systems,”ACM Trans.Embed.Comput.Syst.,vol.13,no.2,2013.
[5].R.Jain,A.Mujumdar,A.Sharma,and H.Wang,“Empirical evaluation ofsome high-level synthesis scheduling heuristics,”in 28th ACM/IEEE DesignAutomation Conference,1991,pp.686–689.
[6].S.Dai,M.Tan,K.Hao,and Z.Zhang,“Flushingenabled loop pipeliningfor high-level synthesis,”in 2014 51st ACM/EDAC/IEEE Design AutomationConference(DAC),2014,pp.1–6.
[7].J.Cong and Z.Zhang,“An efficient and versatile schedulingalgorithm based on sdc formulation,”in 2006 43rd ACM/IEEE Design AutomationConference,2006,pp.433–438.
[8].M.Chen,S.Huang,G.Pu,and P.Mishra,“Branch-and-bound style resourceconstrained scheduling using efficient structureaware pruning,”in 2013IEEEComputer Society Annual Symposium on VLSI(ISVLSI),2013,pp.224–229.
[9].S.Dai,G.Liu,and Z.Zhang,“A scalable approach to exact resource-constrained scheduling based on a joint sdc and sat formulation,”inProceedings of the 2018ACM/SIGDA International Symposium on Field-Programmable Gate Arrays,ser.FPGA ’18,2018,p.137–146.
[10].W.Jiang,Z.Zhang,M.Potkonjak,and J.Cong,“Scheduling with integertime budgeting for low-power optimization,”in 2008Asia and South PacificDesign Automation Conference,2008,pp.22–27.
[11].E.Abrah′am and G.Kremer,“Smt solving for arithmetic the-′ories:Theory and tool support,”in 2017 19th International Symposium on Symbolic andNumeric Algorithms for Scientific Computing(SYNASC),2017,pp.1–8.
[12].P.Kov′acs,“Minimum-cost flow algorithms:an experimentalevaluation,”Optimization Methods and Software,vol.30,no.1,pp.94–127,2015.
[13].V.Faychuk,O.Lavriv,M.Klymash,V.Zhebka,and O.Shpur,“Investigationof the bellman-ford algorithm enhanced for remote execution,”in 2019 3rdInternational Conference on Advanced Information and CommunicationsTechnologies(AICT),2019,pp.204–208.
[14].R.Jaillet,“Network flows:Theory,algorithms,and applicationsbyravindra k.ahuja;thomas l.magnanti;james b.orlin,”Transportation Science,vol.28,no.4,pp.354–356,1994.
[15].N.Een,A.Mishchenko,and N.Amla,“A single-instance incremental satformulation of proof-and counterexample-based abstraction,”in Formal Methodsin Computer Aided Design,2010,pp.181–188.
[16].B.Dezs″o,A.J¨uttner,and P.Kov′acs,“Lemon–an open source c++graphtemplate library,”Electronic Notes in Theoretical Computer Science,vol.264,no.5,pp.23–45,2011,proceedings of the Second Workshop on GenerativeTechnologies(WGT)2010.。
发明内容
本发明的目的是基于现有技术的现状,提供一种基于布尔满足的考虑资源共享问题的高级综合调度方法。
本发明为了缩小搜索空间,提出了多种剪枝策略,同时,提出了一种基于最小代价网络流的独立调度算法来降低在整个设计空间探索过程中需要被多次调用的独立调度算法的时间复杂度;本发明基于布尔满足的考虑资源共享约束调度架构,可以对部分具有更高电路性能要求的行为级设计,提供具有更高的最高可用时钟频率、以及更少资源利用率的寄存器传输级电路实现方案。
为了达到上述目的,本发明的技术方案是:首先根据行为级描述编译生成的数据流图以及高层次综合的配置,构建对应的有向无环图以及基本约束边;然后根据具有共享约束的资源数量,通过迭代调用布尔满足求解器和独立调度程序,寻找出最优的资源共享分组和资源示例绑定结果;最后将寻找到的最优资源共享约束加入到有向无环图中,执行最终的调度,将计算得到的调度结果输出,供高层次综合工具的后续链路使用来生成对应的寄存器传输级电路。
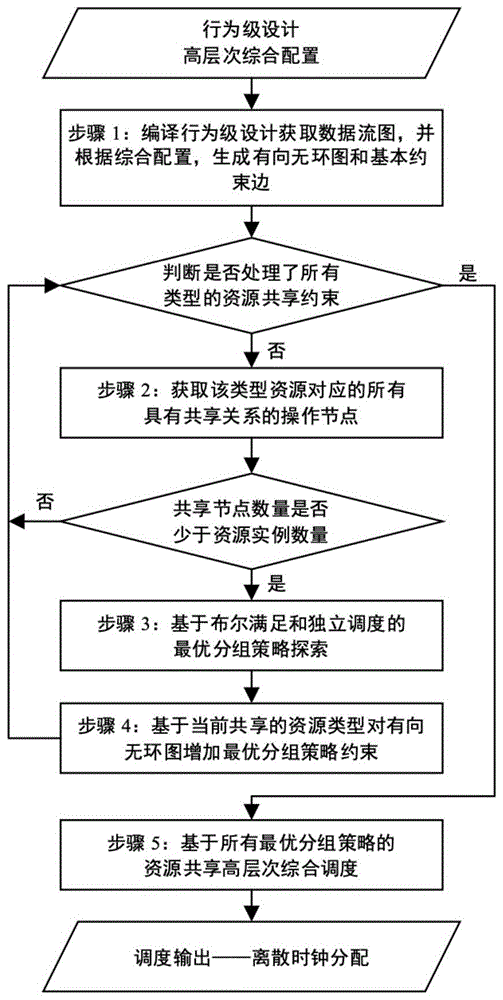
具体的,本发明提供了一种基于布尔满足的考虑资源共享问题的高级综合调度方法,如图1所示,其步骤如下:
步骤1:读取C/C++语言描述的行为级设计、高层次综合配置文件,通过编译器获取行为级设计对应的数据流图(Data Flow Graph,DFG),遍历DFG并生成网络流算法对应是数据结构有向无环图(Directed Acyclic Graph,DAG)G=(V,E),同时根据基础节点约束关系,生成DAG中的约束边E;
步骤2:针对资源类型为r的资源共享约束,从DFG中获取该类型资源对应的操作节点集合
步骤3:通过布尔满足求解寻找可行分组策略F
分步骤3.1:根据资源类型为r的操作节点数量n,初始化表示节点
其中
上式为“与或”表达式,需要转化成为满足布尔求解器使用的合取范式形式,即就是“或与”表达式;根据布尔代数中的对偶定理,可以证明真值边界约束可以表示为:
将上述约束增加到布尔求解器的初始约束中;
分步骤3.2:使用布尔求解器对上述布尔问题进行求解,获得布尔变量赋值RS
分步骤3.3:对资源约束分组情况F
分步骤3.4:迭代执行分步骤3.2、3.3直至遍历整个设计空间,即就是不存在新的资源共享分组;
步骤4:根据基于MCNF的独立调度算法评估得到的最优分组策略,向整个设计的DAG中增加类型为r的资源实例所对应的资源共享约束;通过高层次综合配置文件,获取资源共享约束信息,转到下一个类型r
步骤5:完成所有类型资源实例所对应的资源共享约束构建后,对增加资源共享约束的DAG执行独立调度,并将调度结果—节点执行时间的离散时钟分配,进行输出,供高层次综合工具的后续链路进行执行,最终生成寄存器传输级电路设计文件。
应用本发明的方法,可以对部分具有更高电路性能要求的行为级设计,提供具有更高最高可用时钟频率、和更少资源利用率的寄存器传输级电路实现方案。
本发明具有如下优点:
(1)SRS调度框架考虑资源共享约束关系,进一步扩大了高层次综合的设计空间;
(2)实验结果表明,针对部分设计要求较高的电路,可以获得资源实例利用率更低、最高时钟频率更高的RTL级电路设计。
附图说明
图1为本发明基于布尔满足的考虑资源共享高层次综合调度方法的流程图。
图2为根据资源共享节点构建布尔变量示意图。
图3为迭代进行布尔求解探索资源共享分组与增加约束子句剪枝过程示意图。
图4为测试用例下基于最小代价网络流独立调度算法和基于差分约束系统整数线性规划独立调度算法的运行时间以及加速比实验结果图。
具体实施方式
为使本发明的上述目的、特征和优点能更加明显易懂,下面通过具体的实例测试进一步说明。
实施例1
本发明是在Linux操作系统上基于C++语言实现的。
本发明采用开源布尔满足求解器MiniSat-2.2[15]来求解资源共享约束下的布尔满足问题,同时,本发明使用基于最小代价网络流的独立调度算法来降低需要多次调用、用来评估资源共享策略最优性的独立调度过程的时间复杂度,所采用的是开源C++网络流算法运行库LEMON[16]。
本发明应用基于最小代价网络流算法(MCNF)加速独立调度过程,使用测试用例,分别测试MCNF算法和基于SDC[7]调度算法的运行时间,获得如图4所示的结果。根据图4,相对于SDC算法而言MCNF算法可以获得最高33倍的加速比,平均情况下MCNF算法也可以获得5倍左右的加速比,因此对于降低整体调度的时间复杂度,MCNF算法具有一定的优势。
应用本发明到高层次综合框架中的调度部分,并对几个具体测例运行并生成Verilog文件,即就是寄存器传输级电路设计文件。然后,通过Quartus II软件工具,以10ns为目标时钟频率、以Altera Cyclone V为目标FPGA进行综合和实现,获得实现后的时序报告和资源利用率报告,获得最高可行时钟频率和各种FPGA资源的利用率。同时,将本发明(SRS)所得到的结果与传统调度算法SDC[7]和最新方法SDS[9]所得到的结果进行对比,实际对比结果如下表所示:
表1行为级设计综合实现的时钟频率、资源利用率对比表
表1中各参数含义:
(1)操作节点数:构建出的DAG中节点数目(其中多个参数表示该电路具有多个主要模块);
(2)指令数目:编译获得的DFG中的指令节点数目;
(3)ALM:FPGA中的自适应逻辑模块(Adaptive Logic Modules)使用情况;
(4)LUT:FPGA中的查找表(Look Up Table)使用情况;
(5)Reg:FPGA中的片上寄存器(Register)使用情况;
(6)BRAM:FPGA中的块随机存储器(Block-RAM)使用情况;
(7)RAM:FPGA中的随机存储器(Random Access Memory)使用情况;
(8)DSP:FPGA中的数字信号处理(Digital Signal Process)模块的使用情况。
上述实际测试表明,本发明基于布尔满足的考虑资源共享高层次综合调度方法,可以对部分具有更高电路性能要求的行为级设计,提供具有更高最高可用时钟频率、和更少资源利用率的寄存器传输级电路实现方案。