基于消息队列的数据流处理检查点文件存储的方法及装置
文献发布时间:2023-06-19 09:30:39
技术领域
本发明涉及分布式流式处理技术和分布式存储系统领域,尤其涉及一种基于消息队列的数据流处理检查点文件存储的方法及装置。
背景技术
当前流行的流式处理框架中,对于持有状态运算的聚合式持续查询,需要跨批次的状态支持,其运算中间状态是以检查点文件的形式存储于可靠存储之中的。检查点文件相比于通用的文件存储具有很多独特的性质,以Structured Streaming(Spark2.0以后的提出的流式计算框架)为例,Structured Streaming的流式处理引擎是以持续不断地驱动每个微批次的形式执行的,其检查点文件默认采用兼容HDFS(Hadoop Distributed FileSystem,Hadoop分布式文件系统)接口的存储系统存储。第一,其应用场景为写多读少,在流式应用执行过程中,检查点文件会以微批次的频率源源不断地向文件系统中写入,而只有在任务中断(主动中断或任务因故障中断)恢复时,检查点文件才会被读取;第二,检查点文件具有单个文件小、数量多的特点;第三,检查点文件存储的内容为每个批次的状态数据,经过各自系统实现的编码方式进行存储,其内容不会被更改;第四,Structured Streaming启动自动删除机制,默认保存最近100个批次的检查点数据,因此对于检查点的删除操作来讲,是以一个逻辑文件集合为单位进行删除的。
综合以上特点,对于上述大量流式小文件存储的场景,使用HDFS会造成大量的资源开销,因此使用轻量级的消息队列作为检查点文件存储系统可作为优化该问题的替代方案。
发明内容
本发明旨在至少解决现有技术或相关技术中存在的技术问题之一。
为此,本发明的第一方面提出一种基于消息队列的数据流处理检查点文件存储的方法。
本发明的第二方面提出一种基于消息队列的数据流处理检查点文件存储的装置。
有鉴于此,本发明提供一种基于消息队列的数据流处理检查点文件存储的方法,包括以下步骤:
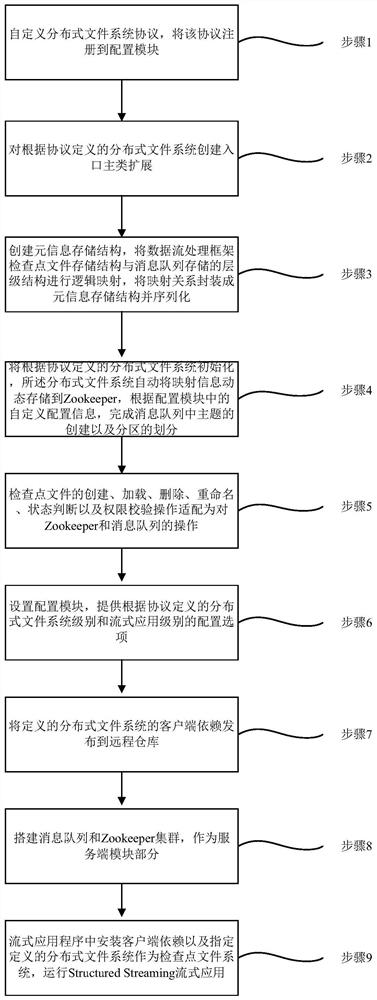
步骤1,自定义分布式文件系统协议,将该协议注册到配置模块;
步骤2,对根据协议定义的分布式文件系统创建入口主类扩展;
步骤3,创建元信息存储结构,将数据流处理框架检查点文件存储结构与消息队列存储的层级结构进行逻辑映射,将映射关系封装成元信息存储结构并序列化;
步骤4,将根据协议定义的分布式文件系统初始化,所述分布式文件系统自动将映射信息动态存储到Zookeeper,根据配置模块中的自定义配置信息,完成消息队列中主题的创建以及分区的划分;
步骤5,检查点文件的创建、加载、删除、重命名、状态判断以及权限校验操作适配为对Zookeeper和消息队列的操作;
步骤6,设置配置模块,提供根据协议定义的分布式文件系统级别和流式应用级别的配置选项;
步骤7,将定义的分布式文件系统的客户端依赖发布到远程仓库;
步骤8,搭建消息队列和Zookeeper集群,作为服务端模块部分;
步骤9,流式应用程序中安装客户端依赖以及指定定义的分布式文件系统作为检查点文件系统,运行Structured Streaming流式应用。
2.根据权利要求1所述的一种基于消息队列的数据流处理检查点文件存储的方法,其特征在于,步骤3中,元信息存储结构的设计方法具体包括以下步骤:
步骤3.1,对于路径基础元信息存储结构,包含name、owner、group、mode、lastModifiedTime信息;
步骤3.2,对于文件附加元信息存储结构,包含文件操作需要的contentHash、contentLength以及在消息队列中表示消息位置的offset信息。
步骤3.3,对元信息结构进行序列化与反序列化,采用开源的Zookeeper客户端Curator与Zookeeper进行交互。
3.根据权利要求1所述的一种基于消息队列的数据流处理检查点文件存储的方法,其特征在于,步骤5中,检查点文件的创建、加载、删除、重命名、状态判断以及权限校验操作包括以下步骤:
步骤5.1,检查点文件创建包括:自定义文件输出流,创建缓存结构,上层应用执行写入操作对应于向缓冲区中填充数据,在关闭输出流的操作中,将该缓冲区中内容封装成消息队列的消息格式,并且创建元信息单元,以事务性操作将元信息单元存入Zookeeper和将检查点文件数据消息生产到消息队列服务端;
步骤5.2,检查点文件的加载包括:自定义文件输入流,创建缓存结构,在上层应用初始化输入流的操作对应于获取对应检查点文件的元信息以及将消息消费到缓存结构,上层应用执行读取操作对应于对缓冲结构的读取;
步骤5.3,检查点文件数据的删除策略通过配置消息队列服务端的消息过期时间完成,根据不同类型的检查点文件进行针对化配置。检查点文件元信息的删除操作对应Zookeeper对于对应节点的删除操作;
步骤5.4,对于检查点文件重命名、状态判断以及权限校验操作对应于对Zookeeper对应节点的修改、查询和判断操作。
4、根据权利要求1所述的一种基于消息队列的数据流处理检查点文件存储的方法,其特征在于,步骤6中,设置配置模块的方法具体包括以下步骤:
步骤6.1,对根据协议定义的分布式文件系统级别的配置功能复用HDFS通用配置文件,为该配置文件添加配置选项,将根据协议定义的分布式文件系统实现的入口主类注册进去;
步骤6.2,提供数据流流式应用级别的配置选项,包括端口号、应用任务带状态操作符个数、数据来源个数、流式应用运行并行度以及运行日志路径等个性化配置。
本发明第二方面提供了一种基于消息队列的数据流处理检查点文件存储的装置,包括:
集成模块,用于集成数据流处理框架;
配置模块,用于提供根据协议定义的分布式文件系统级别和配置流式应用级别的选项;
元数据模块,用于自定义元信息存储结构和将数据流处理框架检查点文件存储结构与消息队列存储的层级结构进行逻辑映射;
数据模块,用于实现对检查点文件数据传输功能;
文件操作模块,用于实现对检查点文件操作的功能;
服务端模块,用于存储检查点文件数据以及元数据。
优选地,数据模块实现对检查点文件数据传输功能,包括:数据输出模块和数据输入模块。
优选地,数据输出模块用于流式应用程序发起检查点文件的创建,输出模块创建对应的输出流,上游应用通过该输出流写入文件数据。
优选地,数据输入模块用于流式应用程序发起检查点文件的加载,输入模块创建对应的输入流,上游应用通过该输入流读取文件数据。
优选地,文件操作模块实现对检查点文件的相关操作功能,检查点文件重命名、状态判断以及权限校验操作对应于对Zookeeper的操作,检查点文件数据的删除策略通过配置消息队列服务端的消息过期时间完成。
优选地,服务端模块存储检查点文件数据以及元数据,包括:
文件数据存储以复用消息队列服务端的形式,检查点文件映射为消息格式,提供检查点文件的操作服务。
文件元数据存储以复用Zookeeper服务端的形式实现,以Zookeeper先天的目录树结构存储检查点文件结构,提供检查点文件元信息的存储服务。
由上述技术方案可知,本发明的有益效果在于:基于消息队列的数据流处理检查点文件存储装置,将能够将上游流式应用对检查点文件的操作准确地转换到对消息队列的操作处理框架之上,从而有效提高流式计算任务的处理效率。本发明能够提高特定复杂流式应用检查点文件存储效率和流式计算的执行效率,减少微批次的执行时间。本发明设计合理,易于使用,具有较高的通用性和实用价值。
附图说明
图1为本发明实施例的基于消息队列的数据流处理检查点文件存储的方法的流程图;
图2为本发明实施例的基于消息队列的数据流处理检查点文件存储装置元信息存储模型UML图(标准建模语言图);
图3为本发明实施例的检查点存储结构与消息队列Kafka存储模型的逻辑结构示意图;
图4为本发明实施例的基于消息队列的数据流处理检查点文件存储装置的总体架构图;
图5为基于消息队列的基于消息队列的数据流处理检查点文件存储装置的连接关系示意图。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
本实施例的软硬件环境为:包含4台主机的服务器集群,其中单个服务器主机硬件为八核2.10Ghz处理器,内存16G,软件为Ubuntu 16.04.6LTS操作系统,安装的分布式系统以及对应版本分别为spark 2.4.3、kafka_2.11-2.1.0、zookeeper 3.4.10。
本发明第一方面提供一种基于消息队列的数据流处理检查点文件存储的方法。
实施例1:如图1至图3所示,本发明提出一种基于消息队列的数据流处理检查点文件存储的方法,具体实施步骤如下:
步骤1,自定义分布式文件系统协议,协议格式为mfs://
所述基于消息队列Kafka的分布式文件系统命名为MFS(Message based FileSystem),本实施例中该协议具体格式为mfs://192.168.56.100:8888/checkpointRoot,注册到配置模块中复用自Hadoop(支持数据密集分布式应用程序并以Apache 2.0许可协议发布的开源软件框架)的core-site.xml,加入如下配置项:
其中mfs.client.MfsFileSystem表示MFS的入口类。
步骤2,使用HCFS(Hadoop Compatible File System,兼容Hadoop规范的文件系统)机制,自定义分布式文件系统MFS,对Hadoop提供的文件操作系统接口进行扩展。具体实现方法为:
创建MFS入口主类mfs.client.MfsFileSystem扩展org.apache.hadoop.fs.FileSystem,该方式以HCFS机制作为技术支持,HCFS机制采用Java的SPI(Service Provider Interface,Java提供的服务发现机制)的设计思想,向上层应用提供统一接口,下层服务提供不同方式实现。
通过以上两个步骤,上游应用利用反射机制,通过动态获取的配置模块的MFS层级的配置,进而路由到MFS入口主类mfs.client.MfsFileSystem,将该入口主类进行加载,完成与MFS集成的关键步骤。
步骤3,创建元信息存储结构,将Structured Streaming检查点文件存储结构与Kafka存储的层级结构进行逻辑映射,将映射关系封装成元信息存储结构写入到Zookeeper中。元信息存储结构的设计方法具体包括以下步骤:
步骤3.1,对于路径基础元信息存储结构PathInfo,各字段含义如下:长整数类型的serialVersionUID表示序列化类的版本标识,布尔类型的isDirectory表示该路径是否为目录,字符串类型的name表示全路径名,字符串类型的owner表示所属用户、字符串类型的group表示所属用户组、短整数类型的mode表示路径权限信息、长整数类型的lastModifiedTime表示最后修改时间。
步骤3.2,对于文件附加元信息存储结构FileInfo,它是对PathInfo表示文件的补充,包括:长整数类型的serialVersionUID表示序列化类的版本标识,文件操作需要的字符串类型的contentHash(表示文件内容的hash值,用于完整性校验)、长整数类型的contentLength(表示文件的大小信息)以及在Kafka中表示消息位置的长整数类型的offset这些必要信息。PathInfo与FileInfo的依赖关系如图2所示,它们均实现自Java提供的用于序列化的接口java.io.Serializable。
步骤3.3,使用Apache Commons Lang(Apache提供的标准Java库)中的序列化工具对元信息结构进行序列化与反序列化,采用开源的Zookeeper客户端Curator(一种用于与Zookeeper服务端交互的第三方开源客户端)与Zookeeper进行交互。
步骤4,初始化MFS,系统自动将映射信息动态存储到Zookeeper集群,根据配置模块中的自定义配置信息,完成相应的Kafka中主题的创建以及分区的划分。具体内容如下:
步骤4.1,读取配置模块中应用层级的配置项,进而确定该应用检查点存储特征,根据特征进行文件路径到topic(表示Kafka的主题)和partition(表示主题的分区)的映射,本实施例中映射关系如图3所示,其树形结构表示检查点文件的目录结构,checkpointRoot表示流式应用自定义的检查点文件目录结构的顶层目录,目录节点的形状表示该节点映射成为Kafka中的不同结构,其中矩形表示映射成topic,椭圆形表示映射为partition,直线代表映射为message(Kafka的消息,它们是具体的检查点文件,如图3的以数字标识的文件名以及用于表示增量状态文件的1.delta和表示快照状态文件的1.snapshot)。
步骤4.2,在本实施例中,映射为Kafka topic层面的结构为:用于唯一标记流式应用的metadata信息、记录Structured Streaming应用的数据来源sources信息、记录任务执行批次的offsets信息、记录已提交批次的commits信息、表示Spark应用数据来源的sources信息以及记录任务执行状态的state信息一级子目录。这些信息对应为针对Kafkatopic层面的操作。
步骤4.3,在本实施例中,映射为Kafka partition层面的结构为:表示Spark应用数据来源的sources信息的一级子目录、以及记录任务执行状态的state信息的二级子目录。这些信息对应为针对Kafka partition层面的操作。
步骤5,检查点文件的创建、加载、删除、重命名、状态判断以及权限校验操作适配为对Zookeeper服务端和Kafka服务端的操作。检查点文件操作对应于MFS操作的方法具体包括以下步骤:
步骤5.1,检查点文件创建分为初始化输出流,缓存文件数据以及与向Kafka生产消息。具体步骤如下。
步骤5.1.1,自定义文件输出流MfsFileOutputStream,该输出流扩展自java.io.OutputStream。在初始化流的操作中,会接收到主类传递的ZkClient对象和KafkaProducer对象,分别用于操作Zookeeper和Kakfa服务。
步骤5.1.2,创建缓存结构,初始化大小设置为1024字节,采用动态指针就缓存位置进行标记。上层应用执行写入操作对应于向缓冲区中填充数据,等待写入完毕。
步骤5.1.3,在写入完毕后关闭输出流的操作中,将该缓冲区中内容封装成Kafka的消息格式,并且创建元信息单元,以事务性操作将元信息单元存入Zookeeper和将检查点文件数据消息生产到Kafka服务端。
步骤5.2,检查点文件加载分为初始化输入流,在Kafka中消费消息以及读取缓存文件数据。具体步骤如下。
步骤5.2.1,自定义文件输入流MfsFileInputStream,该输入流扩展自java.io.InputStream。初始化流的操作分为两个阶段,第一阶段会接收到主类传递的ZkClient对象和KafkaConsumer对象,分别用于操作Zookeeper和Kakfa服务。
步骤5.2.2,在第二阶段,创建缓存结构,初始化大小设置为1024字节,采用动态指针就缓存位置进行标记。通过在Zookeeper中获取到的offset信息,将topic-partiton-offset三元组信息组装出来,三元组信息可以唯一标识一个Kafka消息,利用该信息定向消费Kafka中消息。
步骤5.2.3,将消费得到二进制检查点文件数据缓存到缓存结构中,待初始化完毕,将文件数据流返回给上游应用,提供上游应用对检查点文件数据的加载。
步骤5.3,检查点文件数据的删除策略通过配置Kafka服务端的消息过期时间完成,Kafka服务端提供topic级别的留存时间配置项log.retention.ms,通过该配置并结合上游应用使用场景,用户可以个性化配置留存时间已达到删除检查点文件的目的,这样能够大幅降低常规文件系统删除文件过程中的资源开销。检查点文件元信息的删除操作对应Zookeeper对于对应节点的删除操作。
步骤5.4,对于检查点文件重命名、状态判断以及权限校验操作对应于对Zookeeper的操作,具体为获取对应的Zookeeper数据节点,对数据节点反序列化从而获得相应的字段值,完成对相应字段值的修改、查询和判断操作。
4.步骤6,设置配置模块,提供文件系统级别和流式应用级别的配置选项。设置配置模块的方法具体包括以下步骤:
步骤6.1,MFS文件系统级别的配置功能复用HDFS通用配置文件core-site.xml,为该配置文件添加fs.mfs.impl配置选项,将MFS实现的入口类MfsFileSystem注册进去。并且提供将MFS作为默认文件系统支持,配置方法为:
步骤6.2,提供Structured Streaming流式应用级别的配置选项app.properties,具体配置项以及含义如表1所示:
表1实施例中app.properties配置项及其含义
步骤7,使用Maven deploy(一种软件管理构建工具)工具,将MFS client(客户端依赖)发布到远程仓库。
具体操作如下:
使用Maven构建该Java项目,在pom.xml中配置依赖私服镜像地址,以下为实施例中配置选项:
步骤8,搭建Kafka和Zookeeper集群,作为服务模块部分。
步骤9,流式应用程序中安装MFS client(客户端依赖)以及指定MFS作为检查点文件系统,运行Structured Streaming流式应用。本实施例运行模式采用Spark Standalone(Spark集群资源调度的一种模式)部署模式,运行指令即相关参数如下:
spark-submit--master spark://192.168.56.101:7077
--class structuredStreaming.kafkaWordCount
--packages org.apache.spark:spark-sql-kafka-0-10_2.11:2.4.3
--jars mfs-1.0.0.jar
--executor-memory 4G
app.jar>result.txt
对于流式应用app,程序中显示指定检查点目标路径为本系统路径,具体形式为:
本发明提供的一种基于消息队列的数据流处理检查点文件存储的方法,根据Structured Streaming流式计算中产生的用于保存中间状态的检查点文件进行特征分析,将其存储结构与消息队列Kafka的存储模型进行逻辑适配,设计文件操作接口与消息操作接口的映射关系,使用Zookeeper保存映射关系元信息部分;接着,利用Java的SPI(ServiceProvider Interface)机制实现该系统客户端,自定义分布式文件系统协议,提供依赖库的无服务形式被上游流式处理应用所依赖,以一种对用户透明的运行方式,根据实现的映射规则将检查点数据路由到对应的Kafka存储结构中,当流式应用重启时,根据Zookeeper中的元信息获取到Kafka中相应的状态数据,进行任务恢复以实现Structured Streaming容错机制,支持用户根据应用场景自定义相应配置的选项,通过灵活配置,满足用户个性化应用场景,并充分利用Kafka高吞吐量的特点,以解决HDFS对检查点文件存储资源开销过大的问题,能够有效提高流式应用计算处理效率以及节省资源开销。
本发明第二方面提供一种基于消息队列的数据流处理检查点文件存储的装置。
实施例2:如图4和图5所示所示,本发明提供的一种基于消息队列的数据流处理检查点文件存储的装置,包括:
集成模块,用于集成数据流处理框架;
配置模块,用于提供根据协议定义的分布式文件系统级别和配置流式应用级别的选项;
元数据模块,用于自定义元信息存储结构和将数据流处理框架检查点文件存储结构与消息队列存储的层级结构进行逻辑映射;
数据模块,用于实现对检查点文件数据传输功能;
文件操作模块,用于实现对检查点文件操作的功能;
服务端模块,用于存储检查点文件数据以及元数据。
在该实施例中,集成模块,用于集成数据流处理框架,包括:自定义分布式文件系统协议,协议格式为mfs://
配置模块,用于提供根据协议定义的分布式文件系统级别和配置流式应用级别的选项,包括:MFS文件系统级别的通用配置文件core-site.xml和流式应用级别的配置选项app.properties;
元数据模块,用于自定义元信息存储结构和将数据流处理框架检查点文件存储结构与消息队列存储的层级结构进行逻辑映射,自定义元信息存储结构,包括:定义路径基础元信息存储结构PathInfo,包含name、owner、group、mode、lastModifiedTime信息,定义文件附加元信息存储结构FileInfo,包含文件操作需要的contentHash、contentLength以及在消息队列中表示消息位置的offset这些必要信息;
数据模块,用于实现对检查点文件数据传输功能;
文件操作模块,用于实现对检查点文件操作的功能;
服务端模块,用于存储检查点文件数据以及元数据。
实施例:3:数据模块实现对检查点文件数据传输功能,包括:数据输出模块和数据输入模块。
实施例4:数据输出模块用于流式应用程序发起检查点文件的创建,输出模块创建对应的输出流,上游应用通过该输出流写入文件数据。
实施例5:数据输入模块用于流式应用程序发起检查点文件的加载,输入模块创建对应的输入流,上游应用通过该输入流读取文件数据。
实施例6:文件操作模块实现对检查点文件的相关操作功能,检查点文件重命名、状态判断以及权限校验操作对应于对Zookeeper的操作,检查点文件数据的删除策略通过配置消息队列服务端的消息过期时间完成。
实施例7:服务端模块存储检查点文件数据以及元数据,包括:
文件数据存储以复用消息队列服务端的形式,检查点文件映射为消息格式,提供检查点文件的操作服务;
文件元数据存储以复用Zookeeper服务端的形式实现,以Zookeeper先天的目录树结构存储检查点文件结构,提供检查点文件元信息的存储服务。
- 基于消息队列的数据流处理检查点文件存储的方法及装置
- 一种基于云服务的消息队列流处理方法