声音内容分发系统
文献发布时间:2023-06-19 18:32:25
技术领域
本公开涉及向在虚拟现实空间内用户操作的化身分发声音内容的声音内容分发系统。
背景技术
一直以来,作为虚拟现实空间中的声学技术,已知如下的声场再现技术:除了能够确定声源场所而对进入左右耳的声音赋予时间差、音量差以外,还能够再现将由耳廓、身体的反射的影响引起的声音的变化模型化后的立体声音。通过使用在虚拟现实空间上识别与声源的距离或方向性的声音,具有与现实世界同样的体感的效果。
另外,作为虚拟现实空间制作时的音响效果的SDK(软件开发工具包),存在仅通过对建筑物的内饰或环境的构成物的对象标记素材映射(通过规定物体的材质来计算回响或衰减)的信息,就能够构建立体音响空间的技术。
发明内容
(发明要解决的课题)
近年来,虽然安装了上述那样的立体音响的虚拟现实空间逐渐增加,但与富化的虚拟现实空间上的视觉面相比,在虚拟现实空间中存在向音响的安装不足的状况。即,以往的虚拟现实空间中的音响技术、例如现实的立体音响的追求以现实世界的音响体验的再现为目标。另一方面,存在不能充分地活用所谓能够完全进行音响控制的空间这样的虚拟现实空间的优点的状况。
期望提供一种能够向用户提供在虚拟现实空间中优化的声音内容体验的机制。
(用于解决课题的技术方案)
本公开的一个方式的声音内容分发系统是向在虚拟现实空间内用户操作的化身分发声音内容的声音内容分发系统,具备服务器装置和能够与所述服务器装置通信的用户终端,所述服务器装置具有:声音数据获取部,其从分发源获取声音数据;声音内容数据生成部,其对所述声音数据附加表示是否反映在虚拟现实空间内的声音的回响和/或衰减的音响效果设定信息和音量设定信息,生成适当的音量的声音内容数据;声音内容数据分发部,其将所述声音内容数据分发到在所述虚拟现实空间内操作化身的用户的用户终端,所述用户终端具有:声音内容数据接收部,其从所述服务器装置接收所述声音内容数据;声音数据输出控制部,其将存储在所述声音内容数据中的所述声音数据以与所述音响效果设定信息对应的音响效果输出。
本公开的一个方式的服务器装置构成向在虚拟现实空间内用户操作的化身分发声音内容的声音内容分发系统,所述服务器装置具有:声音数据获取部,其从分发源获取声音数据;声音内容数据生成部,其对所述声音数据附加表示是否反映了虚拟现实空间内的声音的回响和/或衰减的音响效果设定信息,生成声音内容数据;以及声音内容数据分发部,其将所述声音内容数据分发到在所述虚拟现实空间内操作化身的用户的用户终端。
本公开的一个方式的用户终端是构成向在虚拟现实空间内用户操作的化身分发声音内容的声音内容分发系统的用户终端,具有:声音内容数据接收部,接收对声音数据附加表示是否反映虚拟现实空间内的声音的回响和/或衰减的音响效果设定信息后的声音内容数据;以及声音数据输出控制部,将所述声音内容数据中保存的所述声音数据以与所述音响效果设定信息对应的音响效果输出。
本公开的一个方式的声音内容分发方法是向在虚拟现实空间内用户操作的化身分发声音内容的声音内容分发方法,包括:从分发源获取声音数据的步骤;对所述声音数据附加表示是否反映虚拟现实空间内的声音的回响和/或衰减的音响效果设定信息,生成声音内容数据的步骤;以及将所述声音内容数据分发到在所述虚拟现实空间内操作化身的用户的用户终端,并使在该用户终端中存储在所述声音内容数据中的所述声音数据以与所述音响效果设定信息对应的音响效果输出的步骤。
附图说明
图1是表示一实施方式涉及的声音内容分发系统的概略结构的图。
图2是表示服务器装置的结构的框图。
图3是示出用户终端的结构的框图。
图4是用于说明目标信息的类别的表。
图5是表示声音内容数据的构造的一例的图。
图6是用于说明虚拟现实空间中的音响效果和声音内容的活用事例的表。
图7是表示分发声音内容分发系统的动作的一例(推送型分发)的流程图。
图8是示出分发声音内容分发系统的动作的另一例(拉取型分发)的流程图。
具体实施方式
实施方式的第一方式所涉及的声音内容分发系统是向在虚拟现实空间内用户操作的化身分发声音内容的声音内容分发系统,
具备:服务器装置;以及用户终端,其能够与所述服务器装置进行通信,
所述服务器装置具有:
声音数据获取部,其从分发源获取声音数据;
声音内容数据生成部,其对所述声音数据附加表示是否反映虚拟现实空间内的声音的回响和/或衰减的音响效果设定信息和音量设定信息,生成适当的音量的声音内容数据;以及
声音内容数据分发部,其将所述声音内容数据分发到在所述虚拟现实空间内操作化身的用户的用户终端,
所述用户终端具有:
声音内容数据接收部,其从所述服务器装置接收所述声音内容数据;以及
声音数据输出控制部,其将存储在所述声音内容数据中的所述声音数据以与所述音响效果设定信息对应的音响效果输出。
根据这样的方式,在分发声音内容时,在从分发源获取到的声音数据中,根据分发对象的目标或内容内容,附加表示是否反映在虚拟现实空间内的声音的回响和/或衰减的音响效果设定信息和音量设定信息,由此,除了以反映了虚拟现实空间内的回响、衰减的真实的立体音响输出对用户适当的音量的声音数据以外,还能够不衰减由距离引起的声音的衰减,以能够完全控制指向性的人工音响(在现实世界中不会产生的声音)输出。通过以真实的立体声音的输出,自然地听到声音数据。另一方面,通过不衰减的人工音响,声音数据在人听起来会有违和感,容易察觉,因此能够进行声音内容的清晰的传递。因此,与在现有的虚拟现实空间内实施的声音分发相比,能够高质量且有效地分发声音内容,并将优化后的声音内容体验提供给用户。
实施方式的第二方式所涉及的声音内容分发系统是根据第一方式所涉及的声音内容分发系统,
所述声音内容数据生成部除了对所述声音数据附加所述音响效果设定信息以外,还附加用于确定目标的目标信息来生成所述声音内容数据,
所述声音数据输出控制部基于所述声音内容数据所包括的所述目标信息,判定用户操作的化身是否符合目标,在判定为符合目标的情况下,进行所述声音数据的输出。
根据这样的方式,在分发声音内容时,在从分发源获取到的声音数据中,除了音响效果设定信息以外,还附加目标信息,从而能够根据分发对象的目标、内容内容,进行更精细的声音内容的分发。
实施方式的第三方式所涉及的声音内容分发系统是根据第二方式所涉及的声音内容分发系统,
所述目标信息包括确定所述虚拟现实空间内的区域的信息,所述声音数据输出控制部在用户操作的化身位于所述区域内的情况下,判定为符合目标。
根据这样的方式,能够向特定的区域分发。
实施方式的第四方式所涉及的声音内容分发系统是根据第二或第三方式所涉及的声音内容分发系统,
所述目标信息包括确定化身的人数的信息,所述声音数据输出控制部在用户操作的化身在所述虚拟现实空间内与其他化身一起以所述人数以上集合的情况下,判定为符合目标。
根据这样的方式,能够进行面向人群的分发。
实施方式的第五方式所涉及的声音内容分发系统是根据第二至四方式中任一项方式所涉及的声音内容分发系统,
所述目标信息包括确定化身的属性的信息,所述声音数据输出控制部在用户操作的化身具有所述属性的情况下,判定为符合目标。
根据这样的方式,能够进行面向特定的化身的分发。
实施方式的第六方式所涉及的声音内容分发系统是第二至五方式中任一项方式所涉及的声音内容分发系统,
所述目标信息包括确定包括所述虚拟现实空间内的时间、状况、场所中的至少1个的环境状态的信息,所述声音数据输出控制部在用户操作的化身处于所述环境状态的情况下,判定为符合目标。
根据这样的方式,能够进行由时间、状况、场所等特定的环境状态引起的(以特定的环境状态为触发的)分发。
实施方式的第七方式所涉及的声音内容分发系统是在第一至第六方式中任一项方式所涉及的声音内容分发系统中,
所述声音内容数据生成部在进行不反映所述虚拟现实空间内的声音的回响以及衰减的设定作为所述音响效果设定信息的情况下,能够设定在所述虚拟现实空间内声音不回响以及衰减而到达的距离和/或指向性。
根据这样的方式,在以不衰减的人工音响分发声音数据时,通过限定距离和/或指向性,能够进行个人内容、隐秘性信息的分发。
实施方式的第八方式所涉及的声音内容分发系统是第一至七方式中任一项方式所涉及的声音内容分发系统,
所述服务器装置还具有广告费计算部,所述广告费计算部检测在所述用户终端中输出声音数据的情况,并基于其秒数和/或次数来计算赋予给所述用户的广告费。
实施方式的第九方式所涉及的服务器装置是构成向在虚拟现实空间内用户操作的化身分发声音内容的声音内容分发系统的服务器装置,
所述服务器装置具有:
声音数据获取部,其从分发源获取声音数据;
声音内容数据生成部,其对所述声音数据附加表示是否反映虚拟现实空间内的声音的回响和/或衰减的音响效果设定信息,生成声音内容数据;以及
声音内容数据分发部,其将所述声音内容数据分发到在所述虚拟现实空间内操作化身的用户的用户终端。
实施方式的第十方式所涉及的用户终端是构成向在虚拟现实空间内用户操作的化身分发声音内容的声音内容分发系统的用户终端,
所述用户终端具有:
声音内容数据接收部,其接收对声音数据附加表示是否反映虚拟现实空间内的声音的回响和/或衰减的音响效果设定信息后的声音内容数据;以及
声音数据输出控制部,其根据与所述音响效果设定信息对应的音响效果,输出在所述声音内容数据中存储的所述声音数据。
实施方式的第十一方式所涉及的声音内容分发方法是向在虚拟现实空间内用户操作的化身分发声音内容的声音内容分发方法,
所述声音内容分发方法包括:
从分发源获取声音数据的步骤;
对所述声音数据附加表示是否反映虚拟现实空间内的声音的回响和/或衰减的音响效果设定信息来生成声音内容数据的步骤;以及
将所述声音内容数据分发到在所述虚拟现实空间内操作化身的用户的用户终端,并使在该用户终端中存储于所述声音内容数据的所述声音数据以与所述音响效果设定信息对应的音响效果输出的步骤。
以下,参照附图,对实施方式的具体例进行详细说明。此外,在以下的说明以及以下的说明中使用的附图中,对于能够相同地构成的部分,使用相同的附图标记,并且省略重复的说明。
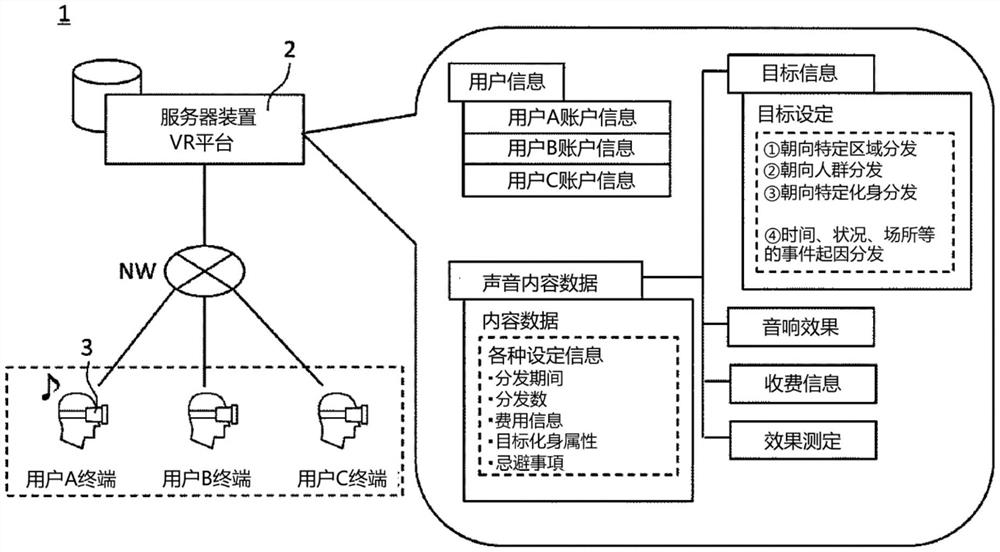
图1是表示一实施方式涉及的声音内容分发系统1的概略结构的图。声音内容分发系统1是向在虚拟现实空间内用户操作的化身分发声音内容的系统。
如图1所示,声音内容分发系统1具有服务器装置2和多个用户终端3。服务器装置2和多个用户终端3经由因特网等网络NW以能够相互通信的方式连接。网络NW可以是有线线路和无线线路中的任意一种,无论线路的种类或方式如何。另外,服务器装置2和用户终端3的至少一部分由计算机实现。
首先,对服务器装置2进行说明。在图示的例子中,服务器装置2由1台计算机构成,但不限于此,也可以由经由网络能够相互通信地连接的多台计算机构成。
图2是表示服务器装置2的结构的框图。如图2所示,服务器装置2具有服务器通信部21、服务器控制部22以及服务器存储部23。各部21~23经由总线、网络以能够相互通信的方式连接。
其中,服务器通信部21是服务器装置2与网络NW之间的通信接口。服务器通信部21经由网络NW在服务器装置2与各用户终端3之间收发信息。
服务器存储部23例如是闪存等非易失性数据存储装置。服务器存储部23中存储有服务器控制部22处理的各种数据。例如,服务器存储部22包括用户信息数据库231和声音内容数据数据库232。
参照图1,在用户信息数据库231中,按每个用户存储该用户的账户信息(例如,用户ID、密码、用户能够操作的化身信息、存入广告费的账户信息等)。
在声音内容数据数据库232中存储有应该向在虚拟现实空间内用户操作的化身分发的声音内容数据。在声音内容数据数据库232中,也可以按每个声音内容数据存储由提供源指定的各种设定信息(例如,分发期间、分发数、费用信息(收费/免费)、目标的化身属性、忌避事项等)。在此,在声音内容是收费的情况下,例如既可以是事先的票单购入等每次发行系统,也可以是包月收费等订阅。另外,在声音内容是收费的情况下,也可以进行该声音内容的后续听到、反复听等优惠的赋予等。
如图2所示,服务器控制部22具有声音数据获取部221、声音内容数据生成部222、声音内容数据分发部223以及广告费计算部224。这些各部221~224可以通过服务器装置2内的处理器执行规定的程序来实现,也可以通过硬件实现。
声音数据获取部221从分发源获取声音数据。例如,在从虚拟现实空间内的对象(广告牌、人偶、无人机等)以声音分发广告的情况下,声音数据获取部221也可以从提供该广告的广告商(即分发源)获取声音数据。另外,例如,在虚拟现实空间内化身彼此通过声音进行对话的情况下,声音数据获取部221也可以从操作该化身的用户(即分发源)经由用户终端的终端输入部(例如麦克风)获取声音数据。
声音内容数据生成部222对由声音数据获取部221获取的声音数据附加表示是否反映在虚拟现实空间内的声音的回响和/或衰减的音响效果设定信息和音量设定信息,生成适当的音量的声音内容数据。
声音内容数据生成部222在进行不反映虚拟现实空间内的声音的回响和衰减的设定作为音响效果设定信息的情况下,也可以能够设定在虚拟现实空间内声音不回响和衰减而到达的距离和/或指向性。
声音内容数据生成部222也可以在由声音数据获取部221获取的声音数据中,除了表示是否反映在虚拟现实空间内的声音的回响和/或衰减的音响效果设定信息和音量设定信息以外,还附加用于确定目标的目标信息,生成适当的音量的声音内容数据。在此,目标信息可以包括(1)确定虚拟现实空间内的区域的信息、(2)确定化身的人数的信息、(3)确定化身的属性的信息、(4)确定包括虚拟现实空间内的时间、状况、场所中的至少1个的环境状态的信息中的1个或2个以上。
图4是用于说明目标信息的类别的表。在目标信息包括“(1)确定虚拟现实空间内的区域的信息”的情况下,能够进行从全部世界级别到最少的区域进行分发的区域的设定,即能够向特定区域分发。区域既可以是能够设定多个,也可以是可变的。另外,也可以在区域内进行多个不同的分发。
在目标信息包括“(2)确定化身的人数的信息”的情况下,相对于有化身的多个或规定数集合的状态,能够通过自动监视进行感知并分发,即能够向群众分发。在群众分发中,设想非特定的化身。
在目标信息包括“(3)确定化身的属性的信息”的情况下,能够自动地监视化身的兴趣嗜好、属性,并针对特定的化身以定点进行分发,即能够向特定化身分发。在面向特定化身的分发中,可以指定一个化身,也可以指定多个化身。
在目标信息包括“(4)确定包括虚拟现实空间内的时间、状况、场所中的至少1个的环境状态的信息”的情况下,能够将虚拟现实空间内的时间、状况、场所等特定的环境状态作为触发来分发,即能够进行起因于时间、状况、场所等特定的事件的分发。例如,能够指定在午餐时间分发汉堡店的广告等。
图5是表示声音内容数据的构造的一例的图。在图5所示的例子中,设想了IP电话中的声音数据包构造(VoIP),声音内容数据由IP头、UDP(User Datagram Protocol:用户数据包传输协议)、RTP(Real-time Transport Protocol:实时传输协议)、头信息以及声音数据构成,表示是否反映在虚拟现实空间内的声音的回响和/或衰减的音响效果设定信息、以及用于确定目标的目标信息被存储在头信息中。
通过声音内容数据生成单元222附加到声音数据的音响效果设置信息和目标信息可以根据来自分发源的指定而手动设置,或者可以根据分发对象的目标或内容的内容来自动设置。例如,在朝向特定的化身的定点的分发中,也可以自动地设定音响效果设定信息、音量设定信息、目标信息,以掌握分发目的地的化身的耳朵、身体的位置、朝向、姿势、视线等,并根据它们以最佳的形式、音量输出声音数据。
由声音内容数据生成部222生成的声音内容数据也可以存储在声音内容数据数据库232中。
声音内容数据分发部223将由声音内容数据生成部222生成的声音内容数据经由网络NW分发到在虚拟现实空间内操作化身的用户的用户终端3。有时也称为虚拟现实空间内,当然能够进行向固定点的分发,例如即使是作为分发目标的化身在虚拟现实空间内移动中的状态,声音内容也会追踪,能够以适当的音量进行不间断的流分发。
广告材料计算部224在声音数据是广告的情况下,检测在用户终端3中输出了声音数据的情况,基于声音数据被输出的秒数和/或次数,计算对操作该用户终端3的用户赋予的广告费。在此,“广告费”既可以是在虚拟现实空间的支付中能够使用的优惠券、积分、电子货币、虚拟货币等,也可以是在现实世界的支付中能够使用的优惠券、积分、电子货币、虚拟货币、现金等。广告费计算部224也可以在向用户终端3发送广告费的信息时,一起发送分发的设置列表、广告一览等,并由终端显示部34进行提示。由此,收听广告的用户立即连接到购买行动。
接着,对用户终端3进行说明。用户终端3是用户使用的终端,例如是头戴式显示器(HMD)、个人计算机(PC)、智能手机、平板终端等。
图3是表示用户终端3的结构的框图。如图3所示,用户终端3具有终端通信部31、终端控制部32、终端输入部33、终端显示部34以及终端声音输出部35。各部31~35经由总线能够相互通信地连接。
终端通信部31是用户终端3与网络NW之间的通信接口。终端通信部31经由网络NW在用户终端3与服务器装置2之间收发信息。
终端输入部33是用于供用户向用户终端3输入信息的接口,例如是头戴式显示器中的手持控制器、智能手机、平板终端中的触摸面板、麦克风、个人计算机中的触摸板、键盘或者鼠标等。在此,头戴式显示器中的手持控制器也可以具有至少1个操作按钮,内置有检测控制器的朝向或运动(加速、旋转等)的各种传感器。通过来自终端输入部33的操作输入,用户能够使化身在虚拟现实空间内移动或发声。
终端显示部34是从用户终端3向用户显示各种信息的接口,例如是液晶显示器等影像显示机构。在用户终端3是头戴式显示器的情况下,终端显示部34是佩戴于用户的头部并覆盖用户的双眼的视野的类型的影像显示机构。佩戴了头戴式显示器的用户能够看到显示于终端显示部34的影像。在终端显示部34上显示静态图像、动态图像、文档、主页等任意的对象(电子文件)。对终端显示部34的显示方式没有特别限制,既可以是在具有进深的虚拟空间(虚拟现实空间)的任意的位置显示对象的方式,也可以是在虚拟平面的任意的位置显示对象的方式。
终端声音输出部35是以声音(声波或者骨传导)从用户终端3向用户输出各种信息的接口,例如是耳机、头戴式耳机、扬声器等。
如图3所示,终端控制部32具有声音内容数据接收部321和声音数据输出控制部322。这些各部321、322可以通过用户终端3内的处理器执行规定的程序来实现,也可以通过硬件实现。
声音内容数据接收部321经由终端通信部31接收从服务器装置2发送的声音内容数据。
声音数据输出控制部322从由声音内容数据接收部321接收到的声音内容数据中提取声音数据和音响效果设定信息,将存储在声音内容数据中的声音数据以与音响效果设定信息相应的音响效果经由终端声音输出部35输出。即,在音响效果设定信息中,在设定了使声音数据反映虚拟现实空间内的声音的回响和/或衰减(以下也称为“立体声音”)的情况下,声音数据输出控制部322基于虚拟现实空间内的声源与化身之间的距离、素材映射后的对象的形状、配置,计算从声源到化身的空间中的声音的回响和/或衰减,并以反映了该计算结果的音响效果(立体声音)从终端声音输出部35输出声音数据。由此,对于用户而言,能够自然地(真实地)听到声音数据。
另一方面,在音响效果设定信息中,设定有使声音数据不反映虚拟现实空间内的声音的回响和/或衰减(以下也称为“不衰减的人工音响”)的情况下,声音数据输出控制部322不反映在虚拟现实空间内的声音的回响以及衰减,而从终端声音输出部35输出声音数据。由此,由于声音数据通过没有回响、衰减的人工音响(在现实世界中无法产生的声音)被输出,因此对于用户来说,听起来会有违和感,容易察觉。因此,能够进行声音内容的清晰的传递。
在音响效果设定信息中,设定了使声音数据不反映在虚拟现实空间内的声音的回响和/或衰减的情况(即“不衰减的人工音响”)的情况下,且在假想现实空间内声音没有回响及衰减地到达的距离和/或指向性被设定的情况下,声音数据输出控制部322判定化身相对于声源的当前位置是否满足设定的距离和/或指向性的条件,在判定为满足条件的情况下,不反映声音的回响或衰减地从终端声音输出部35输出声音数据。另一方面,在判定为不满足条件的情况下,声音数据输出控制部322不进行经由终端声音输出部35的声音数据的输出。
另外,在由声音内容数据接收部321接收到的声音内容数据中存储有目标信息的情况下,声音数据输出控制部322基于声音内容数据中包括的目标信息,来判定用户操作的化身是否符合目标。
例如,在目标信息包括“(1)确定虚拟现实空间内的区域的信息”的情况下,声音数据输出控制部322在用户操作的化身位于该特定的区域内的情况下,判定为符合目标。另外,例如,在目标信息包括“(2)确定化身的人数的信息”的情况下,声音数据输出控制部322在用户操作的化身在虚拟现实空间内与其他化身一起以该特定人数以上集合的情况下,判定为符合目标。另外,例如,在目标信息包括“(3)确定化身的属性的信息”的情况下,声音数据输出控制部322在用户操作的化身具有该特定的属性的情况下,判定为符合目标。另外,例如,在目标信息包括“(4)确定包括虚拟现实空间内的时间、状况、场所中的至少1个的环境状态的信息”的情况下,声音数据输出控制部322在用户操作的化身处于该特定的环境状态的情况下,判定为符合目标。
然后,声音数据输出控制部322在判定为用户操作的化身符合目标的情况下,将存储在声音内容数据中的声音数据以与音响效果设定信息对应的音响效果经由终端声音输出部35输出。另一方面,声音数据输出控制部322在判定为用户操作的化身不符合目标的情况下,不进行经由终端声音输出部35的声音数据的输出。
图6是用于说明虚拟现实空间中的音响效果和声音内容的活用事例的表。例如,可以考虑用于进一步享受“音乐”、“广播”等内容的“立体音响”、以及广告、个人交流、公共性高的告知、朝向注意唤起的“不衰减的人工音响”等作为活用事例。声音内容也能够进行直播分发。
具体而言,例如,如图6所示,关于音乐会分发的声音内容,作为对声音数据附加的音响效果而设定“立体声音”,作为目标而设定“面向特定区域”、“面向人群”或“面向特定化身”,从而能够以在虚拟现实空间内就座于真实的音乐会的座位那样的图像来享受具有临场感的音乐的体验。另外,例如,关于音乐会分发/音频试听的声音内容,作为对声音数据附加的音响效果而设定“立体声音”,作为目标设定“面向特定化身”,由此,即使在虚拟现实空间内位于哪里,都能够以能够感受到7.1ch环绕效果的“最佳座椅”来丰富地享受音乐的体验。
另外,例如,关于广播分发的声音内容,作为对声音数据附加的音响效果而设定“立体声音”,作为目标设定“面向特定区域”、“面向人群”或“面向特定化身”,由此,能够实现在虚拟现实空间内的与室内外真实的广播试听相同的试听体验,在移动中也能够听音。另外,例如,对于BGM(有线广播)的声音内容,作为对声音数据附加的音响效果而设定“立体声音”,作为目标设定“面向特定区域”、“面向人群”或“面向特定化身”,从而能够实现在虚拟现实空间内的与室内真实的有线试听相同的试听体验。
另外,例如,关于声音广告的声音内容,作为对声音数据附加的音响效果而设定“不衰减的人工音响”,作为目标设定“面向特定区域”、“面向人群”或“面向特定化身”,由此,能够在虚拟现实空间中的广播CM那样的定位下进行分发,能够通过与立体声音不同的听到方式下的声音广告来提高听音机会和认知。另外,例如,关于公共的日常信息的声音内容,作为对声音数据附加的音响效果而设定“不衰减的人工音响”,作为目标设定“面向特定区域”、“面向人群”或“面向特定化身”,由此能够进行虚拟现实空间内的报时、天气预报、新闻、服务器维护等公共性高的信息通知。
另外,例如,关于公共的紧急信息的声音内容,作为对声音数据附加的音响效果而设定“不衰减的人工音响”,作为目标设定“面向特定区域”、“面向人群”或“面向特定化身”,从而能够进行紧急地震速报等紧急性高的注意提醒。另外,例如,对于面向个人的私信的声音内容,作为对声音数据附加的音响效果,设定“不衰减的人工音响”,作为目标设定“面向特定化身”,由此,能够进行面向个人的私信的分发,另外,作为目标设定“面向特定区域”、“面向群众”或者“面向特定化身”,由此不仅能够分发,还能够进行聊天的利用。
接着,参照图7对由这样的结构构成的声音内容分发系统1的动作的一例进行说明。图7是表示声音内容分发系统1的动作的一例(推送型分发)的流程图。
如图7所示,在使用本实施方式涉及的声音内容分发系统1的情况下,首先,当在用户终端3中输入了登录信息时(步骤S10),从用户终端3向服务器装置2发送所输入的登录信息(步骤S11),在服务器装置2中进行用户认证的处理(步骤S12)。当用户认证成功时,从服务器装置2向用户终端3发送登录许可(步骤S13)。
接着,若被允许登录的用户操作用户终端3,在虚拟现实空间中生成化身(步骤S14),则从用户终端3向服务器装置2发送用户操作的化身的化身信息(化身属性等)(步骤S15),通过服务器装置2进行化身信息的确认(例如,化身属性与由广告商指定的化身属性一致的确认)(步骤S16)。
接着,服务器装置2的声音数据获取部221从分发源(例如广告商)获取声音数据(步骤S17)。
接着,声音内容数据生成部222进行表示是否反映在虚拟现实空间内的声音的回响和/或衰减的音响效果设定信息、用于确定目标的目标信息的设定(步骤S18)。声音内容数据生成部222在进行不反映虚拟现实空间内的声音的回响和衰减的设定作为音响效果设定信息的情况下,也可以进一步设定在虚拟现实空间内声音不回响和衰减而到达的距离和/或指向性。另外,目标信息也可以包括(1)确定虚拟现实空间内的区域的信息、(2)确定化身的人数的信息、(3)确定化身的属性的信息、(4)确定包括虚拟现实空间内的时间、状况、场所中的至少1个的环境状态的信息中的1个或2个以上。
然后,声音内容数据生成部222对由声音数据获取部221获取的声音数据附加音响效果设定信息、音量设定信息、目标信息,以生成适当的音量的声音内容数据(步骤S19)。所生成的声音内容数据被存储在声音内容数据数据库232中。
接着,声音内容数据分发部223经由网络NW将由声音内容数据生成部222生成的声音内容数据分发到在虚拟现实空间内操作化身的用户的用户终端3,在用户终端3中,声音内容数据接收部321接收该声音内容数据(步骤S20)。
声音数据输出控制部322从由声音内容数据接收部321接收到的声音内容数据中提取目标信息,并基于该目标信息,来判定用户操作的化身是否符合目标(步骤S21)。例如,在目标信息包括“(1)确定虚拟现实空间内的区域的信息”的情况下,声音数据输出控制部322在用户操作的化身位于该特定的区域内的情况下,判定为符合目标。另外,例如,在目标信息包括“(2)确定化身的人数的信息”的情况下,声音数据输出控制部322在用户操作的化身在虚拟现实空间内与其他化身一起以该特定人数以上集合的情况下,判定为符合目标。另外,例如,在目标信息包括“(3)确定化身的属性的信息”的情况下,声音数据输出控制部322在用户操作的化身具有该特定的属性的情况下,判定为符合目标。另外,例如,在目标信息包括“(4)确定包括虚拟现实空间内的时间、状况、场所中的至少1个的环境状态的信息”的情况下,声音数据输出控制部322在用户操作的化身处于该特定的环境状态的情况下,判定为符合目标。
然后,在判定为用户操作的化身符合目标的情况下(步骤S21:是),声音数据输出控制部322将存储在声音内容数据中的声音数据以与音响效果设定信息对应的音响效果经由终端声音输出部35输出(步骤S22)。例如,在音响效果设定信息中,在设定了使声音数据反映虚拟现实空间内的声音的回响和/或衰减的情况下,声音数据输出控制部322基于虚拟现实空间内的声源与化身之间的距离、素材映射的对象的形状、配置,来计算从声源到化身的空间中的声音的回响和/或衰减,并以反映了该计算结果的音响效果(立体声音)从终端声音输出部35输出声音数据。另一方面,在音响效果设定信息中,在设定为使声音数据不反映虚拟现实空间内的声音的回响及/或衰减的情况下,声音数据输出控制部322不反映在虚拟现实空间内的声音的回响及衰减,而从终端声音输出部35输出声音数据。
当通过声音数据输出控制部322进行声音数据的输出时,从用户终端3向服务器装置2发送声音数据的视听开始通知(步骤S23)。服务器装置2的广告费计算部224通过接收从用户终端3发送的视听开始通知,确认(检测)声音内容到达该用户终端3并输出了声音数据(步骤S24)。
然后,广告费计算部224计算在用户终端3中输出了声音数据的秒数和/或次数,基于该秒数和/或次数,计算对操作该用户终端3的用户赋予的广告费(步骤S25),从服务器装置2向用户终端3发送该广告费的信息(步骤S26)。
根据以上那样的本实施方式,在分发声音内容时,在从分发源获取的声音数据中,根据分发对象的目标或内容内容,附加表示是否反映在虚拟现实空间内的声音的回响和/或衰减的音响效果设定信息和音量设定信息,由此,除了以反映了虚拟现实空间内的回响或衰减的真实的立体音响输出对用户适当的音量的声音数据以外,还能够不衰减由距离引起的声音的衰减,以能够完全控制指向性的人工音响(在现实世界中不产生的声音)输出。通过以真实的立体声音的输出,自然地听到声音数据。另一方面,通过不衰减的人工音响,声音数据在人听起来会有违和感,容易察觉,因此能够进行声音内容的清晰的传递。因此,与在现有的虚拟现实空间内实施的声音分发相比,能够高质量且有效地分发声音内容,并将优化后的声音内容体验提供给用户。
另外,根据本实施方式,在分发声音内容时,在从分发源获取的声音数据中,除了音响效果设定信息以外,还附加目标信息,从而能够根据分发对象的目标或内容内容,进行更精细的声音内容的分发。例如,通过在声音数据中附加用于确定虚拟现实空间内的区域的信息作为目标信息,能够进行面向特定区域的分发。另外,通过在声音数据中附加用于确定化身的人数的信息作为目标信息,能够进行面向人群的分发。另外,通过在声音数据中附加用于确定化身的属性的信息作为目标信息,能够进行面向特定的化身的分发。另外,通过在声音数据中附加用于确定包括虚拟现实空间内的时间、状况、场所中的至少1个的环境状态的信息作为目标信息,能够进行由时间、状况、场所等特定的环境状态引起的(以特定的环境状态为触发的)分发。
另外,根据本实施方式,在进行不反映虚拟现实空间内的声音的回响和衰减的设定作为音响效果设定信息的情况下,通过设定(限定)在虚拟现实空间内声音不回响和衰减地到达的距离和/或指向性,能够分发私有内容和隐秘性信息。
另外,在上述的实施方式中,作为声音内容分发系统1的动作的一例,对从服务器装置2单向地分发的推送型分发进行了说明,但本技术并不限定于推送型分发,也可以是从用户终端3请求分发的拉取型分发,例如也可以是如个人聊天、组聊天、或收发器那样具有与化身彼此、世界的双方向性的分发。
图8是表示声音内容分发系统1的动作的另一例(拉取型分发)的流程图。在图8所示的例子中,从由用户终端3输入登录信息的工序到由服务器装置2进行化身信息的确认的工序(步骤S10~S16),与上述的实施方式相同,省略详细的说明。
如图8所示,当在虚拟现实空间内操作化身的用户经由用户终端3的终端输入部33进行音乐或广播等声音内容的请求操作时(步骤S30),从用户终端3向服务器装置2发送请求信息(步骤S31),服务器装置2的声音数据获取部221根据从用户终端3发送的请求信息,从分发源获取声音数据(步骤S17)。
接着,声音内容数据生成部222进行表示是否反映在虚拟现实空间内的声音的回响和/或衰减的音响效果设定信息、用于确定目标的目标信息的设定(步骤S18)。
然后,声音内容数据生成部222对由声音数据获取部221获取的声音数据附加音响效果设定信息、音量设定信息、目标信息,生成适当的音量的声音内容数据(步骤S19)。所生成的声音内容数据被存储在声音内容数据数据库232中。
接着,声音内容数据分发部223经由网络NW将由声音内容数据生成部222生成的声音内容数据分发到在虚拟现实空间内操作化身的用户的用户终端3,在用户终端3中,声音内容数据接收部321接收该声音内容数据(步骤S20)。
声音数据输出控制部322从由声音内容数据接收部321接收到的声音内容数据中提取目标信息,并基于该目标信息来判定用户操作的化身是否符合声音内容的目标(步骤S21)。
然后,在判定为用户操作的化身符合目标的情况下(步骤S21:是),声音数据输出控制部322将存储在声音内容数据中的声音数据以与音响效果设定信息对应的音响效果经由终端声音输出部35输出(步骤S22)。例如,在音响效果设定信息中,在设定了使声音数据反映虚拟现实空间内的声音的回响和/或衰减的情况下,声音数据输出控制部322基于虚拟现实空间内的声源与化身之间的距离、素材映射的对象的形状、配置,计算从声源到化身的空间中的声音的回响和/或衰减,并以反映了该计算结果的音响效果(立体声音)从终端声音输出部35输出声音数据。另一方面,在音响效果设定信息中,在设定为在声音数据中不反映虚拟现实空间内的声音的回响及/或衰减的情况下,声音数据输出控制部322不反映在虚拟现实空间内的声音的回响及衰减,而从终端声音输出部35输出声音数据。
当通过声音数据输出控制部322进行声音数据的输出时,从用户终端3向服务器装置2发送声音数据的视听开始通知(步骤S23)。服务器装置2的广告费计算部224通过接收从用户终端3发送的视听开始通知,而确认(检测)声音内容到达该用户终端3并输出了声音数据(步骤S24)。
接着,当在虚拟现实空间内操作化身的用户经由用户终端3的终端输入部33进行声音内容的视听结束操作时(步骤S32),从用户终端3向服务器装置2发送视听结束通知(步骤S31)。服务器装置2的广告费计算部224通过接收从用户终端3发送的视听结束通知,检测在该用户终端3中停止了声音数据的输出,计算在用户终端3中输出了声音数据的秒数和/或次数。然后,广告费计算部224基于输出了声音数据的秒数和/或次数,来计算对操作用户终端3的用户赋予的广告费(步骤S25),并从服务器装置2向用户终端3发送该广告费的信息(步骤S26)。
此外,上述的实施方式的记载以及附图的公开不过是用于说明专利请求的范围所记载的发明的一例,并不通过上述的实施方式或者附图的公开而对专利请求的范围所记载的发明进行限定。上述的实施方式的构成要素能够在不脱离发明的主旨的范围内任意地组合。
另外,本实施方式所涉及的广告显示系统1的至少一部分能够由计算机构成,但用于使计算机实现广告显示系统1的至少一部分的程序以及将该程序非暂时性(non-transitory)记录的计算机可读取的记录介质也是本发明的保护对象。
- 内容信息分发服务器、终端装置、内容信息分发系统、内容信息分发方法、内容信息播放方法、内容信息分发程序以及内容信息播放程序
- 内容分发控制程序、内容分发控制装置、内容分发装置和内容分发系统