一种基于深度语义匹配的代码克隆检测方法
文献发布时间:2024-04-18 20:01:23
技术领域
本发明涉及代码克隆检测技术领域,特别是涉及一种基于深度语义匹配的代码克隆检测方法。
背景技术
代码克隆检测是软件工程领域一个很重要的研究方向。代码克隆不必要地增加了软件系统的大小。为了检测和管理代码克隆,研究者把代码克隆分为四类:类型一是除了注释、空格、换行之外,完全相同的代码片段;类型二是在类型一的基础上,除了类别名、变量名以及常量名之外,完全相同的代码片段;类型三是在类型二的基础上,有少量语句的增加、删除、修改;类型四是指实现的功能相同,但实现的方法完全不同。在代码克隆成为一个软件工程的研究方向以来,许多非深度学习的方法都专注在检测类型一、二、三的克隆,但是在检测语义代码克隆(中等类型三、弱类型三以及类型四)上取得的进展很有限,存在检测准确率不高,无法达到工业界应用标准的问题。因此,设计一种基于深度语义匹配的代码克隆检测方法是十分有必要的。
发明内容
本发明的目的是提供一种基于深度语义匹配的代码克隆检测方法,将深度语义匹配技术应用到代码克隆检测之中,提高了对于代码检测的检测正确率。
为实现上述目的,本发明提供了如下方案:
一种基于深度语义匹配的代码克隆检测方法,包括如下步骤:
步骤1:基于负采样技术搭建训练样本;
步骤2:搭建代码克隆检测模型,基于训练样本对代码克隆检测模型进行训练;
步骤3:将需要对比的两组代码块输入代码克隆检测模型中进行检测,最终输出相似分数。
可选的,步骤1中,基于负采样技术搭建训练样本,具体为:
获取使用负例中相似但又不同的句子对,基于负采样对其进行调整,其中,将关键词序列拼接在原始检索输入后侧,用于增强原始检索,其中,原始检索的序列为{p_1,p_2,...p_m},关键词序列为{q_1,q_2,...q_m},拼接后的序列为{p_1,p_2,...p_m,q_1,q_2,...,q_n},通过搜索引擎挑选拼接后的负样本,并获取搜索引擎输出的相关性得分。
可选的,步骤2中,搭建代码克隆检测模型,具体为:
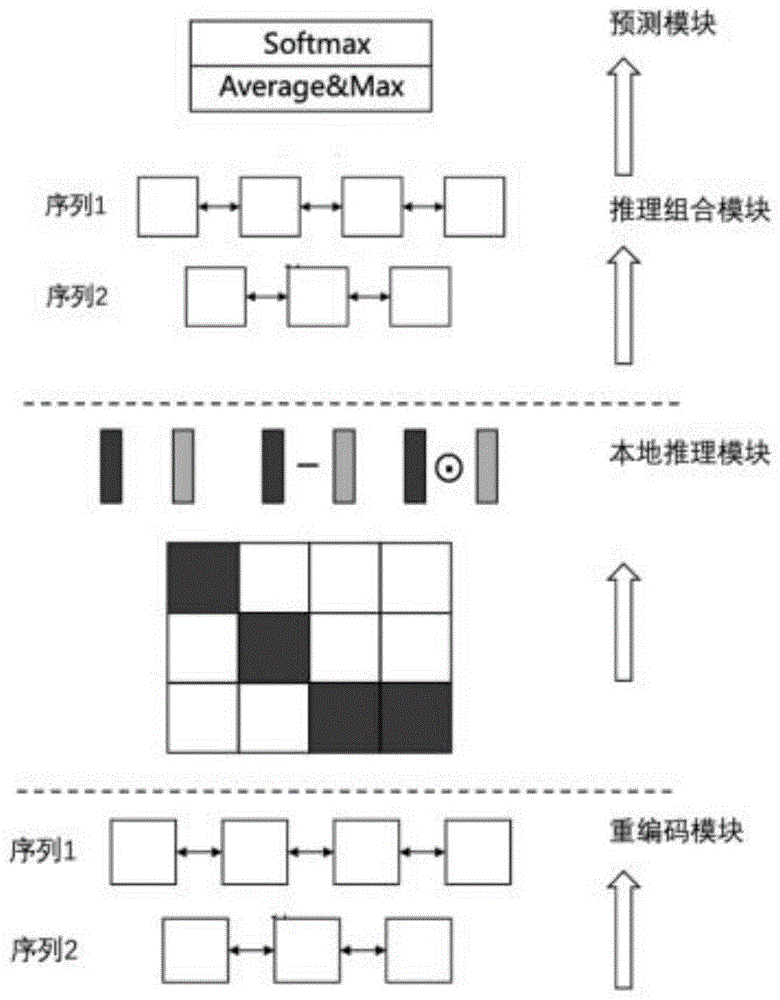
代码克隆检测模型包括重编码模块、本地推理模块、推理组合模块及预测模块,所述重编码模块连接所述本地推理模块,所述本地推理模块连接所述推理组合模块,所述推理组合模块连接所述预测模块。
可选的,步骤3中,将需要对比的两组代码块输入代码克隆检测模型中进行检测,最终输出相似分数,具体为:
将需要对比的两组代码块输入重编码模块中,通过重编码模块的word embedding进行处理,得到代码块的向量表示,将其输入BiLSTM结构中进行重新编码,其中,编码公式为:
式中,BiLSTM(a,i)表示对文本a的第i项进行编码;
将得到的两个代码块的编码向量输入本地推理模块,本地推理模块通过attention使其发生交互以分析其关系,首先使两个代码块的编码向量相乘,分析第一个代码块中某个词与第二个代码块的每个词的联系,将两个代码块的编码向量相乘的结果作为权重值,用第二个代码块的各个词向量乘以权重表示第一个代码块中的某个词,逐个分析,得到两个待计算序列,对两个待计算序列进行分析,计算其差和点积,最终将两个待计算序列进行拼接;
将拼接后的两个待计算序列及其差和点积输入推理组合模块中,推理组合模块将其输入至BiLSTM结构中进行全局分析,提取上下文信息,并对其进行Max池化及Average池化,将结果储存到长度固定的向量之中,得到运算结果v;
将运算结果v发送至预测模块,预测模块将运算结果v放入分类器中,在输出层使用softmax函数,得到相似分数,其中,相似分数为:
Score=S_1·a+S_2·b
式中,S_1为搜索引擎的相关性得分,S_2为语义匹配得分,a及b为两个可调节的参数,用于调整搜索引擎的相关性得分和语义匹配得分对于相似分数的影响大小。
根据本发明提供的具体实施例,本发明公开了以下技术效果:本发明提供的基于深度语义匹配的代码克隆检测方法,该方法首先采用负采样的方法训练模型,提高相似性检测的效果,之后对于需要对比的两组代码块首先通过word embedding得到其向量化表示,然后输入到BiLSTM中进行重编码,再基于attention技术让向量产生交互以分析其联系,并在此基础上使用BiLSTM做一次全局分析,此过程中考虑到不同代码块的长度,所以同时进行了Max池化和Average池化消除影响,最后放入分类器并加入softmax函数得到输出结果。最终的相似分数由使用的ElasticSearch的相关性得分与语义匹配的系数和,该方法提高了代码克隆检测中的准确率,降低了维护成本,保证软件开发的质量。
附图说明
图1为本申请实施例提供的一种基于深度语义匹配的代码克隆检测方法的结构框图。
具体实施方式
本发明的目的是提供一种基于深度语义匹配的代码克隆检测方法,将深度语义匹配技术应用到代码克隆检测之中,提高了对于代码检测的检测正确率。
本发明利用搜索引擎的默认相似分数计算以及经过向量处理之后的匹配分数之后的结合来判断两个代码块的相似程度,能够在很大程度上提高代码克隆检测中对于类型四的检测的正确率。
如图1所示,本发明实施例提供的基于深度语义匹配的代码克隆检测方法,包括如下步骤:
步骤1:基于负采样技术搭建训练样本;
步骤2:搭建代码克隆检测模型,基于训练样本对代码克隆检测模型进行训练;
步骤3:将需要对比的两组代码块输入代码克隆检测模型中进行检测,最终输出相似分数。
步骤1中,基于负采样技术搭建训练样本,具体为:
获取使用负例中相似但又不同的句子对,又被称作hard negatives,提高上述负例的在训练样本中的比例,很大程度上提高模型的效果,基于负采样对其进行调整,其中,将关键词序列拼接在原始检索输入后侧,用于增强原始检索,其中,原始检索的序列为{p_1,p_2,...p_m},关键词序列为{q_1,q_2,...q_m},拼接后的序列为{p_1,p_2,...p_m,q_1,q_2,...,q_n},通过搜索引擎挑选拼接后的负样本,并获取搜索引擎输出的相关性得分。
步骤2中,搭建代码克隆检测模型,具体为:
代码克隆检测模型包括重编码模块、本地推理模块、推理组合模块及预测模块,所述重编码模块连接所述本地推理模块,所述本地推理模块连接所述推理组合模块,所述推理组合模块连接所述预测模块。
步骤3中,将需要对比的两组代码块输入代码克隆检测模型中进行检测,最终输出相似分数,具体为:
将需要对比的两组代码块输入重编码模块中,通过重编码模块的word embedding进行处理,得到代码块的向量表示,将其输入BiLSTM结构中进行重新编码,其中,编码公式为:
式中,BiLSTM(a,i)表示对文本a的第i项进行编码;
将得到的两个代码块的编码向量输入本地推理模块,本地推理模块通过attention使其发生交互以分析其关系,首先使两个代码块的编码向量相乘,分析第一个代码块中某个词与第二个代码块的每个词的联系,将两个代码块的编码向量相乘的结果作为权重值,用第二个代码块的各个词向量乘以权重表示第一个代码块中的某个词,逐个分析,得到两个待计算序列,对两个待计算序列进行分析,计算其差和点积,最终将两个待计算序列进行拼接;
将拼接后的两个待计算序列及其差和点积输入推理组合模块中,推理组合模块将其输入至BiLSTM结构中进行全局分析,提取上下文信息,并对其进行Max池化及Average池化,将结果储存到长度固定的向量之中,得到运算结果v;
将运算结果v发送至预测模块,预测模块将运算结果v放入分类器中,在输出层使用softmax函数,得到相似分数,其中,相似分数为:
Score=S_1·a+S_2·b
式中,S_1为搜索引擎的相关性得分,S_2为语义匹配得分,a及b为两个可调节的参数,用于调整搜索引擎的相关性得分和语义匹配得分对于相似分数的影响大小,便于根据不同的使用场景和语料数据来调整代码克隆测试匹配算法的效果;
设置预设阈值,得到的相似分数达到预设阈值的代码块记为相似代码块。
本发明提供的基于深度语义匹配的代码克隆检测方法,该方法首先采用负采样的方法训练模型,提高相似性检测的效果,之后对于需要对比的两组代码块首先通过wordembedding得到其向量化表示,然后输入到BiLSTM中进行重编码,再基于attention技术让向量产生交互以分析其联系,并在此基础上使用BiLSTM做一次全局分析,此过程中考虑到不同代码块的长度,所以同时进行了Max池化和Average池化消除影响,最后放入分类器并加入softmax函数得到输出结果。最终的相似分数由使用的ElasticSearch的相关性得分与语义匹配的系数和,该方法提高了代码克隆检测中的准确率,降低了维护成本,保证软件开发的质量。