多方联合建模方法、装置、设备及储存介质
文献发布时间:2023-06-19 09:27:35
技术领域
本公开涉及机器学习、安全计算等领域,更具体地,涉及一种多方联合建模方法、装置、设备及储存介质。
背景技术
随着算法和大数据的发展,算法和算力已经不再是阻碍AI发展的瓶颈了。各个领域内真实有效的数据源才是最宝贵的资源。同时数据源之间存在着难以打破的壁垒,在大多数行业中,数据是以孤岛的形式存在的,由于行业竞争、隐私安全、行政手续复杂等问题,即使是在同一个公司的不同部门之间实现数据整合也面临着重重阻力,在现实中想要将分散在各地、各个机构的数据进行整合几乎是不可能的,或者说所需的成本是巨大的。
在此部分中描述的方法不一定是之前已经设想到或采用的方法。除非另有指明,否则不应假定此部分中描述的任何方法仅因其包括在此部分中就被认为是现有技术。类似地,除非另有指明,否则此部分中提及的问题不应认为在任何现有技术中已被公认。
发明内容
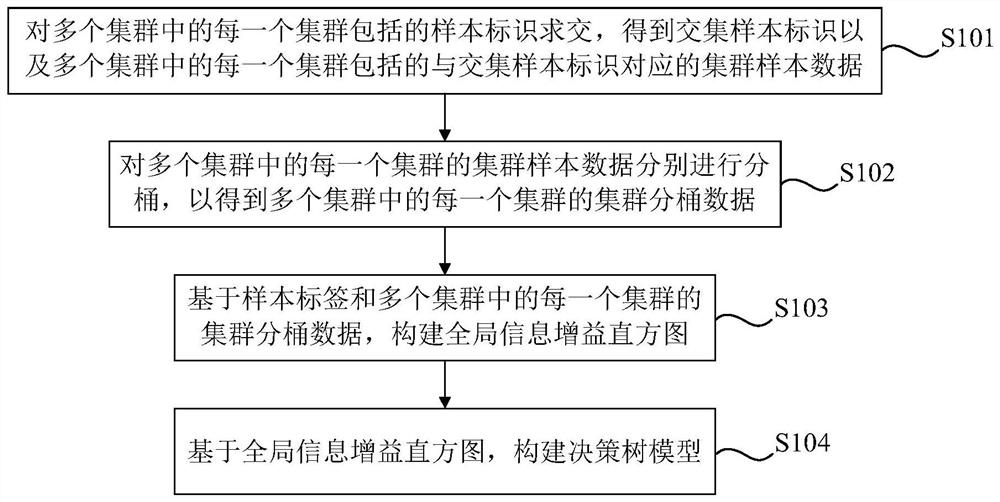
根据本公开的一方面,提供了一种多方联合建模方法,包括:对多个集群中的每一个集群包括的样本标识求交,得到交集样本标识以及多个集群中的每一个集群包括的与交集样本标识对应的集群样本数据,其中,多个集群中的每一个集群包括的样本标识和集群样本数据均分布保存在该相应集群的多个客户端中;对多个集群中的每一个集群的集群样本数据分别进行分桶,以得到多个集群中的每一个集群的集群分桶数据;基于样本标签和多个集群中的每一个集群的集群分桶数据,构建全局信息增益直方图,其中,样本标签为每个样本的真实值,并且样本标签保存在多个集群中的一个特定集群;以及基于全局信息增益直方图,构建决策树模型。
根据本公开的另一方面,还提供了一种基于分布式系统的多方联合预测方法,包括:将预测样本输入决策树模型;针对决策树模型的每一棵子决策树,获取根节点的所属集群;与集群通信,获取根节点的特征;将预测样本的所述根节点的特征的特征数据发送至节点所属集群,获取子节点的所属集群;迭代上述过程,获取所述每一棵子决策树对预测样本的预测值;以及将每一棵子决策树对预测样本的预测值求和,得到预测样本的预测值。
根据本公开的一方面,提供了一种基于分布式系统的多方联合建模装置,包括:求交模块,被配置用于将所述多个集群包括的数据进行求交,使所述多个集群中的每一个得到相应的集群样本数据;分桶模块,被配置用于对所述多个集群中每一个的集群样本数据分别进行分桶,得到所述多个集群中每一个的集群分桶数据;第一构建模块,被配置用于基于样本标签和所述多个集群分桶数据,构建全局信息增益直方图;以及第二构建模块,被配置用于基于所述全局信息增益直方图,构建决策树模型。
根据本公开的另一方面,还提供了一种电子设备,包括:处理器;以及存储程序的存储器,上述程序包括指令,并且指令在由处理器执行时使处理器执行根据上述的多方联合建模方法和/或根据上述的多方联合预测方法。
根据本公开的另一方面,还提供了一种存储程序的计算机可读存储介质,上述程序包括指令,并且指令在由电子设备的处理器执行时,致使电子设备执行根据上述的多方联合建模方法和/或根据上述的多方联合预测方法。
本公开的技术方案通过对分布式数据进行分桶以及对分布式数据构建信息增益直方图,实现了基于分布式系统的多方联合建模方法,从而提升多方联合建模的速度,并且能够在数据量大的场景下完成建模。
附图说明
附图示例性地示出了实施例并且构成说明书的一部分,与说明书的文字描述一起用于讲解实施例的示例性实施方式。所示出的实施例仅出于例示的目的,并不限制权利要求的范围。在所有附图中,相同的附图标记指代类似但不一定相同的要素。
图1-图2是示出根据示例性实施例的多方联合建模方法的流程图;
图3是示出根据示例性实施例的分布式系统的组成框图;
图4是示出根据示例性实施例的对多个集群中的每一个集群的集群样本数据分别进行分桶的流程图;
图5是示出根据示例性实施例的分桶过程的示意图;
图6是示出根据示例性实施例的基于当前特征的特征数据生成至少一个数据桶的流程图;
图7是示出根据示例性实施例的构建全局信息增益直方图的流程图;
图8是示出根据示例性实施例的构建第一信息增益直方图的流程图;
图9是示出根据示例性实施例的得到待分裂节点的特征的第一信息增益子直方图或第一候选分裂增益的流程图;
图10是示出根据示例性实施例的构建第一信息增益子直方图的流程图;
图11是示出根据示例性实施例的多方联合预测方法的流程图;
图12是示出根据示例性实施例的多方联合建模装置的组成框图;
图13是示出能够应用于示例性实施例的示例性计算设备的结构框图。
具体实施方式
在本公开中,除非另有说明,否则使用术语“第一”、“第二”等来描述各种要素不意图限定这些要素的位置关系、时序关系或重要性关系,这种术语只是用于将一个元件与另一元件区分开。在一些示例中,第一要素和第二要素可以指向该要素的同一实例,而在某些情况下,基于上下文的描述,它们也可以指代不同实例。
在本公开中对各种所述示例的描述中所使用的术语只是为了描述特定示例的目的,而并非旨在进行限制。除非上下文另外明确地表明,如果不特意限定要素的数量,则该要素可以是一个也可以是多个。此外,本公开中所使用的术语“和/或”涵盖所列出的项目中的任何一个以及全部可能的组合方式。
相关技术中,现有的多方联合建模方法速度较慢,尤其在数据量大的场景下,受限于设备性能、存储容量等因素,无法进行多方联合建模,从而在实际应用中具有很大的局限性。
为了解决上述技术问题,本公开提供一种基于分布式系统的多方联合建模方法:对多个集群间的样本标识求交,得到每个集群的集群样本数据;对每个集群的集群样本数据进行分桶,得到集群分桶数据;基于样本标签和每一个集群的集群分桶数据,构建全局信息增益直方图;基于全局信息增益直方图,构建决策树模型。由此,通过对分布式数据进行分桶以及对分布式数据构建信息增益直方图,实现了基于分布式系统的多方联合建模方法,从而提升多方联合建模的速度,并且能够在数据量大的场景下完成建模。
以下将结合附图对本公开的多方联合建模方法进行进一步描述。
图1是示出根据本公开示例性实施例的基于分布式系统的多方联合建模方法的流程图。如图1所示,多方联合建模方法可以包括:步骤S101、对多个集群中的每一个集群包括的样本标识求交,得到交集样本标识以及多个集群中的每一个集群包括的与交集样本标识对应的集群样本数据;步骤S102、对多个集群中的每一个集群的集群样本数据分别进行分桶,以得到多个集群中的每一个集群的集群分桶数据;步骤S103、基于样本标签和多个集群中的每一个集群的集群分桶数据,构建全局信息增益直方图;以及步骤S104、基于全局信息增益直方图,构建决策树模型。由此,通过建立分布式系统,将集群的数据分布存放在集群的多个客户端,并使用客户端对分布式数据进行初步分桶以及构建信息增益子直方图,能够大幅提升多方联合建模的速度,使得模型能够支持在更丰富的场景下进行快速多方联合建模。
根据一些实施例,分布式系统包括多个集群,每一个集群包括一个服务器和多个客户端。在一个示例性实施例中,如图3所示,分布式系统3000包括集群3100、集群3200和集群3300,每个集群内包括一个服务器和三个客户端,例如集群3100包括服务器3110和客户端3101,集群3200包括服务器3210和客户端3201,集群3300包括服务器3310和客户端3301。服务器的主要功能可以包括协调本集群内的多个客户端、指示客户端完成分桶和构建直方图等任务、整合客户端上传的信息、下发信息至客户端、完成一些计算功能以及与其他集群的服务器进行通信等。在一个示例性实施例中,集群间的通信可以使用Paillier密文进行加密。客户端的主要功能可以包括存储数据、接收服务器的指令完成分桶和构建直方图等任务、上传信息至服务器等。集群内的通信可以没有隐私需求。在一个示例性实施例中,客户端只与本集群的服务器通信。
每一个集群可以包括若干分布存放在集群的多个客户端的原始样本数据,样本数据包括样本标识。对每一个集群包括的全部样本标识求交,得到共有样本标识。每一个集群选取集群内的原始样本数据中与共有样本标识重合的样本作为该集群的集群样本数据。
在一个示例性实施例中,步骤S101可以包括:每一个集群的服务器汇总本集群内的全部样本标识;基于OT安全协议实现集群间的样本标识求交,每一个集群得到相同的共有样本标识;每一个集群的服务器将共有样本标识发送至本集群的多个客户端,指示客户端将共有样本标识和客户端包括的原始样本数据的样本标识求交,得到每一个客户端的客户端样本数据。集群样本数据例如可以包括保存在相应的多个客户端的多个客户端的样本数据。
根据一些实施例,集群样本数据和客户端样本数据均可以包括样本标识和至少一个特征,如图4所示,步骤S102、对多个集群中的每一个集群的集群样本数据分别进行分桶,以得到多个集群中的每一个集群的集群分桶数据可以包括:步骤S10201、针对多个集群中的每一个集群,遍历该集群的集群样本数据的至少一个特征;步骤S10202、基于当前特征的特征数据,生成至少一个数据桶;以及步骤S10203、整合所有特征对应的数据桶,得到该集群的集群分桶数据。由此,通过对集群样本数据进行分桶,能够减少需要计算的分裂点及其相应的信息增益的数量,从而大大提升建模的速度;同时,由于分桶会抹去桶内所有样本的特征数据,因此同样可以作为在隐私要求下的多方联合建模的基础。
分桶是基于特征信息对特征数据进行特征离散化处理的过程。根据一些实施例,数据桶可以包括样本标识、桶的值、所属客户端、所属特征中的至少一者。在一个示例性实施例中,如图5所示,数据501包括样本标识1-15和一个选定特征的特征数据。分桶过程例如可以包括:将选定特征的特征数据排序,生成排序后的特征数据502;基于预设分桶规则,将特征数据分为若干个数据桶5001,得到分桶数据503。每个数据桶的所属客户端可以包括被分到同一个数据桶的每一个特征数据所在客户端、每个数据桶的所述特征可以为分桶过程基于的特征、每个数据桶的样本标识可以包括分到被同一个数据桶的每一个特征数据对应的样本标识、每个数据桶的值例如可以是分到同一个数据桶的全部特征数据的平均值、中位数、最小值、最大值或者通过其他计算方法得到的值,在此不做限定。在一个示例性实施例中,如图5所示,每个数据桶5001的值可以是分到同一个数据桶的全部特征数据的中位数。
根据一些实施例,待合并数据桶可以包括样本标识、桶的值、所属客户端、所属特征中的至少一者,如图6所示,步骤S10202、基于当前特征的特征数据,生成至少一个数据桶可以包括:步骤S602、判断当前特征的特征数据是否分布在同一个客户端;步骤S603、响应于当前特征的特征数据分布在多个客户端,指示多个客户端中每一个客户端对各自客户端样本数据包括的当前特征的特征数据进行分桶,生成当前特征的至少一个待合并数据桶,并将至少一个待合并数据桶上传至多个客户端对应的服务器;以及步骤S604、将接收到的多个客户端上传的至少一个待合并数据桶进行合并,生成至少一个数据桶。由此,在当前特征的特征数据分布在多个客户端的情况下,通过指示每个客户端对该客户端包括的样本数据进行预分桶,再由服务器将部分桶的值相同或相近的桶合并为同一个桶,实现了在当前特征的特征数据分布在多个客户端的情况下对分布式数据的分桶。相比于将多个客户端的当前特征的全部特征数据传送至服务器,由服务器对全部特征数据进行排序、分桶,上述方法能够显著加快分桶效率,从而大幅提升建模速度。
根据一些实施例,步骤S604、将接收到的多个客户端上传的至少一个待合并数据桶进行合并,生成至少一个数据桶例如可以包括:将当前特征的所有待合并数据桶按桶的值进行排序;将连续的多个桶的值相同或相近的一个或多个待合并数据桶合并为一个数据桶,合并后的数据桶包括的样本标签可以为被合并的一个或多个待合并数据桶包括的全部标签,合并后的数据桶所属客户端可以包括被合并的一个或多个待合并数据桶的所属客户端,合并后的数据桶所述特征可以为当前特征,合并后数据桶的值例如可以为被合并的一个或多个待合并数据桶的值的平均值、中位数、最小值、最大值或者通过其他计算方法得到的值,在此不做限定。
根据一些实施例,如图6所示,步骤S10202、基于当前特征的特征数据,生成至少一个数据桶可以包括:步骤S605、将合并而成的至少一个数据桶中的每一个数据桶发送至该数据桶的所属客户端。该所属客户端的客户端分桶数据包括被合并的至少一个数据桶。
根据一些实施例,如图6所示,步骤S10202、基于当前特征的特征数据,生成至少一个数据桶可以包括:步骤S606、响应于当前特征的特征数据分布在同一个客户端,指示同一个客户端对当前特征的特征数据进行分桶,生成至少一个数据桶,并将至少一个数据桶上传至与同一个客户端相应的服务器。图6中步骤S601、步骤S607分别与图4中步骤S10201、S10203类似。执行完步骤S605、步骤S606后,可以执行步骤S607。由此,在当前特征的全部特征数据分布在同一个客户端的情况下,直接将该客户端的分桶结果作为最终结果,从而可以减少由服务器进行分桶而带来的工作量,进而提升建模速度。
上述技术方案通过指示客户端对其客户端样本数据进行分桶,生成待合并数据桶或数据桶,再由服务器将待合并数据桶进行合并,并结合其他数据桶得到集群分桶数据和各个客户端的客户端分桶数据,实现了对分布式数据的快速分桶,从而能够大幅提升建模速度,同时使得模型能够支持更丰富的场景。
根据一些实施例,多个集群包括第一集群和至少一个第二集群,如图2所示,多方联合建模方法还可以包括:步骤S202、针对第一集群的服务器,生成公钥、私钥对;以及步骤S203、将公钥与建模参数发送至至少一个第二集群中每一个第二集群的服务器。图2中的步骤S201、步骤S204与图1中的步骤S101、步骤S102类似。由此,通过使用同态加密,能够使得第二集群使用加密的数据进行运算得到的加密信息经第一集群并解密后得到的结果与未经加密的运算结果相同,从而能够作为在隐私要求下的多方联合建模的基础。
建模参数例如可以包括最大迭代次数、学习率、停止分裂条件、模型收敛条件等。建模参数对于参与建模的每一个集群都是公开的,不需要加密。
根据一些实施例,第一集群的集群样本数据还包括样本标签,如图7所示,步骤S103、基于样本标签和多个集群中的每一个集群的集群分桶数据,构建全局信息增益直方图包括:步骤S10301、获取当前模型对与第一集群的集群分桶数据的每一个样本标识对应的每一个样本的预测值;步骤S10302、基于预测值和样本标签,计算一阶梯度数据和二阶梯度数据;以及步骤S10303、基于一阶梯度数据、二阶梯度数据和多个集群中的每一个集群的集群分桶数据,构建全局信息增益直方图。由此,通过计算一阶梯度数据和二阶梯度数据,结合每个集群的集群特征数据,能够构建全局信息增益直方图,从而后续能够基于全局信息增益直方图确定最优分裂点,以构建决策树。同时,使用信息增益直方图能够减少需要计算的分裂点及其分裂阈值的数量,并且可以进行直方图差加速,从而提升建模速度。
根据一些实施例,当前模型包括一棵或多棵子决策树。本公开构建的决策树模型例如可以是梯度提升决策树模型,XGBoost模型,LightGBM模型,也可以是其他模型,在此不作限定。当前模型每个叶子结点包括至少一个样本标识,表明被分到这个节点的样本标识。当前模型包括的一棵或多棵子决策树的结构、所有节点的所属集群、所有叶子节点包括的样本标识可以对全部集群公开。样本预测值的计算方法可以是将每一个子决策树对样本的预测值求和,得到模型对样本的预测值。
一阶梯度数据和二阶梯度数据可以是求出模型设定的目标函数的一阶梯度和二阶梯度,将样本的预测值和样本标签带入一阶梯度和二阶梯度,从而得到样本的一阶梯度数据和二阶梯度数据。
信息增益直方图可以包括多个与数据桶一一对应的直方图桶,每一个直方图桶可以用于表示对应的数据桶的信息增益。每一个直方图桶中包括对应的数据桶的全部样本的一阶梯度和、二阶梯度和以及数据桶包括的样本数量。
根据一些实施例,如图2所示,步骤S10303、基于一阶梯度数据、二阶梯度数据和多个集群中的每一个集群的集群分桶数据,构建全局信息增益直方图包括:步骤S207、将一阶梯度数据和二阶梯度数据加密后发送至至少一个第二集群中的每一个第二集群的服务器;步骤S208、获取当前模型的至少一个待分裂节点,待分裂节点包括至少一个样本标识;步骤S209、基于一阶梯度数据、二阶梯度数据、第一集群的集群分桶数据和至少一个待分裂节点,构建第一信息增益直方图;步骤S211、接收来自至少一个第二集群中每一个的服务器的至少一个密文信息增益直方图;步骤S212、将至少一个密文信息增益直方图解密,得到与至少一个密文信息增益直方图一一对应的至少一个第二信息增益直方图;以及步骤S213、将第一信息增益直方图和至少一个第二信息增益直方图合并,得到全局信息增益直方图。图2中的步骤S205-步骤S206分别与图7中的步骤S10301-步骤S10302类似。由此,通过将加密后的梯度发送至至少一个第二集群,接收并解密来自至少一个第二集群发送的密文信息增益直方图,使得双方可以在不获取对方的梯度数据和样本数据的情况下得到相应的至少一个第二信息增益直方图。结合第一集群的第一信息增益直方图和至少一个第二信息增益直方图,实现在隐私要求下构建全局信息增益直方图。
待分裂节点例如可以是最后一棵子决策树的满足允许分裂条件的部分叶子结点。允许分裂条件例如可以是叶子结点包括的样本标识的数量小于预设值、叶子结点的深度小于预设深度等,在此不作限定。作为一种叶子结点,待分裂节点可以包括多个样本标识,表示被模型分到这个节点的样本。
根据一些实施例,如图8所示,步骤S209、基于一阶梯度数据、二阶梯度数据、第一集群的集群分桶数据和至少一个待分裂节点,构建第一信息增益直方图包括:步骤S20901、针对至少一个待分裂节点中的每一个待分裂节点,遍历第一集群的集群分桶数据的至少一个特征;步骤S20902、基于该待分裂节点和当前特征的特征数据,得到该待分裂节点的当前特征的第一信息增益子直方图或第一候选分裂增益;以及步骤S20903、将每一个待分裂节点的第一集群的集群分桶数据的至少一个特征中每一个特征的第一信息增益子直方图或第一候选分裂增益合并,得到第一信息增益直方图。由此,对每一个待分裂节点与每一个第一集群的特征构建第一信息增益子直方图或第一候选分裂增益,能够得到第一信息增益直方图,从而后续能够得到全局信息增益直方图以构建决策树。
根据一些实施例,如图9所示,步骤S20902、基于该待分裂节点和当前特征的特征数据,得到待分裂节点的当前特征的第一信息增益子直方图或第一候选分裂增益:步骤S902、判断当前特征的特征数据是否分布在同一个客户端;步骤S903、响应于当前特征的特征数据分布在多个客户端,指示多个客户端中的每一个客户端基于一阶梯度数据、二阶梯度数据、该客户端的客户端分桶数据和该待分裂节点构建待合并第一信息增益子直方图,并将待合并第一信息增益子直方图上传至多个客户端对应的服务器;以及步骤S904、将接收到的多个客户端上传的多个待合并第一信息增益子直方图合并,构建第一信息增益子直方图。由此,当前特征的特征数据分布在多个客户端的情况下,通过指示每个客户端生成待合并第一信息增益子直方图,再由服务器将待合并子直方图合并,实现了在基于当前待分裂节点的第一集群的当前特征的特征数据分布在多个客户端的情况下对当前待分裂节点与当前特征构建第一信息增益子直方图。相比于由第一集群的服务器直接构建第一信息增益子直方图,上述方法能够使得多个客户端并行构建子直方图,从而提升了建模速度。
根据一些实施例,第一信息增益子直方图包括至少一个直方图桶,至少一个直方图桶与所有所属特征为特征的数据桶一一对应,待合并第一信息增益子直方图包括至少一个待合并直方图桶,至少一个待合并直方图桶与所有所属特征为特征的数据桶一一对应,直方图桶和待合并直方图桶均包括一阶梯度和、二阶梯度和中的至少一者,如图10所示,步骤S904、将接收到的多个客户端上传的多个待合并第一信息增益子直方图合并,构建第一信息增益子直方图包括:步骤S90401、将接收到的多个客户端上传的多个待合并第一信息增益子直方图中的至少一个待合并直方图桶进行合并,生成至少一个直方图桶;以及步骤S90402、基于至少一个直方图桶,构建第一信息增益子直方图。由此,通过将与同一个数据桶对应的待合并直方图桶合并为一个直方图桶,能够构建第一信息增益子直方图,实现了分布式构建第一信息增益子直方图,从而能够后续与其他特征的第一信息增益子直方图合并,得到第一信息增益直方图。
直方图桶与待合并直方图桶均可以包括一阶梯度和、二阶梯度和以及直方图桶或待合并直方图桶对应的数据桶包括的样本标识与当前待分裂节点包括的样本标识的交集部分的样本标识数量。
根据一些实施例,步骤S90401、将接收到的多个客户端上传的多个待合并第一信息增益子直方图中的至少一个待合并直方图桶进行合并,生成至少一个直方图桶可以包括:将与每一个当前特征的数据桶对应的一个或多个待合并直方图桶合并,得到与上述数据桶对应的直方图桶。该直方图桶的一阶梯度和可以为被合并的一个或多个待合并直方图桶的一阶梯度和的总和,该直方图桶的二阶梯度和可以为被合并的一个或多个待合并直方图桶的二阶梯度和的总和,该直方图桶的样本标识数量可以为被合并的一个或多个待合并直方图桶的样本标识数量的总和。
根据一些实施例,如图9所示,步骤S20902、基于该待分裂节点和当前特征的特征数据,得到待分裂节点的当前特征的第一信息增益子直方图或第一候选分裂增益可包括:步骤S905、响应于当前特征的全部特征数据分布在同一客户端,指示同一客户端基于一阶梯度数据、二阶梯度数据、同一客户端的客户端分桶数据和待分裂节点构建第一信息增益子直方图,基于第一信息增益子直方图计算第一候选分裂增益,并将第一候选分裂增益上传至第一集群的服务器。图9中的步骤S901、步骤S906分别与图8中的步骤S20901、步骤S20903类似。在执行完步骤S904、步骤S905后,可以执行步骤S906。由此,在当前特征的全部特征数据分布在同一客户端的情况下,直接构建当前待分裂节点的当前特征的第一信息增益子直方图,并基于第一信息增益子直方图计算第一候选分裂增益,从而可以减少由服务器构建直方图而带来的工作量,进而提升建模速度。
第一候选分裂增益可以是当前待分裂节点的当前特征的最大增益,可以通过计算第一信息增益子直方图的每一个直方图桶对应的分裂增益,并选取其中的最大值而得到。直方图桶对应的分裂增益可以通过如下方法计算得到:在当前待分裂节点与当前特征下,获取全部直方图桶的一阶梯度数据总和、二阶梯度数据总和以及样本标识数量总和,这三个总和在之前的分裂增益计算过程中已经得到,称为父节点信息增益原始数据;计算比直方图桶对应的数据桶的值小的所有数据桶对应的直方图桶的上述三个总和,称为左子节点信息增益原始数据;基于父节点信息增益原始数据与左子节点信息增益原始数据,通过作差可以得到右子节点信息增益原始数据;针对三个节点,分别基于信息增益原始数据计算信息增益;以及,使用左子节点信息增益加右子节点信息增益减父节点信息增益,得到分裂增益。信息增益的计算方法例如可以是一阶梯度总和的平方除以二阶梯度总和和调和参数的和,可以是一阶梯度总和的平方除以样本标识数量总和,也可以是其他计算方法,在此不作限定。
上述技术方案通过指示客户端构建待合并第一信息增益子直方图或直接计算第一候选分裂增益,再由服务器将待合并第一信息增益子直方图合并,并结合第一候选分裂增益得到第一信息增益直方图,实现了快速构建第一信息增益直方图,从而能够提升建模速度,同时使得模型能够支持更丰富的场景。
根据一些实施例,如图2所示,步骤S10303、基于一阶梯度数据、二阶梯度数据和多个集群中的每一个集群的集群分桶数据,构建全局信息增益直方图可包括:步骤S210、基于密文一阶梯度数据、密文二阶梯度数据、第二集群的集群分桶数据和至少一个待分裂节点构建密文信息增益直方图。在一个示例性实施例中,可以采用类似上述步骤S901-步骤S906的方法,例如可以分别使用密文一阶梯度数据和密文二阶梯度数据代替一阶梯度数据和二阶梯度数据,得到相应的密文信息增益直方图。
根据一些实施例,如图2所示,步骤S104、基于全局信息增益直方图,构建决策树模型包括:步骤S214、基于全局新信息增益直方图,确定最优分裂点;步骤S215、指示最优分裂点所在的客户端分裂最优分裂点;步骤S216、对分裂过程进行迭代,直至达到终止分裂条件,生成子决策树;以及步骤S217、对子决策树生成过程进行迭代,直到达到终止迭代条件,得到决策树模型。由此,通过确定并分裂最优分裂点,得到新的叶子结点,并通过重复迭代上述步骤,得到决策树模型。
根据一些实施例,步骤S215、指示最优分裂点所在的客户端分裂最优分裂点包括:指示客户端基于最优分裂点和客户端的客户端分桶数据计算分裂阈值,得到分裂出的叶子节点包括的样本标识,并将叶子节点上传至服务器;以及将最优分裂点所在节点的所属集群和叶子节点同步到除本集群外的多个集群。由此,通过分裂最优分裂点,得到新的叶子结点,并将最优分裂点所在节点的所属集群可新的叶子节点同步到每一个集群,实现集群间模型的共享。
最优分裂点可以是全部待分裂节点与全部特征中的分裂增益最大的直方图桶。计算分裂阈值可以基于如下方法计算得到:对最优分裂点对应的数据桶的样本标识与最优分裂点对应的待分裂节点的样本标识的交集部分对应的特征数据进行排序;以排序后的每两个相邻样本的特征数据的平均作为分裂阈值,计算分裂增益;选取分裂增益最大的分裂阈值,作为最优分裂点的分裂阈值。每个节点的所属集群是公开的,而分裂阈值保存在其所属集群,从而在预测阶段,可以通过多方共享的模型中包括的节点的所属集群找到相应的集群,再将数据发送至该集群,获取下一个节点,直至得到最终的预测值。
根据本公开的另一方面,还提供一种基于分布式系统的多方联合预测方法,如图11所示,多方联合预测方法可以包括:步骤S1101、将预测样本输入决策树模型;步骤S1102、针对决策树模型的每一棵子决策树,获取根节点的所属集群;步骤S1103、与该所属集群通信,获取根节点的特征;步骤S1104、将预测样本的根节点的特征的特征数据发送至该所属集群,获取子节点的所属集群;步骤S1105、迭代上述过程,获取每一棵子决策树对预测样本的预测值;以及步骤S1106、将每一棵子决策树对预测样本的预测值求和,得到预测样本的预测值。由此,通过不断与当前子决策树的当前节点的所属集群通信并返回下一个节点,能够计算出每一个子决策树对样本的预测值,从而得到模型对样本的预测值。由于决策树模型由多个集群共享而分裂阈值仅保存在节点所属集群,因此模型的完整内容对任一集群都是不公开的,从而需要结合每一个集群保存在集群内的信息实现对样本的预测,实现了支持隐私场景的多方联合建模。
根据本公开的另一方面,还提供一种多方联合建模装置。如图12所示,多方联合建模装置1200可以包括:求交模块1201,被配置用于对多个集群中的每一个集群包括的样本标识求交,得到交集样本标识以及多个集群中的每一个集群包括的与交集样本标识对应的集群样本数据;分桶模块1202,被配置用于对多个集群中每一个的集群样本数据分别进行分桶,得到多个集群中每一个的集群分桶数据;第一构建模块1203,被配置用于基于样本标签和多个集群分桶数据,构建全局信息增益直方图;以及第二构建模块1204,被配置用于基于全局信息增益直方图,构建决策树模型。
根据本公开的另一方面,还提供一种电子设备,可以包括:处理器;以及存储程序的存储器,所述程序包括指令,所述指令在由所述处理器执行时使所述处理器执行根据上述的多方联合建模方法。
根据本公开的另一方面,还提供一种存储程序的计算机可读存储介质,所述程序包括指令,所述指令在由电子设备的处理器执行时,致使所述电子设备执行根据上述的多方联合建模方法。
参见图13所示,现将描述计算设备13000,其是可以应用于本公开的各方面的硬件设备(电子设备)的示例。计算设备13000可以是被配置为执行处理和/或计算的任何机器,可以是但不限于工作站、服务器、台式计算机、膝上型计算机、平板计算机、个人数字助理、机器人、智能电话、车载计算机或其任何组合。上述多方联合建模方法可以全部或至少部分地由计算设备13000或类似设备或系统实现。
计算设备13000可以包括(可能经由一个或多个接口)与总线13002连接或与总线13002通信的元件。例如,计算设备13000可以包括总线13002、一个或多个处理器13004、一个或多个输入设备13006以及一个或多个输出设备13008。一个或多个处理器13004可以是任何类型的处理器,并且可以包括但不限于一个或多个通用处理器和/或一个或多个专用处理器(例如特殊处理芯片)。输入设备13006可以是能向计算设备13000输入信息的任何类型的设备,并且可以包括但不限于鼠标、键盘、触摸屏、麦克风和/或遥控器。输出设备13008可以是能呈现信息的任何类型的设备,并且可以包括但不限于显示器、扬声器、视频/音频输出终端、振动器和/或打印机。计算设备13000还可以包括非暂时性存储设备13010或者与非暂时性存储设备13010连接,非暂时性存储设备可以是非暂时性的并且可以实现数据存储的任何存储设备,并且可以包括但不限于磁盘驱动器、光学存储设备、固态存储器、软盘、柔性盘、硬盘、磁带或任何其他磁介质,光盘或任何其他光学介质、ROM(只读存储器)、RAM(随机存取存储器)、高速缓冲存储器和/或任何其他存储器芯片或盒、和/或计算机可从其读取数据、指令和/或代码的任何其他介质。非暂时性存储设备13010可以从接口拆卸。非暂时性存储设备13010可以具有用于实现上述方法和步骤的数据/程序(包括指令)/代码。计算设备13000还可以包括通信设备13012。通信设备13012可以是使得能够与外部设备和/或与网络通信的任何类型的设备或系统,并且可以包括但不限于调制解调器、网卡、红外通信设备、无线通信设备和/或芯片组,例如蓝牙TM设备、1302.11设备、WiFi设备、WiMax设备、蜂窝通信设备和/或类似物。
计算设备13000还可以包括工作存储器13014,其可以是可以存储对处理器13004的工作有用的程序(包括指令)和/或数据的任何类型的工作存储器,并且可以包括但不限于随机存取存储器和/或只读存储器设备。
软件要素(程序)可以位于工作存储器13014中,包括但不限于操作系统13016、一个或多个应用程序13018、驱动程序和/或其他数据和代码。用于执行上述方法和步骤的指令可以被包括在一个或多个应用程序13018中,并且上述多方联合建模方法可以通过由处理器13004读取和执行一个或多个应用程序13018的指令来实现。更具体地,上述多方联合建模方法中,步骤S101-步骤S104可以例如通过处理器13004执行具有步骤S101-步骤S104的指令的应用程序13018而实现。此外,上述多方联合建模方法中的其它步骤可以例如通过处理器13004执行具有执行相应步骤中的指令的应用程序13018而实现。软件要素(程序)的指令的可执行代码或源代码可以存储在非暂时性计算机可读存储介质(例如上述存储设备13010)中,并且在执行时可以被存入工作存储器13014中(可能被编译和/或安装)。软件要素(程序)的指令的可执行代码或源代码也可以从远程位置下载。
还应该理解,可以根据具体要求而进行各种变型。例如,也可以使用定制硬件,和/或可以用硬件、软件、固件、中间件、微代码,硬件描述语言或其任何组合来实现特定元件。例如,所公开的方法和设备中的一些或全部可以通过使用根据本公开的逻辑和算法,用汇编语言或硬件编程语言(诸如VERILOG,VHDL,C++)对硬件(例如,包括现场可编程门阵列(FPGA)和/或可编程逻辑阵列(PLA)的可编程逻辑电路)进行编程来实现。
还应该理解,前述方法可以通过服务器-客户端模式来实现。例如,客户端可以接收用户输入的数据并将所述数据发送到服务器。客户端也可以接收用户输入的数据,进行前述方法中的一部分处理,并将处理所得到的数据发送到服务器。服务器可以接收来自客户端的数据,并且执行前述方法或前述方法中的另一部分,并将执行结果返回给客户端。客户端可以从服务器接收到方法的执行结果,并例如可以通过输出设备呈现给用户。
还应该理解,计算设备13000的组件可以分布在网络上。例如,可以使用一个处理器执行一些处理,而同时可以由远离该一个处理器的另一个处理器执行其他处理。计算系统13000的其他组件也可以类似地分布。这样,计算设备13000可以被解释为在多个位置执行处理的分布式计算系统。
虽然已经参照附图描述了本公开的实施例或示例,但应理解,上述的方法、系统和设备仅仅是示例性的实施例或示例,本发明的范围并不由这些实施例或示例限制,而是仅由授权后的权利要求书及其等同范围来限定。实施例或示例中的各种要素可以被省略或者可由其等同要素替代。此外,可以通过不同于本公开中描述的次序来执行各步骤。进一步地,可以以各种方式组合实施例或示例中的各种要素。重要的是随着技术的演进,在此描述的很多要素可以由本公开之后出现的等同要素进行替换。
- 多方联合建模方法、装置、设备及储存介质
- 联合多方特征数据的模型预测方法、装置、设备及介质