一种表数据批量自动比对的控制方法及装置
文献发布时间:2023-06-19 09:54:18
技术领域
本发明属于数据处理领域,具体地,涉及一种表数据批量自动比对的控制方法及装置。
背景技术
在现有技术中,在比对数据表时,是直接做数据内容的比对,当发现内容有差异后,要通过人工一张张的比对,需要人工获取发生差异的数据,并定位错误,由于大量的比对任务,人工操作比较繁重,而且人工操作的过程中,出错率非常高。
在数据测试中经常需要比对上百张表数据,核对新老hive集群的表数据,编写总量查询和明细查询的sql非常耗时,且需要人工手动一张一张的进行表总量和明细比对,测试效率低,重复性的工作使得枯燥感强。
例如,在现有技术的步骤中,首先核对总量,(1)编写总量查询的SQL,select p_dt,count(*)as cnt fromdm_db.dm_common_appunion_info_export2ckwhere p_dt in('2020-07-16','2020-07-26')group by p_dt;然后,在老集群的hue中执行上述SQL,查询每天的数据总量;紧接着,在新集群的hue中执行上述SQL,查询每天的数据总量;最后,比对新老集群的查询结果集。进一步地,条目数在10条以内,直接观察有无差异数据;条目数在10条以上时,导出新老集群的查询结果集,然后使用Excel实现比对:排序,Excel公式比较。
然后,核对明细,首先,编写明细查询的SQL(拼接明细的方法:找出列并对列进行处理)SELECT cat_ws,COUNT(*)AS cntFROM(SELECT concat_ws('$',CAST(type ASstring),CAST(name AS string),CAST(oldver AS string),CAST(newver AS string),CAST(result_Json AS string),CAST(channelver AS string),CAST(product_type ASstring),CAST(p_dt AS string))AS cat_wsFROM dm_db.dm_safe_upgrade_touch_link_stat_dayWHERE p_dt IN('2020-08-05'))aGROUP BY cat_ws;然后,在老集群的hue中执行上述SQL,然后导出结果集;紧接着,在新集群的hue中执行上述SQL,然后导出结果集;最后,使用Excel函数比较查询结果集。而现有技术的缺点在于:依次处理,等待时间长;导出的文件容易出现乱码;对于Json类型的数据,会因Key顺序不一致导致结果不准确。
而目前并没有一种能够解决上述技术问题的技术方案,具体地,并没有一种表数据批量自动比对的控制方法及装置。
发明内容
针对现有技术存在的技术缺陷,本发明的目的是提供一种表数据批量自动比对的控制方法及装置,根据本发明的一个方面,提供了一种表数据批量自动比对的控制方法,包括如下步骤:
a:基于Python的数据分析模块Pandas对多张待比对表数据中的至少一张源表以及目标表的总量结果集进行比对,若比对一致,则在结果文件中将比对结果作为第一标记进行记录,并执行步骤b,若比对不一致,则在结果文件中将比对结果作为第二标记进行记录,并执行步骤e;
b:基于Python的数据分析模块Pandas对所述源表以及目标表的明细结果集进行比对,若比对一致,则在结果文件中将比对结果作为第三标记进行记录,并执行步骤e,若比对不一致,则在结果文件中将比对结果作为第四标记进行记录,并执行步骤c;
c:判断所述源表以及目标表中是否含有Json类型的字段,若是,则执行步骤d,若不是,则在结果文件中输出第一查询结果作为第五标记进行记录,并执行步骤e,其中,所述第一查询结果至少包括具体查询SQL;
d:将含有Json类型的字段根据Key进行排序,并基于Python的数据分析模块Pandas再次对所述源表以及目标表的明细结果集进行比对,若比对不一致,则在结果文件中输出第二查询结果作为第六标记进行记录,若比对一致,则执行步骤e,其中,所述第二查询结果至少包括Json明细查询不一致的结果以及第一查询结果;
e:对多张待比对表数据中的每一张源表以及目标表执行步骤a至步骤d,直至完成所有表数据的比对,并将总体比对结果进行输出。
优选地,在所述步骤a之前,还包括步骤i:查询多张待比对表数据的表结构,并获取多张待比对表数据的表字段,对所述表字段进行处理以获得总量查询SQL以及明细查询SQL。
优选地,所述步骤i包括:
i1:根据总量查询SQL获取表每天的总量;
i2:拼接表全部字段,将拼接后的数据进行加密,使之变为固定长度,根据加密后的数据进行分组,并对分组数据进行统计以获取拥有唯一键的明细数据。
优选地,在所述步骤a中,执行所述总量查询SQL,获取源表和目标表的总量结果集。
优选地,在所述步骤b中,执行所述明细查询SQL,获取源表和目标表的明细结果集。
优选地,在所述步骤a中,若所述源表以及所述目标表的总量结果集的比对结果不一致,将比对结果不一致的差异数据导出为Excel文件进行高亮显示。
优选地,在所述步骤c中,若所述源表以及目标表中不含有Json类型的字段,将不含有Json类型的字段的差异数据导出为Excel文件进行高亮显示。
优选地,在所述步骤d中,若所述源表以及目标表的明细结果集的比对结果不一致,将比对结果不一致的差异数据导出为Excel文件进行高亮显示。
优选地,在所述步骤d之后,还包括步骤d′:将所述第一标记和/或所述第二标记和/或所述第三标记和/或所述第四标记和/或所述第五标记和/或所述第六标记作为所述源表以及目标表的比对结果。
优选地,在所述步骤e中,所述总体比对结果至少包括所有待比对表数据中的源表以及目标表的比对结果。
根据本发明的另一个方面,提供了一种表数据批量自动比对的控制装置,包括:
第一处理装置:基于Python的数据分析模块Pandas对多张待比对表数据中的至少一张源表以及目标表的总量结果集进行比对,;
第二处理装置:基于Python的数据分析模块Pandas对所述源表以及目标表的明细结果集进行比对;
第三处理装置:判断所述源表以及目标表中是否含有Json类型的字段;
第四处理装置:将含有Json类型的字段根据Key进行排序,并基于Python的数据分析模块Pandas再次对所述源表以及目标表的明细结果集进行比对;
第五处理装置:对多张待比对表数据中的每一张源表以及目标表执行步骤a至步骤d,直至完成所有表数据的比对,并将总体比对结果进行输出。
优选地,还包括第一获取装置:查询多张待比对表数据的表结构,并获取多张待比对表数据的表字段,对所述表字段进行处理以获得总量查询SQL以及明细查询SQL。
优选地,所述第一获取装置包括:
第二获取装置:根据总量查询SQL获取表每天的总量;
第六处理装置:拼接表全部字段,将拼接后的数据进行加密,使之变为固定长度,根据加密后的数据进行分组,并对分组数据进行统计以获取拥有唯一键的明细数据。
本发明公开了一种严格遵循比对策略,基于总量查询和明细查询逐一将源表以及目标表进行比对,进而将比对结果进行高亮反馈的技术方案,本发明首先输入一个或者多个待比对表名,对表分析,查询表结构,获取表字段,自动拼接总量查询SQL和明细查询SQL,无需手动编写SQL,字段组合成select;然后,在总量比对一致的情况下,进一步自动进行明细数据比对(之前是字段对比),无需人工再按序依次进行总量比对和明细比对;当总量或明细存在差异时,输出SQL方便排查定位差异;当明细数据存在差异时,自动判断是否是因Json类型数据的Key顺序不一致导致,然后对Json类型的数据进行排序后比对;一次输入多张表,实现表数据批量比对,无需人工一张张比对;将多张表的总体比对结果以Txt形式输出,并将每张表的差异数据导出为Excel文件同时高亮显示,无需花时间一直等待和关注查询结果,脚本运行的过程中可以多线程兼顾其它工作。
本发明能够不通过人工处理,自动化完成多张表数据的比对,并代替人工查找差异数据,将比对结果予以记录,从而大幅度的提高了工作效率,且相对于人工进行比对而言,大幅度的提高了准确率。
附图说明
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
图1示出了本发明的具体实施方式的,一种表数据批量自动比对的控制方法的具体流程示意图;
图2示出了本发明的第一实施例的,查询多张待比对表数据的表结构,并获取多张待比对表数据的表字段,对所述表字段进行处理以获得总量查询SQL以及明细查询SQL的具体流程示意图;以及
图3示出了本发明的另一具体实施方式的,一种表数据批量自动比对的控制装置的模块连接示意图。
具体实施方式
为了更好的使本发明的技术方案清晰地表示出来,下面结合附图对本发明作进一步说明。
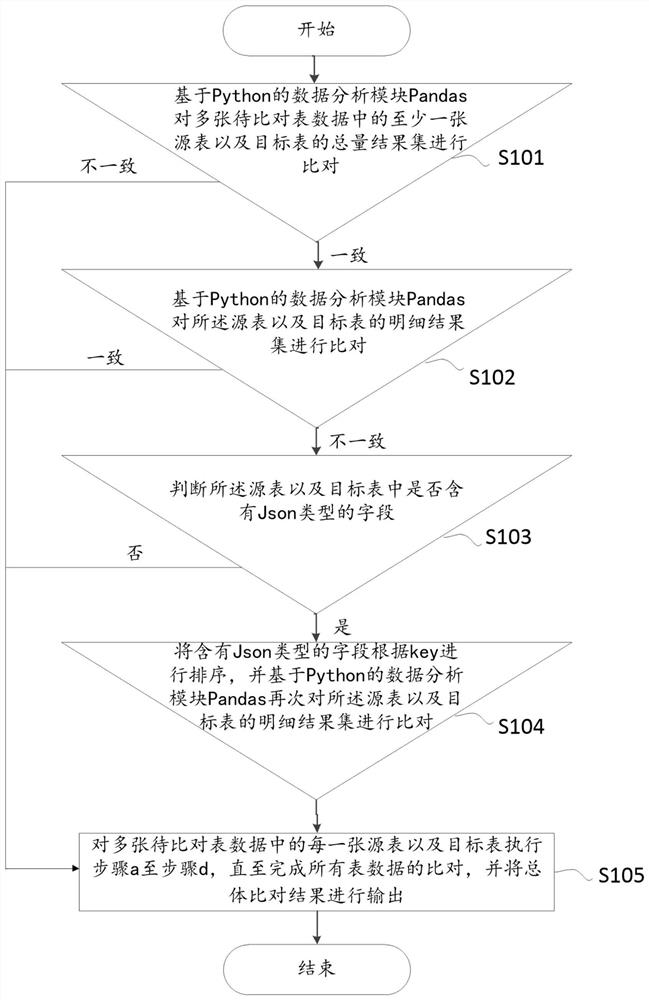
图1示出了本发明的具体实施方式的,一种表数据批量自动比对的控制方法的具体流程示意图,本发明的图1示出了一种源表以及目标表比对的控制方法,其通过比对总量结果集以及明细结果集进而确定多种不同的比对方式以及比对结果,同时实现批量多张表数据的依次比对,并将比对结果进行输出、显示,具体地,包括如下步骤:
首先,进入步骤S101,基于Python的数据分析模块Pandas对多张待比对表数据中的至少一张源表以及目标表的总量结果集进行比对,若比对一致,则在结果文件中将比对结果作为第一标记进行记录,并执行步骤S102,若比对不一致,则在结果文件中将比对结果作为第二标记进行记录,并执行步骤S105,Python是一种跨平台的计算机程序设计语言。是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的、大型项目的开发,Pandas是基于NumPy的一种工具,该工具是为了解决数据分析任务而创建的。Pandas纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。Pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
在步骤S101中,首先对总量结果集进行比对,若比对一致,则认为源表以及目标表的总量查询是一致的,进一步地,在结果文件中将比对结果作为第一标记进行记录,所述结果文件可以为一新建的word文件,txt文件,用以记录每张表的比对过程,比对结果,所述第一标记可以为“总量查询一致”,将“总量查询一致”记录至所述结果文件。
若比对不一致,则认为源表以及目标表的总量查询是不一致的,此时直接在结果文件中将比对结果作为第二标记进行记录,并执行步骤S105,所述第二标记可以为“总量查询不一致”,将“总量查询不一致”记录至所述结果文件,而在另一个优选地实施例中,在获取源表和目标表的总量结果集之前,首先需要执行总量查询SQL,这些将在后述的具体实施方式中作进一步的描述,在这样的实施例中,优选地将“总量查询不一致和具体的查询SQL”作为第二标记记录至所述结果文件。
然后,进入步骤S102,基于Python的数据分析模块Pandas对所述源表以及目标表的明细结果集进行比对,若比对一致,则在结果文件中将比对结果作为第三标记进行记录,并执行步骤S105,若比对不一致,则在结果文件中将比对结果作为第四标记进行记录,并执行步骤S103,在这样的实施例中,所述第三标记可以为“明细查询一致”,所述第四标记可以为“明细查询不一致”,在这样的实施例中,所述结果文件将在步骤S101的基础上进行记录,即当对总量结果集进行比对,若比对一致,将“总量查询一致”记录至所述结果文件,进一步地,在此基础上记录步骤S102的比对结果。
紧接着,进入步骤S103,判断所述源表以及目标表中是否含有Json类型的字段,若是,则执行步骤S104,若不是,则在结果文件中输出第一查询结果作为第五标记进行记录,并执行步骤S105,其中,所述第一查询结果至少包括具体查询SQL,Json是一种轻量级的数据交换格式。它基于ECMAScript的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。简洁和清晰的层次结构使得JSON成为理想的数据交换语言。易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率,在这样的实施例中,所述结果文件将在步骤S101的基础上进行记录,即当对总量结果集进行比对,若比对一致,将“总量查询一致”记录至所述结果文件,进一步地,在此基础上记录步骤S102的比对结果,若比对不一致,则在结果文件中将比对结果作为第四标记进行记录,并执行步骤S103,判断所述源表以及目标表中是否含有Json类型的字段,若不是,则在结果文件中输出第一查询结果作为第五标记进行记录,并执行步骤S105,所述第一查询结果为具体的查询SQL。
再然后,进入步骤S104,将含有Json类型的字段根据Key进行排序,并基于Python的数据分析模块Pandas再次对所述源表以及目标表的明细结果集进行比对,若比对不一致,则在结果文件中输出第二查询结果作为第六标记进行记录,若比对一致,则执行步骤S105,其中,所述第二查询结果至少包括Json明细查询不一致的结果以及第一查询结果,在这样的实施例中,所述结果文件将在步骤S101的基础上进行记录,即当对总量结果集进行比对,若比对一致,将“总量查询一致”记录至所述结果文件,进一步地,在此基础上记录步骤S102的比对结果,若比对不一致,则在结果文件中将比对结果作为第四标记进行记录,并执行步骤S103,判断所述源表以及目标表中是否含有Json类型的字段,若是,则执行步骤S104,将含有Json类型的字段根据Key进行排序,并基于Python的数据分析模块Pandas再次对所述源表以及目标表的明细结果集进行比对,若比对不一致,则在结果文件中输出第二查询结果作为第六标记进行记录,其中,所述第二查询结果至少包括Json明细查询不一致的结果以及具体的查询SQL。
最后,进入步骤S105,对多张待比对表数据中的每一张源表以及目标表执行步骤S101至步骤S104,直至完成所有表数据的比对,并将总体比对结果进行输出,本领域技术人员理解,步骤S101至步骤S104示出了一套较为完整的如何对于单张源表以及目标表的总量以及明细进行查询、判断、给出结果的完整过程,而步骤S105即为对所有表数据同样进行步骤S101至步骤S104,直至完成所有表数据的比对,并将总体比对结果进行输出。
进一步地,在所述步骤S101中,执行所述总量查询SQL,获取源表和目标表的总量结果集,本步骤优选地设置在步骤S101之前,即通过执行所述总量查询SQL,进而获取到源表和目标表的总量结果集。
进一步地,在所述步骤S102中,执行所述明细查询SQL,获取源表和目标表的明细结果集,本步骤优选地设置在步骤S101和/或102之前,即通过执行所述明细查询SQL,进而获取到源表和目标表的明细结果集。
进一步地,在所述步骤S101中,若所述源表以及所述目标表的总量结果集的比对结果不一致,将比对结果不一致的差异数据导出为Excel文件进行高亮显示,在这样的实施例中,所述高亮显示可以通过加粗字体、下划线、改变颜色、改变字号等等形式进行显示,而在其他的实施例中,也可以将其输出至其他用以记录的格式文件。
进一步地,在所述步骤S103中,若所述源表以及目标表中不含有Json类型的字段,将不含有Json类型的字段的差异数据导出为Excel文件进行高亮显示,可以参考前述关于高亮显示的说明。
进一步地,在所述步骤S104中,若所述源表以及目标表的明细结果集的比对结果不一致,将比对结果不一致的差异数据导出为Excel文件进行高亮显示,具体地,可以参考前述关于高亮显示的说明。
进一步地,在所述步骤S104之后,还包括步骤:将所述第一标记和/或所述第二标记和/或所述第三标记和/或所述第四标记和/或所述第五标记和/或所述第六标记作为所述源表以及目标表的比对结果,所述源表以及目标表的比对结果可能会根据判断策略、判断结果形成所述第一标记、所述第二标记、所述第三标记、所述第四标记、所述第五标记、所述第六标记中的一个或多个所组成的比对结果。本领域技术人员理解,在所述步骤S105中,所述总体比对结果至少包括所有待比对表数据中的源表以及目标表的比对结果,在这样的实施例中,即将所有的待比对表数据中的源表以及目标表的比对结果通过合并、排序、调整格式等等处理后,形成一种完整的比对结果即为所述总体比对结果。
作为本发明的另一个优选实施例,本发明首先输入一个或者多个待比对表名,自动依次执行如下步骤:1、查询表结构,获取表字段,对获取的字段进行处理,获得总量查询SQL和明细查询SQL。总量查询和明细查询的方法如下:(1)总量查询SQL:查询表每天的总量select p_dt,count(*)as cnt from db.test where p_dt in('2020-07-16')group byp_dt;(2)明细查询SQL:拼接表全部字段,然后将拼接后的数据进行加密,使之变为固定长度。根据加密后的数据进行分组,并对分组数据进行统计SELECT cat_ws,COUNT(*)AScntFROM(SELECT concat_ws('$',CAST(a1 AS string),CAST(a2 AS string),CAST(p_dtAS string))AS cat_wsFROM db.testWHERE p_dt IN('2020-08-05'))a GROUP BY cat_ws;2、执行总量查询SQL,获取源表和目标表的总量结果集利用python的数据分析模块pandas进行比对,如果不一致,输出“总量查询不一致和具体的查询SQL”到txt结果文件,并将差异数据导出为Excel文件同时高亮显示,然后执行第5步骤;如果一致,输出“总量查询一致”到txt结果文件,然后执行第3步骤:3、执行明细查询SQL,获取源表和目标表的明细结果集利用python的数据分析模块pandas进行比对,如果一致,输出“明细查询一致”到txt结果文件,然后执行第5步骤;如果不一致,输出“明细查询不一致”到txt结果文件。然后判断表中是否含有json类型的字段,如果是,执行第4步骤;如果否,输出“具体的查询SQL”到txt结果文件,并将差异数据导出为Excel文件同时高亮显示,然后执行第5步骤;4、将步骤3查询出的json类型的数据,根据key排序利用python的数据分析模块pandas进行比对,如果不一致,输出“json明细查询不一致和具体的查询SQL”到txt结果文件,并将差异数据导出为Excel文件同时高亮显示,然后执行第5步骤;如果一致,执行第5步骤;5、对下一张待比对表执行第1~4步骤,当所有表都比对完成后,会将总体比对结果以txt形式输出,并将每张表的差异数据导出为Excel文件同时高亮显示。
图2示出了本发明的第一实施例的,查询多张待比对表数据的表结构,并获取多张待比对表数据的表字段,对所述表字段进行处理以获得总量查询SQL以及明细查询SQL的具体流程示意图,本领域技术人员理解,本步骤优选地设置在步骤S101之前执行,即查询多张待比对表数据的表结构,并获取多张待比对表数据的表字段,对所述表字段进行处理以获得总量查询SQL以及明细查询SQL。具体地,所述步骤包括:
首先,进入步骤S201,根据总量查询SQL获取表每天的总量,然后,在步骤S202中,拼接表全部字段,将拼接后的数据进行加密,使之变为固定长度,根据加密后的数据进行分组,并对分组数据进行统计以获取拥有唯一键的明细数据。本领域技术人员理解,进入步骤S201,根据分区日期进行分组,获取表每天的总量。然后,在步骤S202中,将表全部字段强制转换为字符串类型,然后使用拼接函数将所有字段拼接为1个字段,再对拼接后的数据进行分组,以获取拥有唯一键的明细数据且对分组数据进行统计,最后将明细数据进行MD5加密,使之变为固定长度,从而得到唯一且长度固定的明细数据。
图3示出了本发明的另一具体实施方式的,一种表数据批量自动比对的控制装置的模块连接示意图。本发明公开了一种表数据批量自动比对的控制装置,其采用前述图1以及图2中所述的控制方法,包括:第一处理装置1:基于Python的数据分析模块Pandas对多张待比对表数据中的至少一张源表以及目标表的总量结果集进行比对,所述第一处理装置1的具体工作原理可以参考前述步骤S101,在此不予赘述。
进一步地,所述控制装置还包括第二处理装置2:基于Python的数据分析模块Pandas对所述源表以及目标表的明细结果集进行比对,所述第二处理装置2的具体工作原理可以参考前述步骤S102,在此不予赘述。
进一步地,所述控制装置还包括第三处理装置3:判断所述源表以及目标表中是否含有Json类型的字段,所述第三处理装置3的具体工作原理可以参考前述步骤S103,在此不予赘述。
进一步地,所述控制装置还包括第四处理装置4:将含有Json类型的字段根据Key进行排序,并基于Python的数据分析模块Pandas再次对所述源表以及目标表的明细结果集进行比对,所述第四处理装置4的具体工作原理可以参考前述步骤S104,在此不予赘述。
进一步地,所述控制装置还包括第五处理装置5:对多张待比对表数据中的每一张源表以及目标表执行步骤S101至步骤S104,直至完成所有表数据的比对,并将总体比对结果进行输出,所述第五处理装置5的具体工作原理可以参考前述步骤S105,在此不予赘述。
进一步地,还包括第一获取装置6:查询多张待比对表数据的表结构,并获取多张待比对表数据的表字段,对所述表字段进行处理以获得总量查询SQL以及明细查询SQL,更为具体地,所述第一获取装置6包括第二获取装置61:根据总量查询SQL获取表每天的总量,所述第二获取装置61的具体工作原理可以参考前述步骤S201,在此不予赘述。
进一步地,所述第一获取装置6还包括第六处理装置62:拼接表全部字段,将拼接后的数据进行加密,使之变为固定长度,根据加密后的数据进行分组,并对分组数据进行统计以获取拥有唯一键的明细数据,所述第六处理装置62的具体工作原理可以参考前述步骤S202,在此不予赘述。
需要说明的是,上述各装置实施例的具体实施方式与前述对应方法实施例的具体实施方式相同,在此不再赘述。综上所述,本发明的技术方案,为用户提供了自动化的表数据批量比对的控制方法,提高了工作效率,提高了比对准确率,简化了比对方式。
在此提供的算法和显示不与任何特定计算机、虚拟装置或者其它设备固有相关。各种通用装置也可以与基于在此的示教一起使用。根据上面的描述,构造这类装置所要求的结构是显而易见的。此外,本发明也不针对任何特定编程语言。应当明白,可以利用各种编程语言实现在此描述的本发明的内容,并且上面对特定语言所做的描述是为了披露本发明的最佳实施方式。
在此处所提供的说明书中,说明了大量具体细节。然而,能够理解,本发明的实施例可以在没有这些具体细节的情况下实践。在一些实施例中,并未详细示出公知的方法、结构和技术,以便不模糊对本说明书的理解。
类似地,应当理解,为了精简本发明并帮助理解各个发明方面中的一个或多个,在上面对本发明的示例性实施例的描述中,本发明的各个特征有时被一起分组到单个实施例、图、或者对其的描述中。然而,并不应将该公开的方法解释成反映如下意图:即所要求保护的本发明要求比在每个权利要求中所明确记载的特征更多的特征。更确切地说,如下面的权利要求书所反映的那样,发明方面在于少于前面公开的单个实施例的所有特征。因此,遵循具体实施方式的权利要求书由此明确地并入该具体实施方式,其中每个权利要求本身都作为本发明的单独实施例。
此外,本领域技术人员理解,尽管在此所述的一些实施例包括其它实施例中所包括的某些特征而不是其它特征,但是不同实施例的特征的组合意味着处于本发明的范围之内并且形成不同的实施例。例如,在权利要求书中,所要求保护的实施例的任意之一都可以以任意的组合方式来使用。
本发明的各个部件实施例可以以硬件实现,或者以在一个或者多个处理器上运行的软件模块实现,或者以它们的组合实现。本领域技术人员理解,可以在实践中使用微处理器或者数字信号处理器(DSP)来实现根据本发明实施例的装置中的一些或者全部部件的一些或者全部功能。本发明还可以实现为用于执行这里所描述的方法的一部分或者全部的设备或者装置程序(例如,计算机程序和计算机程序产品)。这样的实现本发明的程序可以存储在计算机可读介质上,或者可以具有一个或者多个信号的形式。这样的信号可以从因特网网站上下载得到,或者在载体信号上提供,或者以任何其他形式提供。
应该注意的是上述实施例对本发明进行说明而不是对本发明进行限制,并且本领域技术人员在不脱离所附权利要求的范围的情况下可设计出替换实施例。在权利要求中,不应将位于括号之间的任何参考符号构造成对权利要求的限制。词语“包含”不排除存在未列在权利要求中的元件或步骤。位于元件之前的单词“一”或“一个”不排除存在多个这样的元件。本发明可以借助于包括有若干不同元件的硬件以及借助于适当编程的计算机来实现。在列举了若干装置的单元权利要求中,这些装置中的若干个可以是通过同一个硬件项来具体体现。单词第一、第二、以及第三等的使用不表示任何顺序。可将这些单词解释为名称。
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变形或修改,这并不影响本发明的实质内容。
- 一种表数据批量自动比对的控制方法及装置
- 一种批量表数据自动扩充的控制方法及装置